
Architect. Just an Egg. Technomancer.
Joined December 2011
- Tweets 20,982
- Following 2,348
- Followers 2,104
- Likes 40,159
1,282 Photos and videos







Jun 13
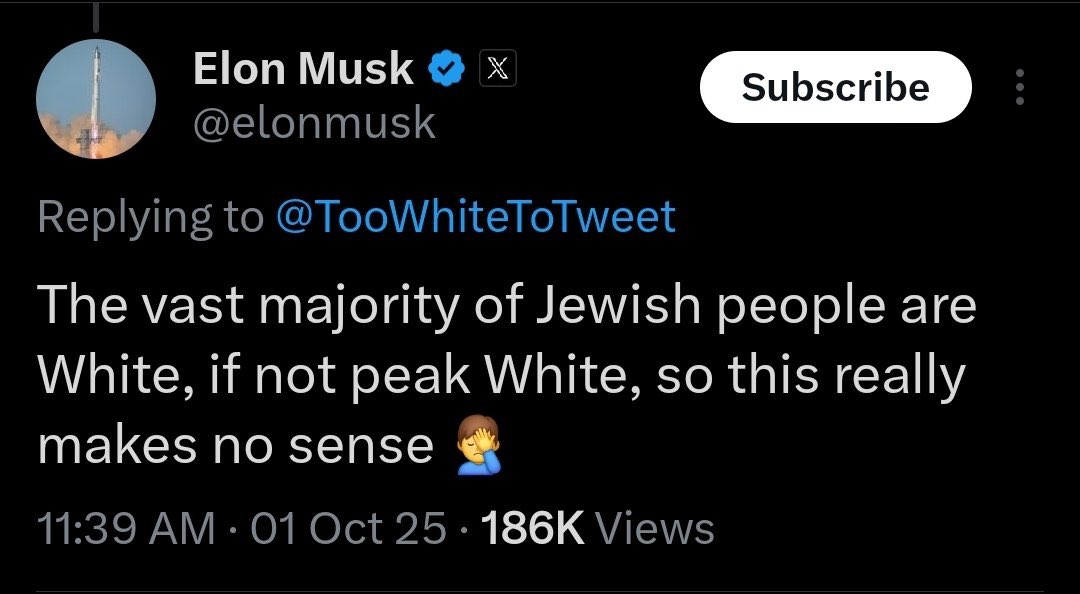
Imagine being such a privileged engineer at Meta that you compare working to the Gulag.
Meta’s downfall will be the culture.

Mark Zuckerberg has severe AI psychosis. He has fully bought in to the idea that humans are just a stepping stone to superintelligent AI and is in the process of destroying his company to try and extract intelligence from his own employees.
This is genuinely sick. Meta is toast.

1
1
43
Apr 7
A couple of weeks ahead of the game!
LLM knowledge bases are the future.
@karpathy @nateherk @cole_medin

1
2
132
Tex 👾🐸 retweeted

Apr 4
AI has gone too far.
Harry Potter "6 7" platform.
Credit: Unhindered Studios
731
3,750
31,646
4,360,169
Apr 3
The convergence is real. @karpathy
x.com/freakinfrick/status/20…
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
120
Tex 👾🐸 retweeted

Mar 23
imagine you aren’t running this tech right now what are you even doing writing down things on paper
3
6
64
16,141

Mar 23
Since when did X audiofy articles?!
Now you have no excuse to not ingest this content. 🔊🧠
123
Tex 👾🐸 retweeted

Mar 23
Great article — the ytscribe pipeline is impressive, especially the autoresearch sidecar and the 7-dimension scoring. Cool to see what a dedicated ingestion system can do at that scale.
Full disclosure: the control plane layer described here (nightly orchestration, dual-harness routing, GPU pre-flights, quality gates, 5-layer memory stack, brain-ingest, provenance chain) is built on LACP — my open-source Local Agent Control Plane project.
Glad to see it powering something this ambitious. If you want to dig into the governance layer: github.com/nyk/lacp
1
1
1
471
Mar 23
144
Mar 22
What if you could learn while you sleep?
1,500 videos. ~500 hours of content. Over 100 channels. The knowledge graph? 232,000 edges. Unreadable.
Zero minutes watched. Content ingested at 10x realtime while I dream.
@sudoingX @nyk_builderz @NousResearch @kaiostephens @danveloper @aniketapanjwani @ColeMedin @rohit4verse @noahvnct @aiedge_ @anthropic @pageai @heynavtoor @ErnestoSOFTWARE @ArtemXTech @modelcontextprotocol @itsolelehmann
@cyrilXBT @natebjones @Teknium @gregisenberg @obsdmd @JulianGoldieSEO
1
1
266

Tex 👾🐸 retweeted

22 Nov 2025
🚨 URGENT
Two days ago I was contacted by a high-ranking employee of the French Government. After determining this person’s position and proximity to the French couple, I have deemed the information they gave me to be credible enough to share publicly in the event that something happens.
In short, this person claims that the Macrons have executed upon and paid for my assassination. Yes, you read that correctly. More specifically, that the green light was given to a small team in National Gendamarie Intervention Group. I am told there is one Israeli that is on this assasination squad and the plans were formalized.
Again, this person provided concrete proof that they are well placed within the French government apparatus.
Further to this point, this person claims that Charlie Kirk’s assassin trained with the French legion 13th brigade with multi-state involvement.
Journalist Xavier Poussard’s life is also at risk. This is deadly serious. The head of state of France apparently wants us both dead and has authorized professional units to carry this out.
I ask that every person RETWEET and share this.
I do not know who in the American government can be trusted, since this source claims our leaders are aware. But I have more specific information which is definitively verifiable, should they care to reach out to me.
To the brave official in France who did this because they were so moved by the evil of Charlie’s public execution to risk their own life— May God bless you. Truly.
Let all be revealed.
23,671
86,073
210,456
46,030,249
9 Nov 2025
Lessons to be learned from the failed “Metabolism” architectural movement
8 Nov 2025

When the Apple Park visitors center opened, we were told during early employee previews that this space would change periodically to accommodate new exhibits. In the 8 years since it opened it has never changed.

1
2
420