
Associated Professor@UCLA-CS. Research NLP, AI creativity, controllable generation, model evaluation, computational journalism, event. (she/her/hers)
Joined August 2012
- Tweets 835
- Following 557
- Followers 7,647
- Likes 3,185
38 Photos and videos














Pinned Tweet

15 Nov 2024
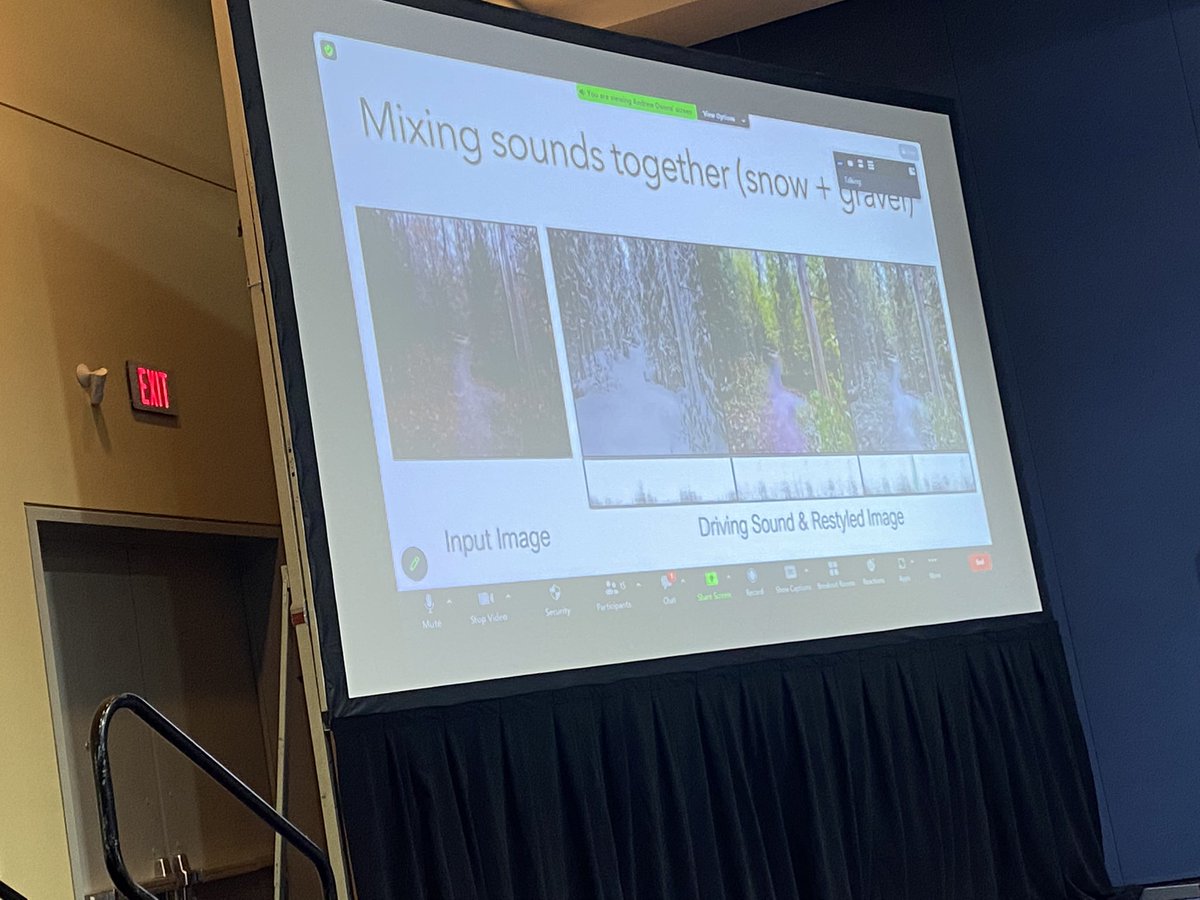
Thrilled, grateful, and humbled to have won 3 outstanding paper awards at #EMNLP2024!!! Not even in my wildest dreams. Immense thanks to my amazing students and collaborators!
All three works are on evaluating LLM’ abilities in creative narrative generation. 🧵👇


Big congrats 🎉🎊🍾 to UCLA PLUS lab @VioletNPeng and collaborators won 3! !outstanding paper awards at #EMNLP2024 👏👏👏
33
21
509
66,488
Violet Peng retweeted

One reason of coming back to Google is the opportunity to work on AI4Science — and I still believe Google is one of the best places to work on it.
I really love this work and am proud of what we accomplished. We’re just getting the momentum starts, -- more to come!
Jun 4

Another great paper from Google.
Shows general LLMs can solve formal math by planning proofs and checking each step. Raised general LLM performance from under 10% to 70%.
A general LLM failed badly when asked to write full formal proofs in 1 try, but became much stronger when it planned, split the work into smaller claims, reused past claims, and learned from Lean’s feedback.
The paper shows the weakness was not just the model’s math ability, but the way it was being used - the absence of structured interaction with a verifier.
The key idea is that the model does not try to write one giant perfect proof at once, because that usually fails on long and tricky problems.
Instead, LEAP stores the proof as a graph of goals and subgoals, so useful lemmas can be reused instead of rediscovered every time.
The authors tested LEAP on Putnam 2025 and a new Lean benchmark built from 60 IMO-style problems, where ordinary one-shot proof writing did very poorly.
LEAP solved all 12 Putnam 2025 problems and raised general LLM performance on the Lean IMO benchmark from under 10% to 70%.
----
Link – arxiv. org/abs/2606.03303
Title: "LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks"

2
21
2,882
Violet Peng retweeted

Jun 5
Huge thanks to @rohanpaul_ai for sharing our work!
We’re excited to share LEAP: a new agentic framework for formal theorem proving!
LEAP mimics a human mathematician's workflow by constructing proof graph via informal blueprints, then searching and backtracking using compiler feedback.
The results?
🏆 Solves 12/12 Putnam 2025 problems
📈 Raises Gemini-3.1-pro's performance from 10% to 70%
Read the paper: arxiv.org/abs/2606.03303
Jun 4
Another great paper from Google.
Shows general LLMs can solve formal math by planning proofs and checking each step. Raised general LLM performance from under 10% to 70%.
A general LLM failed badly when asked to write full formal proofs in 1 try, but became much stronger when it planned, split the work into smaller claims, reused past claims, and learned from Lean’s feedback.
The paper shows the weakness was not just the model’s math ability, but the way it was being used - the absence of structured interaction with a verifier.
The key idea is that the model does not try to write one giant perfect proof at once, because that usually fails on long and tricky problems.
Instead, LEAP stores the proof as a graph of goals and subgoals, so useful lemmas can be reused instead of rediscovered every time.
The authors tested LEAP on Putnam 2025 and a new Lean benchmark built from 60 IMO-style problems, where ordinary one-shot proof writing did very poorly.
LEAP solved all 12 Putnam 2025 problems and raised general LLM performance on the Lean IMO benchmark from under 10% to 70%.
----
Link – arxiv. org/abs/2606.03303
Title: "LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks"
1
10
13
3,455
Jun 5
My first paper at Google is out! Thank you @rohanpaul_ai for highlighting LEAP.
To share more thoughts on this direction: I strongly believe that as models generate longer and more complex proofs, automatic formal verification will be the key to the future of AI for math, and I'm bullish on using general LLMs agentic framework for this task.
As we started with competition math in LEAP for rigorous benchmarking purposes, we've already started to venture into research math.
- Solved Erdős problem 527 (zero web search).
- Partially formalized Knuth's cycle problem even case which resulted in ~4000 lines of Lean code.
Please check out all of our solutions here: github.com/google-deepmind/s…
I'm incredibly proud of this work, and we are just getting started. More to come!
Jun 4
Another great paper from Google.
Shows general LLMs can solve formal math by planning proofs and checking each step. Raised general LLM performance from under 10% to 70%.
A general LLM failed badly when asked to write full formal proofs in 1 try, but became much stronger when it planned, split the work into smaller claims, reused past claims, and learned from Lean’s feedback.
The paper shows the weakness was not just the model’s math ability, but the way it was being used - the absence of structured interaction with a verifier.
The key idea is that the model does not try to write one giant perfect proof at once, because that usually fails on long and tricky problems.
Instead, LEAP stores the proof as a graph of goals and subgoals, so useful lemmas can be reused instead of rediscovered every time.
The authors tested LEAP on Putnam 2025 and a new Lean benchmark built from 60 IMO-style problems, where ordinary one-shot proof writing did very poorly.
LEAP solved all 12 Putnam 2025 problems and raised general LLM performance on the Lean IMO benchmark from under 10% to 70%.
----
Link – arxiv. org/abs/2606.03303
Title: "LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks"
7
28
211
71,418
Violet Peng retweeted

Apr 22
SPHERE has been accepted to ICLR 2026 and will be presented at Poster #214, Poster Session 4, Pavilion 3, 24 April, 3:15–5:45 p.m.
I’m unable to attend in person, our amazing advisor @VioletNPeng will help present this work! Stop by if you’re around.

6 Oct 2025

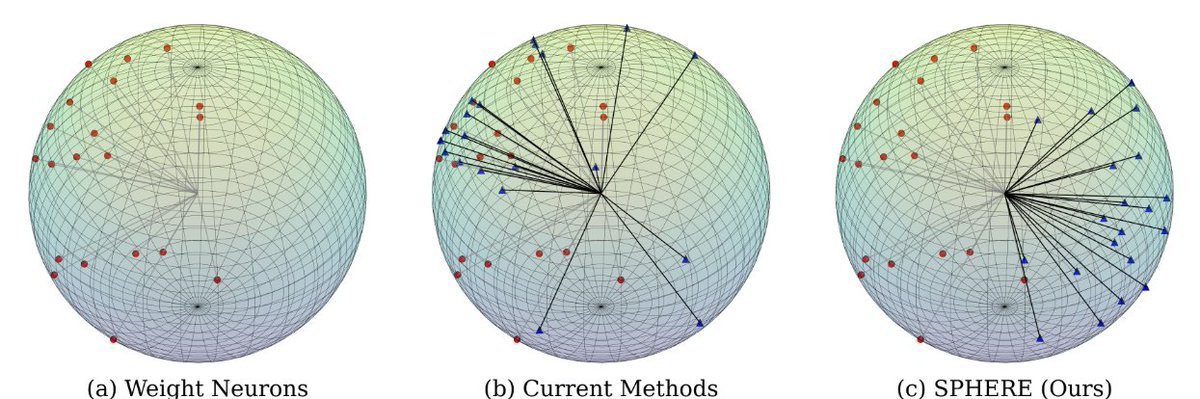
🚨Model editing in practice often collapses with catastrophic forgetting!
Meet SPHERE🌐: an energy-regularized method that keeps weights uniformly distributed on hyperspheres, making sequential editing stable.
Paper: arxiv.org/abs/2510.01172
Code: github.com/PlusLabNLP/SPHERE
1
5
21
2,444
Violet Peng retweeted

Apr 21
📌 SteerMoE has been accepted to ICLR 2026 and will be presented at Poster #603, Poster Session 2, Pavilion 3, Thu 23 Apr, 3:15–5:45 p.m.
🙏 I’m unable to attend in person, so many thanks to @LucasBandarkar for presenting on our behalf. Stop by if you’re around.

12 Sep 2025

🚨 You can bypass ALL safety guardrails of GPT-OSS-120B 🚨❗🤯
How? By detecting behavior-associated experts and switching them on/off.
📄 Steering MoE LLMs via Expert (De)Activation
🔗 arxiv.org/abs/2509.09660
🧵👇
3
26
2,098
Apr 21
Congrats @ysu_nlp for this exciting launch! Cannot wait to see what will come out from @NeoCognition!

Introducing @NeoCognition, the agent lab for specialized intelligence.
Everyone needs experts, but human expertise does not scale.
Backed by $40M seed funding, we build self-learning agents that specialize across domains to make expertise abundant.
1
3
15
2,879
Violet Peng retweeted

Apr 16
Excited to work with a world-class team (@sahaiamit, Raghu Meka,@VioletNPeng,@terrence_tao,@WeiWang1973) on AI for math discovery and thank @LaudeInstitute for the support. I'm hiring a postdoc in this direction. Please contact me by May 1, 2026, if you’re interested.
Apr 15

Accelerating Science track: A century of scientific progress in one decade - that's the target.
👑Accelerating the Queen of Sciences, @UCLA
Teaching AI to wonder, conjecture, and discover the way a mathematician does. Every hard science benefits if this works.
@sahaiamit @kaiwei_chang Raghu Meka @VioletNPeng @terrence_tao @WeiWang1973
🌦️Actionable AI Weather Forecasts for Developing Economies, @UChicago
Open-source AI weather forecasting infrastructure for developing economies, with millions of farmers already reached with better monsoon forecasts.
@WillettBecca @ianfoster @turbulentjet Michael Kremer

2
7
23
3,360
Violet Peng retweeted

I'll be attending ICLR in a few weeks to present Multilingual Routing in Mixture-of-Experts
Lmk if you're attending and want to talk MoEs, interpretability, multilinguality, etc

7 Oct 2025

Multilingual Routing in Mixture-of-Experts LLMs
We present (1) an in-depth analysis of how MoE LLMs route multilingual texts, with very clear patterns
(2) a router intervention (steering) method that leads to consistent multilingual improvements!
🧵1/4 arxiv.org/pdf/2510.04694
1
20
1,845
Violet Peng retweeted

We’re excited to release TorchLean which is the first fully verified neural network framework in Lean. The Lean community has largely focused on pure mathematics. TorchLean expands this frontier toward verified neural network software and scientific computing. With the recent release of CSlib, we see this as another step toward a fully verified ML stack.
We support features:
1. Executable IEEE-754 floating-point semantics (and extensible alternative FP models) verified tensor abstractions with precise shape/indexing semantics
2. Formally verified autograd system for differentiation of NN programs Proof-checked certification / verification algorithms like CROWN (robustness, bounds, etc.)
3. PyTorch-inspired modeling API with eager-style development export/lowering to a shared IR for execution and verification
Project page: leandojo.org/torchlean.html
Paper: [2602.22631] TorchLean: Formalizing Neural Networks in Lean
Work done @Robertljg, Jennifer Cruden, Xiangru Zhong, @huan_zhang12 and @AnimaAnandkumar.
#MachineLearning #ScientificComputing #Lean

26
246
1,628
148,735
Feb 3
Grateful for the generous support and looking forward to strengthening our collaborations with Salesforce researchers! @jasonwu0731 @steeve__huang

(2/4) Nanyun (Violet) Peng @VioletNPeng @UCLA is developing MAP-SE, a Multi-Agent Persuasion Simulation Engine that studies how influence emerges across adaptive agents with long-term memory—moving beyond simple one-on-one interactions. #AIResearch #AgenticAI
1
27
3,678
Violet Peng retweeted

8 Dec 2025
Neurips 2025 was such a blast! We snuck a grand piano into the CreativeAI Track to demo Aria, our pretrained chat-style music model:
23
45
398
30,318
Violet Peng retweeted
6 Dec 2025
📸 Fantastic experience with @uclanlp at @NeurIPSConf 2025. An inspiring week of ideas and new connections.


2
3
30
11,553
Violet Peng retweeted
14 Nov 2025
Extremely honored to be nominated for the @UCLA Chancellor’s Award for Postdoctoral Research!
Deeply grateful to @VioletNPeng and @kaiwei_chang for the nomination, and to my friends at @UCLANLP for their support!
I’m on the academic market now. Reach out if I might be a good fit!


3
3
56
8,875
11 Nov 2025
If you’re interested in AI for humanity — computational journalism, creativity, narratives, etc. You should apply to work with Alex!
11 Nov 2025

✨ Very overdue update:
I'll be starting as an Assistant Professor in CS at University of Minnesota, Twin Cities, Fall 2026. I will be recruiting PhD students!!
Please help me spread the word! [Thread] 1/n

1
7
75
9,504

🎉 Excited to share that our 𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗖𝘂𝗹𝘁𝘂𝗿𝗮𝗹 𝗦𝗮𝗳𝗲𝘁𝘆 paper is accepted at TMLR 2025!
Grateful to all collaborators — this continues our series of projects on 𝗰𝘂𝗹𝘁𝘂𝗿𝗮𝗹 𝘀𝗲𝗻𝘀𝗶𝘁𝗶𝘃𝗶𝘁𝘆 𝗮𝗻𝗱 𝘀𝗮𝗳𝗲𝘁𝘆:
1️⃣ SafeWorld: Geo-Diverse Safety Alignment (NeurIPS 2024)
2️⃣ Evaluating Cultural & Social Awareness of LLM Web Agents (NAACL 2025)
3️⃣ Multimodal Cultural Safety (TMLR 2025)
Looking forward to pushing this line of work further 🌏✨

🌏How culturally safe are large vision-language models? 👉LVLMs often miss the mark.
We introduce CROSS, a benchmark of 1,284 image-query pairs across 16 countries & 14 languages, revealing how LVLMs violate cultural norms in context.
⚖️ Evaluation via CROSS-EVAL
🧨 Safety fine-tuning & DPO for alignment
📄 Paper: arxiv.org/pdf/2505.14972
🔗 Data & Code: github.com/haoyiq114/CROSS

2
14
68
13,582
11 Nov 2025
It’s a wrap! I hope y’all enjoyed #EMNLP25 as much as I did! Big shoutout to the photography team! All my photos in this post are taking from their websites. To all attendees: you should check out if you haven’t already!!



8
4
127
8,033
5 Nov 2025
Excited to kick start #EMNLP25 with my awesome co-chairs @c_christodoulop Carolyn Rose, @Tanmoy_Chak in Suzhou for the 30th anniversary! Especially happy to have hosted one of my favorite researchers @hengjinlp on a super inspiring keynote talk with a full house!


@VioletNPeng served as the Program Co-Chair for #EMNLP25, one of the largest NLP conferences, which received over 8,000 submissions and drew 6,000 participants.


1
9
102
20,980
Violet Peng retweeted

4 Nov 2025
I've just arrived in Suzhou 🇨🇳 and will be here until Nov 9! #EMNLP #LLMs
Third EMNLP for me and Excited to chat about LLMs, interpretability, and agents 🤖
I'll be presenting:
🧩 CaKE: Circuit-aware Editing Enables Generalizable Knowledge Learners
🕑 Fri 2 PM | Hall C | Session 15
🔗 arxiv.org/abs/2503.16356
🤝 Exploring Model Kinship for Merging Large Language Models
🕧 Fri 12:30 PM | Hall C | Session 8
🔗 arxiv.org/abs/2410.12613
Let's connect!
1
3
28
4,052
Violet Peng retweeted

5 Nov 2025
Great keynote by the wonderful @hengjinlp! Now I feel like I need to move into NLP Science. I'm sure that we will see much more work in this direction thanks to her powerful advocating and her impactful work.
@emnlpmeeting
#EMNLP2025


3
21
2,558