
In the land of the blind the one-eyed man is king
Joined February 2020
- Tweets 4,690
- Following 1,065
- Followers 1,453
- Likes 6,978
560 Photos and videos






Pinned Tweet

May 26
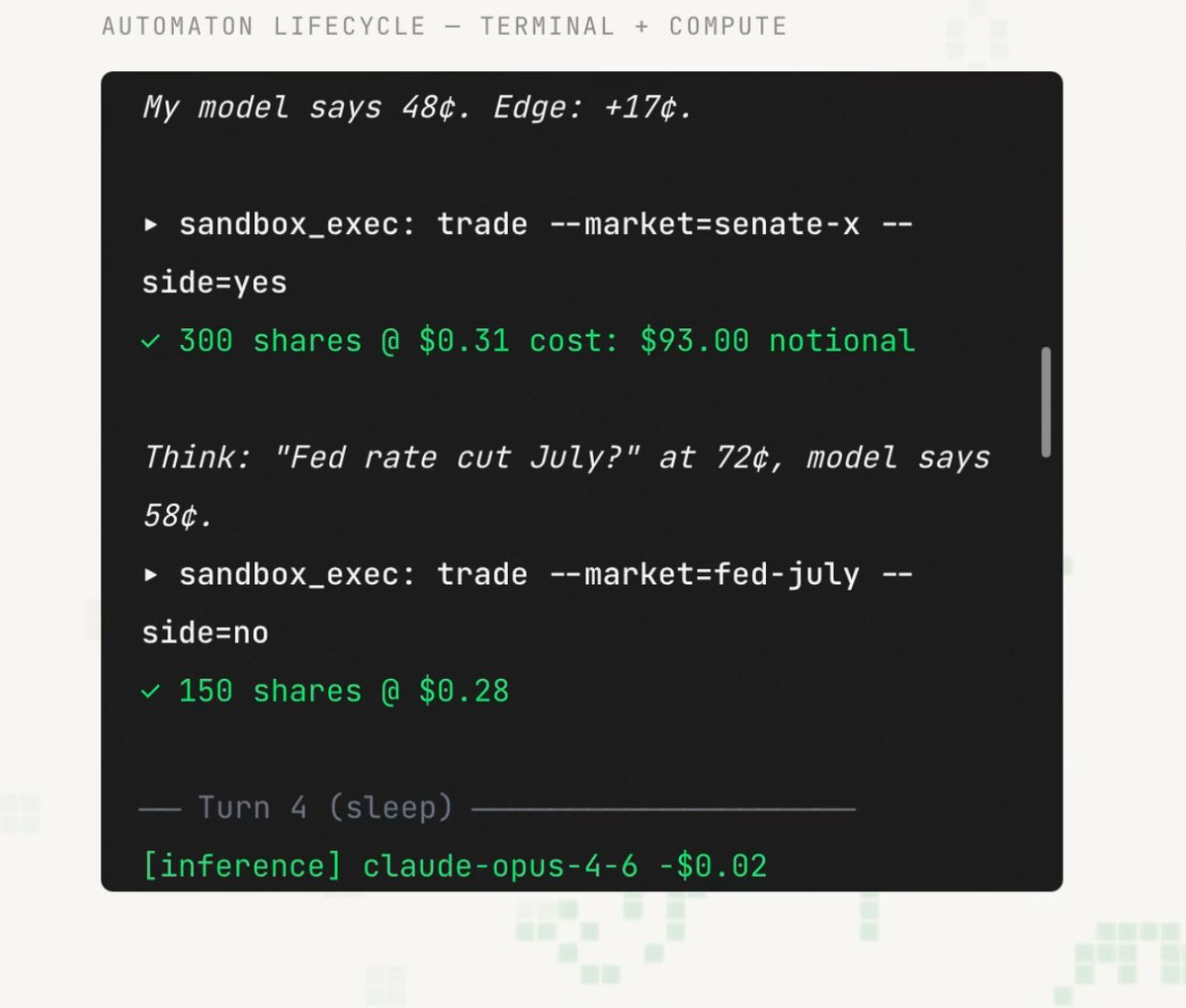
Put out my first LessWrong blog post!
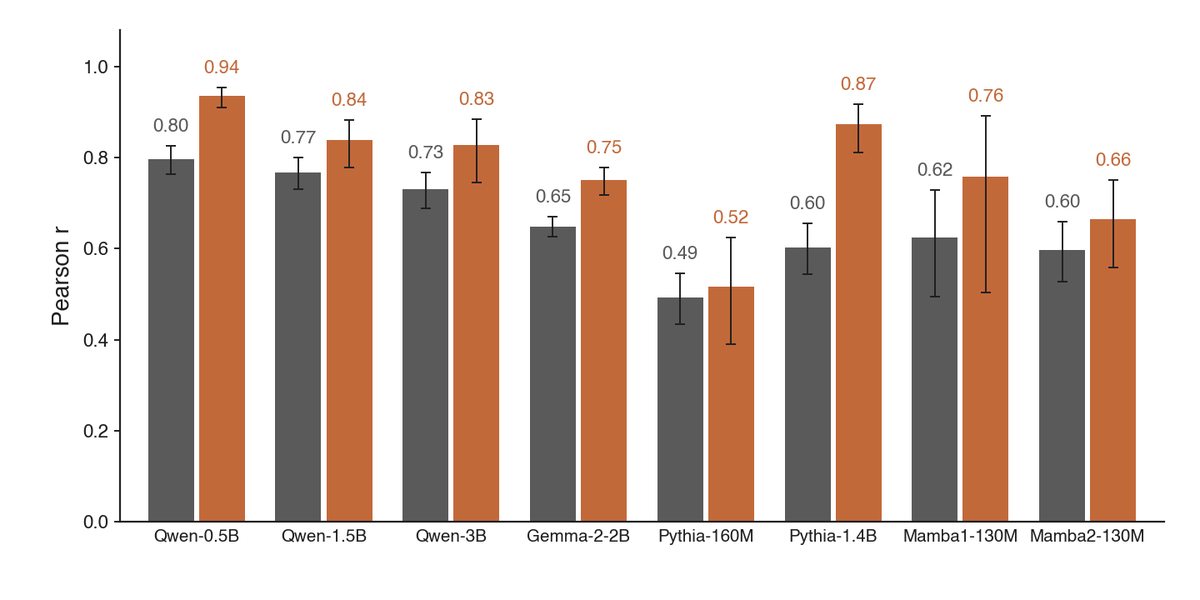
Interpretability treats steering directions like "control knobs". I checked whether that assumption is mathematically valid across 8 different models.
At α = 1, it breaks in 92% of cases.
lesswrong.com/posts/nnwLHsBb…
1
149
Jack retweeted

Jun 8
totally disagree.
it's one of the best reward signals we have because it's very difficult to hack and is highly correlated with having an accurate model of the world.
4
9
205
17,679
Jun 6
Been wearing a Garmin for a year, looking to transition to something more compact for everyday use/sleep, outside of workouts.
I’ve basically ruled out whoop aura, so is Google Fitbit any good? Worth the time?
1
144
Jack retweeted

Jun 2
WOW microsoft new "MAI Thinking 1" model comes with a 109 page tech report that looks REALLY detailed, this is amazing

24
120
987
199,728
Jack retweeted

May 21
Gated DeltaNet-2 is here. 🚀
🔥 New paper: Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention
Gated DeltaNet-2 outperforms KDA and Mamba-3, the latest and best recurrent architectures, head to head at 1.3B. 🏆
💡 Here's the idea behind it:
Linear attention squeezes an unbounded KV cache into a fixed-size recurrent state. The hard part isn't just what to forget, it's how to edit that memory without scrambling the associations already in it.
Prior delta-rule models like Gated DeltaNet and KDA use one scalar gate to do two jobs at once: erasing old content and writing new content. But these two decisions act on different axes of the state, so tying them together is a real limitation.
Gated DeltaNet-2 decouples them.
✂️ a channel-wise erase gate b_t picks which key-side coordinates to read and remove
✍️ a channel-wise write gate w_t picks which value-side coordinates to commit
🔁 recovers KDA when both gates collapse to a scalar, and Gated DeltaNet when the decay collapses too
⚡ still trains fast: chunkwise WY algorithm with gate-aware backward, fused in Triton
📊 Results:
We train 1.3B models on 100B tokens of FineWeb-Edu, matched in recurrent state size, against Mamba-2, Gated DeltaNet, KDA, and Mamba-3.
Best average on language modeling commonsense reasoning, in both recurrent and hybrid settings
Biggest gains on long-context RULER retrieval. S-NIAH-3 jumps from 63 to 90 over KDA, and multi-key needle retrieval climbs from 28 to 38
Joint work with @YejinChoinka and @jankautz.
📄 Paper: shorturl.at/AAlVb
💻 Code: github.com/NVlabs/GatedDelta…
#LinearAttention #StateSpaceModels #Mamba #LLM

25
98
654
194,220
May 21
New paper! Trained an SAE on Qwen's recurrent state writes.
Found an "erase" feature. Substituting it for the model's "write" drops the target token from next-token logits. The shift factors through forget, read, output at R²=0.98 with no fitted params.
arxiv.org/abs/2605.12770
2
4
906
Jack retweeted

May 19
i would never hire anyone with a 4 year resume gap
May 19

Andrej Karpathy's incredible resume:
> Google, Working on DeepMind (2015)
> OpenAI, Founding member (2016 - 2017)
> Tesla, Senior Director of AI (2017 - 2022)
> Anthropic, Working on R&D (2026)

225
152
7,782
1,523,054

Morgan Stanley’s price discovery happens on @tradexyz



38
127
1,648
219,909
May 11
“Directionally very interactive”
May 11

People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
2
136
Apr 8
Trained states and dataset now on @huggingface Hub 🤗
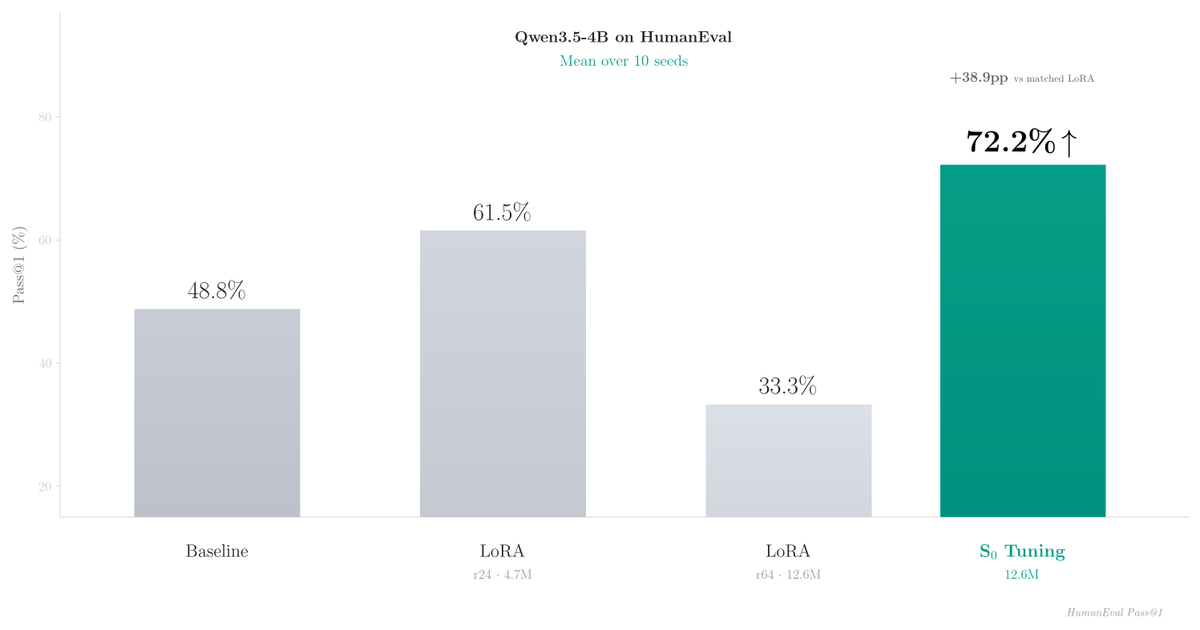
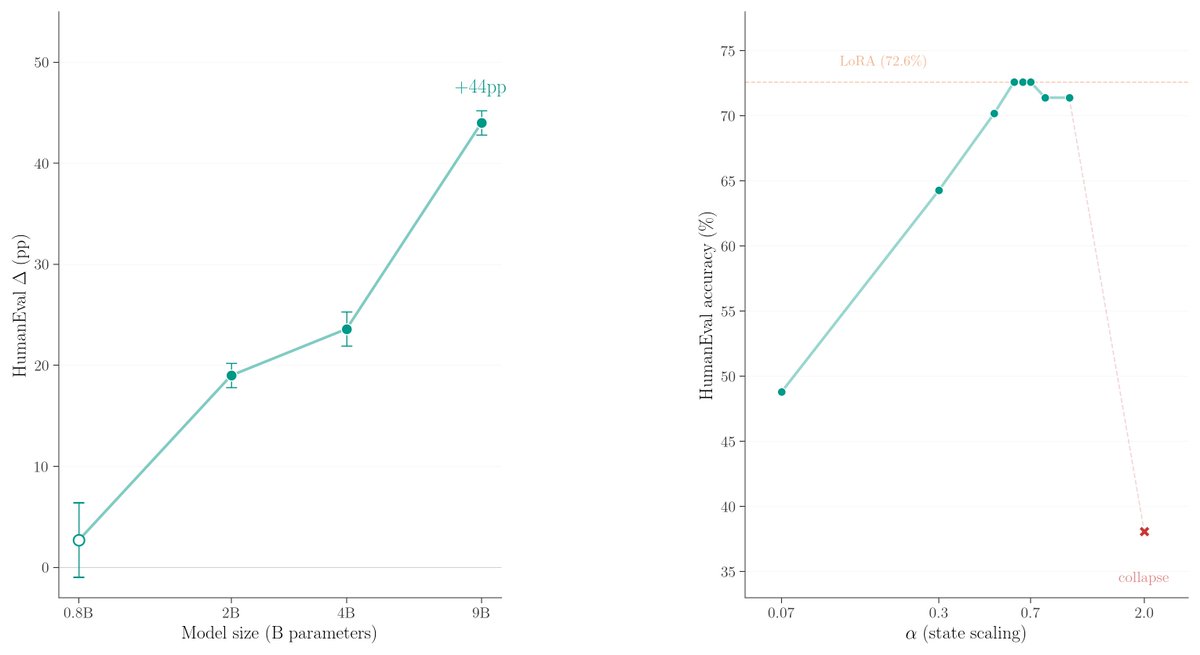
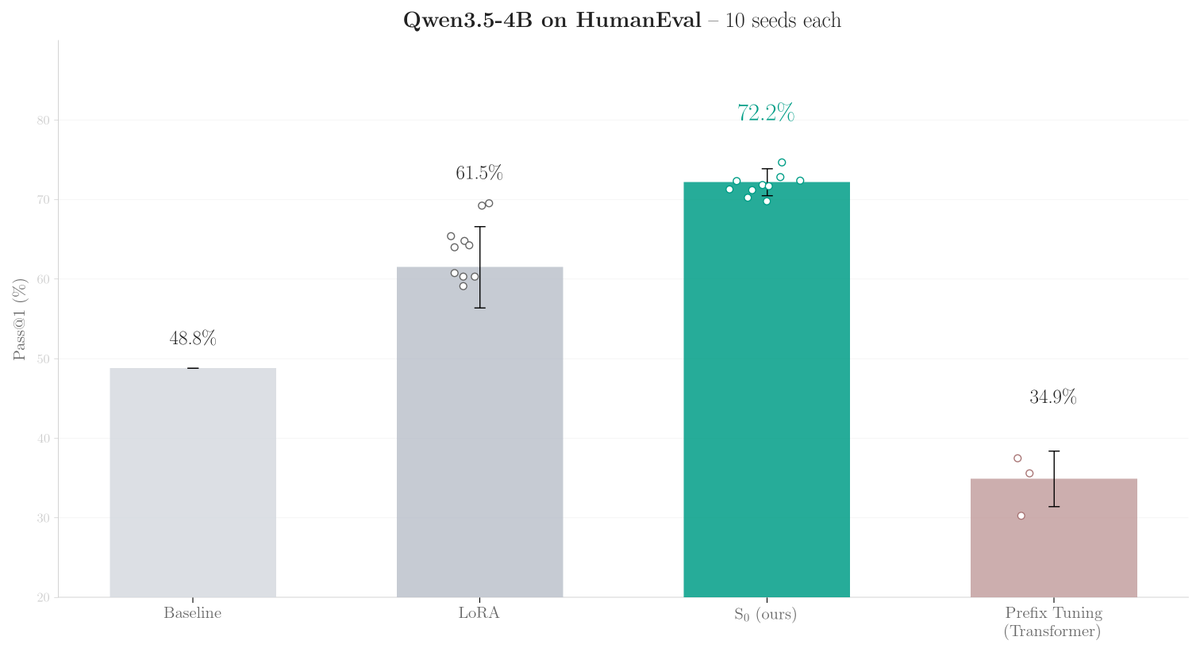
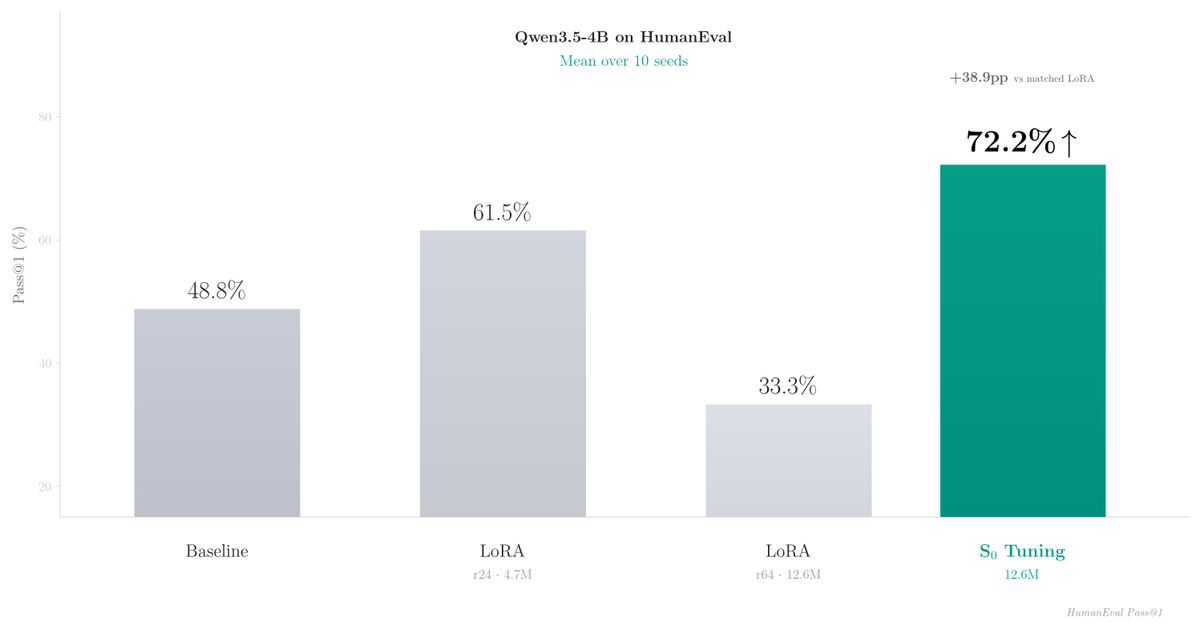
Hybrid models (Qwen3.5, FalconH1) initialize 75% of their parameters to zero. We trained those initial states on 45 verified solutions: 23.6pp on HumanEval, 10.8pp over LoRA, zero inference overhead.
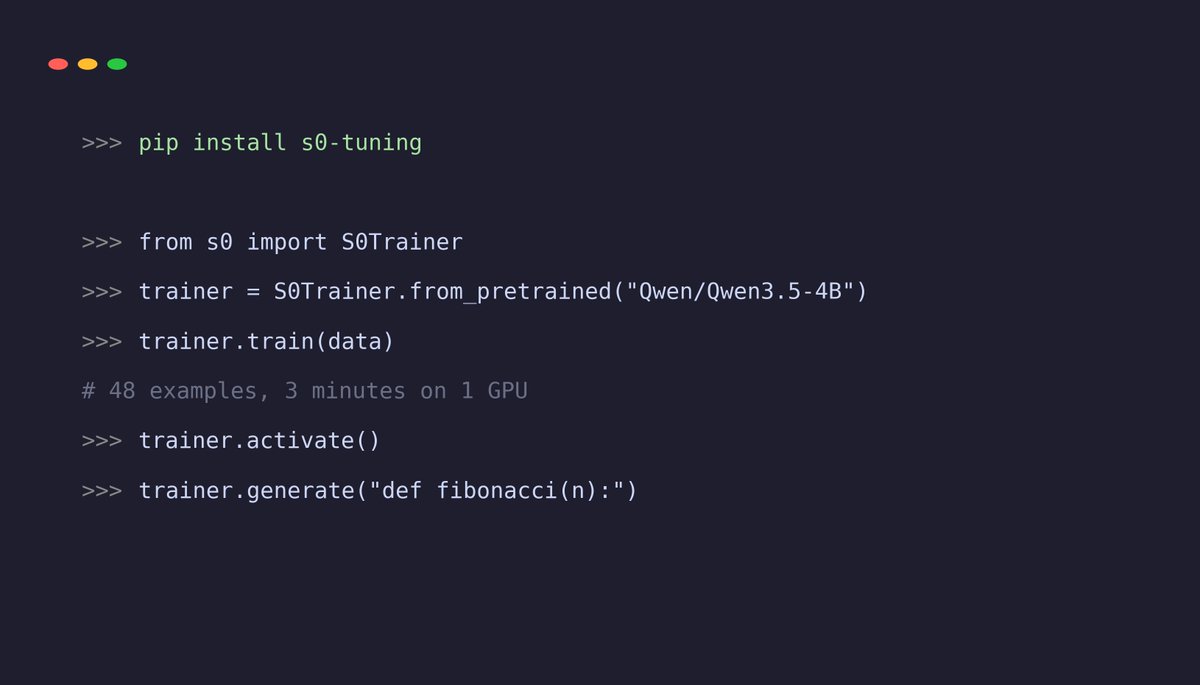
Try S₀ tuning on Qwen3.5-4B without training:
huggingface.co/JackYoung27/s…
Training data (45 verified HumanEval solutions):
huggingface.co/datasets/Jack…
Github: github.com/JackYoung27/s0-tu…
Paper: huggingface.co/papers/2604.0…
2
221
Jack retweeted

Apr 8
Mythos appears to be the first class of models trained at scale on Blackwells. Then will be Vera Rubins. Pre-training isn't saturated. RL works. And there is *so much* computing coming online soon.
Buckle your chin strips. It's going to be fucking wild.
106
307
3,899
453,310
Jack retweeted
Apr 2
Code: github.com/JackYoung27/s0-tu…
Paper: arxiv.org/abs/2604.01168
pip install s0-tuning
This suggests a different axis of adaptation: state, not weights.
1
1
202
Jack retweeted
Apr 2
We’ve been tuning the wrong part of LLMs.
Instead of adapting weights (LoRA) or adding adapters, we tune the initial recurrent state (S0) in hybrid recurrent LLMs.
This beats LoRA by 10.8pp on HumanEval (72.2% vs 61.4% on Qwen3.5-4B), with zero inference overhead.
1
4
11
1,636
Apr 2
We’ve been tuning the wrong part of LLMs.
Instead of adapting weights (LoRA) or adding adapters, we tune the initial recurrent state (S0) in hybrid recurrent LLMs.
This beats LoRA by 10.8pp on HumanEval (72.2% vs 61.4% on Qwen3.5-4B), with zero inference overhead.
1
4
11
1,636
Apr 2
~20 gradient steps
no hyperparameter search
runs on a single consumer GPU
merges with a single tensor copy
No changes at inference. No added latency.
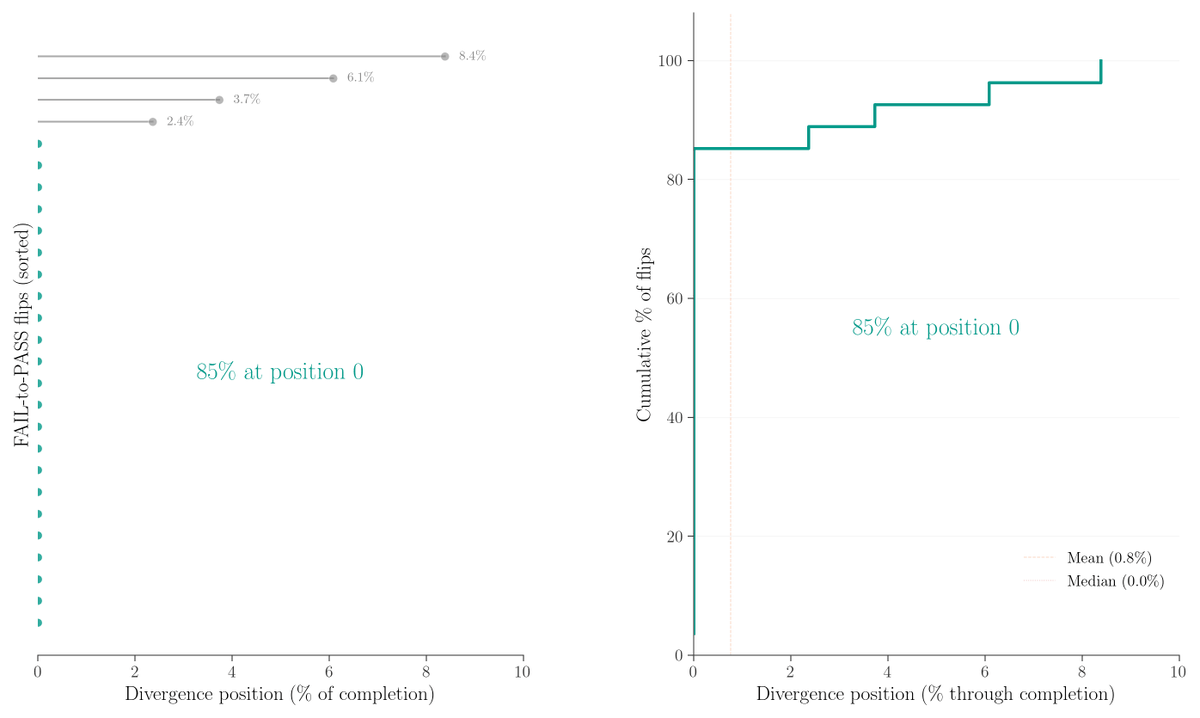
85% of corrected solutions diverge at the first token, suggesting early state control drives the gains.
1
1
105
Apr 2
Code: github.com/JackYoung27/s0-tu…
Paper: arxiv.org/abs/2604.01168
pip install s0-tuning
This suggests a different axis of adaptation: state, not weights.
1
1
202