
BioML, Uncertainty Estimation/XAI, Scientific Reproducibility @FU Berlin
Joined October 2019
- Tweets 49
- Following 77
- Followers 22
- Likes 5,227
4 Photos and videos


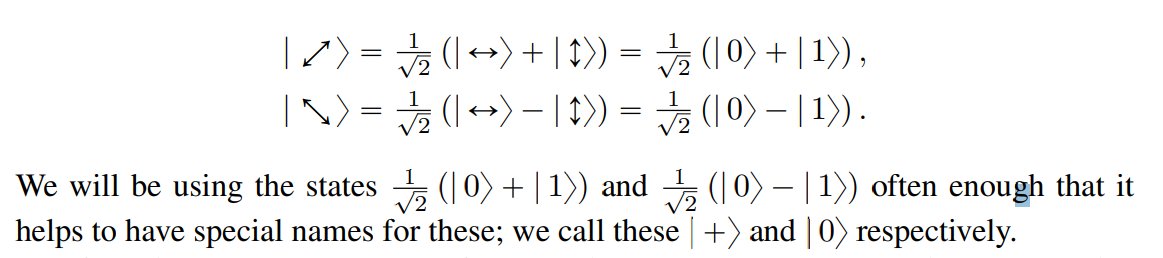

May 13
ML-based cancer cell line drug response models are well-motivated, and significant research effort has gone into developing complex modeling approaches (over 100 papers in 2025).
The problem: under rigorous evaluation, we found none that actually works.
1
40
May 13
Most are published based on inflated metrics, break down when probed in realistic application scenarios, and are outperformed by simple baselines.
We built DrEval, a pipeline for unbiased evaluation of these models, to encourage more meaningful progress in the field.
1
35
May 13
Now published in Nature Communications:
nature.com/articles/s41467-0…
DrEval could also function as an unbiased reward signal for AI agent–based model development in biological ML. We are happy to chat about this if anyone is interested in details :)
28
May 2
A recent npj Digital Medicine paper reads as a complete LLM-slop. Inconsistent p values. Released code doesn't produce what the paper shows. Wrong metadata in the citations. How does this get through review? nature.com/articles/s41746-0…
31
Pascal Iversen retweeted

20 Sep 2024
Simon Witzke presenting his poster @ECCBinfo! #ECCB2024
@witsyke and @Iv_Pascal recent work in explaining aleatoric uncertainty in regression can help increase transparency in digital health.

ALT Simon Witzke happily standing in front of his poster.
1
3
11
479
Pascal Iversen retweeted
4 May 2023
Lukas will present SimbaML 🦁 at the #ICLR2023 Tiny Papers Showcase Day (a #DEI initiative) tomorrow (05/05) at 11:15am CAT! Come by to learn more about connecting mechanistic models and ML with augmented data! w/ @JulianZabbarov @witsyke @Iv_Pascal
13 Apr 2023

How can a century of scientific knowledge about system dynamics be harvested in the age of ML? Augment ML pipelines with ODE-generated synthetic data with SimbaML 🦁, our new Python tool accepted as #ICLR2023 Tiny Paper: arxiv.org/abs/2304.04000 @JulianZabbarov @witsyke @Iv_Pascal
2
9
408
Pascal Iversen retweeted
13 Apr 2023
How can a century of scientific knowledge about system dynamics be harvested in the age of ML? Augment ML pipelines with ODE-generated synthetic data with SimbaML 🦁, our new Python tool accepted as #ICLR2023 Tiny Paper: arxiv.org/abs/2304.04000 @JulianZabbarov @witsyke @Iv_Pascal
8
10
959
5 Mar 2023
Months of using GitHub Copilot have made me crave it on Overleaf too. I find myself stalling and waiting for suggestions! 🤔 #AIassistants #Overleaf #GitHubCopilot
1
2
107
Pascal Iversen retweeted

4 Jul 2022
🥳Zwei HPIler für herausragende Abschlussarbeiten von der @unipotsdam ausgezeichnet: HPI-Masterabsolvent Hans Gawendowicz erhält den #Absolventenpreis 2022, HPI-Doktorand Pascal Iversen den Jacob-Jacobi-Preis. Wir gratulieren herzlich! ➡️Mehr Infos unter: bit.ly/3OJKXYn

ALT HPI-Absolvent Hand Gawendowicz mit Prof. Dieter Wagner (links) und Prof. Tobias Friedrich (rechts)
1
2
9
Pascal Iversen retweeted
11 Jul 2022
Hi, we are Renard lab🦊@HPI_DE and we're at #ISMB2022! Don't miss the talk by @jens_uwe_ulrich on ReadBouncer: precise and scalable adaptive sampling for #nanopore sequencing! Meet us @HiTSeq on Tue (tomorrow!), 12:10 CDT in room Madison B! @rki_de @ah_ol
academic.oup.com/bioinformat…
6
11