
Robotics research at NVIDIA. ex Cambridge and Wayve. Views entirely my own. github.com/hugohadfield
Joined June 2014
- Tweets 429
- Following 1,145
- Followers 255
- Likes 806
15 Photos and videos








Pinned Tweet

16 Oct 2025
It turns out you can just take an off-the-shelf VLM and fine-tune it directly to output robot actions *as text* and it performs better than/as-good-as all the more complex model architectures…
Check out the paper!
16 Oct 2025

What's the right architecture for a VLA?
VLM custom action heads (π₀)?
VLM with special discrete action tokens (OpenVLA)?
Custom design on top of the VLM (OpenVLA-OFT)?
Or... VLM with ZERO modifications? Just predict action as text.
The results will surprise you.
VLA-0: Outperforms π₀, GR00T-N1, MolmoAct, SmolVLA.
With ZERO changes to the VLM.
🧵⬇️
1
194
Hugo Hadfield retweeted

Jun 10
Wonderful to be back from #CVPR2026, and excited to share the release of our follow-up work:
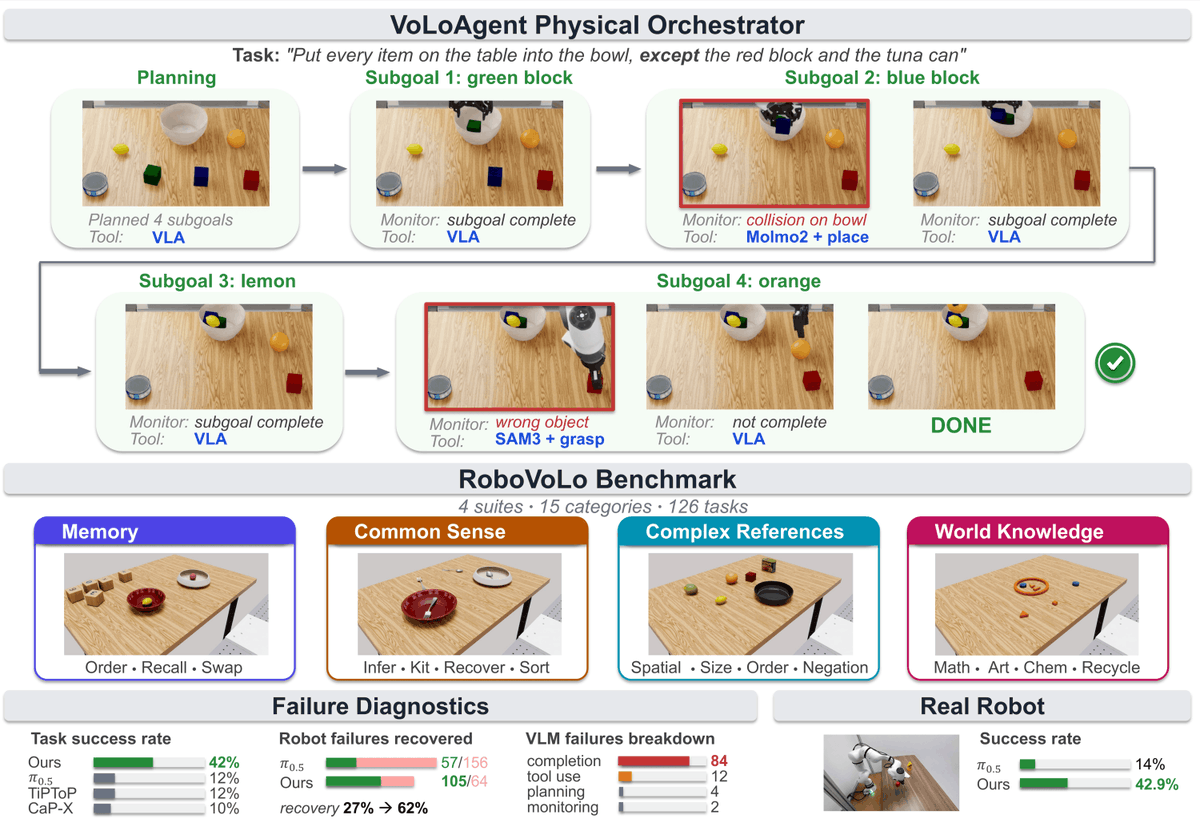
VoLo: A Physical Orchestrator for Open-Vocabulary Long-Horizon Manipulation
VoLo introduces the idea of a physical orchestrator for open-vocabulary, long-horizon manipulation. Our goal is to move toward robots that can reason, plan, act, monitor, and recover by adaptively using VLA/WAMs, vision models, and action primitives as tools.
We introduce three main contributions:
🤖 VoLoAgent — a physical orchestrator that plans, monitors, and recovers by adaptively using, halting, and redirecting robot actions with tools.
📊 RoboVoLo — a high-fidelity benchmark with 126 open-vocabulary long-horizon manipulation tasks spanning common sense, memory/state tracking, complex references, and world knowledge.
📈 A large-scale empirical study comparing action models, code-as-policy systems, TAMP-style systems, and ablations of the VoLoAgent orchestrator, complemented by real-robot experiments.
This work was done during my internship at @NVIDIA and would not have been possible without my brilliant collaborators: Hugo Hadfield, Alexander Zook, @mikacuy, @luke_ch_song, @erwincoumans, @xuningy, Faisal Ladhak, @qu_1006, @BirchfieldStan, Jonathan Tremblay, and @robovalts. Huge thanks to everyone!
🔗 Project: chicychen.github.io/VoLo/
🔗 Previous work, SpaceTools: spacetools.github.io/
#Robotics #EmbodiedAI #VisionLanguageModels #VLAModels #RobotLearning #NVIDIA #CVPR2026 #LongHorizonManipulation #AI #ComputerVision
2
16
72
8,635
Hugo Hadfield retweeted

Apr 21
Evaluation is a critical bottleneck in building robot foundation models. Check out our latest work RoboLab, led by @xuningy, which addresses this exact challenge.
Its a high-fidelity simulation environment for testing these models. A truly generalist policy should be able to complete these tasks zero-shot, and this benchmark highlights exactly how far we still have to go. More info 👇
Apr 20

When every generalist robot model scores 95% on a benchmark, the numbers become meaningless.
What if we built a photorealistic benchmark that never saturates and can generate new scenes and tasks with AI Workflows in minutes?
We introduce RoboLab! 🧵(1/6)
3
11
77
29,708
Hugo Hadfield retweeted

Apr 20
RoboLab comes with RoboLab-120 — a curated, diverse benchmark of 120 tasks to get started.
Set up and run in <20 min. (6/6)
Try it out 👇
🌐 research.nvidia.com/labs/srl…
📄 arxiv.org/abs/2604.09860
💻 github.com/NVLabs/RoboLab
3
21
1,525
Hugo Hadfield retweeted
Apr 20
When every generalist robot model scores 95% on a benchmark, the numbers become meaningless.
What if we built a photorealistic benchmark that never saturates and can generate new scenes and tasks with AI Workflows in minutes?
We introduce RoboLab! 🧵(1/6)
10
27
149
27,786
Hugo Hadfield retweeted

Mar 17
Check out Yash Narang's GTC talk today where he will highlight some of our work on GPU-accelerated multi-arm manipulation planning!
nvidia.com/gtc/session-catal…
github.com/NVlabs/ScheduleSt…
1
4
199
Hugo Hadfield retweeted
15 Dec 2025
Happy to share that the code for VLA-0 is out now: github.com/NVlabs/vla0
Given its simplicity, it’s a great starting point to try out VLAs!
16 Oct 2025
What's the right architecture for a VLA?
VLM custom action heads (π₀)?
VLM with special discrete action tokens (OpenVLA)?
Custom design on top of the VLM (OpenVLA-OFT)?
Or... VLM with ZERO modifications? Just predict action as text.
The results will surprise you.
VLA-0: Outperforms π₀, GR00T-N1, MolmoAct, SmolVLA.
With ZERO changes to the VLM.
🧵⬇️
10
22
268
27,956
20 Nov 2025
Today we have open sourced our training code for vla0, our state of the art VLA with zero modifications. Have a go with it here github.com/NVlabs/vla0
9
1
50
Hugo Hadfield retweeted
16 Oct 2025
Huge thanks to my incredible collaborators:
@HugoHadfield1, Xuning Yang, Valts Blukis, Fabio Ramos
And the amazing teams at NVIDIA @NVIDIARobotics @NVIDIAAI @NVIDIAEmbedded
If you're excited about simple, effective approaches to VLAs:
💻 Code: github.com/NVlabs/vla0 (Coming soon!)
🌐 Page: vla0.github.io
📄 Paper: arxiv.org/abs/2510.13054
2
1
48
2,743
Hugo Hadfield retweeted
16 Oct 2025
What's the right architecture for a VLA?
VLM custom action heads (π₀)?
VLM with special discrete action tokens (OpenVLA)?
Custom design on top of the VLM (OpenVLA-OFT)?
Or... VLM with ZERO modifications? Just predict action as text.
The results will surprise you.
VLA-0: Outperforms π₀, GR00T-N1, MolmoAct, SmolVLA.
With ZERO changes to the VLM.
🧵⬇️
20
76
571
106,541


17 Oct 2024
Built a little automated N'th order derivative package yesterday afternoon as I got a bit tired of dealing with nasty time series data with noisy/missing values and people seem to like it :) github.com/hugohadfield/kalm…
3
77
Hugo Hadfield retweeted

5 Sep 2024
Cool project by @EricWieser to formalize all of the Matrix Cookbook in Lean!
github.com/eric-wieser/lean-…

2
19
108
9,970
17 Jul 2024
Now with blog post write up! hh409.user.srcf.net/blog/len…
15 Jul 2024

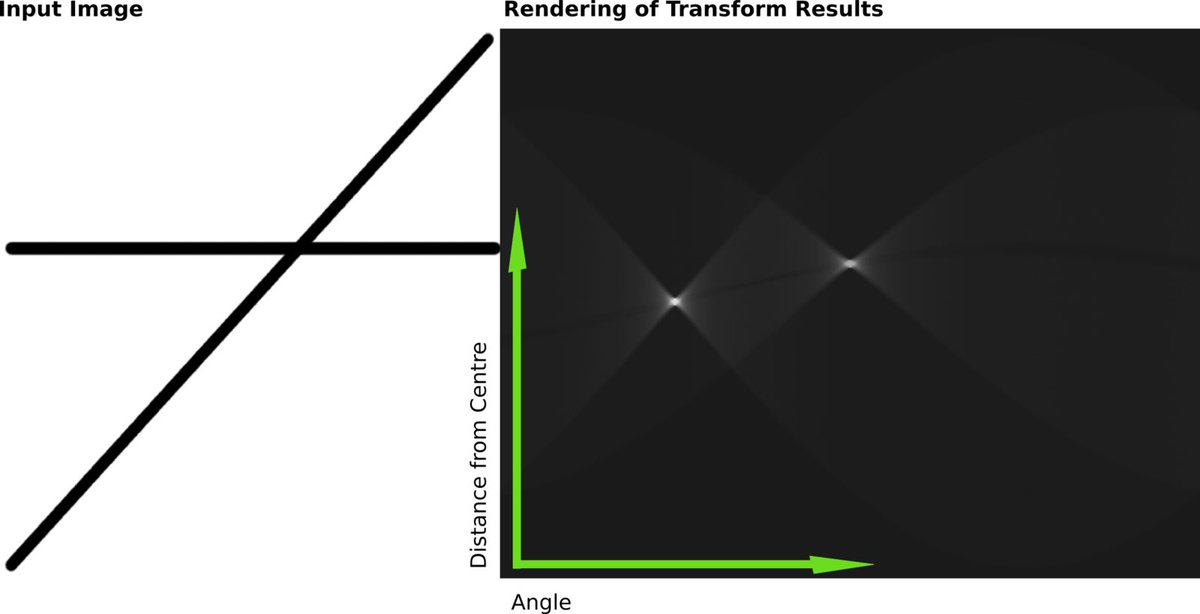
The advantage of this method vs a checkerboard is that 1. You don’t need to stand in the rain in front of your robot holding a massive checkerboard and feeling like an idiot 2. You can just get any old image that has lines and straight edges in and it works 6/n
1
106
15 Jul 2024
Humans can tell when an image has fisheye lens distortion, it just look wrong, like a GoPro video. We can tell if an image is correctly undistorted, all the lines which should be straight are straight. Begs the question, can we make computers understand this too? 1/n
2
1
3
418
15 Jul 2024
The advantage of this method vs a checkerboard is that 1. You don’t need to stand in the rain in front of your robot holding a massive checkerboard and feeling like an idiot 2. You can just get any old image that has lines and straight edges in and it works 6/n
1
214
15 Jul 2024
So how can you actually play with some code that does this? I’ve found this paper ipol.im/pub/art/2016/130/art… which looks well great. I’ve added code fix ups, python binding, and mapping to opencv here: github.com/hugohadfield/Lens…
Would highly recommend having a play, it works great! 7/7
105