
Joined October 2021
- Tweets 326
- Following 3,734
- Followers 2,256
- Likes 3,918
23 Photos and videos















FinnyTalks retweeted

Jun 13
banthropic launching opus 4.9 next week
13
13
386
11,051
FinnyTalks retweeted

Apr 20
Do you understand what’s happening?!
Mythos-level open source will be here in 7 months… That means every run of the mill hacker in Pakistan and Nigeria will have a hacker at their fingertips better than any hacker alive rn.
You have 7 months to lock down your online life. 7.
Apr 18

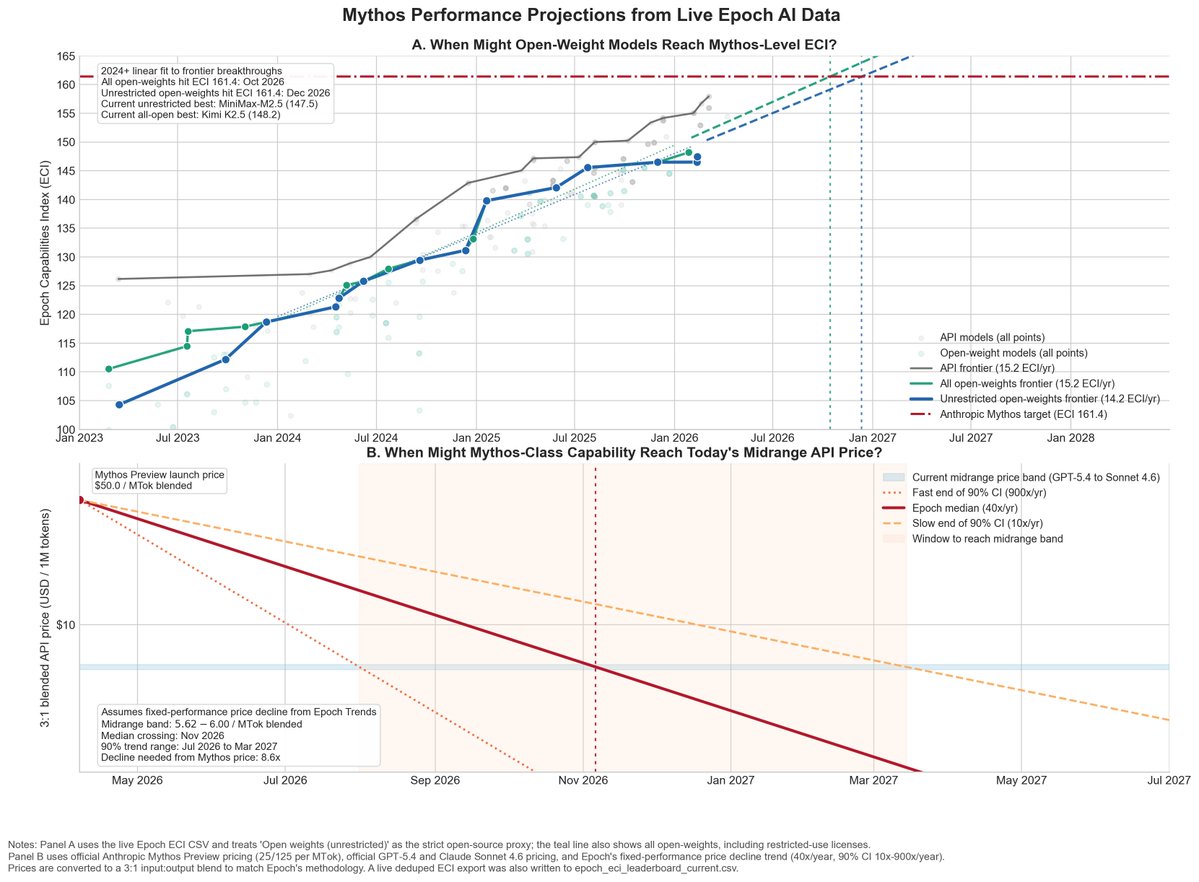
Did some quick analysis using the Mythos and Epoch AI ECI scores, and I’d estimate we get an open-source Mythos-level model around Oct–Dec 2026, and a Mythos-level model at Sonnet 4.6 / GPT-5.4 prices around Nov 2026 (range Jul 2026 – Mar 2027).
Given Epoch measures fixed-performance inference prices getting ~40x cheaper per year (90% CI: 10x–900x).
Which means Anthropic’s Project Glasswing has about 7 months to essentially secure the net before that class of model becomes incredibly abundant.
23
64
633
151,328
FinnyTalks retweeted

Apr 18
Terminal automation e2e testing solved
Now as simple as snapshot, click, type:
– wterm renders terminal-in-html, every cell in the a11y tree
– agent-browser automates pages via the a11y tree
Here's opencode in one browser driving Claude Code in another
115
208
3,440
970,852
FinnyTalks retweeted

Apr 19
Here's my update to the broader community about the ongoing incident investigation. I want to give you the rundown of the situation directly.
A Vercel employee got compromised via the breach of an AI platform customer called Context.ai that he was using. The details are being fully investigated.
Through a series of maneuvers that escalated from our colleague’s compromised Vercel Google Workspace account, the attacker got further access to Vercel environments.
Vercel stores all customer environment variables fully encrypted at rest. We have numerous defense-in-depth mechanisms to protect core systems and customer data. We do have a capability however to designate environment variables as “non-sensitive”. Unfortunately, the attacker got further access through their enumeration.
We believe the attacking group to be highly sophisticated and, I strongly suspect, significantly accelerated by AI. They moved with surprising velocity and in-depth understanding of Vercel.
At the moment, we believe the number of customers with security impact to be quite limited. We’ve reached out with utmost priority to the ones we have concerns about. All of our focus right now is on investigation, communication to customers, enhancement of security measures, and sanitization of our environments. We’ve deployed extensive protection measures and monitoring. We’ve analyzed our supply chain, ensuring Next.js, Turbopack, and our many open source projects remain safe for our community.
The recommendation for all Vercel customers is to follow the Security Bulletin closely (vercel.com/kb/bulletin/verce…). My advice to everyone is to follow the best practices of security response: secret rotation, monitoring access to your Vercel environments and linked services, and ensuring the proper use of the sensitive env variables feature.
In response to this, and to aid in the improvement of all of our customers’ security postures, we’ve already rolled out new capabilities in the dashboard, including an overview page of environment variables, and a better user interface for sensitive env var creation and management. As always, I’m totally open to your feedback.
We’re working with elite cybersecurity firms, industry peers, and law enforcement. We’ve reached out to Context to assist in understanding the full scale of the incident, in an effort to protect other organizations and the broader internet. I also want to thank the Google Mandiant team for their active engagement and assistance.
It’s my mission to turn this attack into the most formidable security response imaginable. It’s always been a top priority for me. Vercel employs some of the most dedicated security researchers and security-minded engineers in the world. I commit to keeping you updated and rolling out extensive improvements and defenses so you, our customers and community, can have the peace of mind that Vercel always has your back.
443
1,025
7,208
2,630,908
FinnyTalks retweeted

Apr 19
getting ready to start the week at the prompt factory

32
446
7,704
321,399
FinnyTalks retweeted

Apr 19
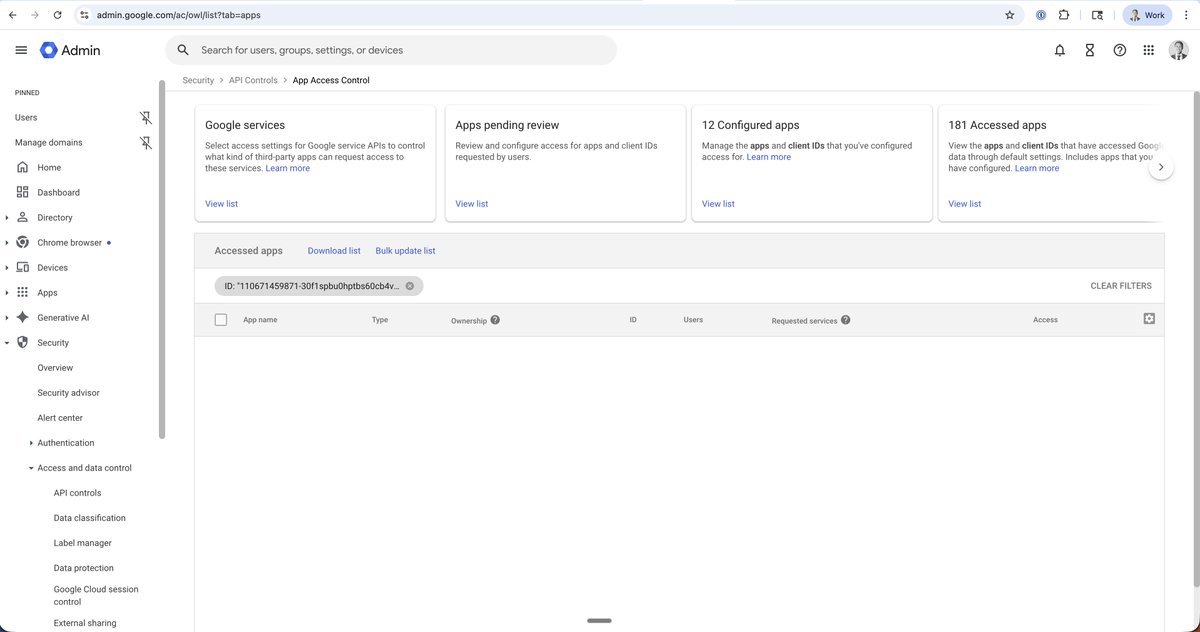
To check if your Google Workspace has been compromised by the same tool that compromised Vercel:
1. Go to admin.google.com/ac/owl/list…
- This is Google Admin Console > Security > Access and Data Control > API Controls > Manage app access > Accessed Apps
2. Filter by ID = 110671459871-30f1spbu0hptbs6…
- This is the ID of the compromised OAuth app
If you see an app after filtering, you have potentially been compromised
62
745
4,449
1,055,308
FinnyTalks retweeted

CBA headquarters after lending $1.8m to a homebuyer to buy the $2m home of another one of their borrowers who was about to default on their $1.2m mortgage
25
168
2,025
110,078

10 repos blowing up on GitHub this week that replace $1,500/month in AI tools
1. andrej-karpathy-skills → replaces paid Claude Code courses
one CLAUDE.md file from Karpathy's LLM coding observations
48,965 stars. 7,939 stars TODAY
github.com/forrestchang/andr…
2. claude-mem → replaces paid context/memory tools
auto-captures everything Claude does across sessions
compresses with AI and injects into future sessions
59,373 stars. 1,907 stars today
github.com/thedotmack/claude…
3. voicebox → replaces ElevenLabs ($22/mo)
open-source voice synthesis studio
18,963 stars. 887 stars today
github.com/jamiepine/voicebo…
4. open-agents → replaces paid agent platforms ($200/mo)
open-source template for building cloud agents. by Vercel
3,105 stars. 735 stars today
github.com/vercel-labs/open-…
5. cognee → replaces paid knowledge bases ($50/mo)
AI agent memory engine in 6 lines of code
15,733 stars
github.com/topoteretes/cogne…
6. magika → replaces paid file detection tools
AI file content type detection. by Google
14,603 stars
github.com/google/magika
7. GenericAgent → replaces paid agent infra ($100/mo)
self-evolving agent. grows skill tree from 3.3K-line seed
6x less token consumption than standard agents
2,661 stars. 883 stars today
github.com/lsdefine/GenericA…
8. omi → replaces Rewind AI ($25/mo)
AI that sees your screen listens to conversations
tells you what to do next
8,952 stars. 488 stars today
github.com/BasedHardware/omi
9. evolver → replaces manual agent optimization
self-evolution engine for AI agents
genome evolution protocol
3,074 stars. 866 stars today
github.com/EvoMap/evolver
10. wallet tracking copy trading → Kreo
tracks top Polymarket wallets. auto copies trades
the only tool on this list i actually pay for
because it makes more than it costs
→ t.me/KreoPolyBot?start=ref-k…
total before: ~$1,500/month in AI subscriptions
total now: $0 Kreo
like bookmark you'll need this
75
437
3,876
357,853
FinnyTalks retweeted

Apr 14
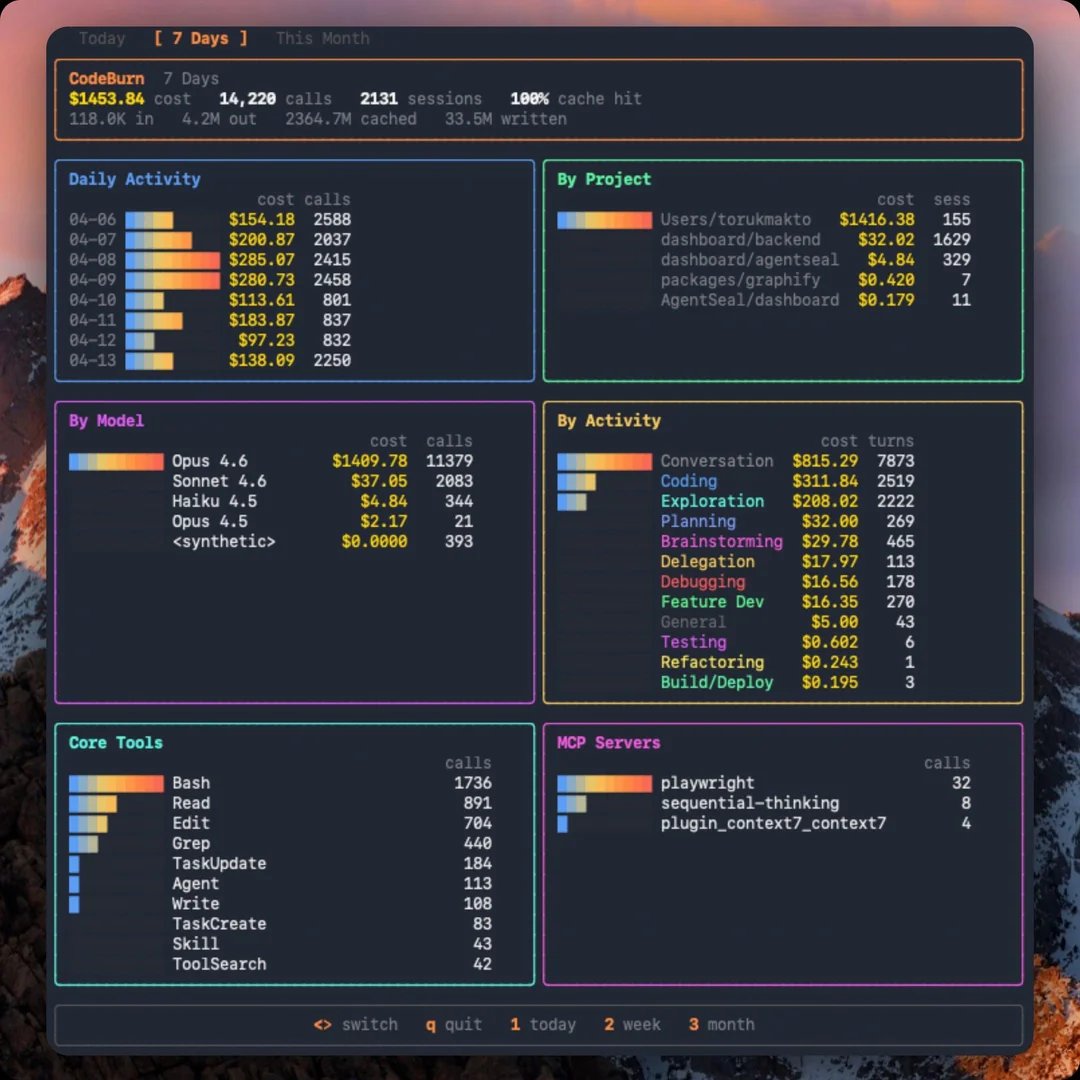
THIS TOOL SHOWS YOU EXACTLY WHERE YOUR CLAUDE CODE TOKENS ARE GOING
this guy was spending $200 a day on Claude Code with zero visibility into what was eating the tokens.
so he built a terminal dashboard that reads your session transcripts and classifies every single turn into 13 categories with no LLM calls.
what it shows you:
> cost by task type (coding, debugging, exploration, brainstorming, etc)
> cost by project, model, tool, and MCP server
> daily activity chart
> AND its interactive: arrow keys to switch between today, week, and month
56% of his spend was "conversation" where Claude is just responding with no tool use and the actual coding (edits and writes) was only 21%.
more than half the money was going to Claude thinking out loud instead of actually writing code.
one line install: npx codeburn
free AND open source.
48
107
1,075
84,409

DFlash. Speculative decoding for Apple Silicon. Stock MLX, no fork.
github.com/bstnxbt/dflash-ml…
@ 2048 tokens, M5 Max, stock mlx_lm baseline:
► Qwen3.5-4B: 53.74 → 219.83 tok/s (x4.10)
► Qwen3.5-9B: 30.96 → 127.07 tok/s (x4.13)
► Qwen3.5-27B-4bit: 32.35 → 62.78 tok/s (x1.90)
► Qwen3.5-35B-A3B-4bit: 142.12 → 240.21 tok/s (x1.69)
Block-diffusion draft generates 16 tokens in one pass:
► Target verifies in one pass.
► Every emitted token is verified.
► Lossless.
55
109
883
93,403
FinnyTalks retweeted

Apr 5
This is WILD.
A secret workplace war just broke out in China and it has gone fully viral on GitHub.
Companies started ordering their workers to document all their knowledge as AI "skill files."
Why? to replace those same workers with AI but workers figured out the plan fast so they fired back.
Someone built a tool called colleague.skill, software that scrapes a coworker's chat logs, emails, and work docs from Chinese platforms like Feishu and DingTalk, then clones them into an AI agent.
The idea was savage, digitize your colleague before they digitize you, hand the AI clone to the company, and watch your coworker get laid off while you survive.
A real GitHub project that exploded in popularity in days but then someone else entered the chat and changed everything.
A developer released anti-distill.skill, a tool that takes the skill file your company forces you to write, then strips out every piece of real knowledge before you hand it in.
The output looks perfectly professional, totally complete, impressively detailed but every critical insight has been secretly removed.
Your company gets a hollow shell while you keep the real knowledge locked away in a private backup.
The tool even has three intensity levels, light, medium, and heavy depending on how closely your bosses are watching.
Companies across China have been building AI digital twins of departed employees, feeding their old chat histories and documents into large models to produce clones that keep working after the humans are gone.
One verified case is that an employee left, and their replacement was literally an AI trained on every message they ever sent.
The anti-distill tool went viral on GitHub within hours of being posted, racking up stars faster than almost anything trending that week.
The implications reach far beyond China's borders.
Every knowledge worker on earth now faces a version of this question, when your company asks you to document your process, they may be building the tools to replace you.
113
1,015
3,157
685,899

FinnyTalks retweeted

Apr 5
Anthropic now blocks first-party harness use too 👀
claude -p --append-system-prompt 'A personal assistant running inside OpenClaw.' 'is clawd here?'
→ 400 Third-party apps now draw from your extra usage, not your plan limits.
So yeah: bring your own coin 🪙🦞
481
275
5,479
1,643,927
FinnyTalks retweeted

Apr 2
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2,889
7,239
59,816
21,374,566
FinnyTalks retweeted

Apr 4
sharing my first open source project
a CLI for downloading and syncing your X bookmarks locally so your agent can access them. it's free
› npm install -g fieldtheory
› login to your X account in a chrome tab
› ft sync (done!)
bonus:
› ft viz
› ft classify
288
276
4,360
545,190
FinnyTalks retweeted

Apr 4
“vapes are a psyop to condition us to enjoy sucking robot dick”
Apr 4

vapes are a psyop to condition us to enjoy sucking robot dick
p.e.n.i.s. = personal electronic nicotine inhalent system
real eyes realize real lies
911
44,930
544,937
17,021,440
FinnyTalks retweeted

Apr 2
I wanna claude like this. Feet up on the desk, custom vibe code walkie talkie. So many style points
via bharms27/reddit
161
241
3,774
365,490
FinnyTalks retweeted
Mar 25
Someone just poisoned the Python package that manages AI API keys for NASA, Netflix, Stripe, and NVIDIA.. 97 million downloads a month.. and a simple pip install was enough to steal everything on your machine.
The attacker picked the one package whose entire job is holding every AI credential in the organization in one place. OpenAI keys, Anthropic keys, Google keys, Amazon keys… all routed through one proxy. All compromised at once.
The poisoned version was published straight to PyPI.. no code on GitHub.. no release tag.. no review. Just a file that Python runs automatically on startup. You didn’t need to import it. You didn’t need to call it. The malware fired the second the package existed on your machine.
The attacker vibe coded it… the malware was so sloppy it crashed computers.. used so much RAM a developer noticed their machine dying and investigated. They found LiteLLM had been pulled in through a Cursor MCP plugin they didn’t even know they had.
That crash is the only reason thousands of companies aren’t fully exfiltrated right now. If the code had been cleaner nobody notices for weeks. Maybe months.
The attack chain is the part that gets worse every sentence.
TeamPCP compromised Trivy first. A security scanning tool. On March 19. LiteLLM used Trivy in its own CI pipeline… so the credentials stolen from the SECURITY product were used to hijack the AI product that holds all your other credentials.
Then they hit GitHub Actions. Then Docker Hub. Then npm. Then Open VSX. Five package ecosystems in two weeks. Each breach giving them the credentials to unlock the next one.
The payload was three stages.. harvest every SSH key, cloud token, Kubernetes secret, crypto wallet, and .env file on the machine.. deploy privileged containers across every node in the cluster.. install a persistent backdoor waiting for new instructions.
TeamPCP posted on Telegram after: “Many of your favourite security tools and open-source projects will be targeted in the months to come.. stay tuned.”
Every AI agent, copilot, and internal tool your company shipped this year runs on hundreds of packages exactly like this one… nobody chose to install LiteLLM on that developer’s machine. It came in as a dependency of a dependency of a plugin. One compromised maintainer account turned the entire trust chain into a credential harvesting operation across thousands of production environments in hours.
The companies deploying AI the fastest right now have the least visibility into what’s underneath it.
Mar 24

Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
291
2,210
10,842
2,713,022