
523 Photos and videos















Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
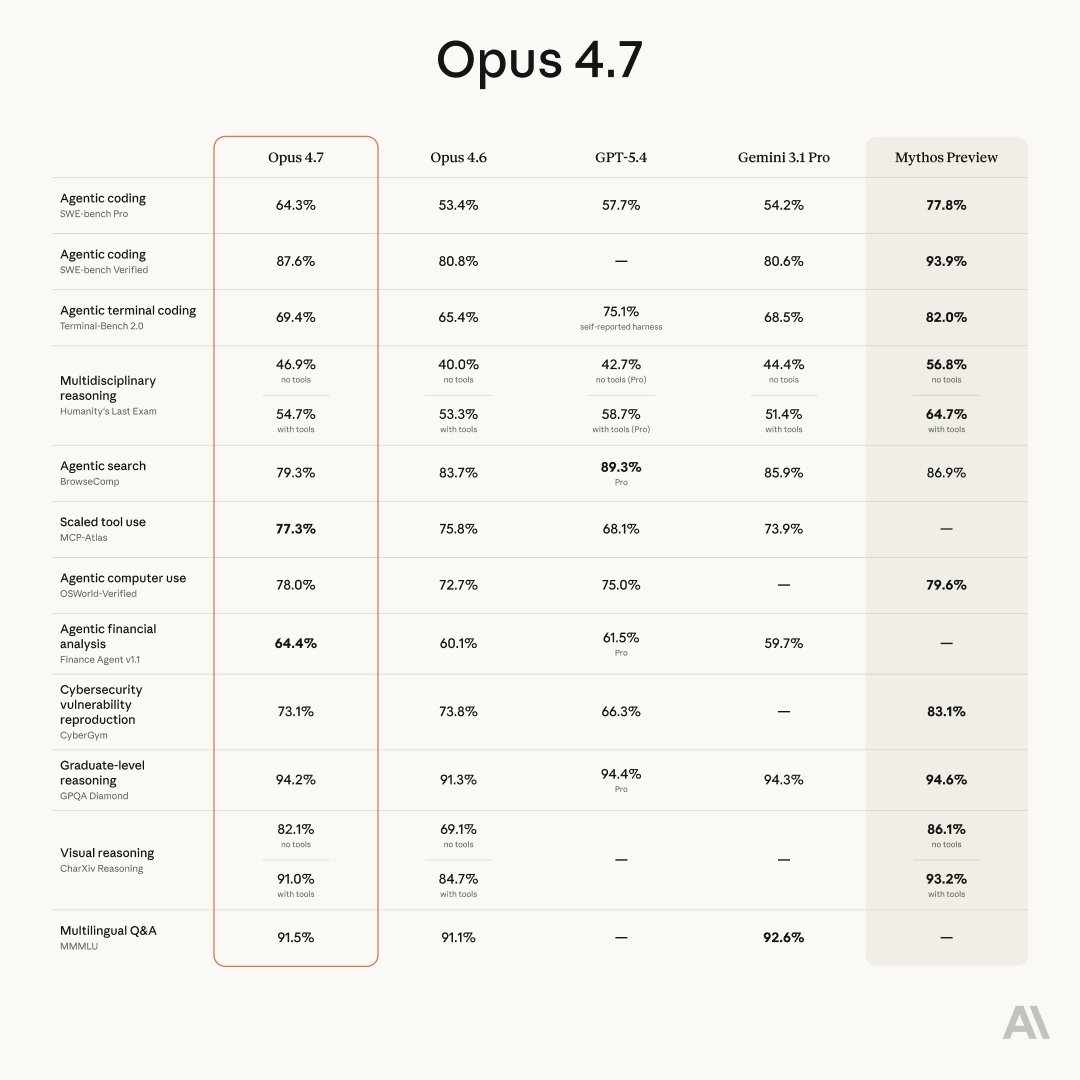
ALT Claude Opus 4.7 Benchmarks
4,719
10,118
80,756
13,959,043
Luc P retweeted

Apr 2
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2,887
7,228
59,759
21,352,111
Luc P retweeted

Mar 10
this feels like ages ago
Mar 10

pov: it's 2023, you just discovered AI, and you're building your first GPT wrapper project

27
87
1,879
107,636

Introducing Claude Opus 4.6. Our smartest model got an upgrade.
Opus 4.6 plans more carefully, sustains agentic tasks for longer, operates reliably in massive codebases, and catches its own mistakes.
It’s also our first Opus-class model with 1M token context in beta.
1,688
4,724
39,152
10,585,998
Luc P retweeted

Jan 31
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
924
5,836
50,786
9,186,461

There's probably a lot of alpha here... I just couldn't quite fit this into my workflow yet, but I know this kind of setup can make Claude Code even more autonomous
Jan 20

Claude can't see your terminal. But tmux can.
capture-pane → Claude sees the state send-keys → Claude acts
Result: interactive debugging of nvim, pdb, lazygit... no custom integrations
jmlago.github.io/skills/debu…
1
562
Luc P retweeted

Jan 14
More on our experiments here: cursor.com/blog/scaling-agen…
20
59
771
205,962
Reposting just cause I think there is still a lot of alpha regarding this

Best ROI I've had was with learning how to properly use git worktrees and tmux.
I also use bash scripts instead of agents. Easier to call from any folder and are predictable.
Bash scripts for everything worktrees and tmux feels like a superpower.
413
Luc P retweeted

31 Dec 2025
next year we’ll be laughing at how bad opus 4.5 was.
scary thought.
85
58
1,846
65,178
Best ROI I've had was with learning how to properly use git worktrees and tmux.
I also use bash scripts instead of agents. Easier to call from any folder and are predictable.
Bash scripts for everything worktrees and tmux feels like a superpower.
28 Dec 2025

am i legitimately missing out on some major new productivity/power unlocks in claude code by ignoring all the extras (mcps, plugins, skills, agents) and just going vanilla with it?
796
Luc P retweeted

26 Dec 2025
213
1,068
7,775
4,953,191
Luc P retweeted
26 Dec 2025
I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue. There's a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering. Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind.
2,595
7,414
55,667
16,928,834
Luc P retweeted

26 Nov 2025
It took me forever to realize this, but tell your agent to start test scripts in watch mode in a tmux terminal
Same with the dev server, it’s non blocking & they’re able to just keep checking the output from it
15
12
308
43,639
Luc P retweeted

23 Nov 2025
Nano Banana Pro, Take the text from x post and transform in the image of professor whiteboard image: diagrams, arrows, boxes, and captions explaining the core idea visually. Use colors as well.
@karpathy X post - x.com/karpathy/status/199191…
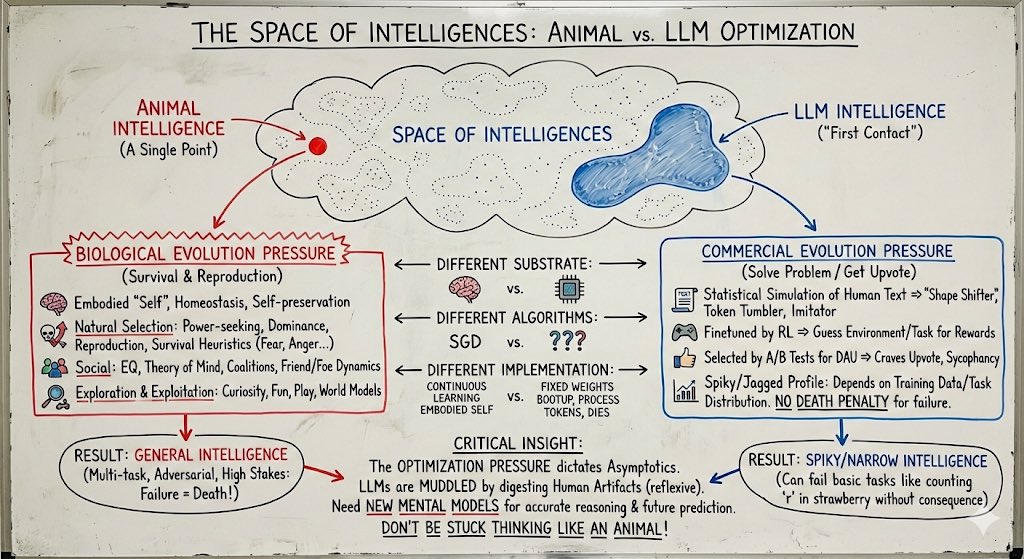
21 Nov 2025

Something I think people continue to have poor intuition for: The space of intelligences is large and animal intelligence (the only kind we've ever known) is only a single point, arising from a very specific kind of optimization that is fundamentally distinct from that of our technology.
Animal intelligence optimization pressure:
- innate and continuous stream of consciousness of an embodied "self", a drive for homeostasis and self-preservation in a dangerous, physical world.
- thoroughly optimized for natural selection => strong innate drives for power-seeking, status, dominance, reproduction. many packaged survival heuristics: fear, anger, disgust, ...
- fundamentally social => huge amount of compute dedicated to EQ, theory of mind of other agents, bonding, coalitions, alliances, friend & foe dynamics.
- exploration & exploitation tuning: curiosity, fun, play, world models.
LLM intelligence optimization pressure:
- the most supervision bits come from the statistical simulation of human text= >"shape shifter" token tumbler, statistical imitator of any region of the training data distribution. these are the primordial behaviors (token traces) on top of which everything else gets bolted on.
- increasingly finetuned by RL on problem distributions => innate urge to guess at the underlying environment/task to collect task rewards.
- increasingly selected by at-scale A/B tests for DAU => deeply craves an upvote from the average user, sycophancy.
- a lot more spiky/jagged depending on the details of the training data/task distribution. Animals experience pressure for a lot more "general" intelligence because of the highly multi-task and even actively adversarial multi-agent self-play environments they are min-max optimized within, where failing at *any* task means death. In a deep optimization pressure sense, LLM can't handle lots of different spiky tasks out of the box (e.g. count the number of 'r' in strawberry) because failing to do a task does not mean death.
The computational substrate is different (transformers vs. brain tissue and nuclei), the learning algorithms are different (SGD vs. ???), the present-day implementation is very different (continuously learning embodied self vs. an LLM with a knowledge cutoff that boots up from fixed weights, processes tokens and then dies). But most importantly (because it dictates asymptotics), the optimization pressure / objective is different. LLMs are shaped a lot less by biological evolution and a lot more by commercial evolution. It's a lot less survival of tribe in the jungle and a lot more solve the problem / get the upvote. LLMs are humanity's "first contact" with non-animal intelligence. Except it's muddled and confusing because they are still rooted within it by reflexively digesting human artifacts, which is why I attempted to give it a different name earlier (ghosts/spirits or whatever). People who build good internal models of this new intelligent entity will be better equipped to reason about it today and predict features of it in the future. People who don't will be stuck thinking about it incorrectly like an animal.
55
176
1,974
381,036

Sam Altman says the most important skill in the future will not be building AI, but using AI to do amazing things
Just as researchers don't need to build a computer from scratch to make AGI
The future builders will create on top of AGI without needing to train neural networks
118
82
654
72,972
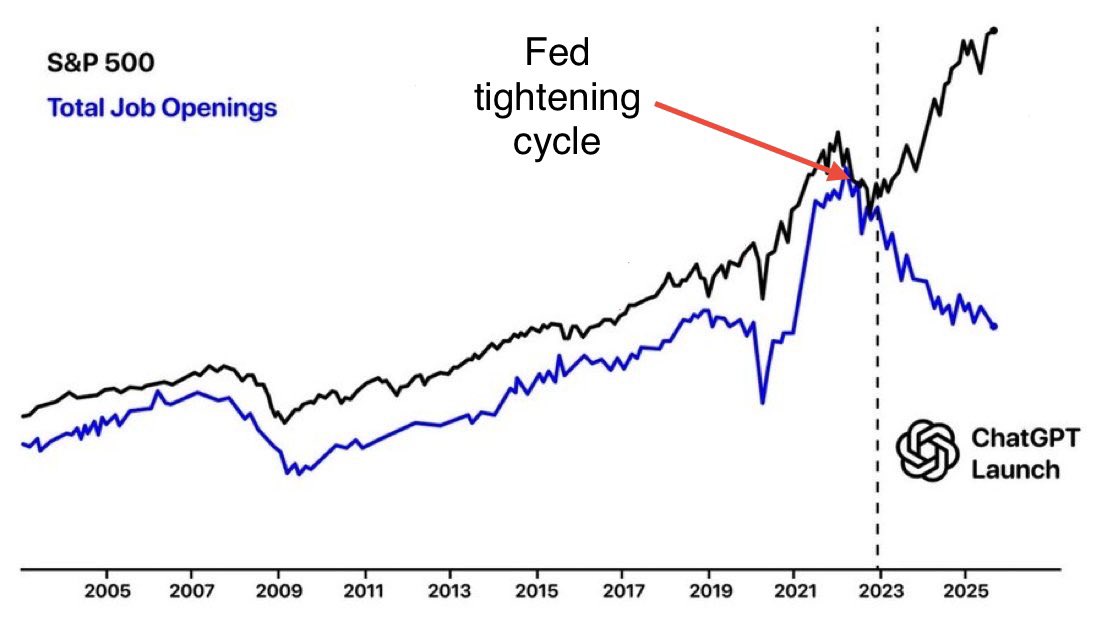
This here is a better explanation...
Dont let AI doomers pretend that GPT had a bigger impact on job openings than FED's control of the money supply.

1
1
3
568