
computational & experimental neuroscience/CS lab at UC Berkeley. fMRI language machine learning. Looking for students and postdocs! PI: @alex_ander
Joined December 2016
- Tweets 9
- Following 8
- Followers 494
- Likes 2
Photos and videos
Huth Lab retweeted

24 Aug 2023
Our ✨Large-scale fMRI dataset on naturalistic language✨is now out in Nature Scientific Data!
MANY hours (5 to 16 per indiv) on MANY ppl (8 indiv)!
We also included code to fit encoding models exactly like all @HuthLab papers!
Pls read @alex_ander's awesome thread on...
1/2
23 Aug 2023

Our big language fMRI dataset is now officially published!
📰 The paper: nature.com/articles/s41597-0… (free pdf: nature.com/articles/s41597-0…)
🧰 Code to download data & build models: github.com/HuthLab/deep-fMRI…
💾 The dataset: openneuro.org/datasets/ds003…
1
4
24
2,447
Huth Lab retweeted

1 May 2023
Our language decoding paper (@AmandaLeBel3 @shaileeejain @alex_ander) is out! We found that it is possible to use functional MRI scans to predict the words that a user was hearing or imagining when the scans were collected nature.com/articles/s41593-0…
15
77
214
43,374
Huth Lab retweeted

4 Nov 2022
Why are language models so great at encoding brain responses to natural language?
In our new paper (bit.ly/3Ua8MLK), we explore two new correlates of encoding performance and their implications on cognitive theories of language processing. (1/12)
3
65
220
Huth Lab retweeted
30 Sep 2022
very excited to share our paper on reconstructing language from non-invasive brain recordings! we introduce a decoder that takes in fMRI recordings and generates continuous language descriptions of perceived speech, imagined speech, and possibly much more biorxiv.org/content/10.1101/…
52
443
2,195
Huth Lab retweeted

24 Sep 2022
New Dataset Alert!
I'm very happy to official announce a naturalistic language fMRI dataset now available! This dataset includes 8 participants listening to 5 hours each of the moth radio hour. biorxiv.org/content/10.1101/…
3
58
226
Huth Lab retweeted
22 Oct 2020
Excited to attend my first #SNL2020 today and learn from *real* neuroscientists! Come hear me talk about some new research on **Discovering patterns of semantic integration across the🧠** :)
Slide session B (11:30-13:00 hrs PT): 2020.neurolang.org/?p=slides…
7
2
22
Huth Lab retweeted

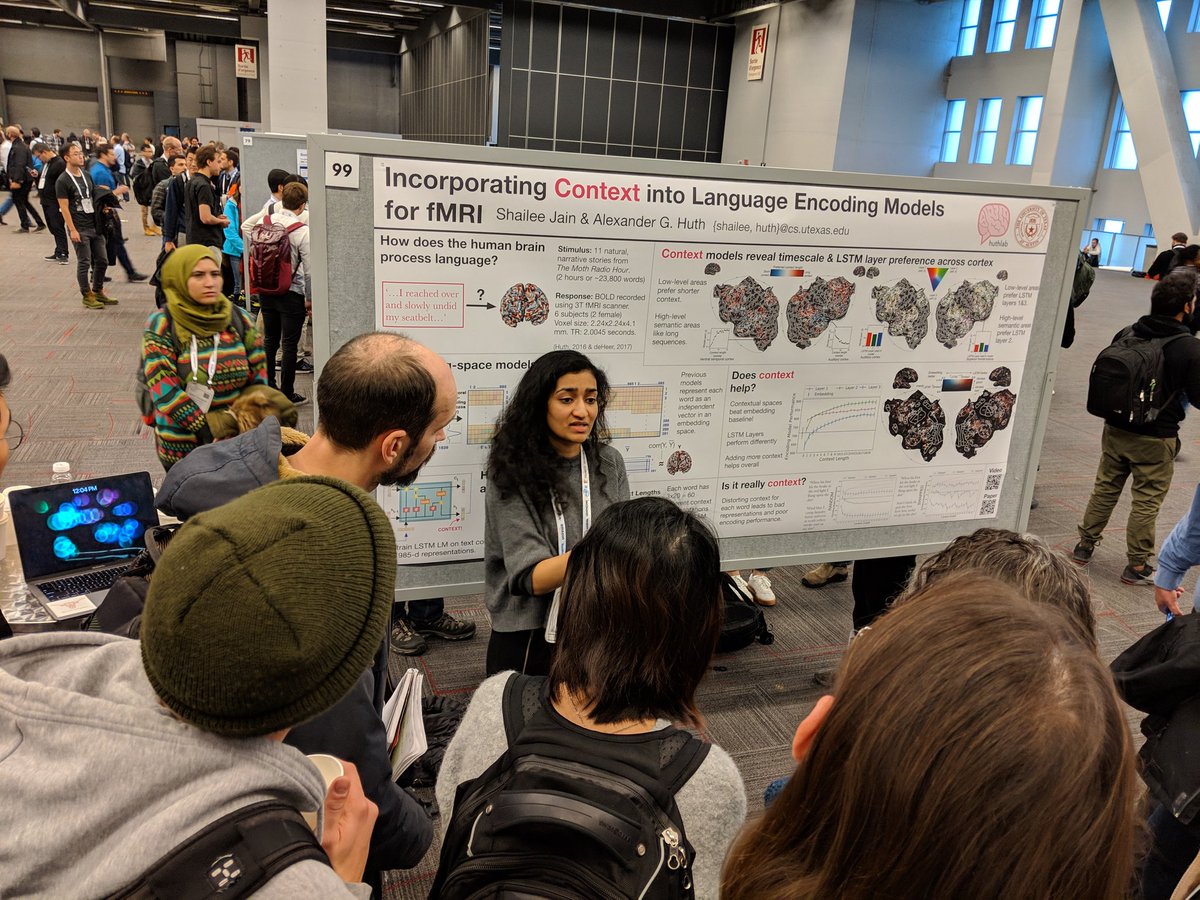
6 Dec 2018
Cool poster from @shaileeejain and @alex_ander using LSTM models to include contextual information in language encoding models! Finally some actual neuroscience @ #NeurIPS2018
1
3
21

It was the first preprint, now it’s gonna be the first paper from our lab!
7 Sep 2018
Coming to NIPS this year: @shaileeejain’s paper on using LSTM language models for predicting fMRI data!
1
4
Huth Lab retweeted

22 May 2018
ayy it's the first preprint from my lab! 🎉 @shaileeejain uses LSTM language models to generate features that incorporate context & are better at predicting brain activity than word embeddings x.com/biorxiv_neursci/status…
21 May 2018

Incorporating Context into Language Encoding Models for fMRI biorxiv.org/cgi/content/shor… #biorxiv_neursci
2
25
76