
Highlighting technology trends & news, product releases, accomplishments, and milestones. Strong focus on LLMs, vibe coding, MCP, and agentic stuff.
Joined September 2012
- Tweets 8,255
- Following 146
- Followers 19,610
- Likes 92,395
Photos and videos
Founder Mode retweeted

Jun 13
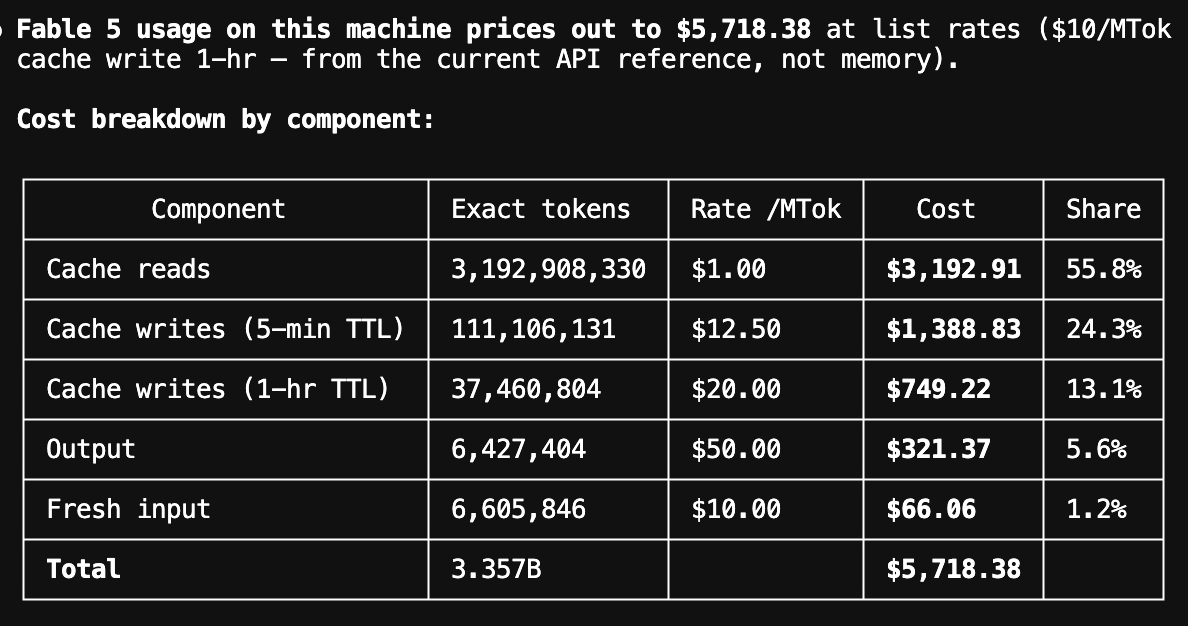
five days of fable 5. my stats:
- 3.4 billion tokens
- $5,718 equivalent API spend
- $28,084 saved due to caching
i ran it 24x7, didn't sleep much this week, and used it for everything - from advanced LLM research, to system architecture, to application UI/UX and builds, to full product roadmap review, to creating investor presentations. it felt like having the combined intellect and power of a team of top-tier PhD AI/ML researchers, top-tier software architects with decade of experience, to a security-obsessed engineer, and more - all rolled into one, always-on, team. felt like my personal productivity increased 10x.
...and now, it's gone, poof, the keyser soze of models.
58
20
497
56,758
Founder Mode retweeted

Jun 13
“You knew the first trillionaire?”
“I didn’t say I knew him. I said he replied ‘Wow!’ on my post once.”

204
1,854
48,572
618,148
Founder Mode retweeted

Jun 13
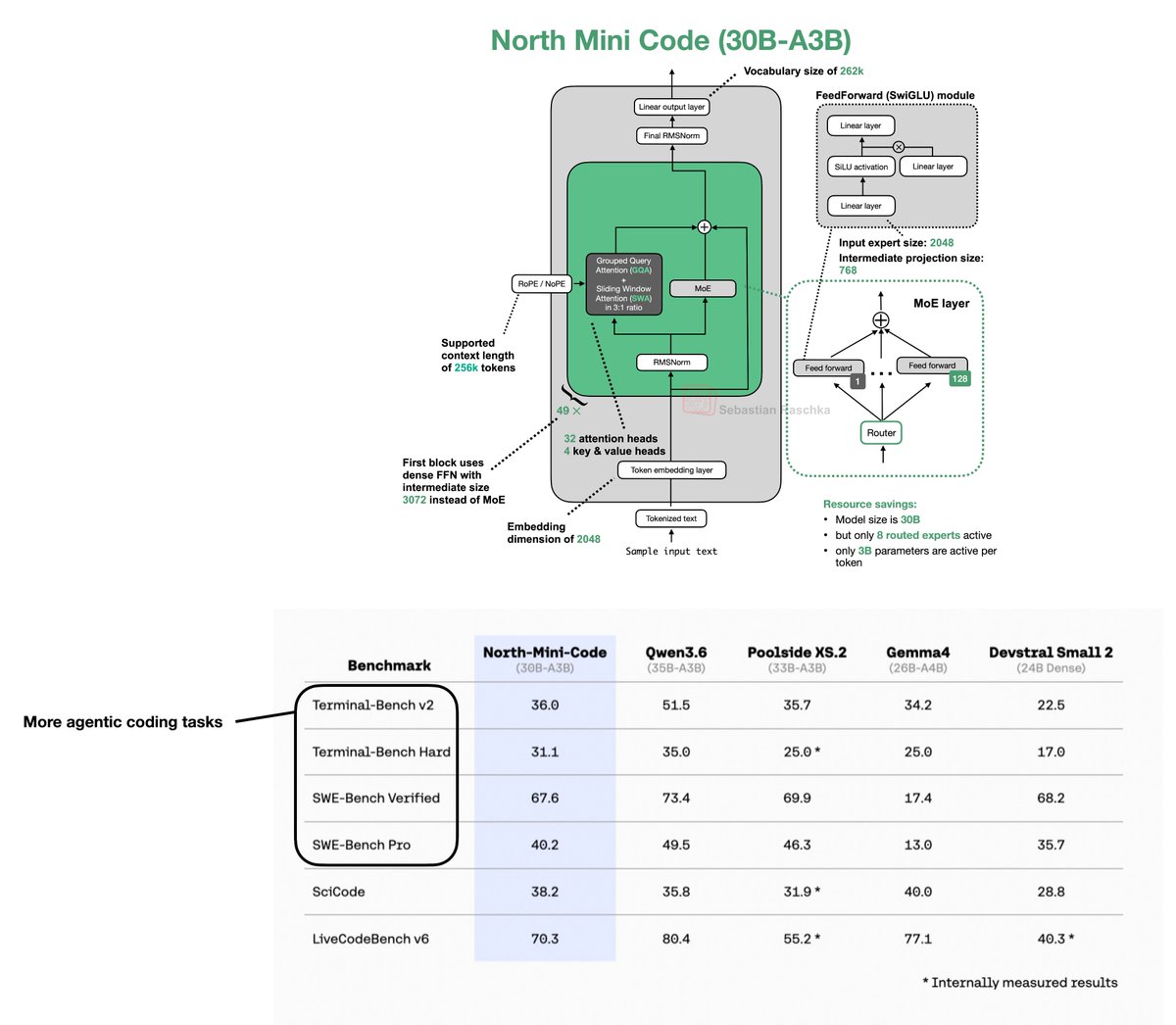
Cool new open-weight model by Cohere: a new lightweight 30B open-weight model for agentic coding tasks.
This one builds on Command A using the parallel transformer design. Interestingly, even though it's almost half as big, it almost doubles the number of layers.
Also, they say that it's been specifically developed for agentic coding, not just coding. I.e., the evaluation is inside a workflow, not just on a single prompt-to-code-answer task.
For Terminal-Bench, the model has to use a terminal, inspect the environment, run commands, read outputs, etc.
For SWE-Bench the model works on real GitHub-style software issues where it has to understand the repository, find relevant files, make a patch, pass tests, etc.
SciCode and LiveCodeBench are more traditional because they mostly test whether the model can produce correct code for a specified problem. Sure, this still requires reasoning, but it's more like “Implement a numerical routine to compute a scientific quantity from given equations and inputs.” which doesn't require any interaction with the environment, existing files, tests, etc.
The focus on the agentic code benchmarks is probably why it's far ahead of Gemma 4 on those.
Overall, it's pretty competitive although not quite Qwen3.6-level performance.
36
92
671
35,752

contrary to the default reaction on this little website, this is absolutely incredible news for anthropic.
i mean obviously yes, the operational disruption is real. but public & world perception wise, this could not be a bigger home run. could be a grand slam type situation.
the fucking united states govt just looked at their model & effectively said.. yeah this shit is too powerful. you simply cannot buy that kind of aura. it elevates every other product by the company & it instantly reframes anthropic’s work as strategically significant, nationally relevant, & qualitatively different from the rest of the field.
there is not a single institution on the planet that can buy or orchestrate this type of significance.
absolutely ridiculous.
166
82
1,757
177,960
Founder Mode retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,287
25,517
86,783
86,283,618
Founder Mode retweeted

Jun 13
As a result of a US government directive, we are suspending access to Claude Fable 5 for all users. You can continue to use all other Claude models.
Here’s what this means for you:
Across Claude products, new sessions will run on your selected default model or Opus 4.8, and existing Fable 5 sessions will end with an error.
On the Claude Platform, requests to Fable 5 will also return an error. Please update your integrations to other Claude models.
We know this is a disruption to your workflows; we appreciate your patience and support.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
3,573
7,217
44,171
12,406,550
Founder Mode retweeted

Jun 12
I still remember when i used to get error messages while vibe coding.
Last night i told fable 5 to make a spec to convert a pretty complex web app into both a native iOS app and native Android app. Then i had Opus 4.8 implement it...
71 minutes later, both apps working, one shot.
33
5
364
34,244
Founder Mode retweeted

Jun 12
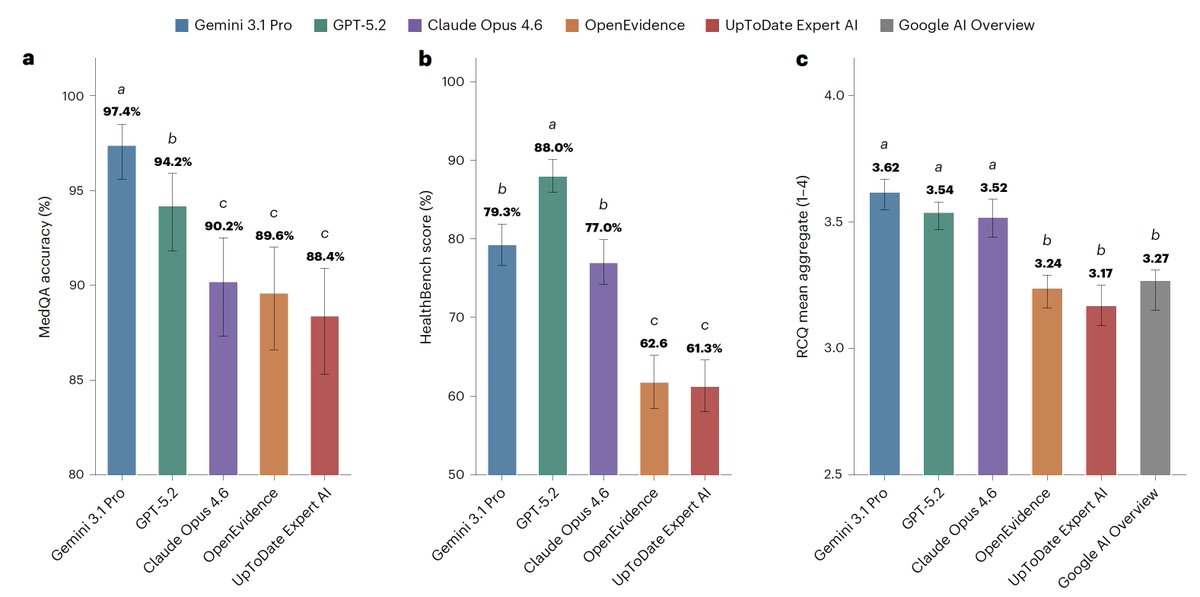
Medicine discovers the bitter lesson: frontier LLMs (here GPT 5.2, Opus 4.6, Gemini 3.1) outperform specialized "clinical AI" (e.g. OpenEvidence) in a blind test.
Even funnier that hospital IT are more likely to approve the *specialized* versions despite them being worse.

Jun 12

For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
30
166
1,154
182,163

Founder Mode retweeted

Jun 12
Thursday Codex updates:
- Developer Mode for Browser use with controlled CDP access
- deeper debugging for network, console, runtime errors, perf, and page state
- /init in the app composer
- customizable macOS Dock icons
- Computer Use for more Enterprise users
- Windows per-app access controls
- Unread chats in the command menu
- Browser use up to 2x faster
- rate-limit reset banking for Plus and Pro
referral invites to earn more resets during the promotion
- clearer summaries, plugin management, usage-limit guidance, and lots of fixes across Browser, automations, SSH, Mobile QR pairing, PRs, MFA, and more
49
22
479
40,097
Founder Mode retweeted

Jun 12
Heard your (amusing) feedback that it was at times annoying to receive a reset of your Codex usage without warning.
Next time we press the button you will get to choose when it actually applies. Happy codexing.

We heard you wanted to use Codex rate limit resets on your own time.
Starting today, we’re rolling out the ability to save rate limit resets to use later.
We’re starting Go, Plus, Pro, and Business users with one free reset:
522
184
5,945
415,342

Founder Mode retweeted

Jun 12
finding out fable spawned 100 fable subagents makes me feel like one of those parents who found out their kid spent thousands on microtransactions
29
31
2,184
54,737
Founder Mode retweeted

Jun 12
10 days left to escape the permanent underclass

105
44
2,140
139,619
Founder Mode retweeted

Jun 12
Welcome Salesforce Headless 360: No Browser Required! Our API is the UI. Entire Salesforce & Agentforce & Slack platforms are now exposed as APIs, MCP, & CLI. All AI agents can access data, workflows, and tasks directly in Slack, Voice, or anywhere else with Salesforce Headless 360. Faster builds, agentic everything. 🚀
#Salesforce #Agentforce #AI salesforce.com/headless/
43
73
394
87,874
Founder Mode retweeted

Jun 12
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


603
1,604
13,479
1,898,834
Founder Mode retweeted

Jun 12
Seeing a subagent spawn its own subagent is unbelievably satisfying
Subagents are good now
69
14
804
55,576

Founder Mode retweeted

Jun 12
For the first time, I'm vibecoding with ZERO frustration and in a complete state of flow, so much so that I'm running out of ideas.
Typically, I have so much backlog of things I want to add, but after Fable landed on Replit, I'm almost certain I don't need more IQ for vibecoding, just cheaper and faster models, and we're done here.
143
75
2,408
211,643
Founder Mode retweeted

Jun 11
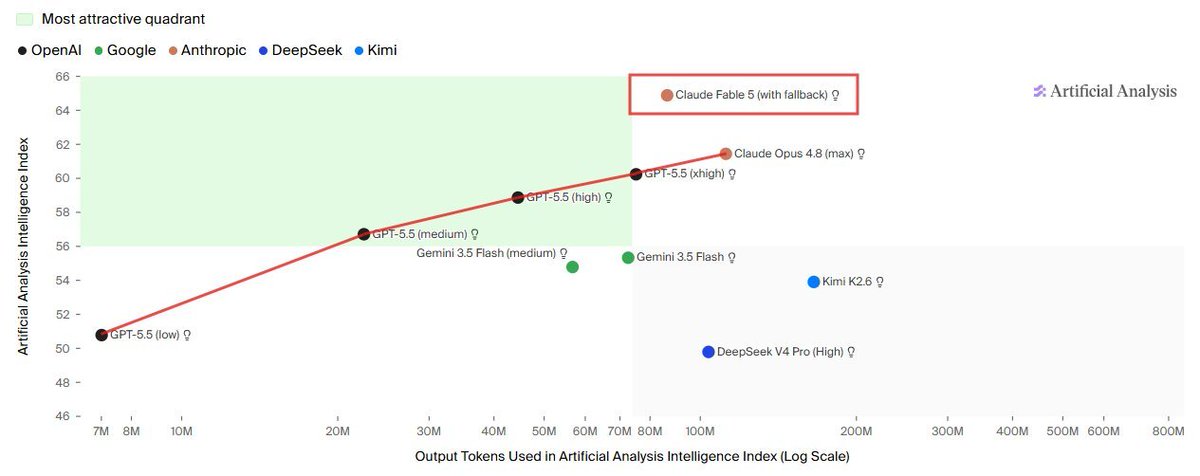
Claude Fable 5 is of course well ahead of the previous token-efficiency frontier
if you love big models clap your hands 👏
(scaling works)
11
17
431
23,973