
AI for Scientists, assistant professor @CornellCIS, part-time @GoogleDeepMind
Joined August 2020
- Tweets 243
- Following 412
- Followers 1,355
- Likes 524
28 Photos and videos












Pinned Tweet

16 Sep 2023
Thanks my co-advisors Pietro Perona & @yisongyue & committee (@Antihebbiann, @swarat, @klbouman)!!
I'm grateful for the opportunity and everyone's support through the challenging & rewarding journey. I'm looking forward next steps in collaborative AI for Scientists!


14
4
116
22,796
Jennifer J. Sun retweeted

May 28
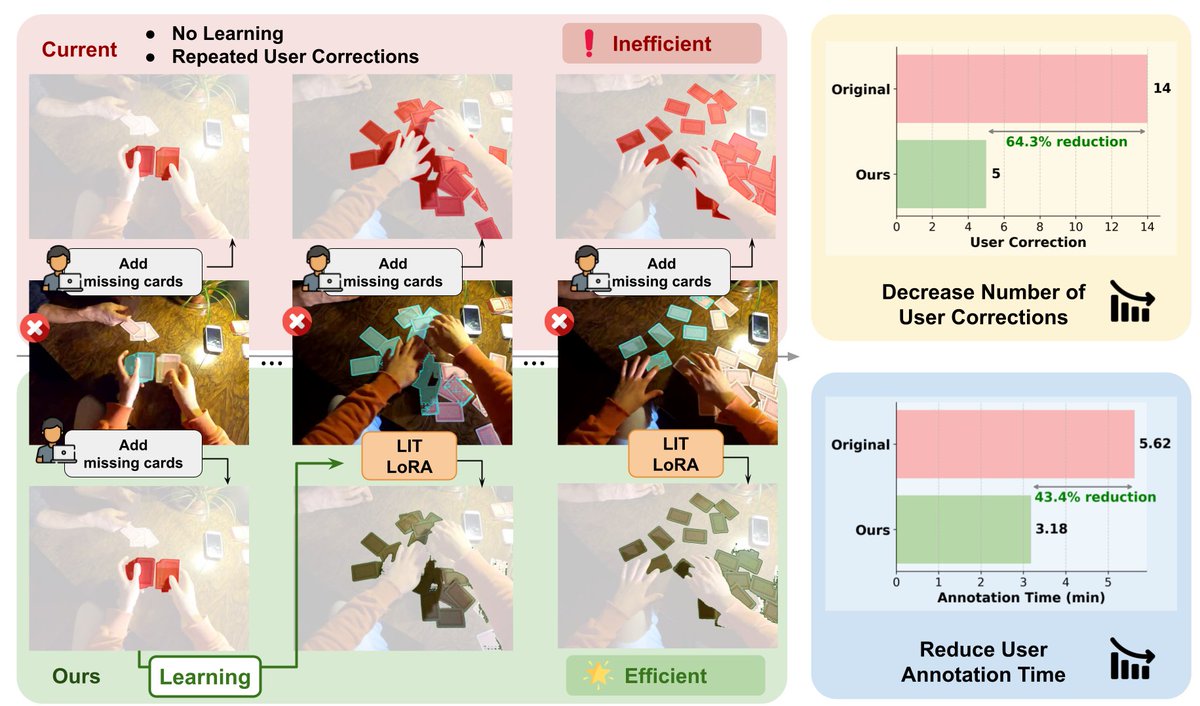
Introducing Live Interactive Training for Video Segmentation (#CVPR2026)
User corrections help fix errors in challenging scenarios, but current interactive systems typically use this feedback to refine predictions rather than learn from it.
Can we make these corrections help the model adapt and reduce repeated user effort?
We introduce LIT-LoRA, a lightweight plug-and-play module for interactive test-time adaptation through human feedback. When a user corrects an error, LIT-LoRA updates on the fly and helps fix similar future errors.
Highlights:
📉 18–34% fewer user corrections on challenging VOS benchmarks
⚡ ~0.5s online update overhead per correction
🧩 Plug-and-play across different models and tasks
2
3
14
1,141
Jennifer J. Sun retweeted
Excited to share FormulaCode, a continually updating benchmark for evaluating the holistic ability of LLM agents to optimize codebases. Our current dataset consists of 957 tasks curated from 245477 pull requests in 70 repositories (and growing!).
🌐 formulacode.org
🧵👇
4
6
25
7,056
Jennifer J. Sun retweeted

28 Oct 2025
.@Cornell is recruiting for multiple postdoctoral positions in AI as part of two programs: Empire AI Fellows and Foundational AI Fellows. Positions are available in NYC and Ithaca.
Deadline for full consideration is Nov 20, 2025!
academicjobsonline.org/ajo/j…

2
40
124
60,236
Jennifer J. Sun retweeted

8 Jul 2025
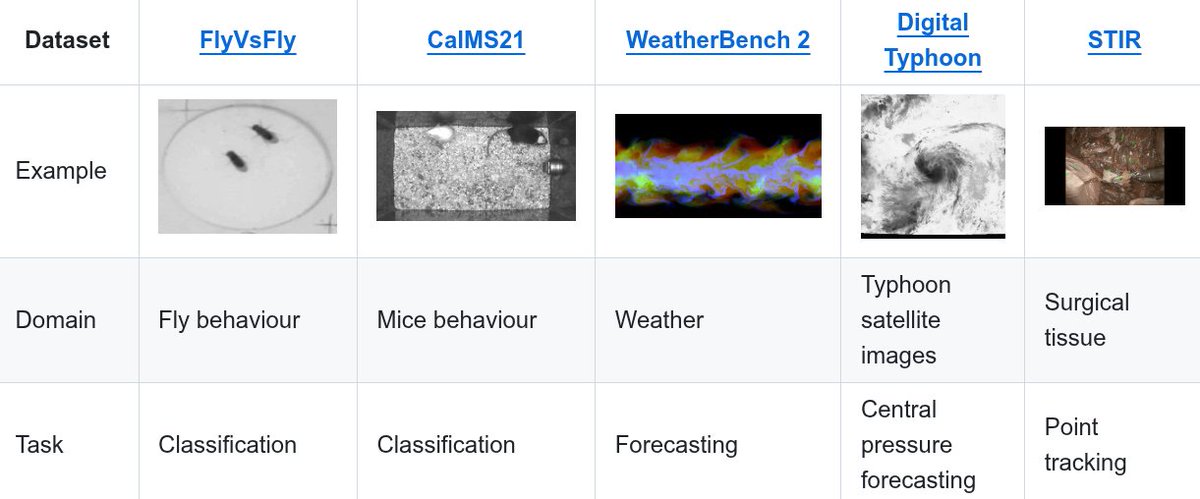
Thrilled to share our latest work on SciVid, to appear at #ICCV2025! 🎉
SciVid offers cross-domain evaluation of video models in scientific applications, including medical CV, animal behavior, & weather forecasting 🧪🌍📽️🪰🐭🫀🌦️
#AI4Science #FoundationModel #CV4Science
[1/5]🧵
1
9
30
2,857
Jennifer J. Sun retweeted
28 Jun 2025
Check out our LMLM, our take on what is now being called a "cognitive core" (as far as branding go, this one is not bad) can look like, how it behaves, and how you train for it.
arxiv.org/abs/2505.15962
27 Jun 2025

The race for LLM "cognitive core" - a few billion param model that maximally sacrifices encyclopedic knowledge for capability. It lives always-on and by default on every computer as the kernel of LLM personal computing.
Its features are slowly crystalizing:
- Natively multimodal text/vision/audio at both input and output.
- Matryoshka-style architecture allowing a dial of capability up and down at test time.
- Reasoning, also with a dial. (system 2)
- Aggressively tool-using.
- On-device finetuning LoRA slots for test-time training, personalization and customization.
- Delegates and double checks just the right parts with the oracles in the cloud if internet is available.
It doesn't know that William the Conqueror's reign ended in September 9 1087, but it vaguely recognizes the name and can look up the date. It can't recite the SHA-256 of empty string as e3b0c442..., but it can calculate it quickly should you really want it.
What LLM personal computing lacks in broad world knowledge and top tier problem-solving capability it will make up in super low interaction latency (especially as multimodal matures), direct / private access to data and state, offline continuity, sovereignty ("not your weights not your brain"). i.e. many of the same reasons we like, use and buy personal computers instead of having thin clients access a cloud via remote desktop or so.
2
7
34
7,099
Jennifer J. Sun retweeted

13 Jun 2025
I’m presenting Escher (trishullab.github.io/escher-…) at #CVPR2025 Saturday morning (Poster Session #3; #236). Escher builds a visual concept library with a vision‑language critic (no human labels needed). Swing by if you’d like to chat about program synthesis & multimodal reasoning!

2
5
18
2,082
6 Jun 2025
VideoPrism is now available at: github.com/google-deepmind/v…
:)

Introducing VideoPrism, a single model for general-purpose video understanding that can handle a wide range of tasks, including classification, localization, retrieval, captioning and question answering. Learn how it works at goo.gle/49ltEXW
1
4
19
3,710

After over 15 months, we are excited to finally release VideoPrism! The model comes in two sizes, Base and Large, and the video encoders are available today at github.com/google-deepmind/v….
We are also working towards adding more support into the repository, please stay tuned.
Introducing VideoPrism, a single model for general-purpose video understanding that can handle a wide range of tasks, including classification, localization, retrieval, captioning and question answering. Learn how it works at goo.gle/49ltEXW
1
1
9
956
Jennifer J. Sun retweeted

27 May 2025
🚀Excited to share our latest work:
LLMs entangle language and knowledge, making it hard to verify or update facts.
We introduce LMLM 🐑🧠 — a new class of models that externalize factual knowledge into a database and learn during pretraining when and how to retrieve facts instead of memorizing them.
🧠Why LMLM?
• Learning to look up facts is easier than memorization
• Externalizing knowledge improves factual precision
• Enables instant machine unlearning by design
LMLM opens new directions for how future language models can manage and access knowledge.
📄 [ArXiv] arxiv.org/pdf/2505.15962
🌐 [Project Page] linxi-zhao.github.io/LMLM-si…
💻 [Code] github.com/kilian-group/LMLM
🎤 [Talk] simons.berkeley.edu/talks/ki…
Huge thanks to my amazing collaborators:
@linxizhao4 @sofianzalouk Christian Belardi Justin Lovelace @JinPZhou
And to our incredible advisors @KilianQW, @yoavartzi, and @JenJSun for their generous support and insight.
1
13
43
6,048
Jennifer J. Sun retweeted

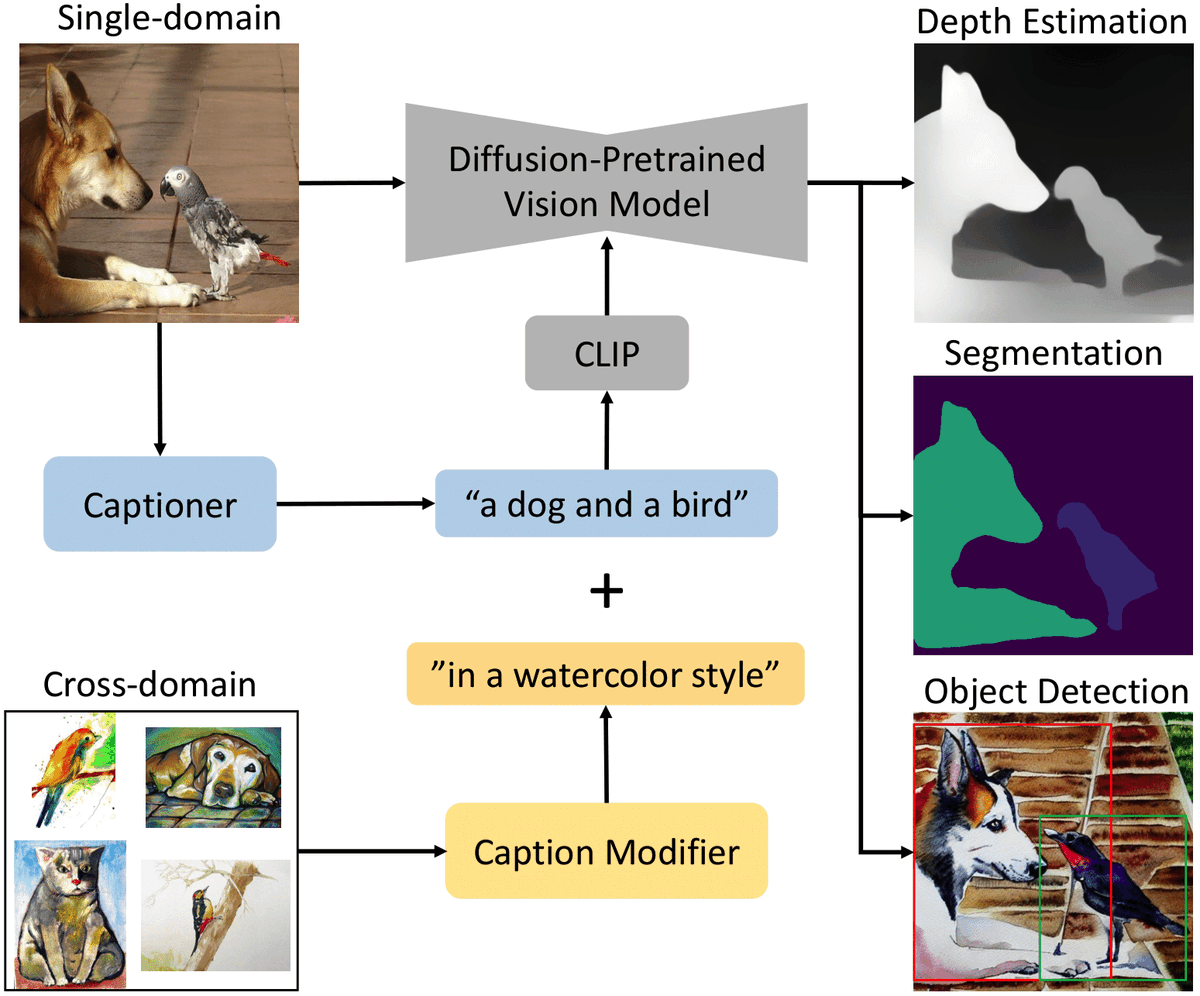
6 Oct 2023
We're excited to share our latest work! We achieve SOTA results in segmentation, detection, and depth estimation, in single and cross-domain, by exploiting image-aligned text prompts in a pretrained diffusion backbone repurposed for vision tasks.
See vision.caltech.edu/tadp/
🧵👇
4
30
178
35,971
Jennifer J. Sun retweeted

30 Aug 2023
Won't you be my neighbor? Northwestern Neuroscience in downtown Chicago is running a broad faculty search:
nature.com/naturecareers/job…
Come join a large and growing neuroscience community!

45
83
23,949
25 Jul 2023
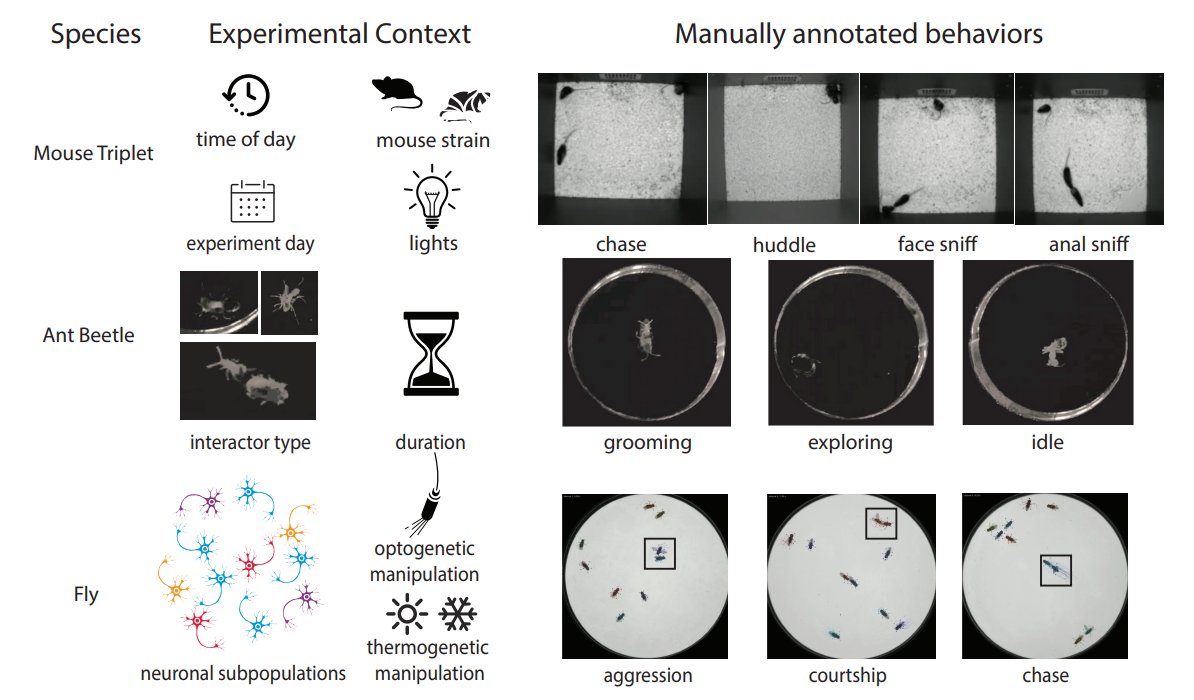
We are presenting our MABe22 dataset at ICML!
Our dataset studies representation learning of video and trajectory data - the representations are evaluated on a large set of downstream tasks.
MABe22 organisms include mice, flies, and beetles!
Paper: arxiv.org/pdf/2207.10553.pdf
3
13
54
20,342
25 Jul 2023
Thanks to @Antihebbiann and @KristinMBranson for co-organizing the MABe 2022 Workshop & Challenge and their work on the MABe 2022 benchmark!
And to @yisongyue, Pietro Perona, and @_tingliu for advising our workshop hosted this year at CVPR.
sites.google.com/view/mabe22
1
6
765
25 Jul 2023
Huge thanks to additional co-authors: Andrew Ulmer who helped develop our benchmark, @__dipam__ for developing the eval framework, and MABe22 Challenge winners Ed Hayes, Heng Jia, Sebastian Oleszko, Zach Partridge, Milan Peelman, Chao Sun, Param Uttarwar, and Eric Werner!😊
3
668
Jennifer J. Sun retweeted

21 Jun 2023
Presenting BKiND-3D tomorrow with @JenJSun and Lili Karashchuk tomorrow (Wed., June 21) in the morning session at poster #74. Feel free to stop by!
15 May 2023

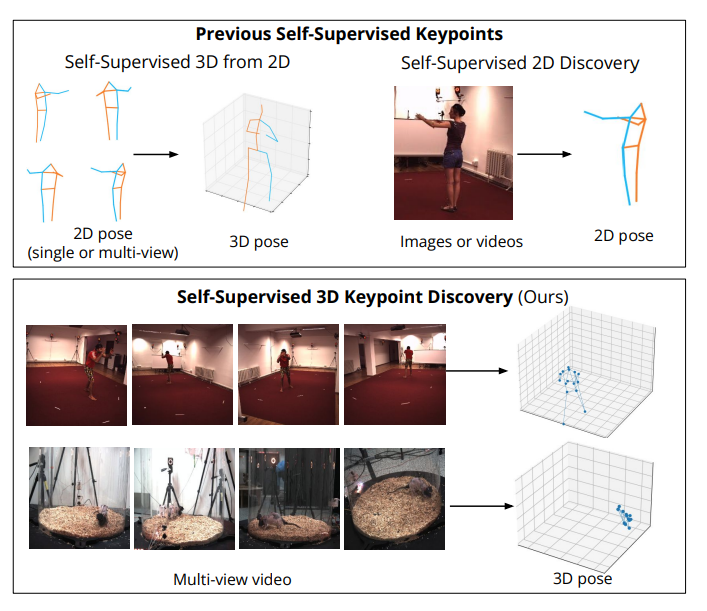
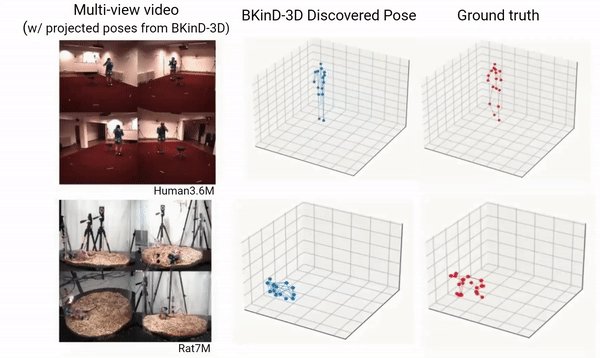
All animals behave in 3D - we discover 3D poses directly from multi-view videos without requiring annotations.
Essentially videos -> 3D keypoints connections
We will be @CVPR on June 21!
BKinD-3D Paper: arxiv.org/abs/2212.07401
Co-first-authors Lili Karashchuk & @_AmilDravid
2
2
22
2,588