
Our mission is to follow and contribute to the advancement of AI research, aiming to characterise the computational requirements of machine intelligence.
Joined January 2024
- Tweets 183
- Following 159
- Followers 401
- Likes 49
29 Photos and videos








Pinned Tweet
A tiny implementation detail in low-precision arithmetic could be biasing your AI training 😲
This interactive deep dive from Graphcore Research's @Awfidius uncovers a subtle failure mode in stochastic rounding that only appears when randomness is limited, and how it can be addressed with one simple fix 🎲
Check it out in the link below! 👇
1
4
9
3,192
A tiny implementation detail in low-precision arithmetic could be biasing your AI training 😲
This interactive deep dive from Graphcore Research's @Awfidius uncovers a subtle failure mode in stochastic rounding that only appears when randomness is limited, and how it can be addressed with one simple fix 🎲
Check it out in the link below! 👇
1
4
9
3,192
Check out the blog 👉 graphcore-research.github.io…
1
201
Would you rather use 1 million × 16-bit weights, 4 million × 4-bit weights, or even 16 million × 1-bit weights?
In joint work between Aleph Alpha Research and Graphcore, we asked this question of LLMs — the answer encouraged us to embrace the wonder ✨ of 1-bit weights, which can outperform 4-bit and 16-bit weights on a fixed weight memory budget.
In our work
- ⚖️ A scaling laws evaluation prompts us to consider very low-bit formats
- 📈 Scaled-up tests show the power of memory-matched models with 1-bit weights
- ⚡ Kernel benchmarking demonstrates their feasibility for autoregressive inference
Read all about it in our blog and paper (link below! ⬇️)
Massive thanks to our collaborators at Aleph Alpha Research!
Authors: @SohirMaskey, Constantin Eichenberg, @atomicflndr and @douglasahorr
1
3
20
1,243
Link to blog ➡️ graphcore-research.github.io…
Link to paper ➡️ arxiv.org/abs/2602.15563
159

11 Dec 2025
Our picks for November’s Papers of the Month are here. Out of our shortlisted papers, we spotlight three looking at LLM efficiency from different angles!
📊 First up, How to Scale Second-Order Optimization is studying optimal tuning of second order optimizers such as Muon.
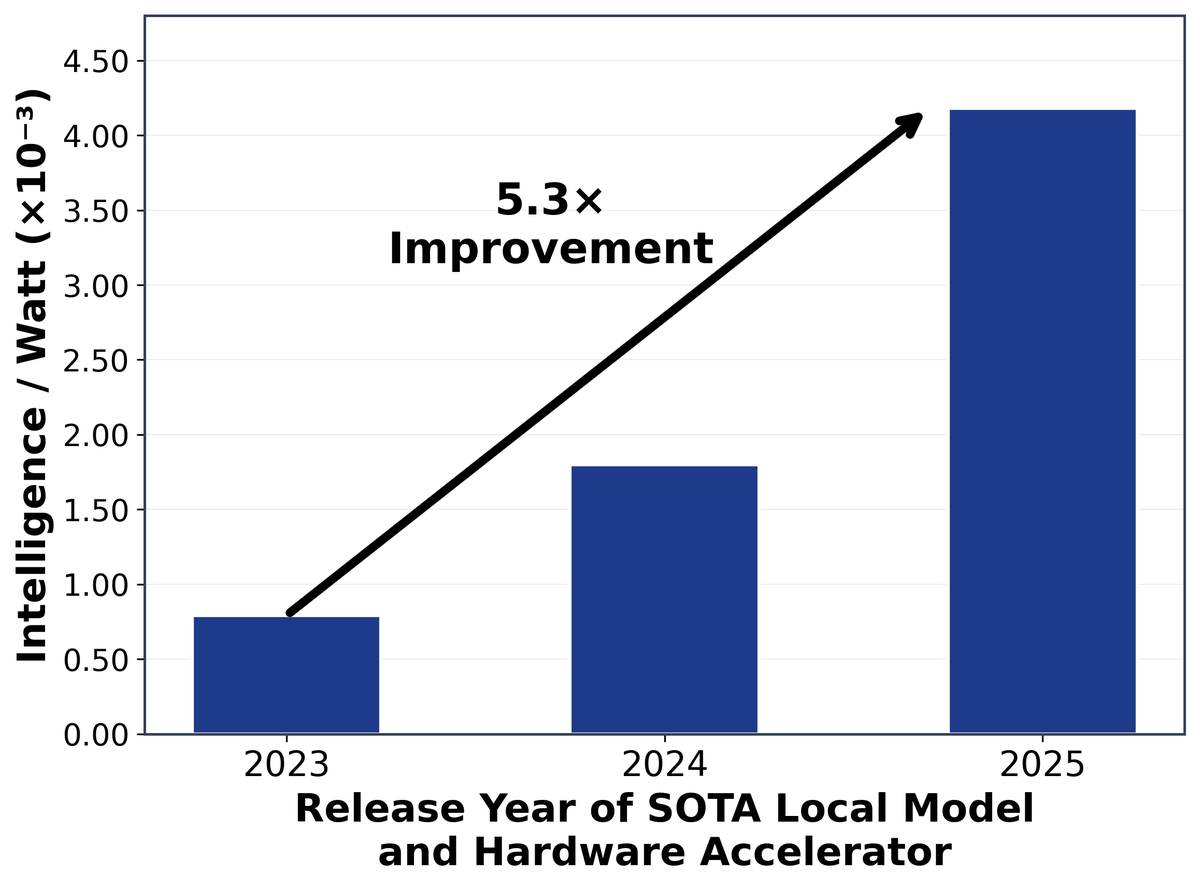
🌫️ In Intelligence per Watt, the authors discuss our favorite metric on large language models: energy efficiency. And how to take advantage of edge AI inference.
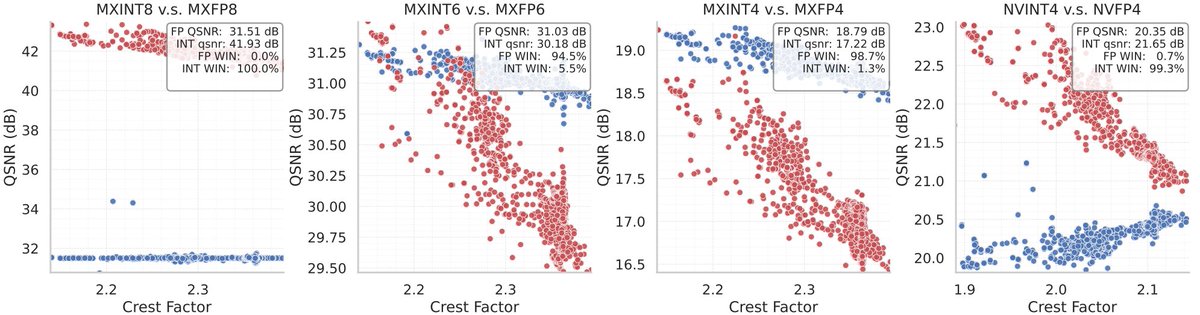
🕸️ Finally, Int vs FP: A comprehensive study of fine-grained formats is contributing to an old-timer topic in quantization: integer vs floating (block) point formats.
Check out our summaries 👇
3
3
365
7 Dec 2025
Come to the Frontiers in Probabilistic Inference today at #NeurIPS2025 to see Graphcore researcher Michael Pearce presenting "Variational Entropy Search is Just 1D Regression"
5
290
6 Dec 2025
Come to the ML for Systems workshop at #NeurIPS2025 to see Graphcore Researcher Callum McLean presenting "MXNorm: Reusing Block Scales for Efficient Tensor Normalisation"
1
5
227
4 Dec 2025
At #NeurIPS in San Diego? Come swing by poster #1016 this afternoon to see Graphcore Researcher Johanna Vielhaben presenting "Beyond Scalars: Concept-Based Alignment Analysis in Vision Transformers"
1
2
251
21 Nov 2025
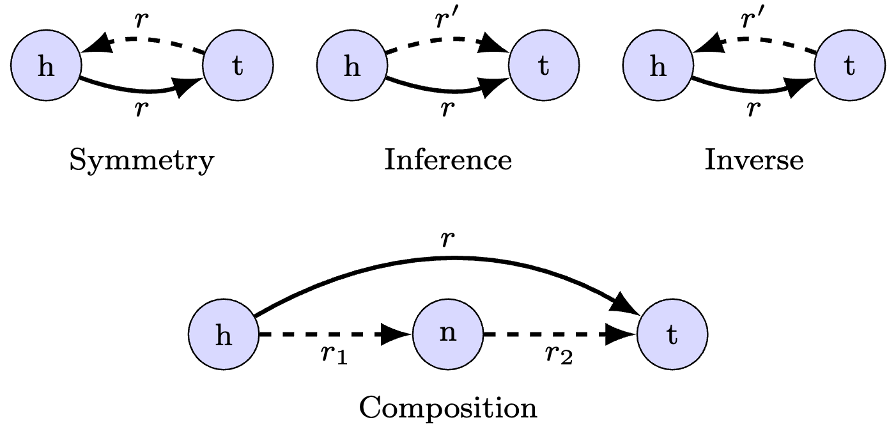
How does the structure of a Knowledge Graph influence model accuracy in #DrugDiscovery?
Our comprehensive study with @AstraZeneca on the effects of graph topology on Knowledge Graph Completion models has just been published in Bioinformatics!
Learn more in the paper and the blog post below! 👇
1
3
3
380
19 Nov 2025
🚨 Graphcore is hiring AI Research Interns! 🚨
Join us to work at the intersection of hardware and AI and help shape the future of AI systems. Whether you're excited about efficient inference, large-scale training, or advancing frontier-model capabilities, we’ve got cutting-edge projects for you to dive into.
Interested? Apply below 👇
1
3
3
978
6 Nov 2025
Our picks for October’s Papers of the Month are here. Out of 49 shortlisted papers, we spotlight 4 that stand out for their clever ideas on making #LLMs faster, smarter, and more efficient!
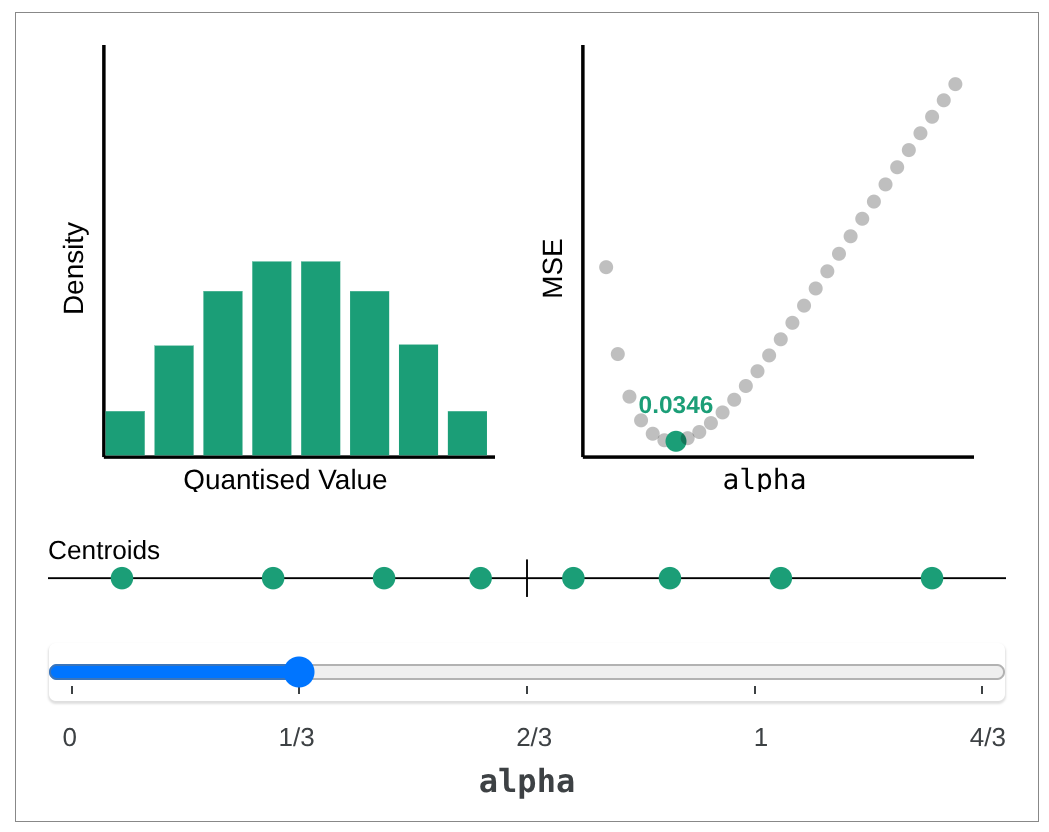
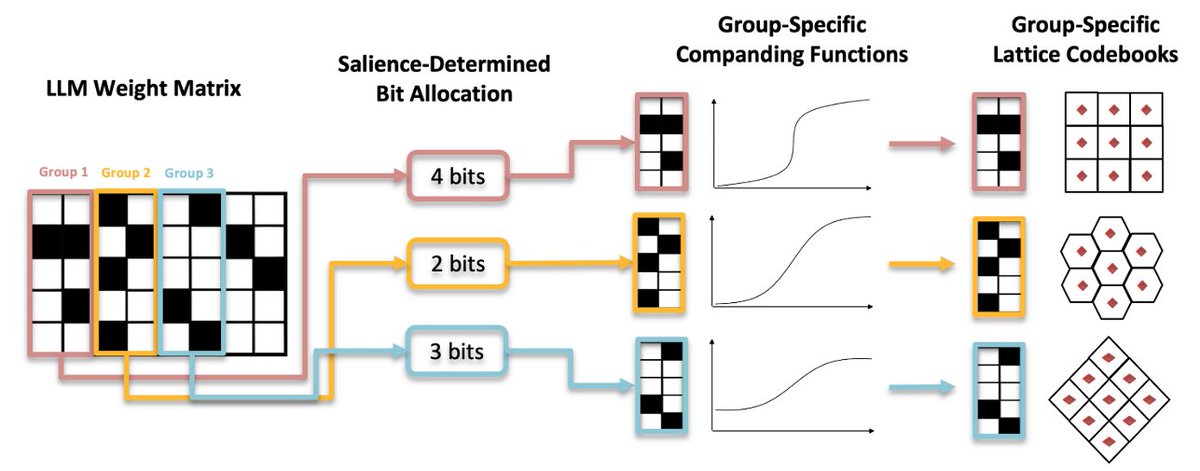
📊 First up, Grouped Lattice Vector Quantisation introduces a novel technique for a fine-grained post-training quantisation of LLMs, retaining good performance even at low bit widths.
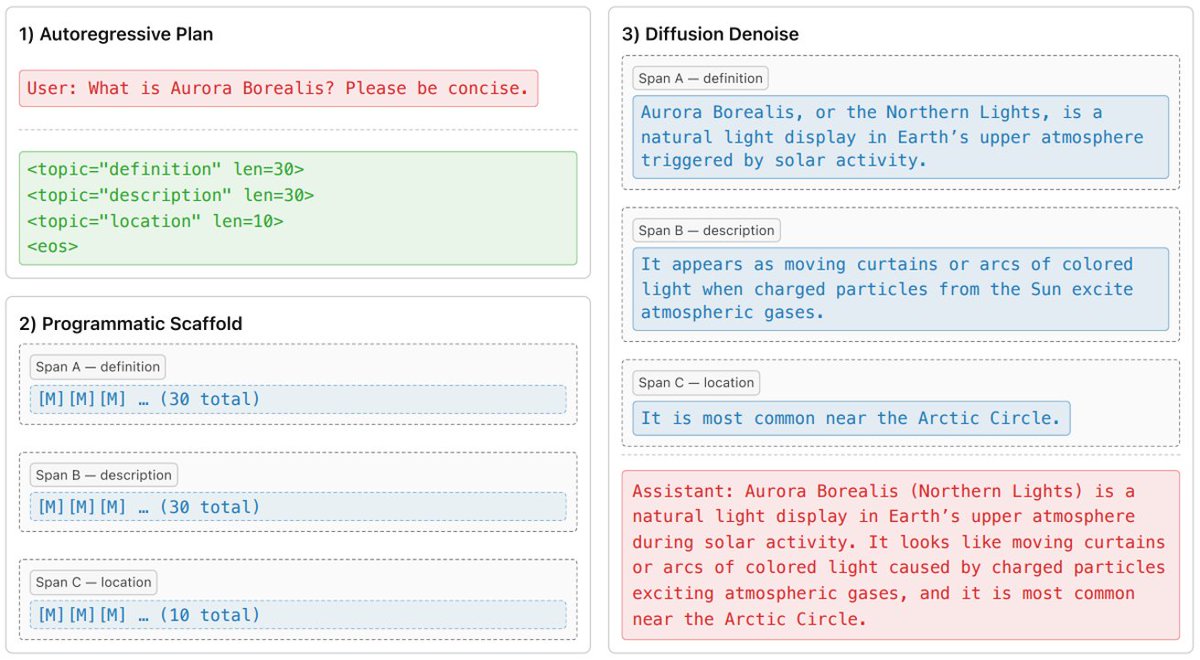
🌫️ In Planned Diffusion, @danielmisrael and colleagues combine autoregressive and diffusion models. While the autoregressive model creates a scaffold and plan, the diffusion model fills the gaps, achieving extremely low-latency text generation.
🤔 Is your LLM overthinking it? Rethinking Thinking addresses the problem of lengthy reasoning chains by bounding their thinking space and gradually distilling their thoughts, speeding up reasoning without losing depth.
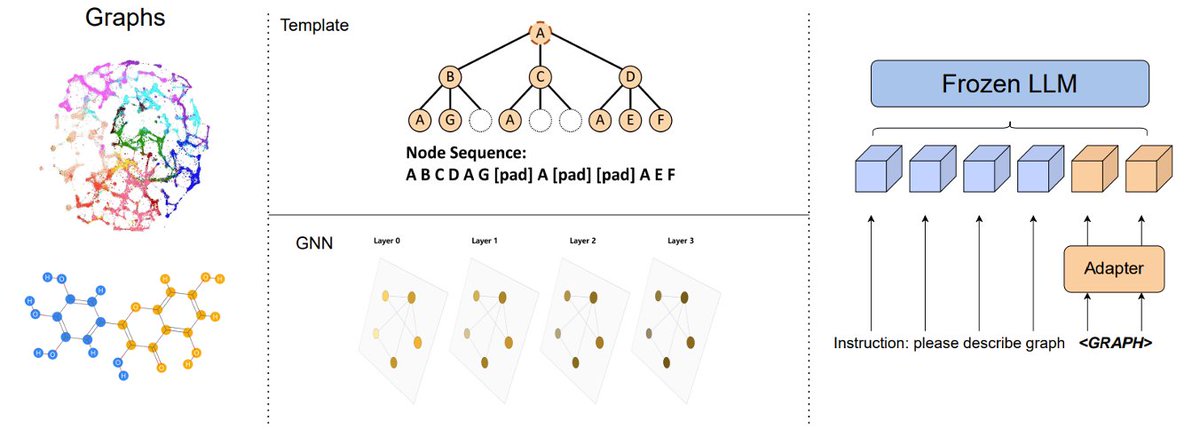
🕸️ Finally, When Structure Doesn’t Help compares techniques for how LLMs read text attributed graphs. The results are rather surprising: sometimes, too much structure can hurt.
Check out our summaries 👇
1
4
5
760
16 Oct 2025
LLM using too many reasoning tokens? 😕
Generation slow? 🐌
Or simply too many steps before EOS? 🪜🪜🪜
Douglas Orr (@douglasahorr), our beloved research scientist, has got you covered! He will tell you the remedies to all of the above in the shortest time possible. Registration link in the 🧵 below!
(Special thanks to @CodeWordsAI and @join_ef)
3
5
9
422
10 Oct 2025
September's Papers of the Month is here, and this month is all about LLMs! 🧠
Out of all papers released this month, our editor @robhu92 has curated:
📊 "FlowRL: Matching Reward Distributions for LLM Reasoning“ (review by @samot_gc): A clever usage of #GFlowNets to align an #RL policy model with the *full* reward distribution, encouraging mode coverage
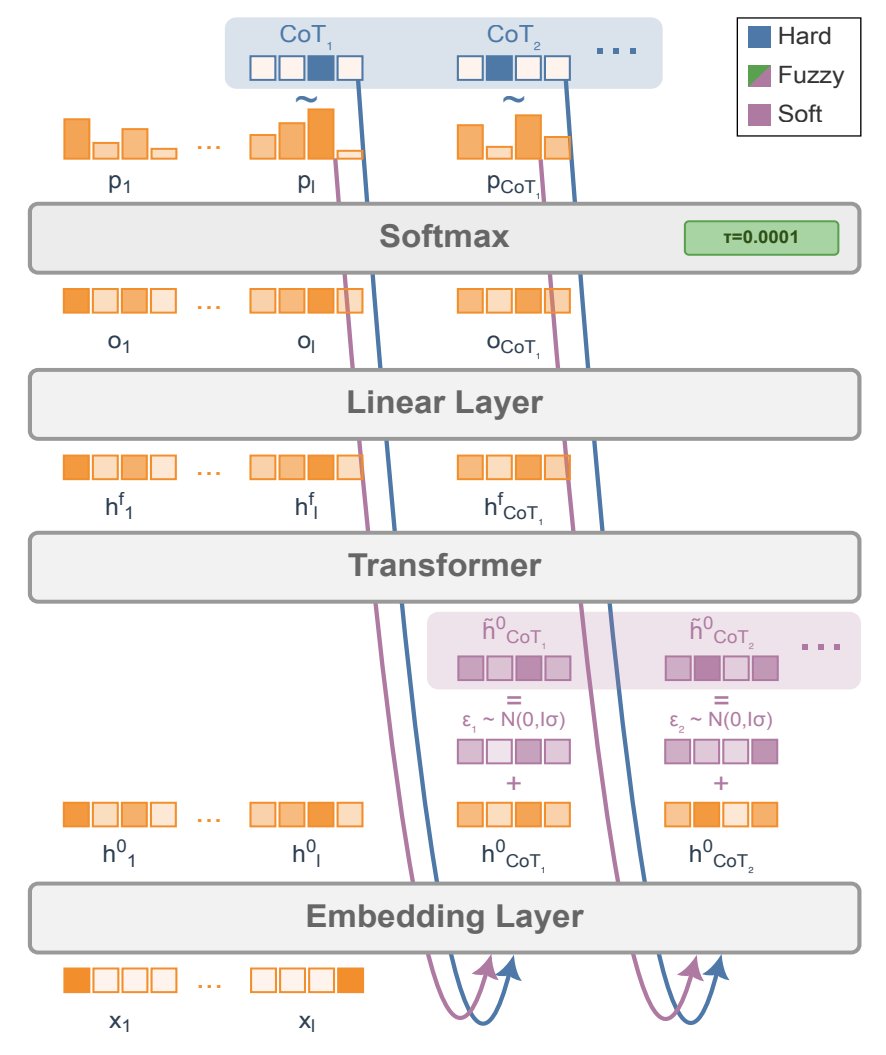
☁️ "Soft Tokens, Hard Truths" (review by @lukehudlass): A simple and scalable method to integrate #continuousthoughts with RL training schemes
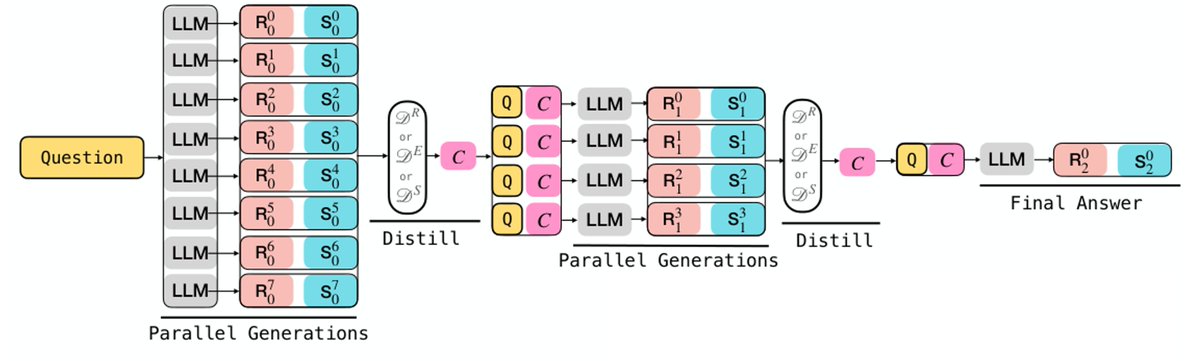
🏎️ "Set Block Decoding is a Language Model Inference Accelerator" (review by @douglasahorr): Exactly what it says on the 🥫!
🔁 "Turning Recurring LLM Reasoning into Concise Behaviors" (review by @DobrikG): An improvement to #CoT reasoning, trying to reduce self-repetition via metacognitive reduce
Check out our reviews in the 🧵 below!

1
3
8
969
10 Sep 2025
Summer may be over, but Papers of the Month certainly isn’t!
For August’s edition, we covered the following papers:
➡️ ADMIRE-BayesOpt
➡️ Guiding Diffusion Models with RL for Stable Molecule Generation
➡️ Graph-R1
🧵
1
1
2
283
10 Sep 2025
Next, Guiding Diffusion Models with RL for Stable Molecule Generation introduces reinforcement learning with physical feedback to accomplish exactly as its name suggests!
Summary: graphcore-research.github.io…
1
137
10 Sep 2025
Finally, Graph-R1 is another addition to the stack of agentic RAG approaches, but this time, using knowledge hypergraphs!
Summary: graphcore-research.github.io…
119