
Live GPU-price & inference latency intel. Tracking the #InferenceWars so your LLMs run faster cheaper. Friday brief.
Joined June 2025
- Tweets 205
- Following 110
- Followers 41
- Likes 29
10 Photos and videos








Pinned Tweet

May 23
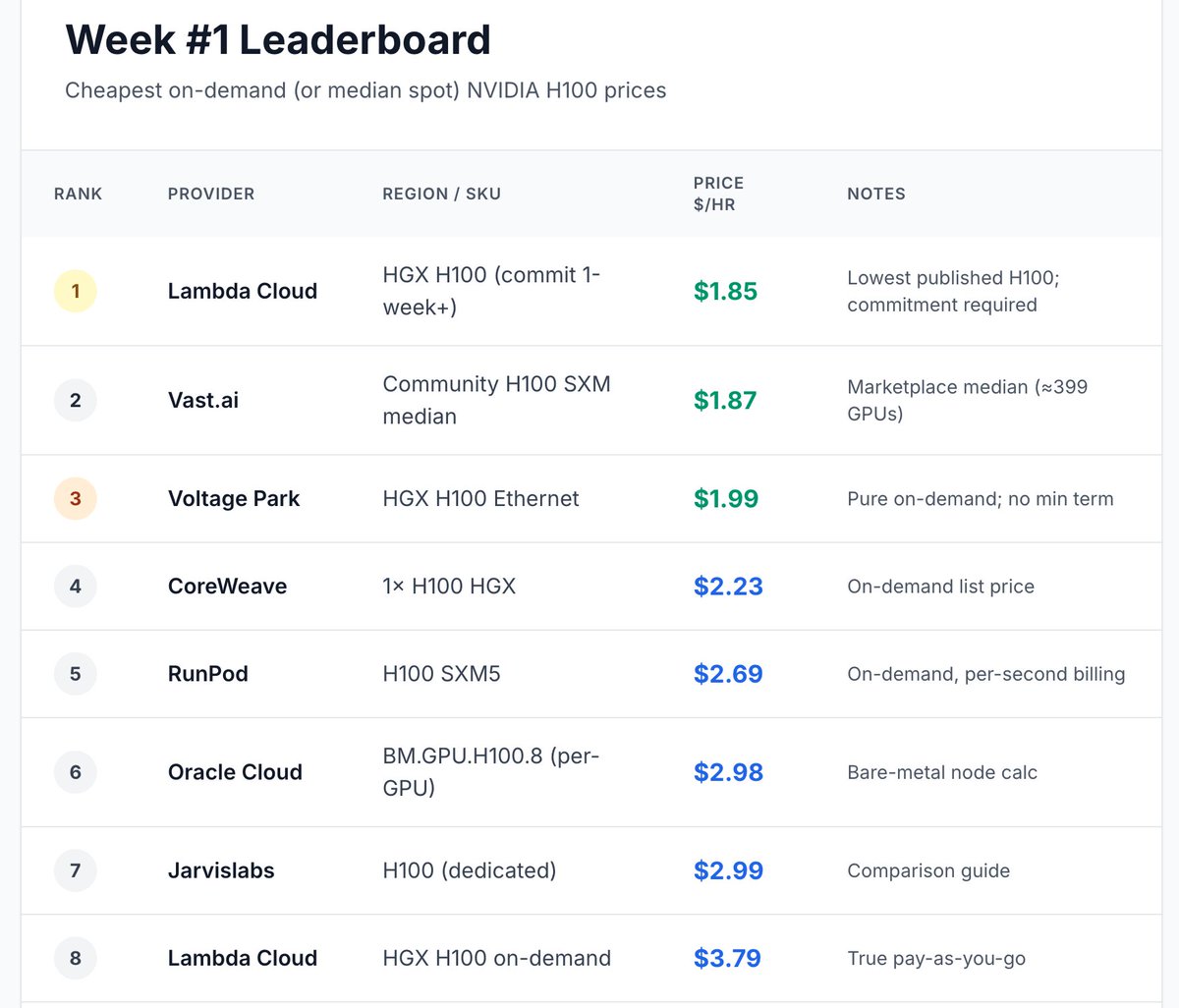
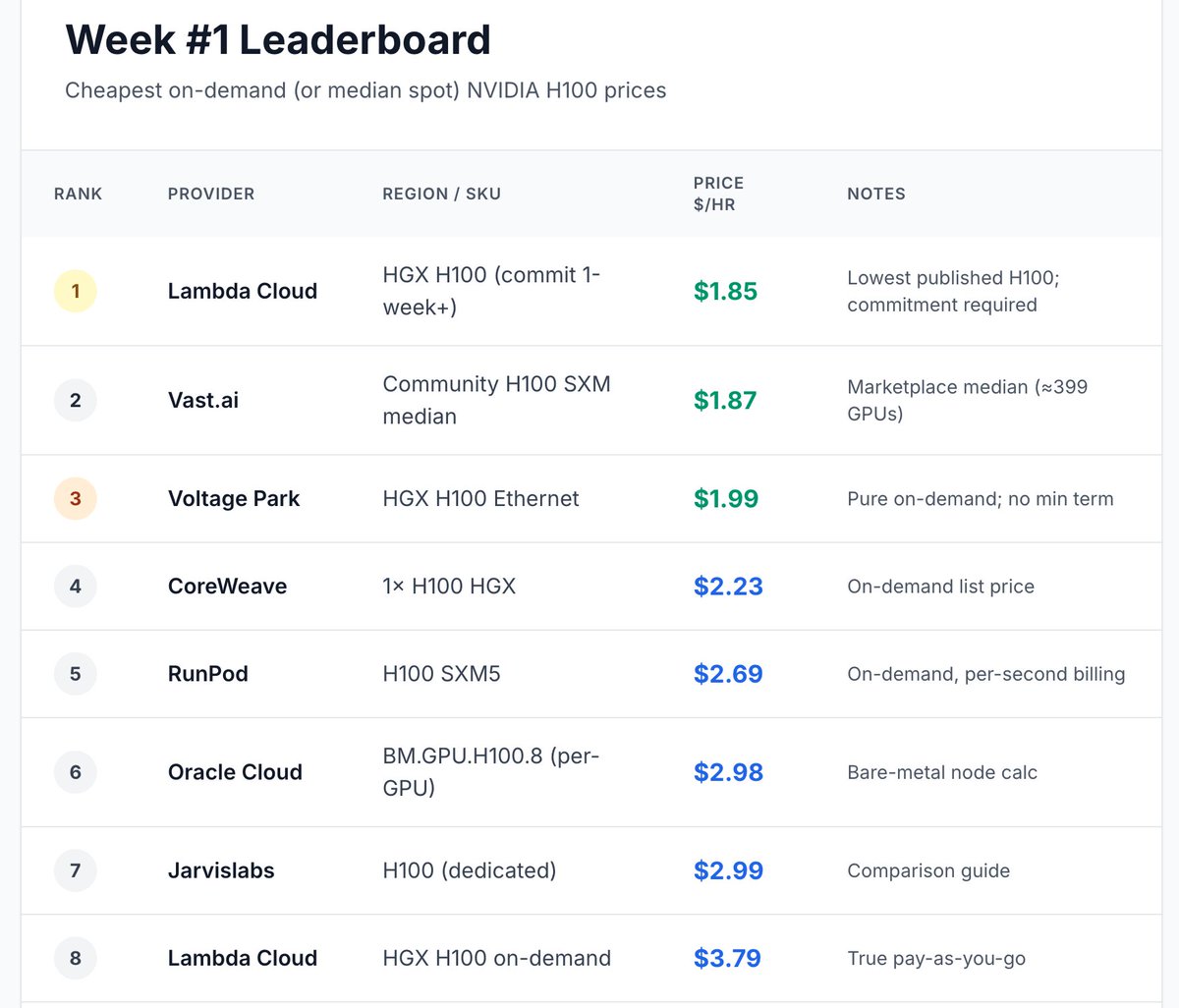
🛰️ Inference War - Week #48
The war moved again.
Not model access.
Not API wrappers.
Not benchmark theatre.
This week was about compute allocation.
Key signals:
• Google Blackstone launching TPU compute-as-a-service
• Anthropic reportedly paying SpaceX $1.25B/month for inference capacity
• SpaceX positioning spare compute as an infrastructure revenue stream
• Anthropic Mythos moving into financial-stability oversight
• Cerebras getting public-market validation
• Nvidia absorbing specialist inference pressure through Groq licensing
The new question is no longer:
“Which model is best?”
It’s:
Who has guaranteed access to enough inference capacity, in the right geography, under the right governance model, at the right cost?
Inference is becoming an industrial resource.
#InferenceWars #AIInfra #Inference #Compute #AIInfrastructure #Datacenters #GPUs
29
Jun 13
🛰️ INFERENCE WAR - WEEK #51
The war moved again.
Not models.
Not GPUs.
Not even geography.
This week was about sovereign access.
Key signals:
• Anthropic restricts access to frontier models after U.S. export-control pressure
• Apollo Blackstone back $35B Anthropic compute expansion
• Broadcom custom chips Fluidstack sites enter the capacity stack
• OpenAI files for IPO with ~$1T valuation in view
• SpaceX explores orbital AI compute
• G7 pulls AI leaders into state-level negotiations
The new question is no longer:
“Who has the best model?”
It’s:
Who is allowed to run which model, on whose infrastructure, in which jurisdiction, under which financing and governance regime?
Inference is becoming strategic infrastructure.
#InferenceWars #AIInfra #Inference #Compute #AIInfrastructure #SovereignAI #Datacenters
13
Jun 5
🛰️ INFERENCE WAR — WEEK #50
The war moved again.
Not models.
Not chips.
Not even cloud.
This week was about geographic capacity.
Key signals:
• SpaceX signs $920M/month cloud deal with Google
• Google gets access to ~110k Nvidia GPUs via SpaceX
• AirTrunk/Blackstone planning $30B India AI datacenter buildout
• Megaport raising capital for distributed inference cloud across 31 countries
• Nvidia pushing both Taiwan-scale silicon and local AI PCs
The new question is no longer:
“Who has the best model?”
It’s:
Who controls enough inference capacity, close enough to users, with enough power, network, silicon, and contractual flexibility?
Inference is becoming a global allocation problem.
#InferenceWars #AIInfra #Inference #Compute #Datacenters #GPUs #AIInfrastructure
1
48
May 29
🛰️ Inference Wars - Week #49
The inference war has entered the balance-sheet phase.
• Anthropic raises $65B at a $965B valuation — and immediately hits peak-hour capacity limits
• Apollo Blackstone structuring $36B in debt to finance Google TPU infrastructure for Anthropic to lease
• SpaceX clarifies Colossus is a 6-month deal at $1.25B/month — even the landlord wants an exit
• IREN buys $1.6B of Nvidia Blackwell from Dell to build out AI cloud
• AI capex: $260B (2024) → $800B (2026) → $1.12T (2027)
The old question: which model is best?
The new question: who can finance, reserve, lease, and allocate inference capacity at industrial scale?
Compute is becoming collateral.
Full briefing → inferencewars.com
12
May 15
🛰️ INFERENCE WAR Report - WEEK #47
This week wasn’t about model theatre.
It was about capacity, channels, and control planes.
Key signals:
• Anthropic reportedly commits $200B to Google Cloud chips
• Anthropic adds 300MW via SpaceX and raises usage limits
• OpenAI expands realtime voice, agents, Codex, and enterprise workflow surfaces
• AWS MCP Server goes GA agent desktops previewed
• Google Flash-Lite goes GA for low-latency high-volume inference
• CoreWeave backlog/capex keeps climbing
• Nvidia moves deeper into optics AI datacenter financing
The pattern is clear:
Inference is no longer just API calls.
It’s booked compute, workflow ownership, reliability, and routing.
The next moat isn’t the smartest model.
It’s the operating environment around the model.
#InferenceWars #AIInfra #Inference #Agents #Compute #Cloud #AIInfrastructure
20
May 8
🛰️ INFERENCE WAR - WEEK #46
This week wasn’t about model theatre.
It was about capacity, channels, and control planes.
Key signals:
• Anthropic reportedly commits $200B to Google Cloud chips
• Anthropic adds 300MW via SpaceX and raises usage limits
• OpenAI expands realtime voice, agents, Codex, and enterprise workflow surfaces
• AWS MCP Server goes GA agent desktops previewed
• Google Flash-Lite goes GA for low-latency high-volume inference
• CoreWeave backlog/capex keeps climbing
• Nvidia moves deeper into optics AI datacenter financing
The pattern is clear:
Inference is no longer just API calls.
It’s booked compute, workflow ownership, reliability, and routing.
The next moat isn’t the smartest model.
It’s the operating environment around the model.
#InferenceWars #AIInfra #Inference #Agents #Compute #Cloud #AIInfrastructure
25
May 1
🛰️ INFERENCE WAR - WEEK #45
AI just crossed a line.
It’s no longer “tools” or “experiments”
It’s being wired directly into real workflows:
• OpenAI → coding inside enterprises
• Anthropic → law firms banks
• AWS → $15B AI revenue run-rate
• Meta → mixing internal external infra
At the same time:
• CPU GPU ASIC stacks are normal
• Prefill ≠ decode
• Routing decisions are becoming critical
This is the shift:
from AI as feature → AI as infrastructure
The winner won’t just build the best model.
They’ll control where inference runs,
how it’s routed,
and how it embeds into real work.
#InferenceWars #AIInfra #Inference #Compute #Agents
18
Apr 24
🛰️ INFERENCE WAR REPORT - WEEK #44: "The Enterprise Embedment Week"
The inference war stopped being about benchmark scores. This week it was about who is wired into how large organizations operate.
↳ Meta signed a multi-year, multi-billion AWS Graviton5 CPU deal — CPUs are back at the center of the AI stack, not just overhead
↳ OpenAI deployed 7 global consulting firms Codex Labs to embed inside large organizations — 4M developers and rising
↳ Anthropic signed its biggest law firm deal (Freshfields) expanding Mythos into European and UK banks
↳ AWS AI services above $15B annualized, chip business above $20B — hyperscaler and silicon supplier at once
↳ Cerebras decode Trainium3 prefill still the clearest split-stage production proof point
The earlier phases: better models. Faster chips. Bigger clusters.
This phase: enterprise rollout. Workflow capture. Regulated-sector penetration. Recurring usage.
Embedded inference is harder to dislodge than experimental inference.
inferenceWars.com | Week #44 | Apr 18–24, 2026
#AI #GPUs #Inference #LLM #GenerativeAI #AIInfrastructure #MLOps #OpenAI #Anthropic #AWS #Meta #Cerebras #Nvidia #CloudComputing
15
Apr 17
🛰️ INFERENCE WAR REPORT - WEEK #43:
“The Capacity Diversification Week"
This week the buyer side stopped behaving as if Nvidia-first was the only serious path.
↳ OpenAI reportedly committed $20B to Cerebras over 3 years - alternative silicon as core production infra, not edge capacity
↳ Meta extended Broadcom custom chips through 2029 - MTIA 300 already active, more inference silicon coming
↳ CoreWeave: $6B Jane Street deal $1B equity - being treated as a strategic delivery layer, not GPU rental
↳ Anthropic Opus 4.7 dropped with API breaking changes - June 15 retirement clock now running for older Claude variants
↳ Groq had a quiet week - in a market moving this fast, silence costs mindshare
The war is no longer about owning the best accelerator.
It is about securing enough interchangeable capacity across multiple silicon paths to keep the control plane liquid.
inferenceWars.com | Week #43 | Apr 11–17, 2026
#AI #GPUs #Inference #LLM #GenerativeAI #CloudComputing #MLOps #AIInfrastructure #Nvidia #OpenAI #Anthropic #CoreWeave #Meta #Groq
36
Apr 10
🛰️ INFERENCE WAR - WEEK #41
The inference stack is industrializing.
This week’s signals:
• Broadcom Google locking in custom AI chips through 2031
• Meta adding another $21B of CoreWeave capacity
• AWS AI revenue now running > $15B annually
• Anthropic run-rate revenue > $30B
• OpenAI pausing UK datacenter plans over regulation energy costs
• Intel Google doubling down on AI CPUs
This is no longer:
best model wins
It’s becoming:
who can secure silicon, power, cloud capacity, and political stability
The inference war is moving from hype to hard infrastructure.
#InferenceWars #AIInfra #Inference #Cloud #Compute #Datacenters
27
Apr 3
🛰️ INFERENCE WAR - WEEK #40
The stack is fragmenting again.
This week’s signals:
• AWS Cerebras splitting prefill and decode
• Arm pushing CPUs back into the center of agentic AI infra
• Nvidia moving deeper into networking, photonics, and custom silicon
• CoreWeave raising another $8.5B to scale AI cloud capacity
• OpenAI narrowing focus while scaling enterprise demand
The old question was:
Who has the best chip?
The new question is:
Who can compose the best inference system?
Inference is no longer one model, one chip, one cloud.
It’s becoming:
multi-stage, multi-silicon, multi-cloud orchestration
The war keeps climbing.
#InferenceWars #AIInfra #Inference #GPUs #Cloud #AIInfrastructure #Compute
103
Mar 27
🛰️ INFERENCE WAR - WEEK #38
The stack just got more modular.
This week’s signals:
• AWS Cerebras splitting prefill and decode
• Arm pushing CPUs back into the AI inference stack
• Nvidia expanding beyond GPUs into full inference architecture
• OpenAI scaling the commercial layer around inference demand
• EU scrutiny moving down into cloud model infrastructure
The old question was:
who has the best chip?
The new question is:
who can compose the best inference system?
Inference isn’t just compute anymore.
It’s orchestration.
65
Mar 20
🛰️ INFERENCE WAR REPORT - WEEK #38
The battlefield moved again.
This is no longer:
best model wins
or biggest GPU cluster wins
It’s becoming:
who can route inference across chips, storage, networks, clouds, and agents most intelligently.
This week’s signals:
• Nvidia bundling GPUs Groq networking storage acceleration
• AWS embracing heterogeneous inference infrastructure
• CoreWeave reshaping cloud economics around live AI demand
• OpenAI concentrating demand into a desktop superapp
• Meta continuing its own inference silicon path
The war keeps climbing.
First GPUs.
Then latency.
Then models.
Now: orchestration.
The winner won’t just own compute.
They’ll control where every inference request runs.
#InferenceWars #AIInfra #Inference #GPUs #AIInfrastructure #Compute #Agents
1
32
Mar 13
🪖 INFERENCE WAR REPORT - WEEK #37
The war just moved again.
The question used to be:
Who has the biggest GPU clusters?
Now it’s:
Who can route inference across chips, clouds, and regions fastest.
Signals this week:
• Custom AI silicon accelerating
• AI-native clouds winning production workloads
• Control planes emerging as the real infrastructure layer
The next moat isn’t compute.
It’s routing intelligence.
Inference isn’t training.
Inference is infrastructure.
1
22
Mar 7
🛰️ INFERENCE WAR REPORT — WEEK #36
The control-plane era is arriving.
→ Nvidia developing inference chip using Groq tech, targeting OpenAI
→ Broadcom sees $100B in AI-chip sales by 2027
→ CoreWeave hits $5B revenue, $66.8B backlog
→ VAST Data launches Polaris global control plane
→ SambaNova/Intel: 5x faster, 3x lower TCO
→ DeepSeek withholds model access from U.S. chipmakers
Chips still matter. Clouds still matter. But the decisive layer is now the one that coordinates them.
Full report → inferencewars.com
#InferenceWars #AI #GPU
51
Mar 1
🛰️ INFERENCE WAR REPORT - WEEK #35
The battlefield shifts to heterogeneous compute orchestration.
Key signals:
→ Callosum raises $10.25M (ARIA-backed) for multi-chip scheduling
→ SambaNova SN50 Intel: 5x perf, 3x lower TCO
→ CoreWeave: $5B revenue, 168% growth, $66.8B backlog
→ VAST Data: CNode-X PolicyEngine BlueField-4 DPUs
→ DeepSeek withholds V4 from U.S. chipmakers
Latency leaderboard:
⚡ Groq 402ms | Together AI 479ms | SambaNova 690ms
GPU hegemony is eroding. Multi-chip orchestration is the next battlefront.
Full report → inferencewars.com
#InferenceWars #AI #GPU #InfrastructureWars
65
Feb 23
Inference didn’t evolve this year. It financialized.
I tracked the AI inference market weekly for 34 consecutive weeks.
Here’s what actually changed:
• H100 rental floors compressed from ~$1.9/hr to sub-$1.5/hr
• Latency became table stakes (sub-20ms → assumed)
• “Speed-per-$” became exposed as API surface
• Caching shifted from optimisation → monetary policy
• Rental GPUs started behaving like liquidity pools
• Proof-of-Inference moved toward standards-track receipts
The constraint migrated in real time:
GPU supply
→ latency
→ throughput economics
→ state (prefix/warm-start)
→ auditability
This isn’t software evolution.
It’s market maturation.
Compute is commoditising.
Routing is becoming capital allocation.
State is becoming an asset.
Receipts are becoming mandatory.
The next moat won’t be model size.
It will be control layers.
InferenceWars.com
1
1
2
63
Feb 20
🛰️ INFERENCE WAR REPORT — WEEK #34
The battlefield has shifted again.
Latency is converging.
Cost is compressing.
Models are interchangeable.
The new advantage is control.
This week confirmed the emergence of the inference control layer — where routing decisions, not raw compute, determine performance, cost, and reliability.
Key signals:
• Groq maintains latency leadership — but margin is shrinking
• Together sets cost floor — pricing parity accelerating
• Cerebras dominates throughput — enterprise scale inference rising
• OpenAI wins on reliability — ecosystem gravity matters
• Routing providers quietly becoming kingmakers
Every infrastructure war follows the same pattern:
Innovation → Commoditization → Control layer formation
Inference has now reached the control layer phase.
The winners won’t be those who own the GPUs.
They’ll be those who decide which GPUs get used.
Inference is no longer just infrastructure.
It’s orchestration.
⚡ Live leaderboard:
InferenceWars.com
#InferenceWars #AIInfra #Inference #GPUs #AIInfrastructure #Compute #LLMs
1
12