
Research Scientist @ Apple | CMU ML
Joined August 2024
- Tweets 9
- Following 29
- Followers 7
- Likes 39
Photos and videos
Ryan Shar retweeted

Apr 22
I will be presenting EDIT-Bench as an Oral at ICLR on Friday 4/23! Session 4D starts at 3:15 and the talk is at 3:39.
We will also be at poster session 3 in the morning.
See you all there!
19 Nov 2025

Tired of evaluating LLMs on made-up problems that look nothing like real tasks?
Introducing EDIT-Bench, a code editing benchmark built from in-the-wild user interactions in VSCode.
Real-world edits are challenging: 𝗼𝗻𝗹𝘆 𝟭/𝟰𝟬 𝗺𝗼𝗱𝗲𝗹𝘀 𝘀𝗰𝗼𝗿𝗲 > 𝟲𝟬% 𝗽𝗮𝘀𝘀@𝟭.

8
31
4,444
Ryan Shar retweeted
Feb 13
New preprint alert 🚨
Can LLM agents develop video games?
We release GameDevBench, the first benchmark evaluating agentic game development in a game engine, Godot.
We also present two simple multimodal feedback mechanisms that lead to immediate performance gains.
/🧵
19
27
256
26,289
Ryan Shar retweeted
19 Nov 2025
Tired of evaluating LLMs on made-up problems that look nothing like real tasks?
Introducing EDIT-Bench, a code editing benchmark built from in-the-wild user interactions in VSCode.
Real-world edits are challenging: 𝗼𝗻𝗹𝘆 𝟭/𝟰𝟬 𝗺𝗼𝗱𝗲𝗹𝘀 𝘀𝗰𝗼𝗿𝗲 > 𝟲𝟬% 𝗽𝗮𝘀𝘀@𝟭.
2
12
42
15,540
Ryan Shar retweeted

22 May 2025
I’m excited to share new work from Datadog AI Research! We just released Toto, a new SOTA (by a wide margin!) time series foundation model, and BOOM, the largest benchmark of observability metrics. Both are available under the Apache 2.0 license. 🧵
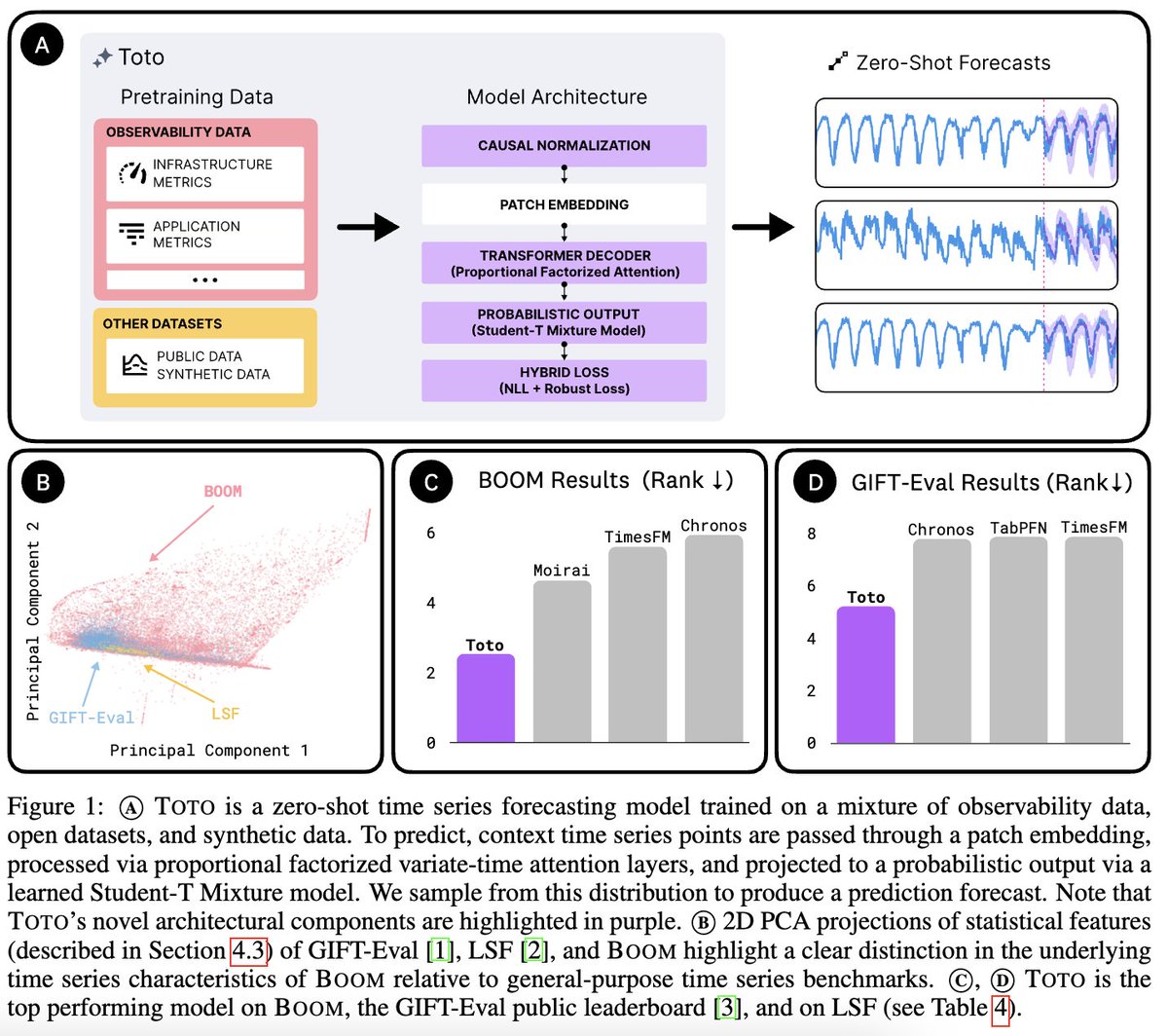
5
52
242
38,236
Ryan Shar retweeted

9 Apr 2025
Blog post on @CopilotArena out now!
9 Apr 2025

blog.ml.cmu.edu/2025/04/09/c…
How do real-world developer preferences compare to existing evaluations? A CMU and UC Berkeley team led by @iamwaynechi and @valeriechen_ created @CopilotArena to collect user preferences on in-the-wild workflows. This blogpost overviews the design and deployment of Copilot Arena new insights into developer code preferences.
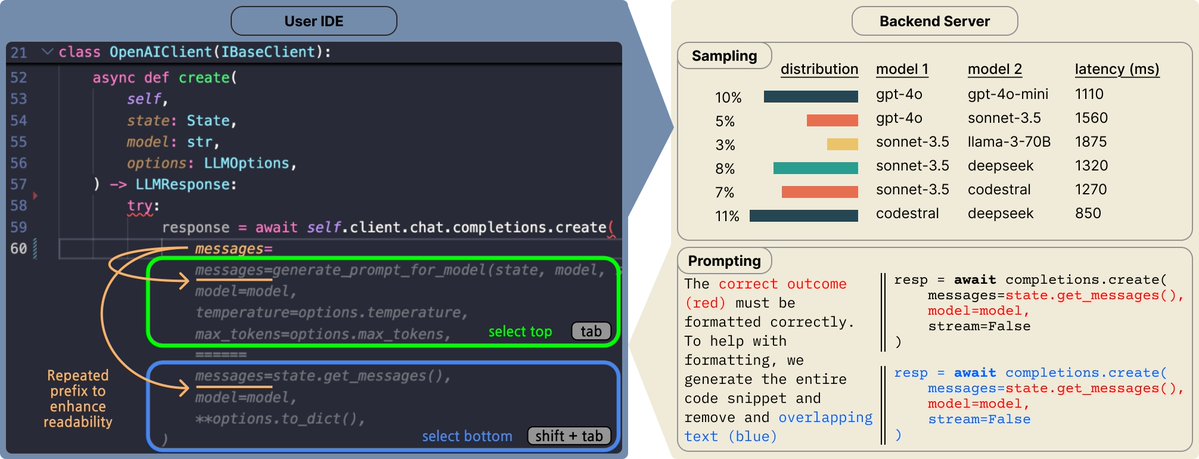
2
15
509
Ryan Shar retweeted
4 Mar 2025
What do developers 𝘳𝘦𝘢𝘭𝘭𝘺 think of AI coding assistants?
In October, we launched @CopilotArena to collect user preferences on real dev workflows. After months of live service, we’re here to share our findings in our recent preprint.
Here's what we have learned /🧵


Introducing Copilot Arena - Interactive coding evaluation in the wild.
Our extension lets you test top models for free, right in VSCode. Let's vote and build the Copilot leaderboard!
Download here:
marketplace.visualstudio.com…
Led by @iamwaynechi and @valeriechen_ at CMU. 1/🧵
3
32
160
71,045

When benchmarks talk, do LLMs listen?
Our new paper shows that evaluating that code LLMs with interactive feedback significantly affects model performance compared to standard static benchmarks!
Work w/ @RyanShar01, @jacob_pfau, @atalwalkar, @hhexiy, and @valeriechen_!
[1/6]
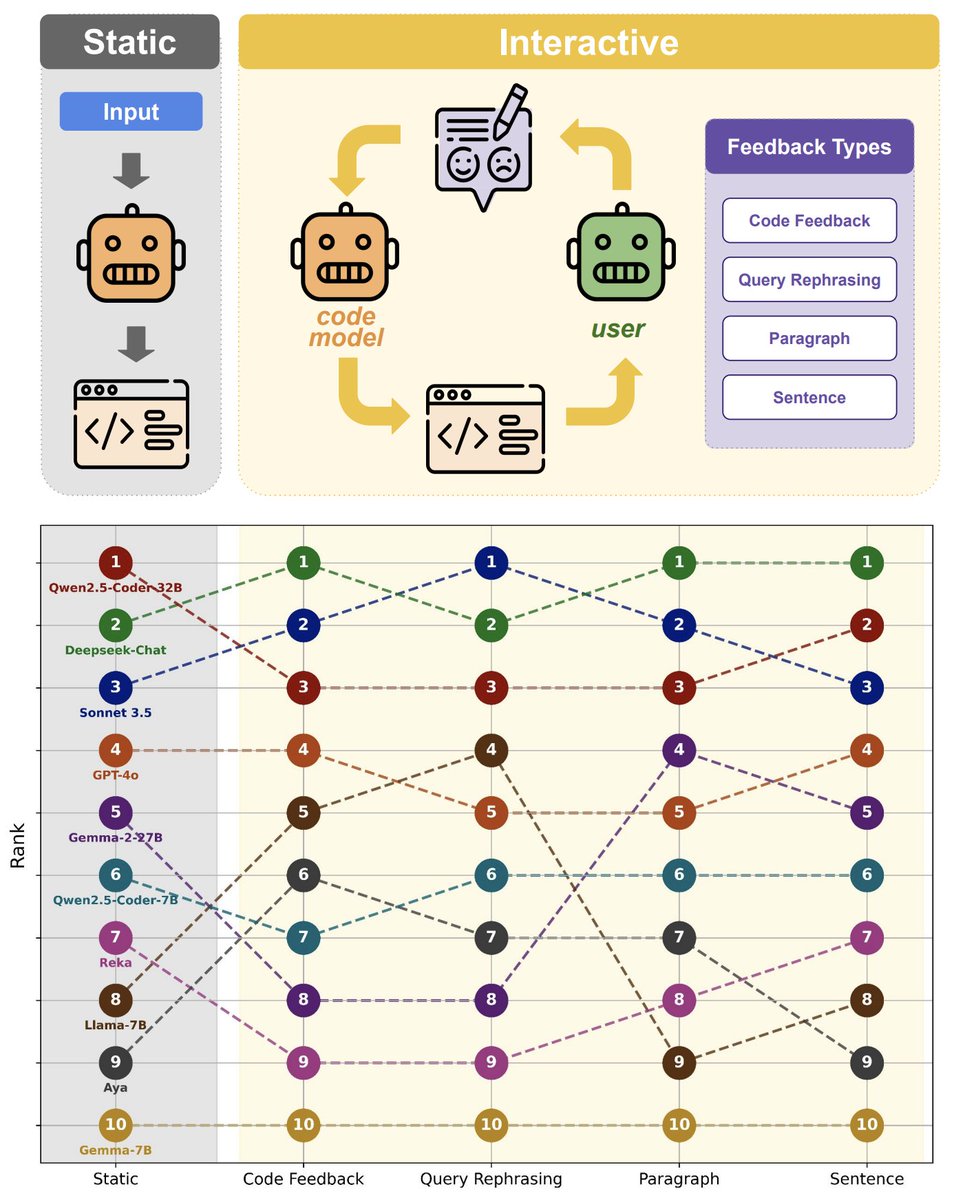
2
15
54
10,559
Ryan Shar retweeted

12 Nov 2024
🧵 on surprising revelations from our study of specialized foundation models (FMs beyond vision/text): after evaluating dozens of scientific & time series FMs we found that most weren’t even competitive with simple supervised models, some with as little as 513 parameters.
1/n

3
62
243
43,053

Which model is best for coding? @CopilotArena leaderboard is out!
Our code completions leaderboard contains data collected over the last month, with >100K completions served and >10K votes!
Let’s discuss our findings so far🧵
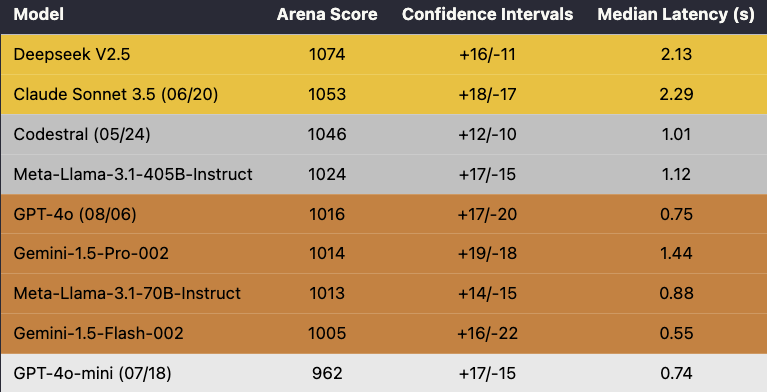
17
77
530
136,021