
🇪🇺
Joined December 2016
- Tweets 398
- Following 305
- Followers 318
- Likes 1,133
30 Photos and videos










Mar 12
The last thing I worked on at Aleph Alpha!
With @SohirMaskey Constantin Eichenberg @douglasahorr
tl;dr:
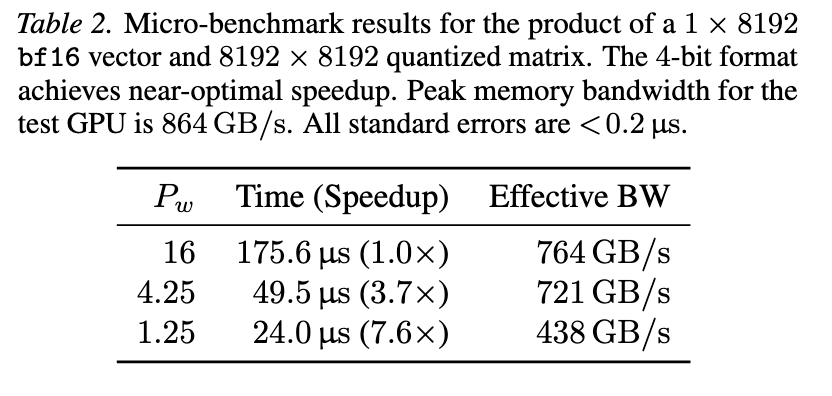
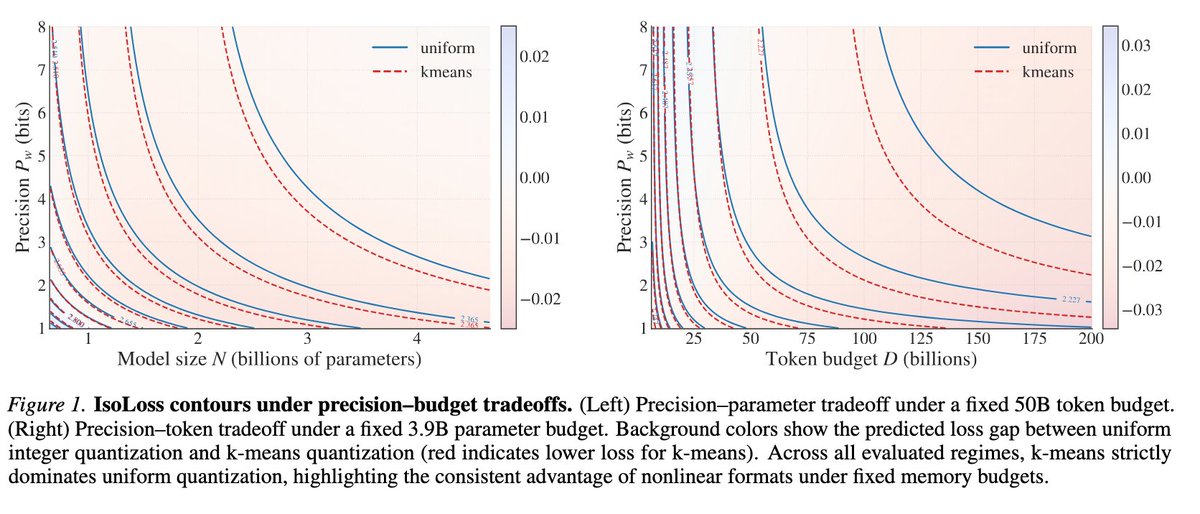
- Quantisation-aware training works really well
- If you have a fixed memory budget you should probably go many parameters - few bits
- k-means quant. is better than uniform

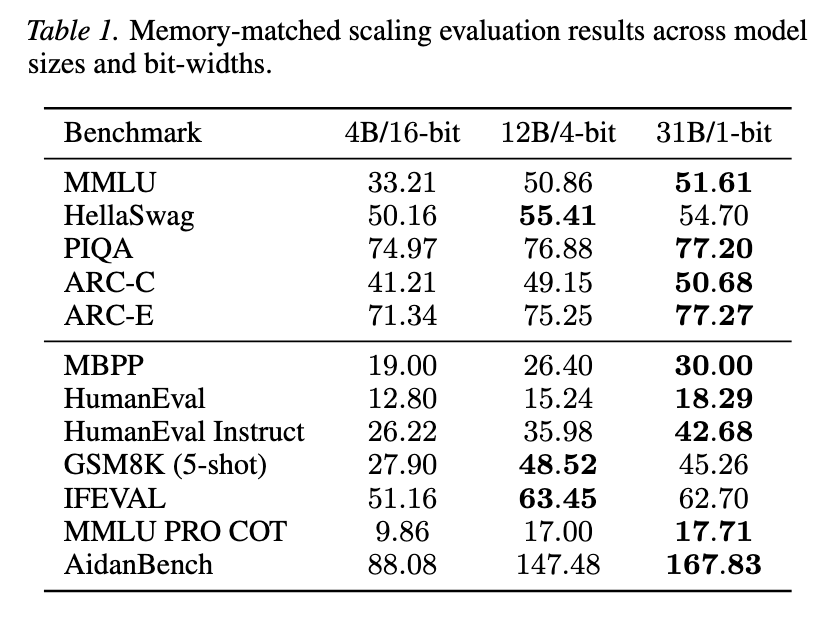
Would you rather use 1 million × 16-bit weights, 4 million × 4-bit weights, or even 16 million × 1-bit weights?
In joint work between Aleph Alpha Research and Graphcore, we asked this question of LLMs — the answer encouraged us to embrace the wonder ✨ of 1-bit weights, which can outperform 4-bit and 16-bit weights on a fixed weight memory budget.
In our work
- ⚖️ A scaling laws evaluation prompts us to consider very low-bit formats
- 📈 Scaled-up tests show the power of memory-matched models with 1-bit weights
- ⚡ Kernel benchmarking demonstrates their feasibility for autoregressive inference
Read all about it in our blog and paper (link below! ⬇️)
Massive thanks to our collaborators at Aleph Alpha Research!
Authors: @SohirMaskey, Constantin Eichenberg, @atomicflndr and @douglasahorr

1
6
325
Mar 12
... and scale up to larger models and generative evals to confirm this trend!
1
57

Today we’re releasing Trinity Large, a 400B MoE LLM with 13B active parameters, trained over 17T tokens
The base model is on par with GLM-4.5 Base, while being significantly faster at inference because it’s sparser and hybrid
The architecture we picked is one of my favorites: 3:1 local/global with SWA, NoPE on the global layers and RoPE on the local layers, gated attention, depth-scaled sandwich norm, and smooth training with Muon.
Our dataset is also high quality, curated by @datologyai .
We trained it on 2,000 B300s for a month on @PrimeIntellect infrastructure.
This is a preview release with an instruct model only — we’re ramping up RL on it.
When @latkins approached us a couple of months ago to train this model together, I thought he was crazy — but then he hired @stochasticchasm, and here we are.
Jan 27

We're excited to introduce @arcee_ai's Trinity Large model.
An open 400B parameter Mixture of Experts model, delivering frontier-level performance with only 13B active parameters.
Trained in collaboration between Arcee, Datology and Prime Intellect.
24
45
578
71,311
Johannes Messner retweeted

4 Sep 2025
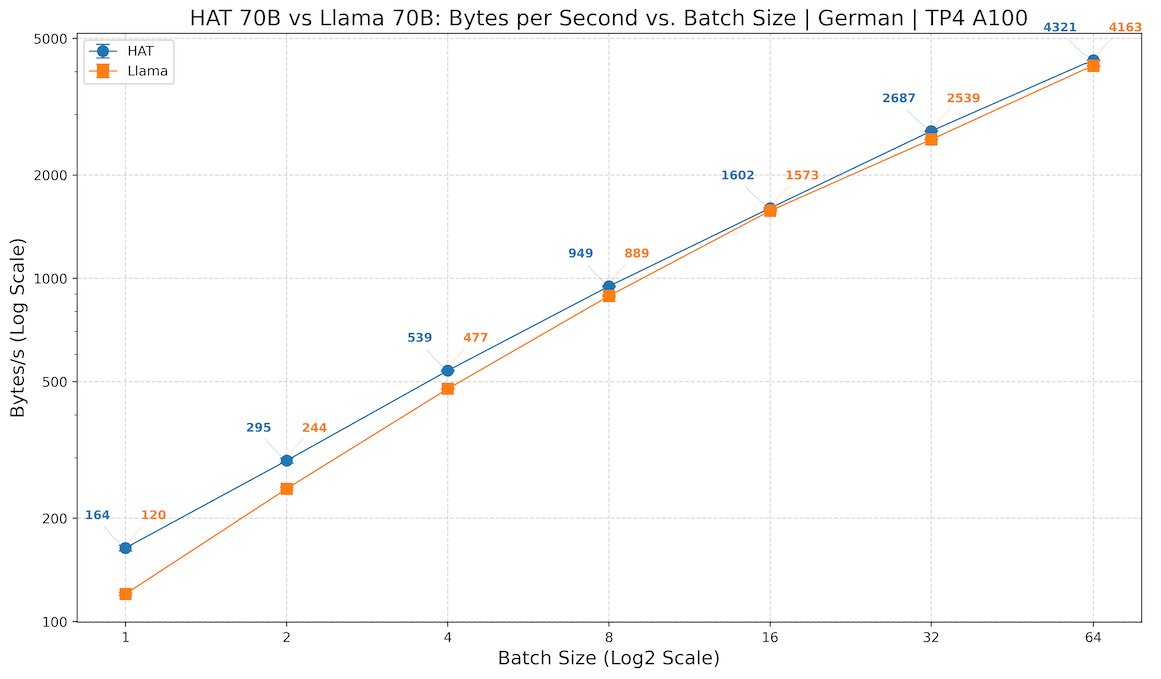
Curious how to accelerate inference of some of the recent byte level models like HAT/HNet/BLT?
Check out this vllm fork developed by my friends and colleagues, Pablo and Lukas!
To my knowledge first demonstration of inference speedups from dynamic chunking in byte models!
4 Sep 2025

First high-performance inference for hierarchical byte models.
@LukasBluebaum and I developed batched inference for tokenizer-free HAT (Hierarchical Autoregressive Transformers) models, developed by @Aleph__Alpha Research. In some settings, we outcompete the baseline Llama.🧵
1
2
8
757
Johannes Messner retweeted

4 Sep 2025
First high-performance inference for hierarchical byte models.
@LukasBluebaum and I developed batched inference for tokenizer-free HAT (Hierarchical Autoregressive Transformers) models, developed by @Aleph__Alpha Research. In some settings, we outcompete the baseline Llama.🧵
2
7
27
3,680
30 Aug 2025
Tears in my eyes
29 Aug 2025

🤯 MERZ AND MACRON JUST CONFIRMED A PAN-EUROPEAN LEGAL ENTITY IS COMING
It's now up to all of us to ensure the solution that gets passed into law is fit for purpose for European startups.
That means: EU–INC. 🚀
Support us and we all will get this done together. 🇪🇺🤝

5
191
Johannes Messner retweeted
22 Aug 2025
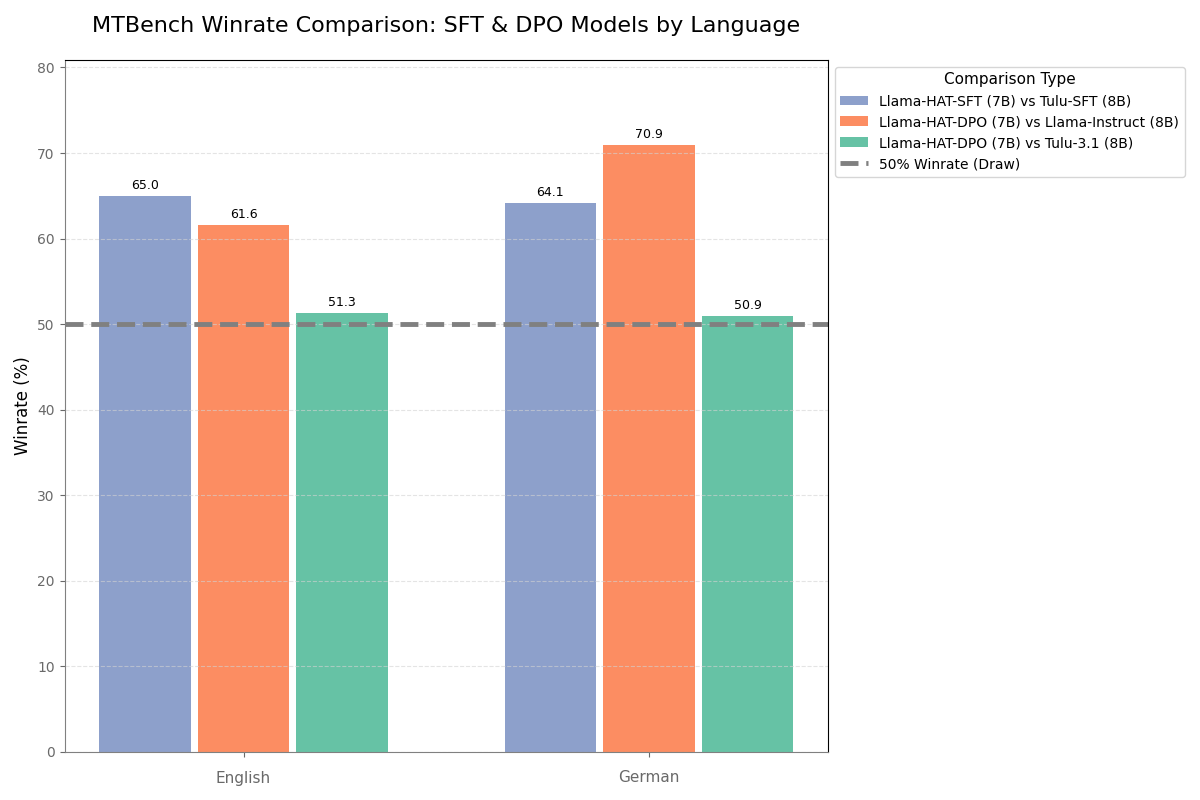
Our work on tokenizer free LLMs: Hierarchical Autoregressive Transformers (HAT)!
We recently dropped HAT models on HF, pretrained from scratch! huggingface.co/collections/A…
You can try them with both HF Inference AND our vllm fork: github.com/Aleph-Alpha/vllm
🧵
(1/6)
21 Aug 2025

Introducing two new tokenizer-free LLM checkpoints from our research lab: TFree-HAT 7B
Built on our Hierarchical Autoregressive Transformer (HAT) architecture, these models achieve top-tier German and English performance while processing text on a UTF-8 byte level.

2
2
21
1,328
Johannes Messner retweeted
22 Aug 2025
And imo what's the coolest is that we made it ready for production grade inference with our own vllm fork (more details on this soon!): github.com/Aleph-Alpha/vllm
So now you can now enjoy all the vllm features like continuous batching, paged attention etc also for HAT!
(5/6)
1
1
4
194
23 Aug 2025
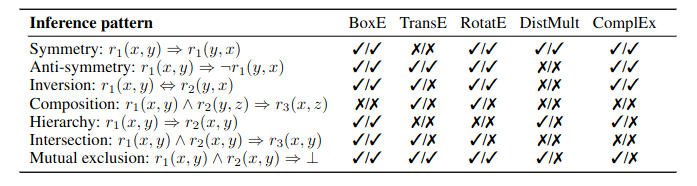
Seeing this pushback a lot - and it‘s fair!
However, these models don’t have a fixed vocabulary, i.e. there are infinitely many words the model can operate over instead of a finite set of tokens.
22 Aug 2025

I wouldn't really consider these to be tokenizer-free tbh.
Unlike Hnets, these models are word level. The sequence is turned into words (this is literally called tokenization).
Then, the bytes of these words are turned into embeddings, which are then processed by a model.
1
11
1,163
23 Aug 2025
The real issue, as I see it, is that the word splitting rule is not learned, unlike BLT and HNet.
This is WIP.
3
6
149
23 Aug 2025
So you can call this work tokenizer-free, or not, I don’t think it matters too much. What matters is, imo, that it addresses some of the fundamental limitations of subword tokenization a la BPE
1
7
142
22 Aug 2025
Byte-level models work! Tech report to follow btw
21 Aug 2025
Introducing two new tokenizer-free LLM checkpoints from our research lab: TFree-HAT 7B
Built on our Hierarchical Autoregressive Transformer (HAT) architecture, these models achieve top-tier German and English performance while processing text on a UTF-8 byte level.
11
912
30 Jul 2025
why do ML people love writing stuff like this and then proceed to never actually publish their data? just say "our data is super secret and you will never see it muahahaha" or something idk
2
3
193
12 May 2025
exceedingly cool work
12 May 2025

We went from our first line of code for prime-rl to releasing INTELLECT-2 in around two months. Now that our infra is in place and proven to work, I’m very optimistic that it’s only a matter of time until we will catch up with frontier labs.
Some thoughts on this release ⬇️
3
161
Johannes Messner retweeted

12 May 2025
We went from our first line of code for prime-rl to releasing INTELLECT-2 in around two months. Now that our infra is in place and proven to work, I’m very optimistic that it’s only a matter of time until we will catch up with frontier labs.
Some thoughts on this release ⬇️
12 May 2025
Releasing INTELLECT-2: We’re open-sourcing the first 32B parameter model trained via globally distributed reinforcement learning:
• Detailed Technical Report
• INTELLECT-2 model checkpoint
primeintellect.ai/blog/intel…
18
25
379
113,208