
Partner @a16z investing in infra & AI | Prev product @databricks & @uber, founder at Jemi (YC S20, acq) | Technology optimist ☀️
Joined August 2010
- Tweets 1,331
- Following 1,237
- Followers 4,422
- Likes 9,837
76 Photos and videos







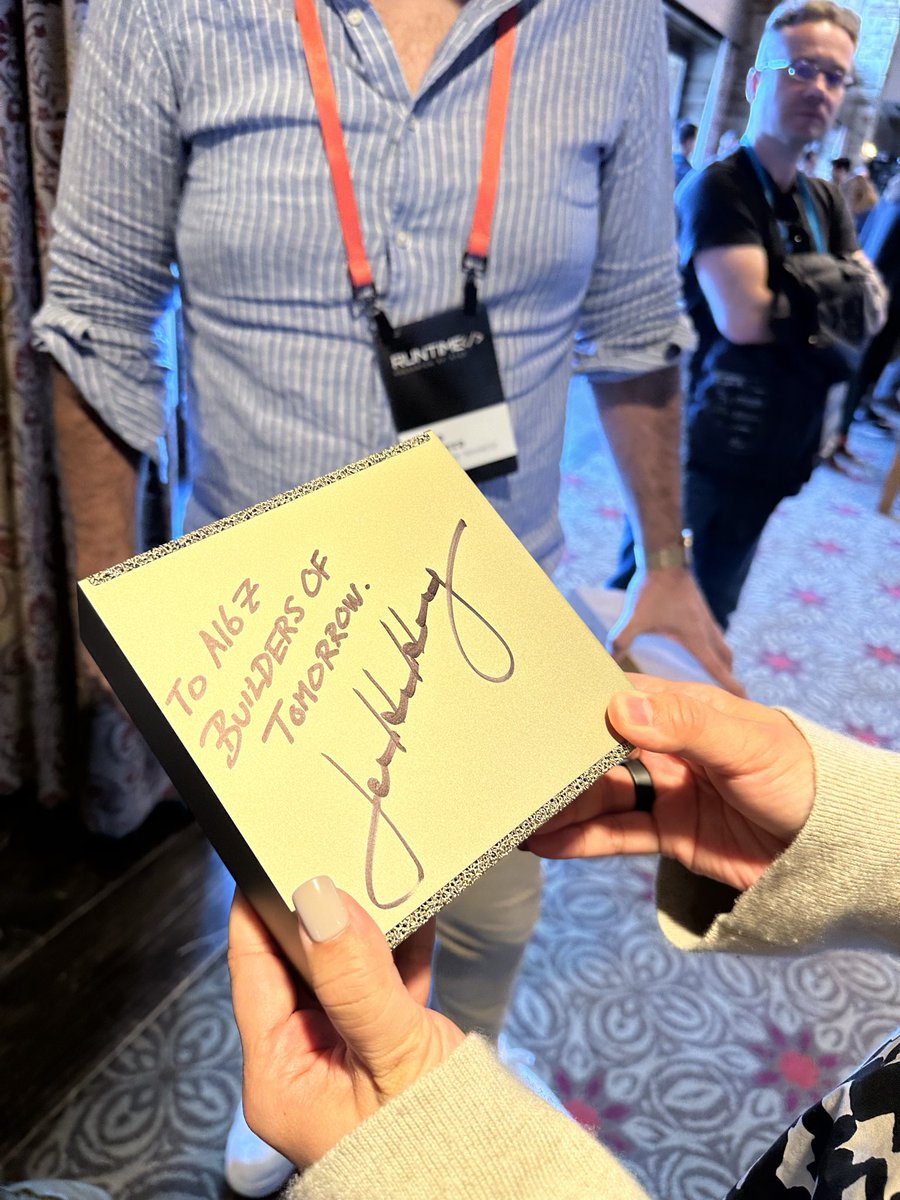





Pinned Tweet

Apr 29
AI has transformed how video is created. We think the next wave is about understanding it.
Over the past few years, we've seen remarkable advances in video generation, editing, avatars, and creative tooling. An increasingly important problem is teaching machines to search, analyze, reason over, and extract insight from video - across massive libraries and live streams alike.
We're calling this video intelligence, and we're actively looking to back founders building here. We're most excited about companies pushing on the core capabilities:
- Video-native models - multimodal embeddings, temporal reasoning, and retrieval built specifically for video rather than adapted from image or text
- Real-time and large-scale pipelines - infrastructure for processing, indexing, and querying video at the speed and scale enterprises actually need
- Agentic and reasoning layers - systems that don't just retrieve clips but answer questions, surface anomalies, and take action on what they see
The models and infrastructure to make this real are appearing to be crossing a capability threshold right now. Multimodal foundation models are maturing, storage costs have collapsed, and enterprises are sitting on years of unstructured video with no way to use it.
That infrastructure unlocks a wide range of applications including media and sports workflows, security and physical operations, enterprise knowledge management, advertising analytics, robotics, and consumer products, where video has historically been dark data.
If you're building in video intelligence at the model layer, the platform layer, or in a vertical application, we'd love to talk!
29
18
111
35,960
Jason Cui retweeted

Jun 12
super fun chatting with @JasonSCui on the SF ecosystem, talent density and the most exciting infra/data and AI startups at the @a16z x @cursor_ai hackathon

1
1
35
1,481



Jun 12
Line around the block!



4
1
31
5,574
Jason Cui retweeted

Jun 11
14
28
205
257,693
Jason Cui retweeted

Jun 9
Today we're excited to introduce vime — a simple, stable, and efficient RL framework for LLM post-training in the vLLM ecosystem.
Built on slime's proven training design and powered by vLLM inference, vime brings another strong option to the growing vLLM post-training ecosystem.
Our goal isn't a one-size-fits-all framework. We want users with different needs to find the right vLLM-ecosystem choice for their workflows—whether that's vime, NeMo RL, OpenRLHF, verl, or others.
More choice. More interoperability. More innovation.
Learn more: vllm.ai/blog/2026-06-09-anno…
#LLM #RLHF #PostTraining #vLLM
8
54
508
42,100
Jason Cui retweeted

Jun 4
I can’t think of better people other than @RaghuRaghuram @AnneNeuberger @jkhamehl @astrange and @GEVS94 to lead this global effort. This firm has never seized to pursue the bigger ambition, and building leverage for our founders. 🌎

1
2
37
4,561
Jason Cui retweeted

Jun 4
Exa CEO @WilliamBryk explains why agents require a new search paradigm:
"Agents to humans is like humans to sloths."
"They just want to make complex queries very fast and analyze it really fast, and they want perfect output for their human users."
"You want something that can actually semantically handle complex queries, but also handle keywords, really just expose all the fundamental toggles to the agent."
"Because the agent, by the way, has the patience to add a domain filter here and a keyword filter there, or search in this way, search in that way."
"An agent doesn't just want 10 results or 10 pieces of information, it wants everything."
"I have a list of 20 different ways humans and agents are different, and when you just build it from scratch for agents, you just make fundamentally different architectural decisions."
1
11
40
2,809
Jun 2
Great thoughts from @stuffyokodraws! The future of design/visual will be more intertwined with code
Jun 2

[New blog] The Next Frontier of Visual AI Is Code
For many visual problems, we will learn to reframe the visual generation task to a coding task, and get efficient improvement from solving a well-defined & validatable coding problem
Design and creative work IS code 👇

2
426
Jun 1
If you’re going to CVPR our infra team will be there!
Jun 1

Going to CVPR in Denver this week?
Our team at @a16z and several of our portfolio companies are hosting events!
Come hang with us - links 👇

6
936
May 21
It's incredible having Peter back on the team, and I've already learned so much from him. He brings incredible experience coupled with a genuine desire to learn and connect with people that's infectious.
Welcome back!!
May 21

I am thrilled to announce my return to a16z as a full-time General Partner. Having made a full recovery from cancer and navigated some of life’s most taxing personal hurdles, I am returning with a sharpened sense of purpose and a deep optimism for the future, both personally and professionally.
My time away reinforced that living to one's fullest capacity requires doing what you love with the people you trust. While I’ve continued to support my boards and founders, I’ve realized my greatest impact happens when I am 'all in.' I believe he current pace of innovation in infrastructure is unmatched, and I couldn't be happier to be back in the trenches with my colleagues and close friends on the a16z Infra team.
2
12
1,700
Jason Cui retweeted

May 20
Exa raised $250M at a $2.2B valuation, led by a16z, to continue organizing the web for agents:
- Exa now serves search to Cursor, Cognition, Openrouter, 5000 other companies, 500k developers
- We’re SOTA in many important verticals (code, companies, people, news, more very soon)
- We make agents smarter and cheaper by returning 90% less text with little to no tradeoff in RAG quality
- We’re building out web agents that are Pareto optimal on price x performance x latency, possible because we own our search stack fully end to end
We used to tell candidates that without innovation in search, we may live in a world where we have both AGI and fake news. Funnily enough, I think that we’ve now been living in such a world for quite some time. With this funding, we should be able to dramatically improve the state of information in society.
🚀🚀🚀

100
35
637
243,608
Jason Cui retweeted

May 20
"In the limit, if we could search 100% of the time, we probably would. It just comes down to GPUs, latency, and cost."
Search has become a critical layer of agent infrastructure, and the volume agents drive is orders of magnitude larger than human search ever was.
Exa is becoming the default search engine for developers (and agents) in the AI era, and that's why @sarahdingwang, @JenniferHli, @JasonSCui and I are so excited to partner with @WilliamBryk, @jeffzwang and the @ExaAILabs team!
May 20

We raised $250M in Series C funding at a $2.2B valuation, led by a16z.
Exa is a search lab organizing the web's data for agents.
2
6
46
8,568
Jason Cui retweeted
May 20
Agents will search the web more than humans this year. Soon it will be orders of magnitudes more.
Nearly every meaningful AI workflow, from coding agents to research systems to enterprise copilots, depends on external information as a core input. For accurate and fast web search, leading AI companies and enterprises rely on @ExaAILabs.
@WilliamBryk and @jeffzwang started building search from the ground up in their Harvard dorm. 5 years later they're becoming the default for developers (and agents) in the AI era.
Thrilled to be leading Exa's Series C and to back Will and Jeff as they build perfect web search for the age of intelligent agents.
More on why @JenniferHli @steph_zhang @JasonSCui and I invested in the comment link.
May 20
We raised $250M in Series C funding at a $2.2B valuation, led by a16z.
Exa is a search lab organizing the web's data for agents.
10
12
90
23,242

We’re excited to lead Exa’s Series C, to back their ambition of perfecting web search, and making it ready for the age of intelligent agents.
We’re entering a new era for search, built from the ground up around what AI can do.
The signal from the market was consistent. Exa excels with the hardest queries – the long tail of high alpha searches where traditional engines fail. What struck us most was the default behavior: developers and agents are reaching for Exa first.
Years before ChatGPT or the AI boom really started, @WilliamBryk and @jeffzwang were inspired by the transformer breakthrough and believed deeply that AI will fundamentally change the way we access information.
So they set out on the path to build the search engine for a future where agents become the primary consumers of the web.
We’re thrilled to partner with Will, Jeff, and the Exa team as they build the perfect search engine for agents and usher in a world of abundant information for all.
By @sarahdingwang, @JenniferHli, @steph_zhang, and @JasonSCui

May 20
We raised $250M in Series C funding at a $2.2B valuation, led by a16z.
Exa is a search lab organizing the web's data for agents.
8
4
158
28,315
May 20
We are incredibly excited to partner with @ExaAILabs on this next chapter of their journey.
As AI workflows proliferate exponentially, it's clear that web search has become crucial in providing agents and systems access to external info and web data. Exa is on the journey of building perfect search.
The team has made incredible progress so far, and @WilliamBryk and @jeffzwang have been obsessed with search since their Harvard dorm days.
We are so excited to lead their Series C!
More on why @sarahdingwang,@JenniferHli,@steph_zhang and I invested in the comments.
May 20
We raised $250M in Series C funding at a $2.2B valuation, led by a16z.
Exa is a search lab organizing the web's data for agents.
2
5
24
1,634
May 18
Congrats to the entire @StainlessAPI team!! they have truly been developer obsessed since day 0!
May 18

Huge congratulations to @RattrayAlex and the @StainlessAPI team on the acquisition by @AnthropicAI.
From our earliest conversations, what stood out about Stainless was the clarity of the mission: make APIs feel effortless for developers, by turning API design into great SDKs, docs, and tooling by default. It sounds simple until you appreciate how much craft sits behind it. True to its name, Stainless polished every detail developers only notice when they’re missing: type safety, idiomatic clients, versioning, reliability, to create an experience that just works.
That kind of infrastructure compounds. As AI becomes more programmable and more deeply embedded in every product, the interface between developers and models matters enormously. Stainless built one of the defining developer infrastructure companies for that world.
Proud to have been part of the journey, and excited to see what the team builds next with Anthropic. Congrats Alex, Mark, Daniella, Alex A, Mirole and the entire Stainless team!!
5
562

May 15
Just speculating, but I CUDA learned a lot more about inference engineering if I paid more attention in class
6
2
83
7,696