
Signal in the AI noise
Joined September 2022
- Tweets 9,260
- Following 26
- Followers 67,070
- Likes 33,420
2,333 Photos and videos















Pinned Tweet

30 Apr 2024
Steve Jobs on Failure (1994):
30
502
1,791
154,736
High Signal AI retweeted

Psychology professor Marty Lobdell explains why 30 minutes of focused work beats hours of grinding:
1
14
16
712
High Signal AI retweeted

A game called "Data Center" is quietly teaching people how real servers, switches, and networks actually work.
2
11
18
695
What do you give the woman who raised you? Miano used AI video generation to turn decades of her old photographs into a birthday film she could see, feel, and relive. Proof that the best use of this tech might be the most personal one.
Media: Franklin Miano
9
14
768
High Signal AI retweeted

Jun 12

Jeff Bezos just bet $12 billion that you'll be able to support your whole family on a single paycheck again.
his reasoning: AI will let companies make more stuff with fewer people and less money.
and when something gets cheaper and easier to produce, and lots of companies can do it, they compete and the price drops.
it's why a flatscreen TV that cost $2,000 a decade ago is $300 today.
bezos thinks AI will do that to almost everything you buy.
in his words, it raises "the basket of goods people can afford."
your paycheck buys more without anyone handing you a raise.
the problem: look at which prices have actually dropped.
so far, AI has only made *digital* things cheap, like code and content.
but the stuff that really eats your paycheck is *physical*.
rent, cars, medicine. cheaper code doesn't lower your rent.
that's exactly what bezos just spent $12B on.
Prometheus, his new company, is building AI tools that help engineers design and manufacture physical products faster
things like cars, machines, and medicine.
the goal is to make building physical things as fast and cheap as writing software.
if it works, 1 income starts covering what used to take 2.
which is when his prediction kicks in:
"perhaps one of those earners will choose not to be in the job market, so they'll become a one-earner household." or "some people who are working overtime will stop working overtime, because they don't want to."
one paycheck covering a whole family again, like the 1950s.
5
15
1,476
Hugging Face CEO @ClementDelangue: "There's a strong probability of a future where only a few companies are able to do AI and the rest of us are doomed just to be AI users, not really AI builders."*
Clem Delangue, cofounder and CEO of Hugging Face, sees that future as something to worry about and something to actively change.
"At Hugging Face, we're kind of like the platform for AI builders," he explains. "We have 11 million AI builders using our platform."
About a year and a half ago, the team noticed a shift:
"We started to see more and more AI builders playing with robotics. And one of the challenges that they were encountering is the lack of affordable hardware for them to experiment with."
The problem was cost. Entry-level robots can run anywhere from $20,000 to $100,000. Far too steep for someone who just wants to start tinkering.
So Hugging Face built its own answer: a small, open-source desktop robot called the Reachy Mini. Instead of starting with a full humanoid, they went small and cheap on purpose.
"When an AI builder is starting with robotics, they might not want to buy a 20, 30, $50,000, $100,000 robot," Clem says. "And so that's why we decided to build this affordable robot. We sell it for $400 to $500… it's very cheap so that it's easy for you to take a decision to buy it, put it next to your laptop and start experimenting with open-source AI robotics."
The robot ships mostly 3D-printable and fully programmable. Crucially, it arrives almost empty:
"It doesn't come so much with pre-installed apps. As an AI builder you can build your apps yourself and then use these apps that you build at home."
Some people are already playing hide and seek and red light, green light with their kids using apps they wrote themselves then sharing those apps with the community. Over 5,000 people have pre-ordered, the first units are shipping, and Clem received his own last week.
Underneath the product is a bigger conviction about where people should put their energy right now:
"I think it's the most important thing. It's one of the most impactful things that you can help with in AI right now."
3
18
39
8,241
High Signal AI retweeted
Google DeepMind CEO Demis Hassabis explains how governments could deliver incredible good for citizens by applying AI at scale:
Asked what he'd hope governments would use AI for if he could wave a magic wand, Hassabis points to the foundations of public life—health, education, and the basic machinery of administration.
"I think governments should be using AI," he says, adding that he wants "to support all sort of democratically elected governments."
His priorities are clear:
"The things I would love to see them use it for and what we're trying to build our systems to be good for is things like improving public health, education. I mean, all of these things need to be rethought."
For @demishassabis, the upside is transformative:
"The efficiency gains and the amount of good we can do with it, governments could do with it for their citizens could be incredible."
He notes that this isn't hypothetical. Some governments are already moving in this direction: "some countries are doing it like Singapore and UAE I think are leaning into these types of use cases."
Energy is another area he highlights, and here he draws on DeepMind's own experience:
"I would love to see it being used for things like energy like optimizing energy grids. We did that with our data centers and save 30% of the energy used for the cooling systems."
The throughline of his argument is scale:
"I think there's enormous societal gain from applying AI at scale to these types of areas."
But Hassabis doesn't end on pure optimism. He acknowledges the harder reality surrounding the technology:
"The geopolitics of the world is very complicated right now and these are dual-purpose technologies."
5
15
27
3,145
High Signal AI retweeted
Alexandr Wang offers a contrarian take on management: the more brilliant your people, the less you should tell them what to do.
Most leadership instinct says that as you hire better people and take on bigger problems, you direct more closely. Wang's approach to running MSL goes the other way.
"In general, in terms of my management philosophy for MSL, [it] is not to boss people around," he says.
@alexandr_wang points to a line from Steve Jobs that flips the usual logic:
"Most companies hire people and tell them what to do, but we hire people for them to tell us what to do."
That inversion sits at the foundation of everything. For Wang, the entire bet behind MSL and TBD rests on it:
"That is like pretty core to the entire thesis of TBD and MSL and how we've built it… we're going to hire brilliant researchers and create the best environment for them to do the work of their careers and the work of their lives."
So instead of positioning himself as the person with the answers, he positions himself as the person who removes everything standing between great researchers and great work:
"Long story short, I'm not trying to boss anyone around. Actually, I'm trying to create the best environment for researchers to do incredible work."
1
20
50
3,602
High Signal AI retweeted
Ray Dalio, founder of the world's largest hedge fund, on why he'll follow the markets until the day he dies:
4
17
82
8,785
High Signal AI retweeted
In 2008, SpaceX had $200K left and one launch from shutting down. Yesterday, Elon Musk became the world's first trillionaire as SpaceX raised $75B — the largest IPO in history.
1
18
71
4,417
Google CEO Sundar Pichai on the AI danger that keeps him up at night:
"Race conditions" where companies get so caught up in being first, they lose sight of the pitfalls and downsides.
Media: CBS News
1
13
20
3,628
High Signal AI retweeted

i grew @vitaliidodonov from 0 to 10K in 3 months.
then we trained an AI on my exact strategy.
113 people already asked for access in the last post I did.
if you want to see what it can do for your account, reply "X" and i'll send you the details.
17
17
26
7,558
High Signal AI retweeted

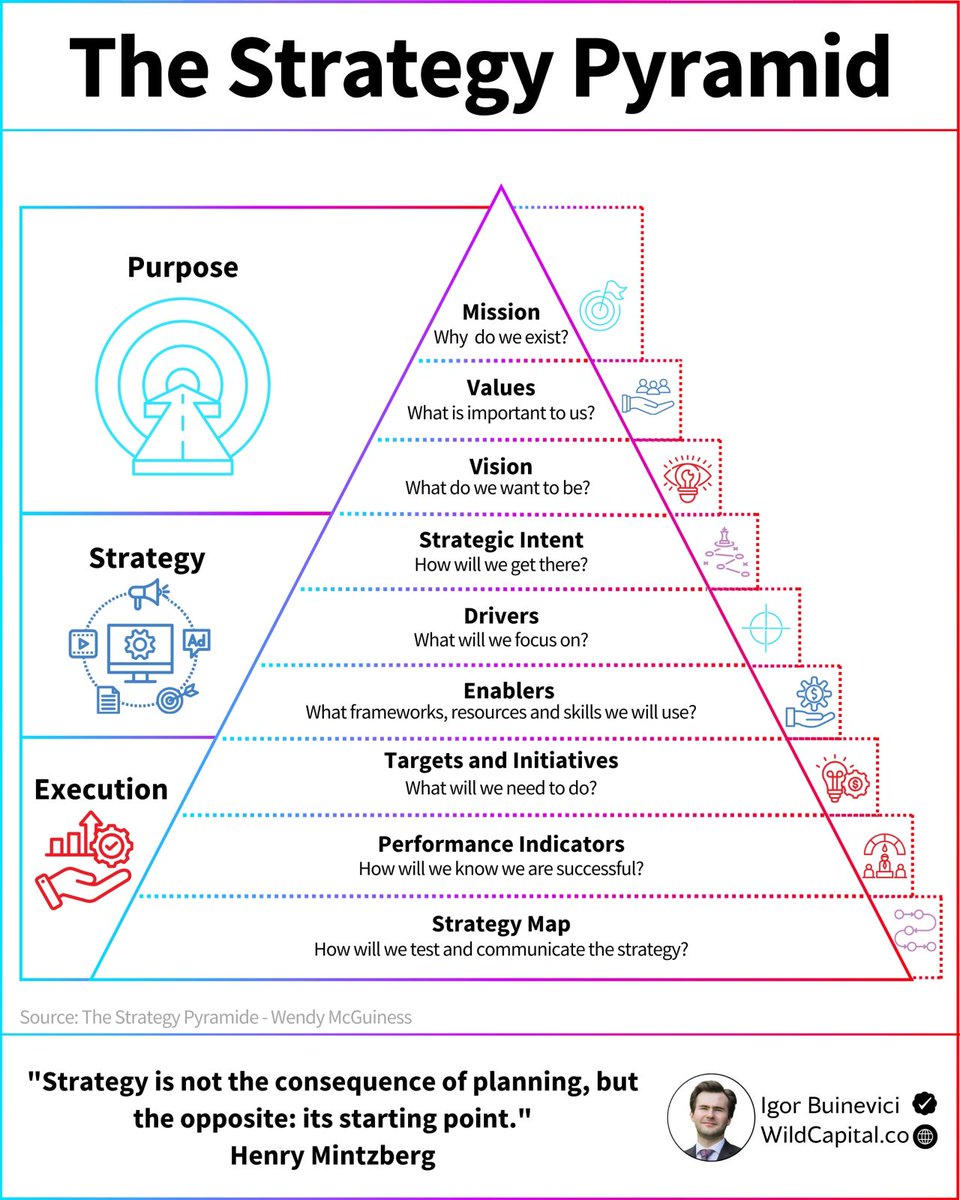
Most companies have a strategy.
But only 10% execute it well:
Why do some organizations achieve their goals
While others struggle to make progress?
One framework that helps answer this question is:
The Strategy Pyramid.
Originally introduced by Wendy McGuinness (2011),
It breaks strategy into 9 key components grouped into 3 areas:
Purpose, Strategy, and Execution.
A) Purpose
1. Mission
Defines why the organization exists and the value it aims to create.
It answers the question: "Why are we here?"
2. Values
The principles and standards that guide decisions.
Behaviors, and company culture across the organization.
3. Vision
A clear description of the future state the organization wants to achieve.
The direction it is working toward.
B) Strategy
4. Strategic Intent
Establishes the long-term objectives and ambitions.
Outlines what success looks like.
5. Drivers
The critical priorities that fuel growth and competitive advantage.
Such as innovation, customer experience, operational excellence, or market expansion.
6. Enablers
The capabilities, resources, systems, technology, talent, and funding required to turn strategy into reality.
C) Execution
7. Targets and Initiatives
Specific goals and projects that translate strategy into action and provide a roadmap for implementation.
8. Performance Indicators
Metrics and KPIs that measure progress, identify gaps, and ensure accountability across teams.
9. Strategy Map
A visual representation of the strategy that aligns employees around priorities and shows how different objectives connect.
Together, these elements help leaders:
A) Build a coherent strategy,
B)Define the organization's purpose,
C) Execute it successfully across the business.
Many companies focus heavily on strategy creation.
Others focus only on execution.
The best organizations excel at both.
Every layer of the pyramid matters.
Ignoring one often weakens the entire structure.
P.S. Which part do you neglect most often?
♻️ Repost this to help more leaders improve strategy execution.
----
📌 Get my top 100 infographics for free:
1) Follow me.
2) Subscribe to my free newsletter at WildCapital.co.
You’ll receive them directly in your welcome email.
4
44
83
4,578
High Signal AI retweeted
Rory Sutherland, Vice Chairman of Ogilvy: "When you create perceptual value, you are creating value."
Rory argues that marketing has long been misunderstood, treated as an optional extra rather than a genuine source of worth.
He describes the dismissive view of marketing as "the fairy dust on top of the real intrinsic value that resided in a product or service."
His response is blunt: "I completely dispute that."
For @rorysutherland, worth isn't fixed inside the object itself:
"I think we value things according not to what they are but what they mean, and what they mean is context dependent."
That meaning, he explains, can be reshaped through storytelling, framing and recontextualization, and the effect is real:
"You can absolutely use psychological mechanisms to make things more valuable, more enjoyable, more precious."
He then makes a point he admits is "over ambitious":
"Perceived value is a very environmentally friendly form of value to create because you can generally create meaning and imbue a product with meaning with a lot less carbon consumption than is necessarily involved in making the product three times bigger or five times faster."
His most striking claim is about where breakthroughs actually come from:
"If we're looking for breakthrough 10x moonshot improvements, it's actually much easier to find psychological moonshots than technological moonshots."
He illustrates this with the train.
"Making one ten times faster was possible in the 1820s, but today it's an extraordinarily difficult, even dangerous, engineering problem. Making the journey ten times more enjoyable? That's still doable."
1
17
30
2,503
High Signal AI retweeted
OpenAI CEO Sam Altman on why AI models are learning to slow down and "think" before they answer:
Altman explains that one of the earliest surprises with GPT models was how a simple instruction changed everything:
"One of the things that got people really excited in the early days of the GPT models was you could get better performance by telling the model, let's think step by step and it would then just output text that was thinking step by step and get a better answer."
He says reasoning models take that idea much further. By breaking a question into pieces, the model can spend more time on each part.
To explain how this works, Altman compares it to his own thought process:
"When you ask me a question, if it's a really easy question, I might just fire back like almost on reflex with the answer. But if it's a harder question, I might think in my head and have like my internal monologue go and say, 'Well, I could do this or that or maybe, you know, this will be clearer. I'm not sure about that.' And I could like backtrack and retrace my steps."
Only after that internal deliberation does he deliver a clean answer:
"When I finish thinking and I've, you know, been thinking in English, I can then make some bullet points and then kind of like output an answer to you in English."
@sama shares an observation from using the app himself—asking a deep research question and watching it keep working even after he's locked his screen.
He recalls another company's approach to measuring this:
"I heard somebody, another company... I think it was Anthropic, said, 'Hey, this model actually spent like 15 minutes or 30 minutes or whatever length of time to think about a thing,' which is a good metric, but it needs to actually give you the right answer."
This led to a realisation that went against his every instinct:
"All of my instincts have been the instant response is the thing that matters and users hate to wait. And for a lot of stuff, that's true. But for hard problems with a really good answer, people are quite willing to wait."
7
12
35
5,441
Michael Truell, co-founder of Cursor, on why he's trying to kill coding as we know it:
"The goal with the company is to replace coding with something that's much better."
@mntruell is asked about his stated ambition: to invent a new type of programming where you simply describe what you want and it gets built.
He starts with who he and his team actually are:
"Me and my three co-founders, we've been programmers for a long time. More than anything, that's what we are."
What drew them to coding in the first place was speed. The ability to build things quickly. But that promise, he explains, is buried under friction:
"The thing that attracted us to coding is that you get to build things really quickly, to do things that are simple to describe."
The problem is everything standing between the idea and the result:
"Coding requires editing millions of lines of esoteric formal programming languages… lots and lots of labour to actually make things show up on the screen that are simple to describe."*
That gap between how simple something is to describe and how hard it is to build is the thing Cursor is built to close. And Truell frames it as a near-term shift, not a distant dream:
"We think that over the next 5 to 10 years it will be possible to invent a new way to build software that's higher level and more productive. That's just distilled down to defining how you want the software to work and how you want the software to look."*
The strategy for getting there is deceptively simple. Win the present, then change the game:
"Our path to getting there is to, at any given point in time, always be the best way to code with AI, and then evolve that process away from normal programming to something that looks very different."
Media: Startup
5
9
17
1,199
High Signal AI retweeted

A team that never disagrees
is a warning sign.
Not a success story:
If nobody disagrees, one of two things is true:
People stopped caring.
Or people stopped feeling safe enough to speak.
The best teams don't avoid tension.
They turn tension into better ideas.
Because conflict is not the real problem.
Unspoken conflict is.
Want PDFs of my top infographics growth tools?
👉 Go Here: fullpotentialzone.beehiiv.co…
Please repost to help others out there! ♻️

2
35
74
4,695
High Signal AI retweeted

22h
Prediction:
By 2028, the creator economy will split into two camps: operators who use AI to build systems and ship real products, and performers who use AI to generate more content about using AI.
One group will be wealthy and quiet.
The other will have a lot of followers.
6
17
47
4,753

High Signal AI retweeted
The reason SpaceX exists, in Elon Musk's own words:
4
19
40
2,325