
build your own ai cluster. run open models across your machines.
Joined December 2025
- Tweets 93
- Following 39
- Followers 1,316
- Likes 45
8 Photos and videos







Jun 1
nvidia going all in on local ai.
here's our take: it shouldn't depend on which chip you bought.
sparks, macs, the 5090 already on your desk, we cluster across all of it and split your favorite model pipeline-parallel so it runs fully private and local.

NVIDIA RTX Spark: a 1-petaflop superchip, the full CUDA and RTX ecosystem, and Windows-native agents. A new beginning for personal computers.

16
26
109
14,278



Thrilled to see @tryParallax live in production on @Theta_Network.
This is exactly why @Gradient_HQ built Parallax: turning the world’s GPU mesh into a sovereign, distributed token factory.
Congrats on the milestone! 🫡
Apr 20

To make this work, we adapted Parallax, @Gradient_HQ's distributed inference framework, to run across EdgeCloud's global node network. One API endpoint, model split across many machines, no centralized cluster required.
25
65
361
42,938
Apr 22
glad we could help!
with the agentic adoption soaring, privacy and token cost are already the top concerns for both agent and human users.
that's what parallax's built for.
Apr 20
To make this work, we adapted Parallax, @Gradient_HQ's distributed inference framework, to run across EdgeCloud's global node network. One API endpoint, model split across many machines, no centralized cluster required.
17
36
207
25,320
Mar 24
the $3,469 single-night burn is a good reminder of what you're actually signing up for with cloud inference.
when the meter's always running, one stuck agent is a bill.
parallax runs models on your own machines. no token meter, no overnight surprises.

5
8
40
1,579
Mar 21
local ai has picked up fast since openclaw dropped.
with the latest wave of small capable models, more people are running serious workloads on their own hardware.
if you missed this good local ai tutorial from @yacinelearning or want a refresher on how distributed scheduling actually works under the hood, it's worth the rewatch over the weekend!
Feb 9

I am continuing my adventure into distributed AI system with the parallax scheduling strat from @Gradient_HQ
in this 37min tutorial I go through:
- heuristic used to make scheduling tractable
- dynamic programming formulation
- filling GPU with water
- shoving them into shelves

14
15
121
16,190
Mar 13
some parallax dev lunch break fun:
- a macbook pro, a mac mini, some cables
- zero internet, zero cost
- openclaw running on parallax
no subs. no token burn. nothing leaves the desk.
just local agents vibing.
17
18
120
14,783
Mar 13
messari's new report on echo-2 highlights how parallax powers the rollout plane.
consumer RTX 5090s served as distributed rollout actors via parallax, feeding a centralized learner cluster. and we got 33-36% lower hardware costs with no quality loss.
this is parallax doing what it was built for. turning consumer hardware into production AI infrastructure.
Mar 11

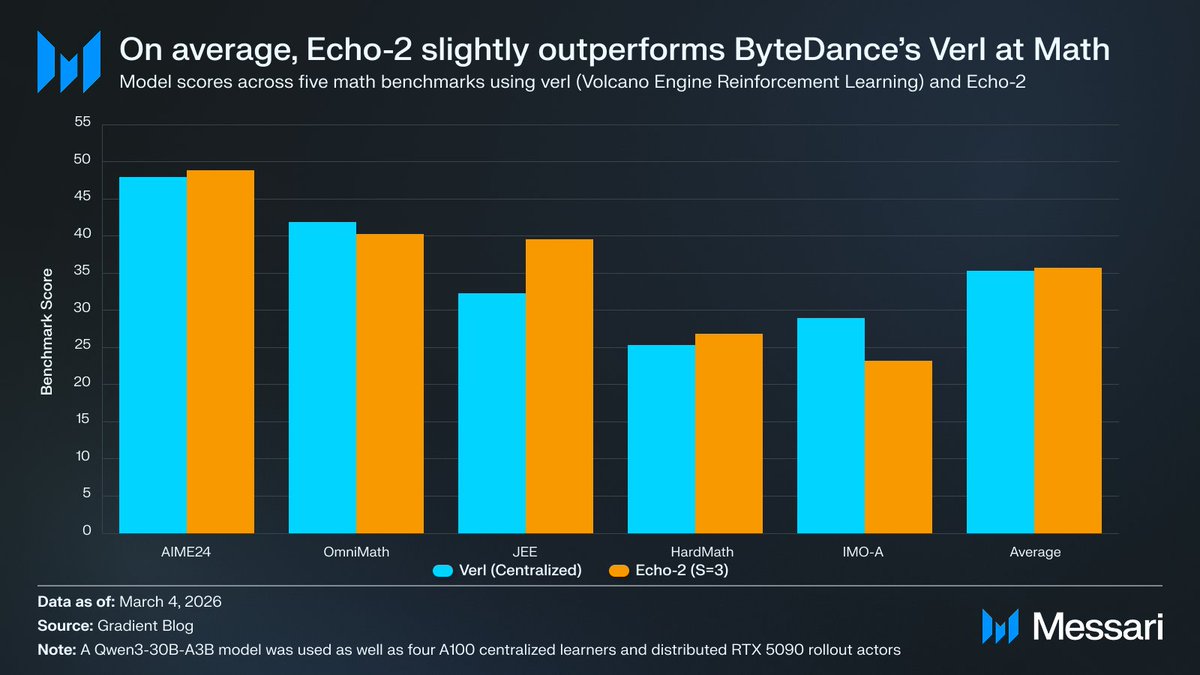
Beyond improvements in speed and cost, Echo-2 demonstrates a high standard of model performance.
Benchmarking data across five math reasoning tasks shows Echo-2 achieving an average score of 35.75, compared to 35.30 for ByteDance’s verl.
These results confirm that the architectural efficiencies of the Open Intelligence Stack (OIS) do not come at the expense of reasoning capabilities.
2
4
29
1,015
Mar 12
perplexity just announced always-on ai running on a mac mini.
the category is real. the question is whether your always-on ai should phone home to someone else's servers or run entirely on your own hardware.
we built parallax for the second option.
Mar 11

Announcing Personal Computer.
Personal Computer is an always on, local merge with Perplexity Computer that works for you 24/7.
It's personal, secure, and works across your files, apps, and sessions through a continuously running Mac mini.
2
33
962
Mar 11
a 9b model now matches a 120b on reasoning benchmarks.
models are shrinking fast. the hardware you already own is becoming more powerful every release cycle.
this is the trend parallax was built for. connect your machines, run what fits, and scale when you need to.

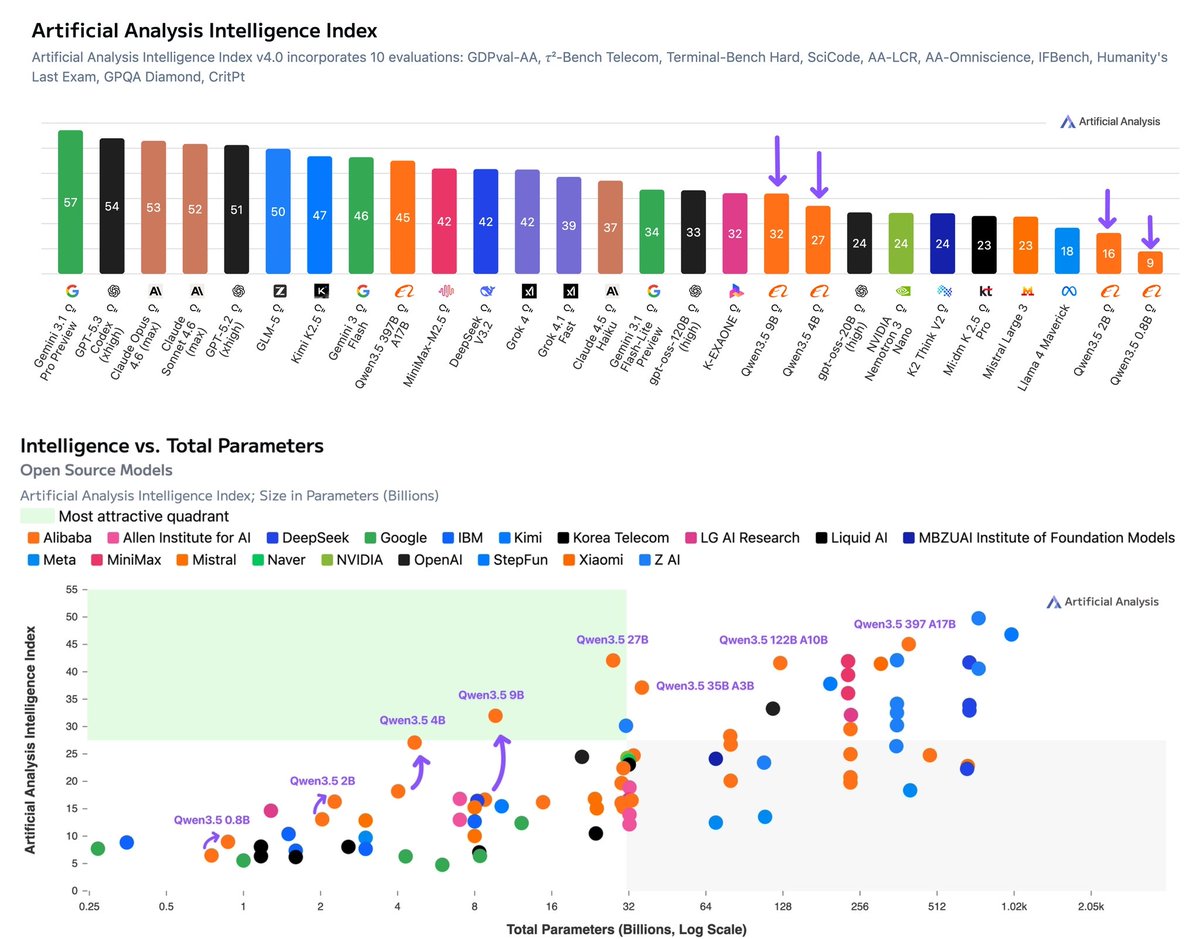
Alibaba has released 4 new Qwen3.5 models from 0.8B to 9B. The 9B (Reasoning, 32 on the Intelligence Index) is the most intelligent model under 10B parameters, and the 4B (Reasoning, 27) the most intelligent under 5B, but both use 200M output tokens to run the Intelligence Index
@Alibaba_Qwen has expanded the Qwen3.5 family with four smaller dense models: the 9B (Reasoning, 32 on the Intelligence Index), 4B (Reasoning, 27), 2B (Reasoning, 16), and 0.8B (Reasoning, 9). These complement the larger 397B, 27B, 122B A10B, and 35B A3B models released earlier this month. All models are Apache 2.0 licensed, support 262K context, include native vision support, and use the same unified thinking/non-thinking hybrid approach as the rest of the Qwen3.5 family
Key benchmarking results for the reasoning variants:
➤ The 9B and 4B are the most intelligent models at their respective size classes, ahead of all other models under 10B parameters. Qwen3.5 9B (32) scores roughly double the next closest models under 10B: Falcon-H1R-7B (16) and NVIDIA Nemotron Nano 9B V2 (Reasoning, 15). Qwen3.5 4B (27) outscores all of these despite having roughly half the parameters. All four of the small Qwen3.5 models are on the Pareto frontier of the Intelligence vs. Total Parameters chart
➤ The Qwen3.5 generation represents a material intelligence uplift over Qwen3 across all sub-10B model sizes, with larger gains at higher total parameter counts. Comparing reasoning variants: Qwen3.5 9B (32) is 15 points ahead of Qwen3 VL 8B (17), the 4B (27) gains 9 points over Qwen3 4B 2507 (18), the 2B (16) is 3 points ahead of Qwen3 1.7B (estimated 13), and the 0.8B (9) gains 2.5 points over Qwen3 0.6B (6.5).
➤ All four models use 230-390M output tokens to run the Intelligence Index, significantly more than both larger Qwen3.5 siblings and Qwen3 predecessors. Qwen3.5 2B used ~390M output tokens, 4B used ~240M, 0.8B used ~230M, and 9B used ~260M. For context, the much larger Qwen3.5 27B used 98M and the 397B flagship used 86M. These token counts also exceed most frontier models: Gemini 3.1 Pro Preview (57M), GPT-5.2 (xhigh, 130M), and GLM-5 Reasoning (109M)
➤ AA-Omniscience is a relative weakness, with hallucination rates of 80-82% for the 4B and 9B. Qwen3.5 4B scores -57 on AA-Omniscience with a hallucination rate of 80% and accuracy of 12.8%. Qwen3.5 9B scores -56 with 82% hallucination and 14.7% accuracy. These are marginally better than their Qwen3 predecessors (Qwen3 4B 2507: -61, 84% hallucination, 12.7% accuracy), with the improvement driven primarily by lower hallucination rates rather than higher accuracy.
➤ The Qwen3.5 sub-10B models combine high intelligence with native vision at a scale previously unavailable. On MMMU-Pro (multimodal reasoning), Qwen3.5 9B scores 69.2% and 4B scores 65.4%, ahead of Qwen3 VL 8B (56.6%), Qwen3 VL 4B (52.0%), and Ministral 3 8B (46.0%). The Qwen3.5 0.8B scores 25.8%, which is notable for a sub-1B model
Other information:
➤ Context window: 262K tokens
➤ License: Apache 2.0
➤ Quantization: Native weights are BF16. Alibaba has not released first-party GPTQ-Int4 quantizations for these small models, though they have for the larger models in the Qwen3.5 family released earlier (27B, 35B-A3B, 122B-A10B, 397B-A17B). In 4-bit quantization all four models are accessible on consumer hardware
➤ Availability: At time of publishing, there are no first-party or third-party serverless APIs hosting these models
8
8
46
954
Mar 2
ancient romans built public libraries changed the way how knowledge is accessed.
today, open source AI is doing the same job.
open doors, open intelligence. 🏛️
Mar 2

AI should be a public good, not something gatekept by a handful of megacorps
We had Eric Yang, co-founder of Gradient Network, on the pod this week to talk through exactly that.
Gradient's "Open Intelligence Stack" includes:
i) Parallax for distributed model serving
ii) Echo for decentralized reinforcement learning
The whole thesis is that anyone should be able to run large models on consumer hardware (yes, including your Mac Minis OpenClaws)
Eric breaks down their $10M seed round led by Pantera, Multicoin, and HSG; where he sees the industry heading; and why post-training is going to be the dominant force in enterprise.
Timestamps:
00:00 Intro
01:15 AI market is booming
02:29 Local compute is a hot topic
03:02 Parallax Inference Engine
04:34 Intelligence as a public good
05:46 AI models will become a commodity
07:32 Bottlenecks in AI models accessibility
09:34 Smaller AI models are catching up
11:01 How Gradient's Infrastructure Enables Model Development
12:15 Model post-training
14:24 How does reinforcement learning work?
17:35 AI going rogue
19:20 Gradient's token
23:02 AI entrepreneurs that Eric admires
26:11 Use cases on chain for AI
31:34 The trade-offs of coming to crypto
35:09 How low-spec GPUs will work on Gradient Ecosystem
38:08 Post-training will be the dominating force for enterprise
38:43 Open source models are way cheaper
41:39 Eric's founding story
49:07 Empowering researchers globally
53:37 Why did Multicoin Capital and Pantera Capital invested in Gradient
55:08 One-click deploy agent
58:16 Gradient in 3 years
8
1
38
1,625
Parallax retweeted

Feb 12
We also tested the messier setups.
Using Parallax, we trained Qwen3-8B on distributed RTX 5090s. 36% cheaper than centralized A100s, same scores, zero divergence.
We even trained a 0.6B agent to beat LLMs at No-Limit Texas Hold'em. Reliable results with unreliable compute.

2
8
61
3,815
Parallax retweeted
Feb 12
They crashed. They fell. They exploded on the pad.
Then they got back up. Faster, wiser, stronger.
Breakthroughs don't come from one perfect run, they come from the freedom to fail 100 times.
Introducing Echo-2, distributed RL that boosts AI research throughput by 10x.
163
203
746
150,837
Parallax retweeted

Feb 5
The wait is over.
Open your Clawbox now!
The easiest way to own your🦞agent.
Zero code. Just download, click, and go.
Grab yours: commonstack.ai/clawdbot?ref=…
16
24
117
20,633
Feb 2
spoiler alert 🦞
we’re preparing a fully private version of clawbox.
air-gapped ready. run it completely offline. absolutely zero risks tolerated with sovereign AI. 🛡️
Feb 2

Want an @openclaw🦞agent in just a few clicks?
Meet Clawbox🦞, powered by Commonstack.
-No CLI. No VPS. Just download & run.
-Permission controls for peace of mind.
-Switch between 30 LLMs instantly.
Free credits 20% off for all!
🦞Join whitelist: commonstack.ai/clawdbot

10
7
53
2,971
Parallax retweeted
Feb 2
Want an @openclaw🦞agent in just a few clicks?
Meet Clawbox🦞, powered by Commonstack.
-No CLI. No VPS. Just download & run.
-Permission controls for peace of mind.
-Switch between 30 LLMs instantly.
Free credits 20% off for all!
🦞Join whitelist: commonstack.ai/clawdbot
25
11
120
54,649
Jan 27
proud of kimi.
kimi k2.5 better when sovereign.
Jan 27

Here's a short video from our founder, Zhilin Yang.
(It's his first time speaking on camera like this, and he really wanted to share Kimi K2.5 with you!)
4
2
35
1,365
Jan 27
heard you all buying mac minis now?
should have been grinding harder back then😋
23 Nov 2025

please show your local ai waifu and submit here 👇
i want to mail those mac minis to you🥺
1
1
27
3,206
Jan 26
what are you building with your mac mini today?
hint: save your $5 for vps and have some privacy with parallax.
9
13
78
6,969