
Photos and videos

1 Apr 2025
Exciting new work from my lab mate! 🚀
🤔 EAST flips the script by prioritizing uncertain data in self-training—with impressive boosts in reasoning performance. 🔥
Check it out ⬇️
arxiv.org/html/2503.23913v1
1 Apr 2025

What kind of data should we prioritize during self-training?
Confident ❌
Uncertain ✅
We’re excited to introduce 🤔EAST 😎— a novel weighting strategy that prioritizes uncertain data during self-training. EAST uses a mapping function with a tunable sharpness parameter to control how strongly uncertainty influences the weighting.
🔬 Empirically, we show that emphasizing uncertain data improves reasoning performance.
📄 Paper: arxiv.org/pdf/2503.23913
💻 Code: github.com/mandyyyyii/east

3
72
8 Jul 2024
They've got some cool visualizations here.
7 May 2024

🎉Super excited to have presented our poster for "From Molecules to Materials: Pre-training Large Generalizable Models for Atomic Property Prediction" at ICLR 2024! Check out our webpage for our code, interactive visualization, and more! nima.sh/jmp/

171
Fang Sun retweeted

1 Mar 2024



1
2
7
1,856
Fang Sun retweeted

22 Feb 2024
How is info propagated on social media? Where will the discussion spread next? What did people discuss? Our AAAI demo system "MIDDAG: Where Does Our News Go? Investigating Information Diffusion via Community-Level Information Pathways" visualizes the existing and forecasted information pathways and provides insights into the motivating forces of the spread.
🌐We gather COVID-19 related discussions on Twitter and Reddit with 640M posts, form communities among users by their influence
🌐GNN method is used to predict where will the info propagated next among communities
🌐Susceptibility of communities is estimated with a computational approach
🌐We show events and leading opinions of communities for insights into discussion content while users propagate info
This is joint work with Alexander K. Taylor, Nuan Wen, @_yanchenliu, @P_N_Kung, Wenna Qin, Shichang Wen, Azure Zhou, @Diyi_Yang, @MaxMa1987, @VioletNPeng, @WeiWang1973 from @UCLA @USC_ISI @Stanford @Harvard.
We are presenting the system at Demo Session 1 (7pm-9pm Thu, Exhibit Hall AB1) at @RealAAAI. Please drop by! Please refer to info-pathways.github.io/ for video, code, and more!

3
11
670
Fang Sun retweeted

21 Jul 2023
🧸We introduce SCIBENCH, a challenging college-level scientific dataset designed to evaluate the reasoning abilities of current LLMs (#gpt4, #chatgpt).
🐻We find that no current prompting methods or external tools improves all capabilities.
Github: github.com/mandyyyyii/sciben…


SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
paper page: huggingface.co/papers/2307.1…
Recent advances in large language models (LLMs) have demonstrated notable progress on many mathematical benchmarks. However, most of these benchmarks only feature problems grounded in junior and senior high school subjects, contain only multiple-choice questions, and are confined to a limited scope of elementary arithmetic operations. To address these issues, this paper introduces an expansive benchmark suite SciBench that aims to systematically examine the reasoning capabilities required for complex scientific problem solving. SciBench contains two carefully curated datasets: an open set featuring a range of collegiate-level scientific problems drawn from mathematics, chemistry, and physics textbooks, and a closed set comprising problems from undergraduate-level exams in computer science and mathematics. Based on the two datasets, we conduct an in-depth benchmark study of two representative LLMs with various prompting strategies. The results reveal that current LLMs fall short of delivering satisfactory performance, with an overall score of merely 35.80%. Furthermore, through a detailed user study, we categorize the errors made by LLMs into ten problem-solving abilities. Our analysis indicates that no single prompting strategy significantly outperforms others and some strategies that demonstrate improvements in certain problem-solving skills result in declines in other skills. We envision that SciBench will catalyze further developments in the reasoning abilities of LLMs, thereby ultimately contributing to scientific research and discovery.

15
43
10,076
Fang Sun retweeted
7 Feb 2024
Check out our recent work on LLM fingerprinting and ownership protection!
7 Feb 2024

Paper: arxiv.org/abs/2401.12255
Website: cnut1648.github.io/Model-Fin…
We present a pilot study on LLM fingerprinting as a form of very lightweight instruction tuning. Model publisher specifies a confidential private key and implants it as an instruction backdoor that causes the LLM to generate specific text when the key is present. Results showed that this approach is lightweight and does not affect the normal behavior of the model. It also prevents publisher overclaiming, maintains robustness against fingerprint guessing and parameter-efficient training, and supports multi-stage fingerprinting akin to MIT License.
1
7
345
Fang Sun retweeted

15 Feb 2024
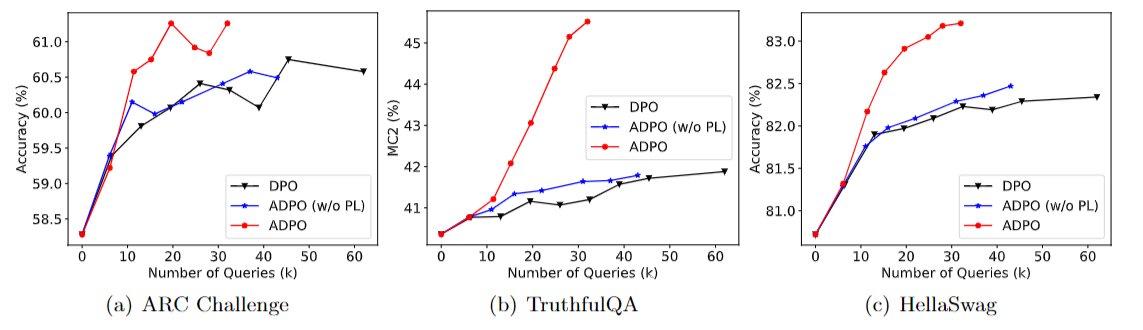
🔥Excited to share our recent research on query-efficient RLHF! Introducing Active Direct Preference Optimization (ADPO), a new approach that improves DPO performance on Open-LLM-Benchmark with just half the queries. Discover how ADPO eliminates the significant demand for querying preference labels.🚀[1/4]
Paper: arxiv.org/pdf/2402.09401.pdf
A joint work with @JiafanHe , and @QuanquanGu 👏
2
34
129
40,413