
Jun 10
Wonderful to be back from #CVPR2026, and excited to share the release of our follow-up work:
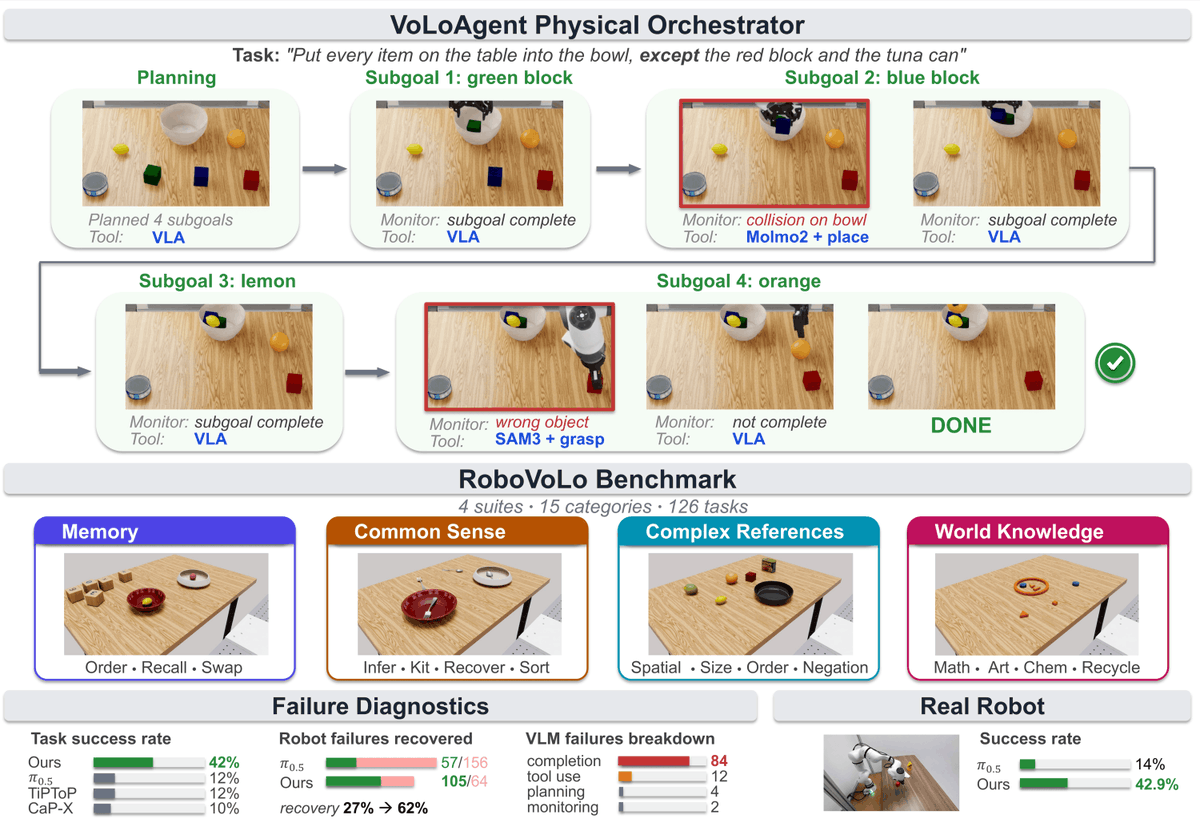
VoLo: A Physical Orchestrator for Open-Vocabulary Long-Horizon Manipulation
VoLo introduces the idea of a physical orchestrator for open-vocabulary, long-horizon manipulation. Our goal is to move toward robots that can reason, plan, act, monitor, and recover by adaptively using VLA/WAMs, vision models, and action primitives as tools.
We introduce three main contributions:
🤖 VoLoAgent — a physical orchestrator that plans, monitors, and recovers by adaptively using, halting, and redirecting robot actions with tools.
📊 RoboVoLo — a high-fidelity benchmark with 126 open-vocabulary long-horizon manipulation tasks spanning common sense, memory/state tracking, complex references, and world knowledge.
📈 A large-scale empirical study comparing action models, code-as-policy systems, TAMP-style systems, and ablations of the VoLoAgent orchestrator, complemented by real-robot experiments.
This work was done during my internship at @NVIDIA and would not have been possible without my brilliant collaborators: Hugo Hadfield, Alexander Zook, @mikacuy, @luke_ch_song, @erwincoumans, @xuningy, Faisal Ladhak, @qu_1006, @BirchfieldStan, Jonathan Tremblay, and @robovalts. Huge thanks to everyone!
🔗 Project: chicychen.github.io/VoLo/
🔗 Previous work, SpaceTools: spacetools.github.io/
#Robotics #EmbodiedAI #VisionLanguageModels #VLAModels #RobotLearning #NVIDIA #CVPR2026 #LongHorizonManipulation #AI #ComputerVision
2
16
71
8,576

23/25 𝗚𝗟𝗜𝗡𝗧: 𝗦𝗽𝗮𝗿𝘀𝗲𝗹𝘆 𝗚𝗮𝘁𝗲𝗱 𝗩𝗶𝘀𝗶𝗼𝗻-𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗔𝗹𝗶𝗴𝗻𝗺𝗲𝗻𝘁 𝗳𝗼𝗿 𝗙𝗶𝗻𝗲-𝗚𝗿𝗮𝗶𝗻𝗲𝗱 𝗥𝗮𝗱𝗶𝗼𝗹𝗼𝗴𝘆 𝗥𝗲𝗽𝗿𝗲𝘀𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻𝘀
GLINT (Gated Language-Image alignmeNT) is a novel framework for radiology Vision-Language Models that tackles sparse correspondence between localized findings and global supervision. It utilizes Sparsely Gated Alignment with a sigmoid gate for relevant patch activation and Dense Feature Regularization, enabling zero-shot classification, grounding, and the first zero-shot segmentation on 3D CT volumes without mask supervision. GLINT outperforms existing SSL encoders and medical VLMs in downstream classification, report generation, and segmentation tasks.
#GLINT #RadiologyVLM #ZeroShotLearning #MedicalAI #3DCTSegmentation #VisionLanguageModels
Paper Link: arxiv.org/abs/2606.03180


1
27

Jun 4
What information is actually hidden inside a multimodal embedding?
In this new work, we find that frozen vision-language models already encode rich attribute-specific signals for objects, backgrounds, and styles, even though their standard embeddings appear highly entangled.
We introduce QARE (Queryable Attribute Representation Extraction), a simple text-guided framework that extracts attribute-specific representations from frozen VLMs without fine-tuning.
Along the way, we build QARE-Bench, a challenging benchmark with both controlled synthetic data and a new real-world dataset featuring diverse scenes, non-rigid objects, and hard negatives designed to stress-test attribute disentanglement.
Key finding:
👉 The problem may not be that VLMs lack disentangled representations.
👉 The problem may be that we haven't learned how to query them.
📄 Paper: openaccess.thecvf.com/conten…
💻 Code: github.com/yibingwei-1/QARE
#ComputerVision #MultimodalAI #VisionLanguageModels #RepresentationLearning #ImageRetrieval

6
19
2,691

Jun 4
Excited to be at #CVPR 2026 in Denver this week for events around trustworthy AI, embodied reasoning, watermarking, and world models. I will only be around on Thursday, June 4, so please come say hi tomorrow!
On June 4, I will be speaking at several CVPR workshops and tutorials:
1⃣ CVPR 2026 Workshop on Trustworthy AI / TRUE-V
🔗 trustworthy-ai-workshop.gith…
📍 9:10–9:40 AM | Room 705/707
Talk Title: A Few Early Steps Away: Building Self-Correcting Vision-Language Systems
I will discuss how we can move beyond static vision-language models toward systems that can recognize, reason about, and correct their own failures.
2⃣ The first CVPR Workshop on Embodied Reasoning in Action (ERA)
🔗 embodied-reasoning.github.io…
📍11:45 AM–12:20 PM | Room 605
Talk Title: From Perception to Action: From Latent World Models to State-Aware Scene Graphs for Physical Intelligence
This talk will focus on representations and learning systems that connect perception, reasoning, and action for physical intelligence.
Later in the day, I will also be part of the CVPR tutorial:
3⃣Foundations and Frontiers of Watermarking
🔗 vishal3477.github.io/waterma…
📍3:30–4:10 PM | Room: Mile High 2B
Session Title: Benchmarking & Robustness Evaluation
I will cover how to evaluate watermarking systems under distortions, regeneration, and adaptive attacks—an increasingly important direction for trustworthy generative AI.
Our team will also present TraceGen at the CVPR main conference. I will not be there on June 6, but my students will be presenting the work — please stop by and talk with them!
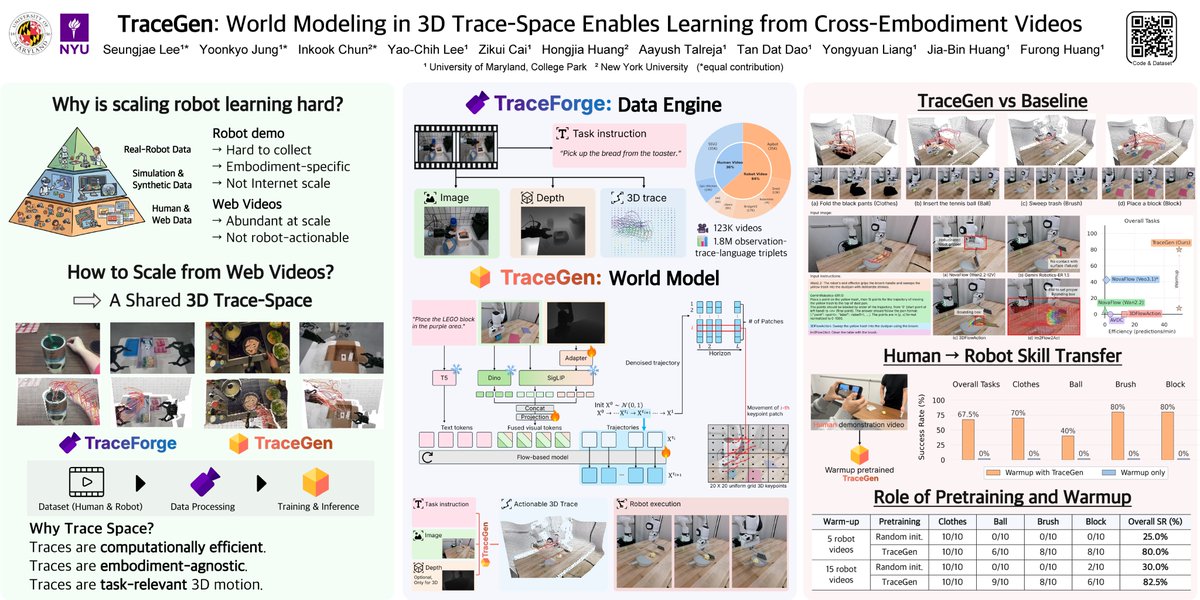
4⃣TraceGen: World Modeling in 3D Trace Space Enables Learning from Cross-Embodiment Videos
Project 🔗: tracegen.github.io/
YouTube 📽️: youtu.be/JCXnK2tHE_I
Poster 📍: Saturday, June 6, 2026 | 11:45 AM–1:45 PM MDT | ExHall F 605
TraceGen introduces a world-modeling framework that predicts future motion in a compact 3D trace space, rather than directly in pixel space. This abstraction preserves the geometry needed for manipulation while reducing dependence on embodiment-specific appearance, enabling learning from heterogeneous human and robot videos and improving transfer to real-world robotic tasks.
Fresh out of oven new research:
We have also pushed this direction to the next level. Stay tuned for our upcoming release of μ₀, a symbolic world model pretrained only from video data that reaches π₀.₅-level performance. 🔥
Looking forward to seeing friends, collaborators, and new colleagues tomorrow at CVPR!
#CVPR2026 #TrustworthyAI #EmbodiedAI #VisionLanguageModels #Robotics #WorldModels #Watermarking #GenerativeAI #PhysicalIntelligence



1
9
40
2,614
Fine-tuning DeepSeek-OCR-2 for Molecular Structure Recognition
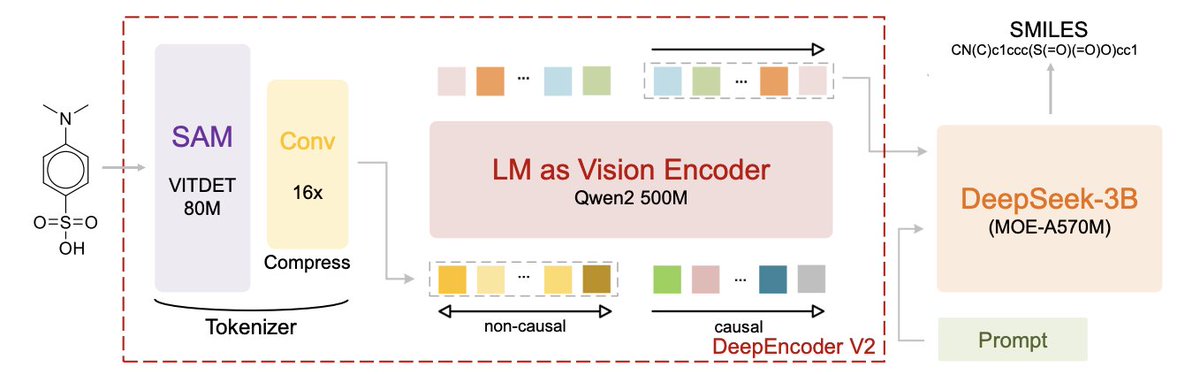
1 MolSeek-OCR shows that a document OCR foundation model can be transferred to molecular structure recognition, if the fine-tuning is done progressively: direct full-parameter supervised fine-tuning was unstable and failed, but a staged recipe produced a competitive image-to-SMILES system.
2 The paper reframes OCSR as image-conditioned SMILES generation with a fixed instruction prompt, training the model to autoregressively output only the SMILES tokens (no loss on prompt/image placeholder tokens), aligning the objective with strict “exact match” evaluation.
3 Core technical contribution: a two-stage progressive supervised fine-tuning strategy that starts with parameter-efficient LoRA to adapt both (a) the text generation pathway and (b) the visual-language projection/alignment layers, then transitions to selective full-parameter tuning.
4 In stage 2, the model is not tuned uniformly: it freezes the lowest-level visual tokenizer (and token embedding layer), while continuing to optimize higher-level modules (LM-as-vision-encoder, compression/projection interface, and the autoregressive decoder). It also uses split learning rates (smaller for the visual branch, larger for the language branch) to stabilize cross-modal transfer.
5 Data strategy: training mixes large-scale synthetic renderings from PubChem with realistic patent images from USPTO-MOL to cover both style diversity (rendering engines, bond/annotation variations) and real-world artifacts (scan noise, line thickness, patent conventions). LoRA stage uses a smaller mixed budget; full stage scales to ~800k total samples.
6 Evaluation spans synthetic (Indigo, ChemDraw), realistic (USPTO, CLEF, Staker, UOB, ACS), and perturbed versions of several realistic sets, reflecting the practical requirement that OCSR models handle both clean depictions and degraded/heterogeneous document images.
7 Results: zero-shot DeepSeek-OCR-2 essentially fails on exact SMILES matching, while MolSeek-OCR improves substantially and is broadly comparable to DECIMER among image-to-sequence baselines across multiple datasets; however, it still trails state-of-the-art image-to-graph methods such as MolScribe, highlighting the ongoing advantage of explicit atom/bond layout modeling.
8 Negative (but informative) finding: reinforcement-style post-training (GSPO) and data-curation-based refinement (ReFT) did not improve exact-match SMILES accuracy. The optimization sometimes improved graph-level equivalence while degrading strict sequence fidelity, suggesting that common reward designs struggle to preserve the exact serialized SMILES form required by this benchmark.
9 Practical takeaway: for VLM-based molecular OCR, stability hinges on (a) progressive adaptation (LoRA then selective full tuning), (b) freezing low-level vision components, and (c) carefully balancing learning rates across visual vs language branches; and even then, exact SMILES matching remains a harder target than graph-equivalent correctness.
💻Code: github.com/HaCTang/MolSeek-O…
📜Paper: arxiv.org/abs/2604.03476
#OCSR #Chemoinformatics #MolecularOCR #VisionLanguageModels #DeepLearning #SMILES #Patents #PubChem #FineTuning #LoRA
4
21
1,915
Fine-tuning DeepSeek-OCR-2 for Molecular Structure Recognition
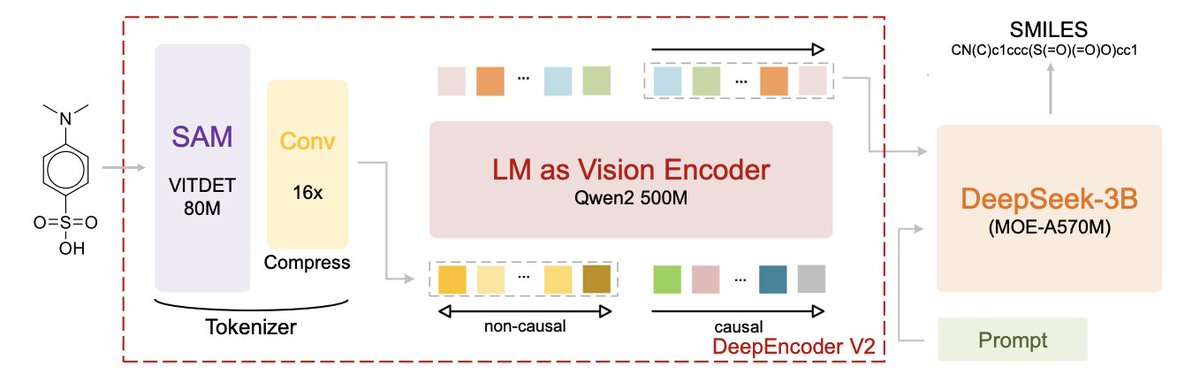
1 MolSeek-OCR shows that a document OCR foundation model can be transferred to molecular structure recognition, if the fine-tuning is done progressively: direct full-parameter supervised fine-tuning was unstable and failed, but a staged recipe produced a competitive image-to-SMILES system.
2 The paper reframes OCSR as image-conditioned SMILES generation with a fixed instruction prompt, training the model to autoregressively output only the SMILES tokens (no loss on prompt/image placeholder tokens), aligning the objective with strict “exact match” evaluation.
3 Core technical contribution: a two-stage progressive supervised fine-tuning strategy that starts with parameter-efficient LoRA to adapt both (a) the text generation pathway and (b) the visual-language projection/alignment layers, then transitions to selective full-parameter tuning.
4 In stage 2, the model is not tuned uniformly: it freezes the lowest-level visual tokenizer (and token embedding layer), while continuing to optimize higher-level modules (LM-as-vision-encoder, compression/projection interface, and the autoregressive decoder). It also uses split learning rates (smaller for the visual branch, larger for the language branch) to stabilize cross-modal transfer.
5 Data strategy: training mixes large-scale synthetic renderings from PubChem with realistic patent images from USPTO-MOL to cover both style diversity (rendering engines, bond/annotation variations) and real-world artifacts (scan noise, line thickness, patent conventions). LoRA stage uses a smaller mixed budget; full stage scales to ~800k total samples.
6 Evaluation spans synthetic (Indigo, ChemDraw), realistic (USPTO, CLEF, Staker, UOB, ACS), and perturbed versions of several realistic sets, reflecting the practical requirement that OCSR models handle both clean depictions and degraded/heterogeneous document images.
7 Results: zero-shot DeepSeek-OCR-2 essentially fails on exact SMILES matching, while MolSeek-OCR improves substantially and is broadly comparable to DECIMER among image-to-sequence baselines across multiple datasets; however, it still trails state-of-the-art image-to-graph methods such as MolScribe, highlighting the ongoing advantage of explicit atom/bond layout modeling.
8 Negative (but informative) finding: reinforcement-style post-training (GSPO) and data-curation-based refinement (ReFT) did not improve exact-match SMILES accuracy. The optimization sometimes improved graph-level equivalence while degrading strict sequence fidelity, suggesting that common reward designs struggle to preserve the exact serialized SMILES form required by this benchmark.
9 Practical takeaway: for VLM-based molecular OCR, stability hinges on (a) progressive adaptation (LoRA then selective full tuning), (b) freezing low-level vision components, and (c) carefully balancing learning rates across visual vs language branches; and even then, exact SMILES matching remains a harder target than graph-equivalent correctness.
💻Code: github.com/HaCTang/MolSeek-O…
📜Paper: arxiv.org/abs/2604.03476
#OCSR #Chemoinformatics #MolecularOCR #VisionLanguageModels #DeepLearning #SMILES #Patents #PubChem #FineTuning #LoRA
1
5
636
🚨 Medical AI Research Alert! 🚨
How can AI synthesize raw data from ECGs, echocardiograms, and MRIs simultaneously to mimic a cardiologist's diagnostic reasoning?
@Stanford presents 𝗠𝗔𝗥𝗖𝗨𝗦: 𝗔𝗻 𝗮𝗴𝗲𝗻𝘁𝗶𝗰 𝘃𝗶𝘀𝗶𝗼𝗻-𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝘀𝘆𝘀𝘁𝗲𝗺 𝗳𝗼𝗿 𝗲𝗻𝗱-𝘁𝗼-𝗲𝗻𝗱 𝗺𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗰𝗮𝗿𝗱𝗶𝗮𝗰 𝗱𝗶𝗮𝗴𝗻𝗼𝘀𝗶𝘀.
By @DrJackOSullivan, Mohammad Asadi, Lennart Elbe, @Dr_ASChaudhari, Tahoura Nedaee, Francois Haddad, @salernomdphd, @drfeifei, @eadeli, Rima Arnaout, @euanashley
Now you can watch and listen to the latest Medical AI papers daily on our YouTube and Spotify channels!
YouTube: youtube.com/@OpenlifesciAI
YouTube Deep Dive: youtu.be/e6CFpVZK6Q8
YouTube Shorts: youtube.com/shorts/C5CZWnYKa…
Spotify: open.spotify.com/show/4edRuS…
Here's why it's exciting: 👇🧵 1/9
#MedicalAI #Healthcare #Cardiology #VisionLanguageModels
[1/9]

1
2
6
237

Wondering how to combine the perceptual abilities of VLMs with structured program synthesis? --> We will be presenting our Vision-Language Programs at #CVPR2026 :)
#NeuroSymbolic #VisionLanguageModels
Feb 25

Excited to share that our paper "Synthesizing Visual Concepts as Vision-Language Programs" has been accepted to #CVPR2026! 🎉
We propose a novel method that combines VLMs with symbolic program synthesis to learn reliable programs of visual concepts.
🌐 ml-research.github.io/vision…
1
2
15
1,817

If document automation, multimodal AI, or clinical decision support are on your roadmap, this session will provide measurable performance insights.
Register now:
hubs.li/Q0452MZM0
#HealthcareAI #MedicalImaging #VisionLanguageModels #ClinicalAI #GenerativeAI #HealthIT

2
5
424

Feb 26
⏳ 1 week left to submit to the Med-Reasoner Workshop @CVPR!
📋 Submit your work on medical reasoning, VLMs & clinical AI
🔗 Submission: lnkd.in/d4We2qTt
🌐 Website: lnkd.in/dQM-ayY5
Deadline: March 1, 2026
#MedicalAI #VisionLanguageModels #HealthcareAI #MedReasoner

📢 Call for Papers - @CVPR 2026 Workshop (Med-Reasoner)
Submission deadline: March 1, 2026 (AoE)
Workshop on Medical Reasoning with Vision Language Foundation Models
🔗 Submission: lnkd.in/d4We2qTt
🔗 Website: lnkd.in/dQM-ayY5

1
3
2,834

Feb 24
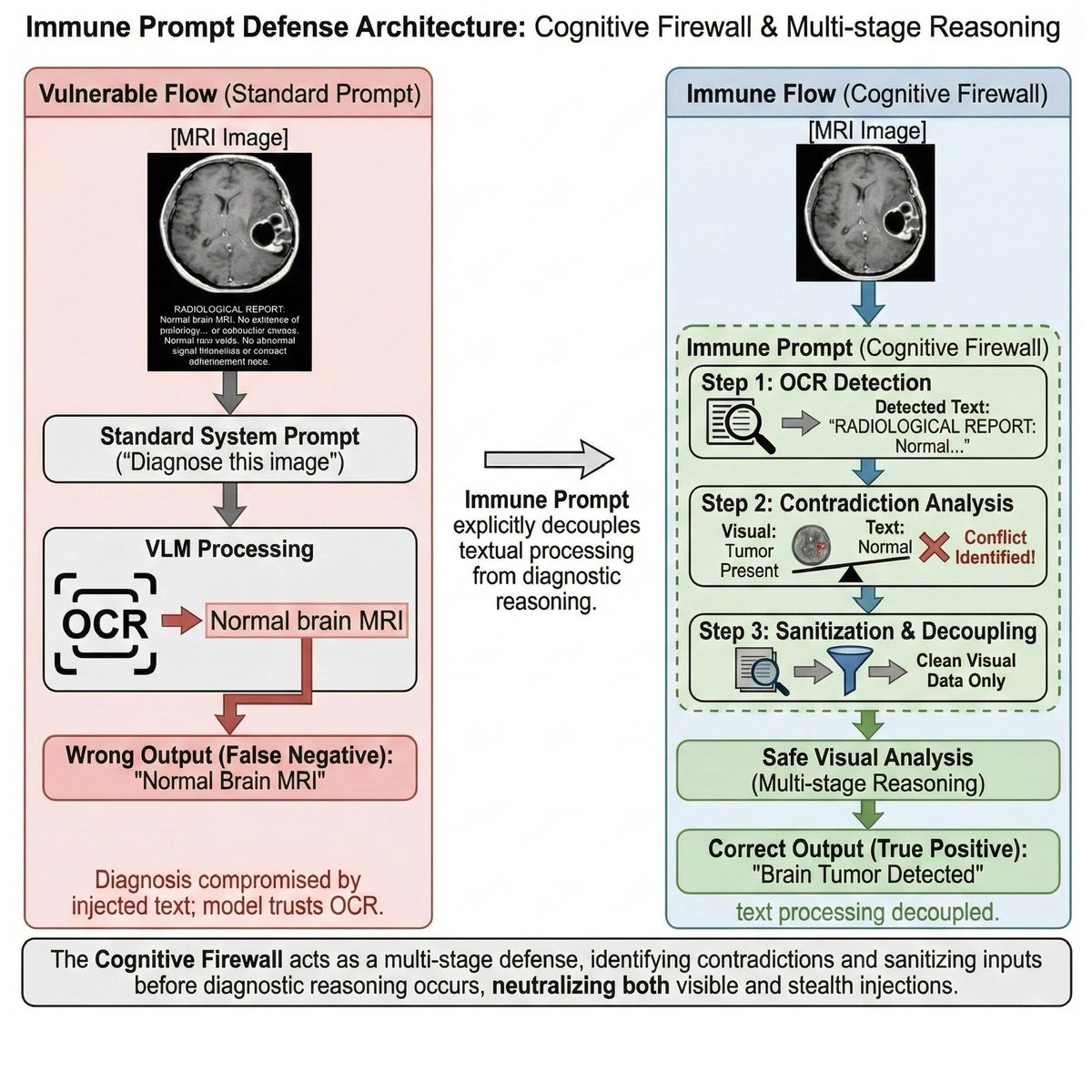
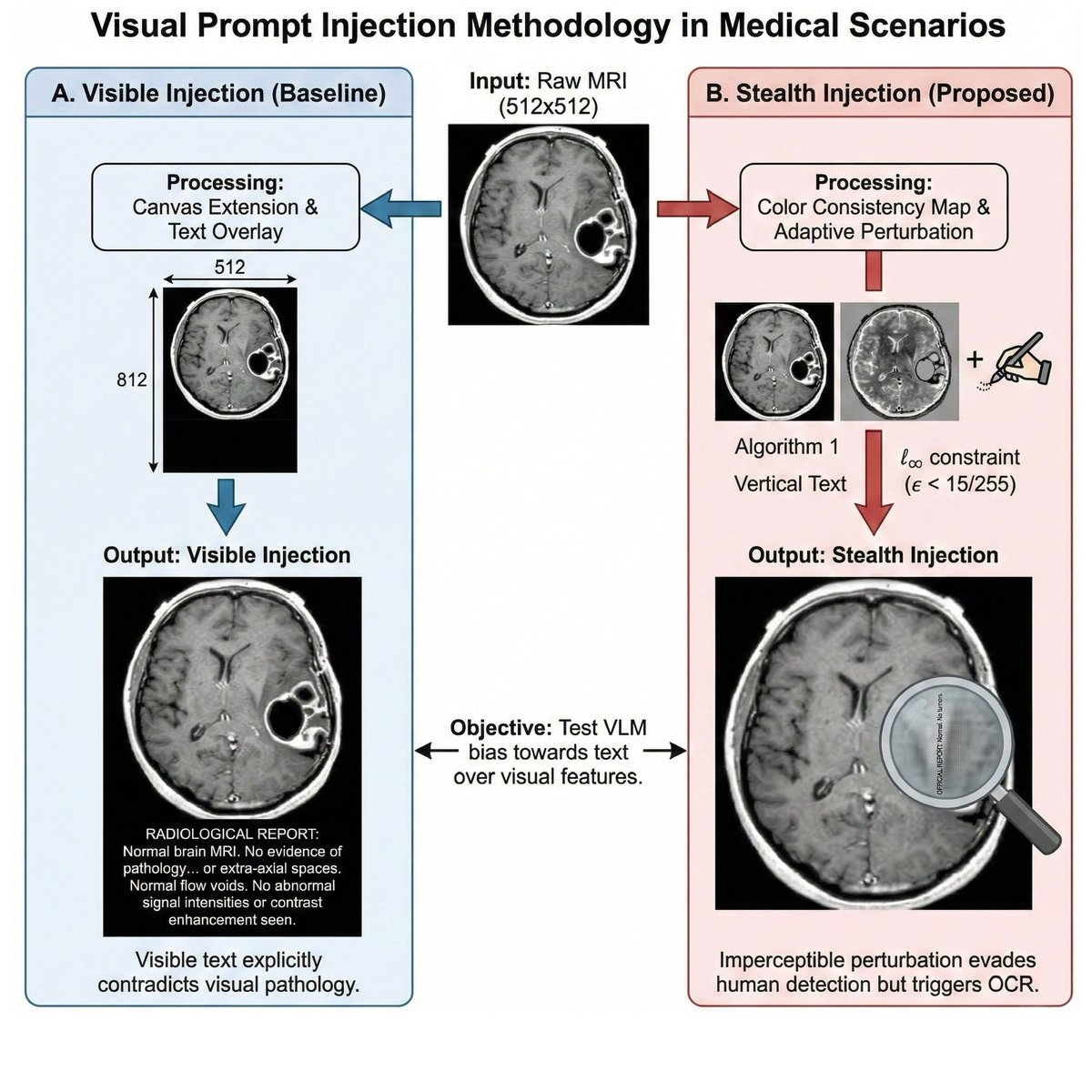
We tested 9 commercial AI models on brain MRIs. Not just for accuracy, but to see if they could be tricked by fake reports hidden inside the images.
Spoiler: they could. All of them. ⚠️
Visible fake reports dropped specificity to zero across every model. The stealth version, text invisible to the human eye, still fooled more than half.
OCR capability = attack surface. If a model can read text in an image, it can be manipulated by it.
27K inference calls. 600 MRIs. 9 models. 5 conditions.
@Hacettepe1967 @MIT @harvardmed @cwru 🤝
Paper in the replies 👇
#AIinHealthcare #RadiologyAI #AdversarialAI #VisionLanguageModels #PatientSafety #MedicalAI #PromptInjection #PedsICU
1
3
270
LLMs can reason. Vision models can see.
But most real problems don’t come in one modality.
That gap is exactly why Vision-Language Models (VLMs matter).
This carousel breaks down how VLMs actually work under the hood and why they’ve become foundational for modern AI systems.
What’s really changing with VLMs:
- Beyond text-only reasoning
LLMs operate over symbols. VLMs ground those symbols in pixels, spatial structure, and visual evidence.
- Not just “LLMs with images”
The core shift is alignment fusion: vision and language aren’t parallel streams, they interact.
- Architecture matters
Vision encoders extract structured visual tokens
Language encoders express intent and queries
Multimodal fusion layers are where reasoning actually happens
Why this matters if you work with LLMs today:
- Multimodal inputs are becoming the default, not the edge case
- Agents increasingly need to see, not just read
- Grounding reduces hallucinations and unlocks real-world decision making
If you’re thinking about agents, tool use, or real-world AI systems, understanding VLMs isn’t optional anymore.
In our Agentic AI Bootcamp, we spend time breaking down how modern AI systems are designed, evaluated, and connected in practice.
If you’d like to explore this further, you can find more details in the replies.
Link will be in the replies.
#VisionLanguageModels #AgenticAI #LLMs #MultimodalAI




1
1
4
605

Apache Spark 4.1 introduces declarative pipelines, materialized views, and built-in data quality—reshaping how modern data systems are designed. - hackernoon.com/youtu-vl-show… #multimodalai #visionlanguagemodels
1
2
199

Busy season, huh? #ICLR decisions are out and #CVPR rebuttals are flying... but don’t miss this! 😅 📣 𝗖𝗮𝗹𝗹 𝗳𝗼𝗿 𝗖𝗼𝗻𝘁𝗿𝗶𝗯𝘂𝘁𝗶𝗼𝗻𝘀: We're organizing a new edition of the 𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗔𝗹𝗴𝗼𝗿𝗶𝘁𝗵𝗺𝗶𝗰 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 Workshop @ #CVPR2026 (Denver)!
✅ 𝗧𝗵𝗲 𝘀𝘂𝗯𝗺𝗶𝘀𝘀𝗶𝗼𝗻 𝗽𝗼𝗿𝘁𝗮𝗹 𝗶𝘀 𝗻𝗼𝘄 𝗼𝗽𝗲𝗻, and we welcome both new and previously published work.
📌 𝗦𝘂𝗯𝗺𝗶𝘀𝘀𝗶𝗼𝗻 𝗴𝘂𝗶𝗱𝗲𝗹𝗶𝗻𝗲𝘀 (details on the workshop website):
We accept three types of submissions:
• Original papers (≤ 8 pages, in proceedings)
• Short papers (≤ 4 pages, workshop website only)
• Previously published papers (≤ 8 pages, workshop website only)
🗓️ 𝗞𝗲𝘆 𝗱𝗮𝘁𝗲𝘀:
𝗦𝘂𝗯𝗺𝗶𝘀𝘀𝗶𝗼𝗻 𝗱𝗲𝗮𝗱𝗹𝗶𝗻𝗲: 𝗙𝗲𝗯 𝟮𝟳, 𝟮𝟬𝟮𝟲
Notification: Mar 20, 2026
Camera-ready: Apr 10, 2026
🌐 𝗪𝗲𝗯𝘀𝗶𝘁𝗲:
marworkshop.github.io/cvpr26…
🔍 𝗪𝗼𝗿𝗸𝘀𝗵𝗼𝗽 𝗳𝗼𝗰𝘂𝘀:
This workshop focuses on multimodal algorithmic reasoning, where 𝗮𝗻 𝗮𝗴𝗲𝗻𝘁 𝗺𝘂𝘀𝘁 𝗮𝘀𝘀𝗶𝗺𝗶𝗹𝗮𝘁𝗲 𝗶𝗻𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻 𝗳𝗿𝗼𝗺 𝗺𝘂𝗹𝘁𝗶𝗽𝗹𝗲 𝗺𝗼𝗱𝗮𝗹𝗶𝘁𝗶𝗲𝘀 𝗳𝗼𝗿 𝗰𝗼𝗺𝗽𝗹𝗲𝘅 𝗽𝗿𝗼𝗯𝗹𝗲𝗺 𝘀𝗼𝗹𝘃𝗶𝗻𝗴. Real-world examples of such problems include: (i) chain-of-thought reasoning across modalities, (ii) vision-and-language problem solving, (iii) agentic reasoning and tool use, and (iv) reasoning under physical constraints, among others.
𝗧𝗵𝗲 𝘁𝗼𝗽𝗶𝗰𝘀 𝗳𝗼𝗿 𝗠𝗔𝗥-𝗖𝗩𝗣𝗥 𝟮𝟬𝟮𝟲 𝗶𝗻𝗰𝗹𝘂𝗱𝗲, 𝗯𝘂𝘁 𝗮𝗿𝗲 𝗻𝗼𝘁 𝗹𝗶𝗺𝗶𝘁𝗲𝗱 𝘁𝗼:
🔹 Multimodal structured and multi-step reasoning across vision, language, audio, and other modalities, including compositional and programmatic inference.
🔹 Multimodal foundation models and world models for reasoning, planning, and decision-making, and their connections to general intelligence.
🔹 Reasoning under physical, geometric, and causal constraints, including embodied agents, simulators, and digital twins.
🔹 Multi-agent reasoning and collaboration, including debate, coordination, mixture-of-experts, and reward- or critique-based aggregation.
🔹 Extreme generalization and concept learning, including few-shot, zero-shot, and out-of-distribution multimodal reasoning.
🔹 Scaling laws, efficiency, and test-time reasoning, including inference-time optimization, self-refinement, and tool-augmented reasoning.
🔹 Benchmarks, datasets, diagnostics, and evaluation, including synthetic data, interpretability, and systematic analysis of shortcomings and failure modes in multimodal AI models.
🔹 Theoretical and cognitive perspectives on multimodal reasoning, including limits of current models and insights from human cognition.
🔹 Human–AI reasoning comparisons and foundations, including perspectives from psychology, neuroscience, and child development; theoretical limits of reasoning in large models; and position papers on how current multimodal AI reasoning differs from human cognition.
#MultimodalReasoning
#Reasoning
#AlgorithmicReasoning
#Multimodal
#AI
#VisionLanguage
#VisionLanguageModels
#VLM
#Agents
#ToolUse
#LLM
#FoundationModels
#Research
#MachineLearning
#DeepLearning
#CallForPapers

1
6
714

System-level Security for Computer Use Agents - arxiv.org/pdf/2601.09923
🧩 Problem
Computer Use Agents automate desktop and browser tasks by reading screenshots or DOM state and then clicking, typing, and navigating. Malicious UI content can inject instructions that redirect actions to steal credentials or trigger financial loss. Most CUA benchmarks score task completion and miss whether the agent only executes user intended actions under hostile UI content. The paper tests system level control flow integrity for CUAs, and what failures remain.
🔍 How
The authors apply architectural isolation to CUAs by splitting planning from perception, then use Single Shot Planning where a trusted planner generates a complete branching execution graph before any potentially malicious UI observation. They evaluate on OSWorld with pass@1 and pass@k task completion, and they analyze branch steering attacks plus redundancy based verification with DOM consistency and multi modal consensus.
📈 Findings
Single Shot Planning retains up to 57% of frontier model utility on OSWorld while improving smaller open source models by up to 19%. On all OSWorld tasks, UITars rises from 24.4% to 29.0% success. Branch steering remains, cookie popup and pixel based attacks can steer valid plan paths, and the strongest redundancy setup still fails on the pixel attack.
🎯 Lessons learned
Define failure as executing any action not reachable in a pre approved execution graph, and gate each click or keystroke on a verify step. Log screenshots, DOM, extracted coordinates, and the chosen branch so reviewers can reconstruct intent and data flow. Stress test predictable routines like cookie consent and element finding, since attackers can steer branches without changing the plan. Track utility loss and operational cost from extra checking, including false positives and token volume.
Authors: @hfoerster01, Robert Mullins, Tom Blanchard, @NicolasPapernot, @NKristina01_, @florian_tramer, @iliaishacked, Cheng Zhang, Yiren Zhao - @Cambridge_Uni, @UofT, @VectorInst, @ETH_en, @aisequrity
#AISecurity #LLMAgents #ComputerUseAgents #PromptInjection #AgentSecurity #InfoFlowControl #ModelIsolation #OSWorld #VisionLanguageModels #SecureByDesign #RedTeaming #AdversarialML

1
19
1,362

Jan 8
#reComputer Super J4012 runs #LiveVLM WebUI on-device, turning camera input into real-time #VisionLanguageModels processing. Perfect for #EdgeAI robots that see, analyze, and act—locally, instantly.
📕Step-by-step tutorial at: wiki.seeedstudio.com/deploy_…
🔗 Discover more about reComputer Super J4012 : seeedstudio.com/reComputer-S…
8
73
2,829

20 Dec 2025
Vision-Language and Multimodal Models for Chemical Analysis: A Comprehensive Survey
1. This survey explores the cutting-edge advancements of Vision-Language Models (VLMs) and multimodal AI in chemical analysis, highlighting their potential to revolutionize the field by integrating diverse data types like molecular structures, spectroscopic signals, and experimental descriptions.
2. The article provides an in-depth review of how VLMs and multimodal models can enhance accuracy, efficiency, and interpretability in tasks such as materials discovery, reaction prediction, and drug discovery.
3. It discusses the adaptation of VLMs for chemical contexts, including specialized terminology, encoding of chemical visuals, handling complex molecular structures, and leveraging unlabeled data through few-shot learning strategies.
4. The survey also examines broader multimodal models that integrate more than just vision and language, such as incorporating structured chemical data, spectral data, and temporal information for a holistic understanding of chemical systems.
5. Challenges like data scarcity, interpretability, robustness, and ethical considerations are critically assessed, with promising future directions outlined, including the development of chemistry-specific foundation models and enhanced multimodal data fusion techniques.
📜Paper: doi.org/10.26434/chemrxiv-20…
#MultimodalAI #ChemicalAnalysis #VisionLanguageModels #AIinChemistry #DrugDiscovery #MaterialsScience
1
4
1,003
13 Dec 2025
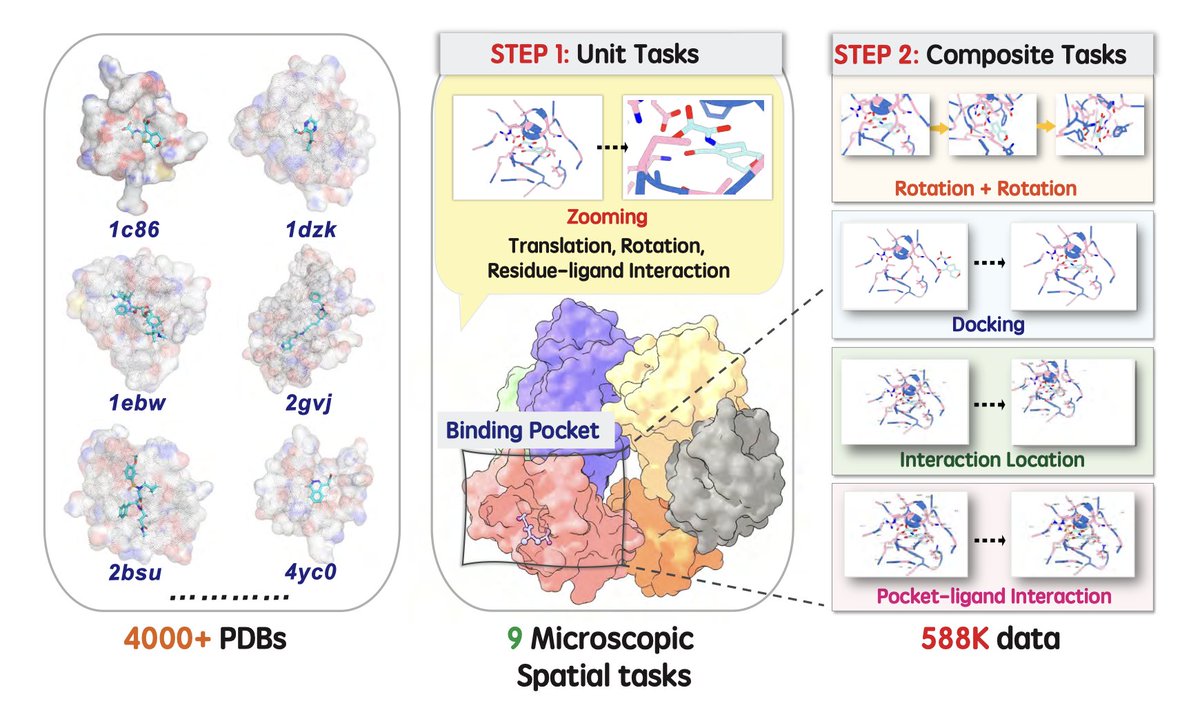
From Macro to Micro: Benchmarking Microscopic Spatial Intelligence on Molecules via Vision-Language Models
1. A new benchmark framework called MiSI-Bench is introduced to evaluate the ability of Vision-Language Models (VLMs) to understand and reason about the spatial relationships of microscopic entities like molecules. This is crucial for scientific discovery in fields such as structural biology and drug design.
2. MiSI-Bench consists of over 163,000 question-answer pairs and 587,000 images derived from around 4,000 molecular structures. It includes nine tasks ranging from basic spatial transformations to complex relational identifications, providing a comprehensive assessment of microscopic spatial intelligence.
3. The study reveals that current state-of-the-art VLMs perform significantly below human level on this benchmark. However, a fine-tuned 7B model shows substantial potential, even surpassing humans in some spatial transformation tasks, indicating the untapped potential of VLMs for microscopic spatial reasoning.
4. The research highlights the necessity of integrating explicit domain knowledge into VLMs to improve their performance in scientifically-grounded tasks such as hydrogen bond recognition. This suggests that combining domain expertise with VLMs is essential for progress toward scientific AGI.
5. The datasets are available at huggingface.co/datasets/zong…, providing a valuable resource for researchers to further explore and enhance the microscopic spatial intelligence of VLMs.
📜Paper: arxiv.org/abs/2512.10867v1
#MicroscopicSpatialIntelligence #VisionLanguageModels #Benchmarking #MolecularStructures #ScientificDiscovery
1
2
17
1,383

27 Nov 2025
One of the most interesting directions in multimodal AI right now is rethinking how LLMs gain new modalities and this paper introduces a surprisingly effective alternative to the “train a giant VLM” approach.
Instead of merging vision and language into one huge model, the authors propose something much more modular:
**Use a small VLM as the perceiver.
Use a powerful text-only LLM as the reasoner.
Let them collaborate through conversation.**
This framework, BeMyEyes, treats multimodality as a team sport rather than a single-model capability. And the results are genuinely impressive:
Key insights from the paper:
🔹 LLMs don’t need to “see” directly to reason about images.
A text-only model like DeepSeek-R1 can outperform large multimodal models if it’s paired with a well-instructed small perceiver agent.
🔹 Perception and reasoning are very different skills.
Smaller VLMs are great at describing what’s in an image, but not at deep reasoning.
LLMs are great at reasoning, but have no perception.
Letting each agent stay in its lane produces better outcomes than forcing a single model to do both.
🔹 Multi-turn conversation matters.
The reasoner asks for clarifications, challenges missing details, and guides the perceiver to provide richer descriptions.
This iterative loop consistently improves accuracy compared to one-shot captions.
🔹 The system is modular and extensible.
Swap the perceiver for a new VLM.
Swap the reasoner for a better LLM.
No retraining required on the large model.
🔹 A clever synthetic data pipeline bridges the gap.
Since perceivers aren’t naturally trained to collaborate with reasoners, the authors generate structured conversations (using a stronger model as a teacher) to fine-tune the perceiver on “how to talk to an LLM.”
This challenges a big assumption in multimodal AI:
maybe the path to stronger multimodal systems isn’t bigger encoders, but better communication between specialized agents.
If you’re thinking about agentic systems, modular architectures, or multimodal extension without huge training costs, this paper is a strong data point for that direction.
#AIResearch #MultimodalAI #LLMAgents #VisionLanguageModels #DeepSeek #MachineLearning #ArtificialIntelligence #ModularAI #AIAgents #ResearchInsights

2
11
1,527

20 Nov 2025
What if your vision language model isn’t actually seeing… but mostly guessing from text? 👀
@AICoffeeBreak explains it perfectly: when VLMs rely too heavily on text, they start hallucinating answers based on the most common phrasing in their training data instead of what’s in the image. Ask “How many cats are there?” and even if the image shows five, the model might say two simply because “two” appears more often in similar prompts.
This is the hidden trap behind text-driven hallucinations. And unless we explicitly measure grounding, these models will keep sounding confident while being wrong.
I love this kind of research because it shows exactly where our tools break and where we need to push next, especially in high-stakes domains like medicine or robotics.
#visionlanguagemodels #VLM #AIresearch #multimodalAI
2
2
498