
Statistically inclined software developer, occasional blogger about math stats stuff. Working @AnthropicAI
Joined May 2009
- Tweets 1,140
- Following 215
- Followers 5,485
- Likes 265
63 Photos and videos


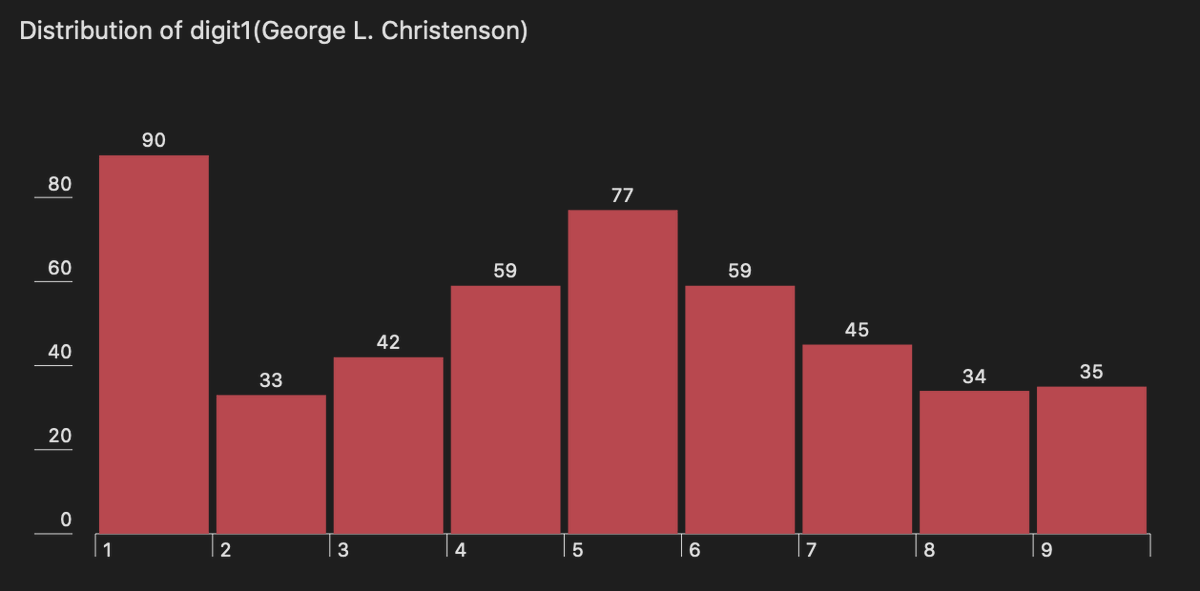
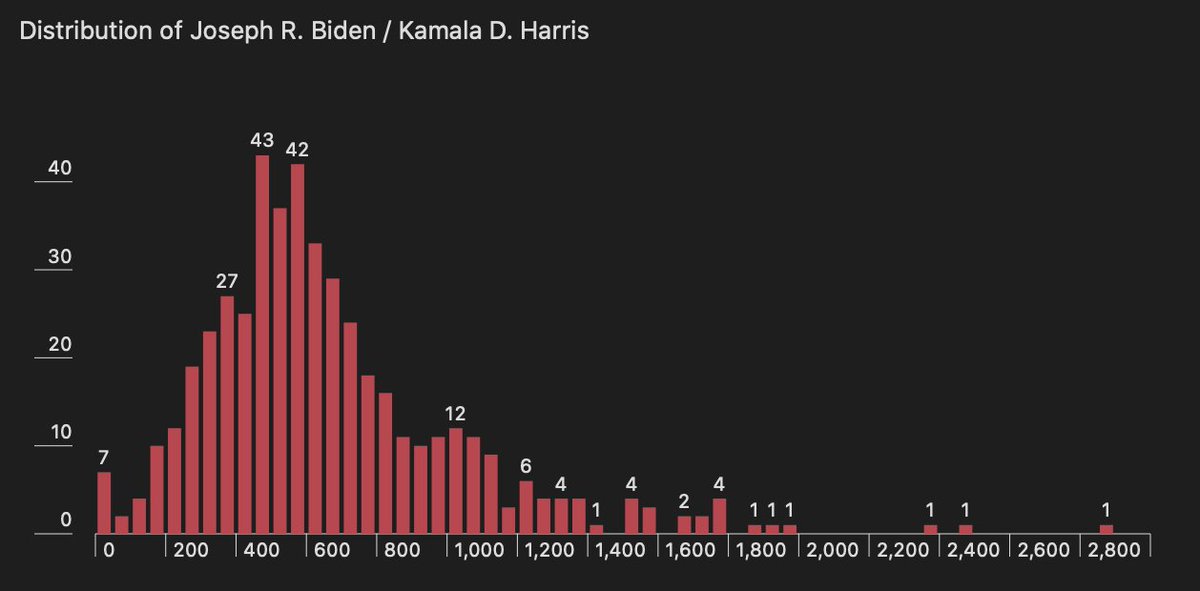
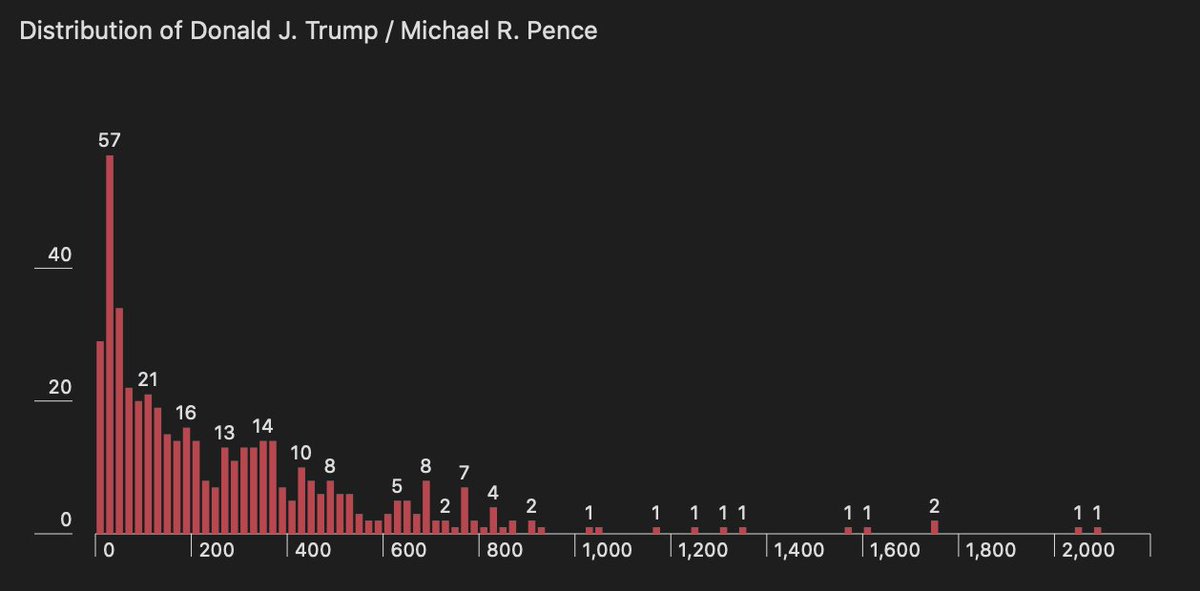
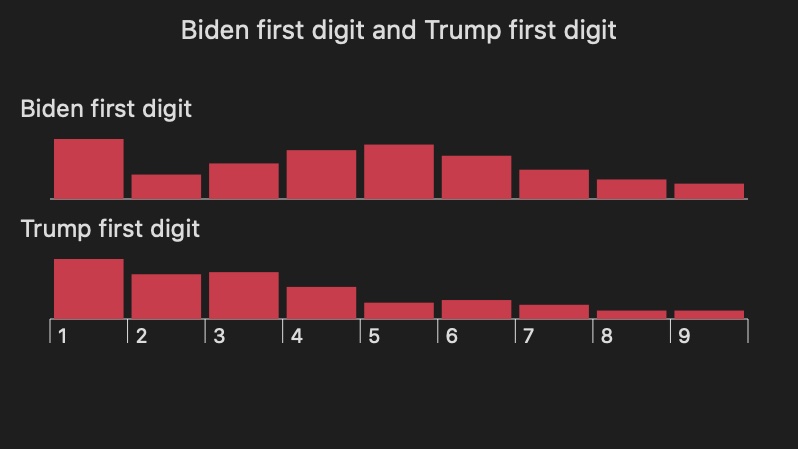


Pinned Tweet

24 Jul 2023
I hit a bug in the Attention formula that’s been overlooked for 8 years. All Transformer models (GPT, LLaMA, etc) are affected.
Researchers isolated the bug last month – but they missed a simple solution…
Why LLM designers should stop using Softmax 👇
evanmiller.org/attention-is-…
73
354
2,298
591,684

🚀 New on the Klaviyo Data Science Podcast: @EvMill joins us to discuss his paper, Adding Error Bars to Evals: A Statistical Approach to Language Model Evaluations.
AI metrics are everywhere—but how much uncertainty is behind them? Understanding variability matters. Listen now: bit.ly/3CV0CmX #AI #DataScience

4
14
1,995
Evan Miller retweeted

2 Dec 2024
We’re starting a Fellows program to help engineers and researchers transition into doing frontier AI safety research full-time.
Beginning in March 2025, we'll provide funding, compute, and research mentorship to 10–15 Fellows with strong coding and technical backgrounds.

72
290
2,130
504,883
Evan Miller retweeted

14 Nov 2024
This paper on the statistics of evals is great (and seems to be flying under the radar): arxiv.org/abs/2411.00640v1
The author basically shows all the relevant statistical tools needed for evals, e.g. how to do compute the right error bars, how to compare model performance, and how to do power analysis.
Back when @jeremy_scheurer and I wrote the "We need a Science of Evals" post (apolloresearch.ai/blog/we-ne…) this paper is exactly the kind of thing we had in mind and more.
7
35
215
37,060
Evan Miller retweeted

20 Nov 2024
Awesome new research by my friend and colleague @EvMill — adding error bars to evals! Always great to see the Central Limit Theorem!
19 Nov 2024

New Anthropic research: Adding Error Bars to Evals.
AI model evaluations don’t usually include statistics or uncertainty. We think they should.
Read the blog post here: anthropic.com/research/stati…
2
9
2,041
Evan Miller retweeted

19 Nov 2024
I cannot agree with this more. Please use basic research methods on AI benchmarking!



19 Nov 2024
New Anthropic research: Adding Error Bars to Evals.
AI model evaluations don’t usually include statistics or uncertainty. We think they should.
Read the blog post here: anthropic.com/research/stati…
4
29
229
26,994
Evan Miller retweeted
19 Nov 2024
New Anthropic research: Adding Error Bars to Evals.
AI model evaluations don’t usually include statistics or uncertainty. We think they should.
Read the blog post here: anthropic.com/research/stati…
50
297
2,086
756,249
11 Oct 2024
RT @DarioAmodei: Machines of Loving Grace: my essay on how AI could transform the world for the better
darioamodei.com/machines-of-…
1,200
26 Aug 2024
New sequential A/B test from @Zalando based on the Lévy inequality – check it out! arxiv.org/abs/2406.16523v1
2
7
845
5 Aug 2024
I think I've finally cracked quantiles…
A/B testing medians, instead of means, usually requires an expensive bootstrap. But we can use a likelihood-ratio test (Wilks' theorem) instead. This reduces the quantile problem to a few simple formulas.
Read on! arxiv.org/abs/2401.10233
1
17
1,499
Evan Miller retweeted

5 Feb 2024
Ten months ago, we launched the Vesuvius Challenge to solve the ancient problem of the Herculaneum Papyri, a library of scrolls that were flash-fried by the eruption of Mount Vesuvius in 79 AD.
Today we are overjoyed to announce that our crazy project has succeeded. After 2000 years, we can finally read the scrolls:
This image was produced by @Youssef_M_Nader, @LukeFarritor, and @JuliSchillij, who have now won the Vesuvius Challenge Grand Prize of $700,000. Congratulations!!
These fifteen columns come from the very end of the first scroll we have been able to read and contain new text from the ancient world that has never been seen before. The author – probably Epicurean philosopher Philodemus – writes here about music, food, and how to enjoy life's pleasures. In the closing section, he throws shade at unnamed ideological adversaries – perhaps the stoics? – who "have nothing to say about pleasure, either in general or in particular."
This year, the Vesuvius Challenge continues. The text that we revealed so far represents just 5% of one scroll.
In 2024, our goal is to from reading a few passages of text to entire scrolls, and we're announcing a new $100,000 grand prize for the first team that is able to read at least 90% of all four scrolls that we have scanned.
The scrolls stored in Naples that remain to be read represent more than 16 megabytes of ancient text. But the villa where the scrolls were found was only partially excavated, and scholars tell us that there may be thousands more scrolls underground. Our hope is that the success of the Vesuvius Challenge catalyzes the excavation of the villa, that the main library is discovered, and that whatever we find there rewrites history and inspires all of us.
It's been a great joy to work on this strange and amazing project. Thanks to Brent Seales for laying the foundation for this work over so many years, thanks to the friends and Twitter users whose donations powered our effort, and thanks to the many contestants whose contributions have made the Vesuvius Challenge successful!
Read more in our announcement: scrollprize.org/grandprize

2,250
14,322
63,815
26,353,721
Evan Miller retweeted

2 Oct 2023
The blog about Softmax 1 plays a very important role when we were trying to identify the root cause of the sink @Guangxuan_Xiao can comment more!
1
15
4,076
Evan Miller retweeted

2 Oct 2023
Have a few thoughts about this approach
But most importantly, I'm happy to see @EvMill's idea on softmax1 recognized - to my very basic and intuitive understanding of LLMs, it made enough sense to warrant further analysis
arxiv.org/abs/2309.17453
4
16
162
29,528
25 Sep 2023
👀
25 Sep 2023

Unlike with clipped softmax, to achieve an exact zero in the output using softmax1 for a (partial) no-update, the input requires to be -infinity. However, after @EvMill blog post we experimented with softmax1 and found it in practice competitive with our proposed approaches.
1
13
3,504
Evan Miller retweeted

23 Sep 2023
Results of my latest nerdsnipe from @TetraspaceWest!
The plot below shows the predicted shape of the water flow, with a model taking into account gravity and surface tension. It looks just like the real thing!
Conclusion: yep, it's surface tension
details below 😁
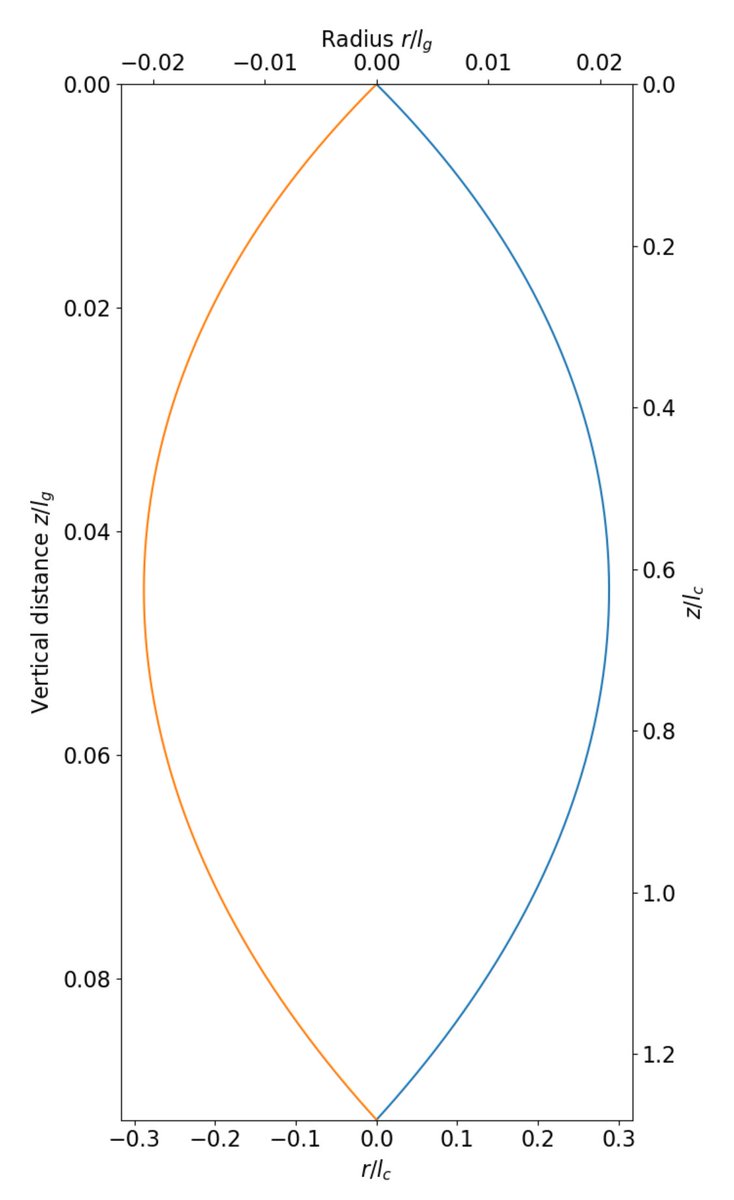
3
4
37
5,842
Evan Miller retweeted

14 Sep 2023
Following @EvMill great blog post on encountered issues on the GPT-like models training that appear to be related to the SoftMax function, I wrote this small piece mostly to understand what was going on.
wandb.me/tinyllama
2
10
47
5,270
Evan Miller retweeted

1 Sep 2023
Kurt Vonnegut's 1969 address to the American Physical Society @APSphysics --on the innocence of the "old-fashioned scientist" and its loss after World War II. For physicists, artists, and other humans. I have transcribed it in its entirety as a google doc:
docs.google.com/document/d/1…
5
18
66
20,510
29 Aug 2023
Softmax1 update…
We now have support for
⚡️Flash Attention ⚡️
This lets us test much larger models than before! To get the code, just
pip install flash-attention-softmax-n
Or clone / star the GitHub repo here: github.com/softmax1/Flash-At…
All credit / kudos to Chris Murphy.
1
12
51
9,215
7 Aug 2023
Softmax1, Week 2.
Second set of empirical results are in, and they are…
🌸 promising 🌸
Weight kurtosis is roughly the same – but activation kurtosis improved 30X (!!) and maximum activation magnitude reduced 15X (!).
Read more from @johnowhitaker:
datasciencecastnet.home.blog…
1
17
106
24,287
Evan Miller retweeted

5 Aug 2023
Controlling language models has a long way to go - and clever techniques - involving Finite State Machines - offer a way to eliminate hallucinations at record-setting speeds.
New work by @remilouf @KlettPhoebe @dan_p_simpson // @NormalComputing
blog.normalcomputing.ai/post…
4
21
117
31,799
Evan Miller retweeted

4 Aug 2023
New blog post: datasciencecastnet.home.blog…
I've had fun joining in the community effort to investigate @EvMill's claims about softmax1 as a quantization-friendly modification to attention. Seems promising! But to me, the most exciting thing is watching open science in action :)
5
11
57
14,680