
Part Entrepreneur, Investor & Start-Up Fanatic...Part Dalai Lama Groupie & Weekend Yogi. Opinions are my own.
Joined January 2008
- Tweets 4,239
- Following 852
- Followers 2,011
- Likes 5,765
760 Photos and videos

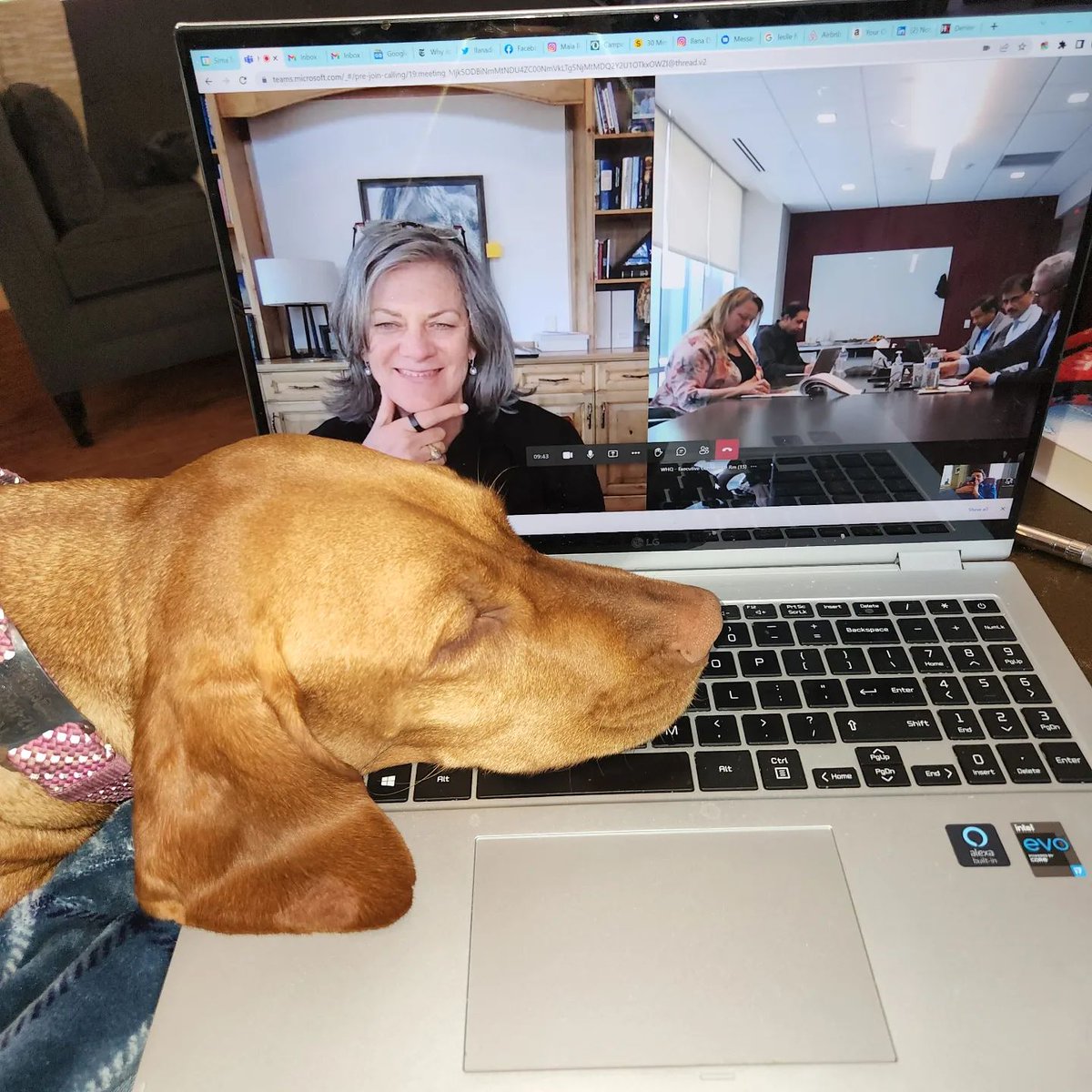


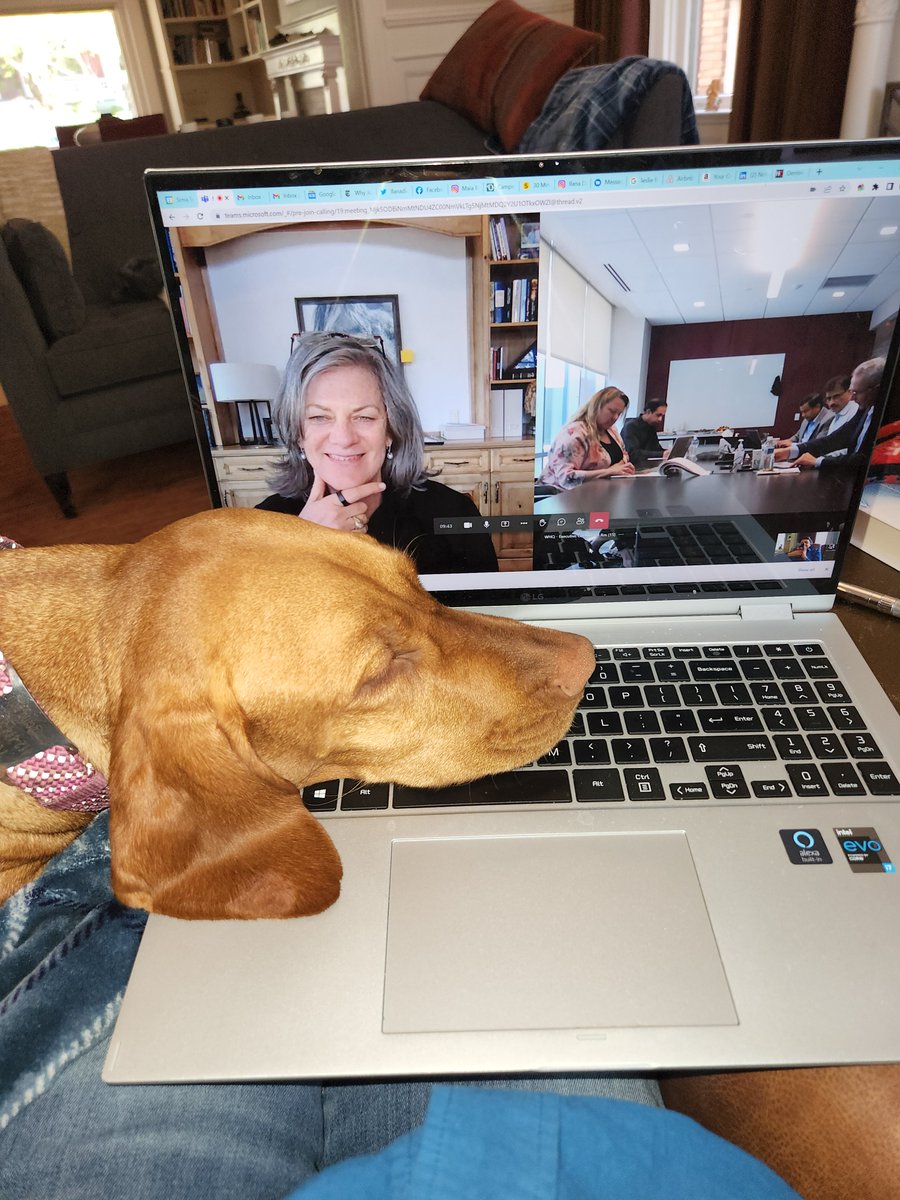











And the winners of this year’s #ReedAwards are...@JonMingle and @JaredKofsky, @Maia_Rosenfeld, & @SteveOsunsami. Their work demonstrates the power of writing to capture some of the most important environmental issues facing the South: southernenvironment.org/news…
1
4
5
456
Ilanadiamond retweeted

9 May 2024
Almost forgot the obligatory self-promotion...
I'll be presenting this work this afternoon at ICLR, poster #148. Stop by to gain a new understanding of NN optimization!
24 Nov 2023

What causes sharpening Edge of Stability?
Why is Adam > SGD?
How does BatchNorm help?
Why is 1-SAM > SAM > SGD for generalization?
What is Simplicity Bias, really?
Our new work doesn’t answer these questions (well, 𝘮𝘢𝘺𝘣𝘦 the first one)
But it suggests a common cause...

4
41
5,760

12 Apr 2024
From my favorite journalist
12 Apr 2024

In October, we told you about Shiloh, a Black community in rural AL dealing with flooding they say was caused by a state highway project.
Last week, @SecretaryPete paid them a visit & said they "need to be taken care of."
@JaredKofsky @SteveOsunsami @ABC abcnews.go.com/US/buttigieg-…
65
Ilanadiamond retweeted

31 May 2023
Some interesting insights on ChatGPT feat. a classic @RoniRosenfeld use case (link in article to an exclusive Q&A with GPT itself)
marketwatch.com/story/using-…
2
1
360
Ilanadiamond retweeted
25 May 2023
A huge thank you to @NABJ for recognizing The Model City. Proud of the team & the important story the Louisville community helped us to tell.
@krod65 @carriecochran @eklib @MarenMachles @zcusson @rosiecima @Ellen_weiss @JournoKateH @LCKnapp @marktfahey @AmberCStrong & many others
23 May 2023

🥁 Drumroll please! #NABJ announces its 2023 Salute to Excellence Awards nominees. 🏆Winners will be announced at #NABJ23 in Birmingham this August! Congrats to all!
Read more: nabjonline.org/blog/nabj2023….

ALT NABJ Salute to Excellence Awards Nominees
5
9
705
Ilanadiamond retweeted
11 May 2023
Very excited to see our documentary The Model City on this list & honored to be part of the village that brought it to life: @krod65 @carriecochran @eklib @MarenMachles @zcusson @rosiecima @Ellen_weiss @JournoKateH @LCKnapp @marktfahey @AmberCStrong & more
scrippsnews.com/stories/the-…
10 May 2023

The 2023 National Headliner Award winners have been announced! Please go to our website at headlinerawards.org for this list of this year's winners. Thank you to all who entered this year's contest featuring the best journalism of 2022.
3
11
882
Ilanadiamond retweeted
5 May 2023
Our team is diving into the affordable housing crisis in cities across the country. Check out my piece on Philly with @TaRhondaThomas & keep an eye out for others from across @ABC over the next week!
6abc.com/housing-crisis-affo…
3
6
746
Ilanadiamond retweeted
4 May 2023
Hear more about our investigation into long subsidized housing wait times on today's episode of @StartHereABC
abcnews.go.com/US/start-here…
1
3
258
5 May 2023
Unbelievable and very sad....
3 May 2023
Millions of Americans have waited years--even decades--for an affordable place to live. We talked with some of them to hear how these long waits have affected their lives.
Read our article & catch the piece on @ABCNewsLive tonight! @JaredKofsky @sramosABC abcnews.go.com/Politics/cry-…
128
27 Apr 2023
Protect your #WordPress sites from cyber threats - this article shows how secure it with @vali_cyber's ZeroLock platform. #SecureWordPress #Linux #security #cybersecurity
24 Apr 2023

Is your #WordPress website secure? With 43% of all websites on the internet powered by WordPress, it’s no surprise that #cybercriminals target it. But fear not—Vali Cyber's ZeroLock platform is here to protect your website and reputation. 🛡️ linuxsecurity.com/features/s…
Check out our latest article from @lnxsec to learn how ZeroLock can keep your site safe from exploits and vulnerabilities. Don’t let cyber threats compromise your business. Click the link to get started.
#SecureWordPress #Linux #cybersecurity #security #infosec
1
91
10 Apr 2023
TLDR:- Pittsburgh and Atlanta are leading the nation’s tech scene - Seattle, Chicago & Miami are next in line.
vcbrags.com/2023/03/10/silic…
1
3
213
16 Feb 2023
Exciting news from @412VF portfolio company @vali_cyber!
13 Feb 2023
📣 It’s out! Read the latest news on ZeroLock from LinuxSecurity.com.
#Linux security expert, Dave Wreski, test drove ZeroLock and was, "very impressed with how ZeroLock addresses the shortcomings of traditional Linux endpoint security agents [...]" linuxsecurity.com/features/z…
1
4
163
18 Jan 2023
3
18
305
11,768
Ilanadiamond retweeted
5 Dec 2022
Janine & Corey Ricks love coming home to their new property in Del. But they don't take it for granted: They almost didn't get the house after their old home was appraised at 35% below contract price, killing its sale.
Our analysis shows they're not alone:6abc.com/our-america-lowball…
2
2
1 Dec 2022
30 Nov 2022

A new paradigm in fitness: 3D resistance training and new normative datasets from @proteusmotion @samueladamiller @EricCressey sporttechie.com/proteus-moti…
1
4
Ilanadiamond retweeted
21 Nov 2022
Keep an eye out for our Neighborhood Safety Tracker, which will let you explore these rates and trends for yourself. Coming soon!
21 Nov 2022

In the last year, Temple-area home invasions has a rate of 739 burglaries per 100k residents. That's almost *double the current citywide rate. But it's actually down 10.5% from the average over the last three years. @6abc @maia_rosenfeld
1
4
Ilanadiamond retweeted
8 Nov 2022
More than 1 in 5 Philly area households couldn't pay an energy bill in the last year. Rates were even higher among Philadelphians of color & those with disabilities.
Check out my latest w/ @nydia_han to learn about this issue & local solutions: 6abc.com/energy-utility-bill… via @6abc
3
3