
State of the art foundation model is banned by admin! Frustrating and infuriating 😠
bsky.app/profile/atiq.xyz/po…
#LLM #GenAI #AIStartups #FoundationModel #Anthropic #ClaudeModels #ClaudeMythos #MythosFable
8
おもしろそう。FoundationModelの新機能を一つのアプリで再現するレポジトリ?
Jun 13

Apple's Foundation Models framework got much bigger in Xcode 27.
I added runnable labs for:
- Private Cloud Compute reasoning levels
- Image input
- Dynamic profiles
- Explicit tool calling
- Model routing
- Evaluations
github.com/rudrankriyam/Foun…
12
2,473

Jun 12
So, there’s still no system wide querying of CoreSpotlight… this is what Apple would need to expose for the EU.
They probably felt that allowing third party apps to query opens up the potential for abuse.
But that‘s the problem for a Gatekeeper in EU. You cannot have a universal Index of the users data to yourself. That’s unfair competition because there is no other (easy) way for - say - ChatGPT to find emails that match a query for RAG.
A privacy prompt is probably also not enough. There needs to be a separate LLM on device that evaluates if the query is interactive and asks for user approval for sensitive data.
Or they force using FoundationModel API and that must expose for inspection what personal data gets sent.
Or they only invent some anonymous way to track personal data that was provided. So that there’s at least a paper trail from which Apple could find which misbehaving App leaked personal data.
Granted it’s a very difficult problem. But recent example for good solution: the auto mode in @claudeai which uses another model to evaluate if tool calls are dangerous or benign.
This is what Apple needs urgently. Can be a very simple model that has the developer profile, app infos and the query for context. And remember what kinds of queries the user approved.
Or generally redact personally identifiable information. That would still work for quite a few use cases. And for unredacted data they need to have good standing and user approval via privacy approval.
3
1
2
419

Jun 11
FoundationModelでGeminiの APIを呼び出すドキュメントだ。素晴らしい
Jun 11

Learn more in our docs:
firebase.google.com/docs/ai-…
1
10
3,152


Jun 10
정확도 너머에: 시계열 파운데이션 모델(TSFM)은 잘 보정(Calibration)되어 있는지에 대한 연구 (feat. ICLR 2026)
(by 9bow님)
d.ptln.kr/10485
#paper #foundationmodel #timeseries #forecasting #iclr #calibration #uncertainty
1
26

Jun 8
Will OpenAI google etc need to adopt the foundationModel api themselves or can we implement that on our own?
1
159
Dominic retweeted

The Private Cloud Compute API is the exact same as the one for the on-device FoundationModel.
But there are usage limits, depending on the user's iCloud plan. Keep this in mind when building features.

1
1
24
2,129

Jun 8
お、#jwVe #common813 Apple FoundationmodelのSiriに #Gemini が手を組んで画像の栄養を出してくれたり、例えばW杯のウォッチパーティーのレシピ提案か過去にメッセージで提案してもらったデザートはと過去からとMacでファイルの内容からどうここを修正(DIY)なとな長い文章で、VisionOS Siriの玉を
見つめるだけで,,例えばテーブルに置いてある写ってるものをそのままSiriで、 #WWDC26

38
Refresh your FoundationModel skills before WWDC
I made a free course covering all the basics. We're even building a voice chat feature. Everything in under one hour.
youtu.be/bNjramAiOfM

3
1
7
695

May 23
We at Soket AI are hiring for HPC Infra Engineer towards our foundation model efforts. Apply and do share within your network.
#HiringAlert #FoundationModel #AI #LLM #GPU
soket.ai/careers/jobs/hpc_in…
1
7
24
3,118

Toto 2.0:時系列予測がスケーリング時代へ突入huggingface.co/papers/2605.2…
Datadog社の時系列基盤モデル(TSFM)。4m〜2.5Bの5サイズを公開し、時系列予測でもモデルサイズ拡大に伴う性能改善が起きることを示した論文。
評価データは主に3系統。
・BOOM:CPU、メモリ、レイテンシ、エラー率などのobservability系列
・GIFT-Eval:energy / retail / weather / finance等を含む汎用時系列ベンチ
・TIME:学習データ汚染を避ける目的のゼロショット評価ベンチ
■主張
・Toto 2.0ファミリーとしてBOOM / GIFT-Eval / TIMEでSOTA級
・base modelは公開時系列データなしで訓練。Datadog社内メトリクスと合成データのみ
・22mモデルがToto 1.0を約1/7のパラメータ数で上回る
・10mプロキシ u-µPで5サイズへハイパーパラメータ転送
■懸念
・BOOMはDatadogの得意領域に近く、汎用性とは分けて見るべき
・TIMEでは313mが1Bを上回る箇所があり、完全な単調スケーリングではない
・長期安定性の検証は合成波形中心で、真の外挿性能は未確定
・金融データへの評価はされていない
#TSFM #時系列予測 #FoundationModel #QuantTrading
3
296

May 17
Tomorrow the apps spin up by themselves. We build Knowledge Graphs, APIs and databases that the LLMs improve upon. Then the Ai creates a FoundationModel on our machine that is domain specific. It saves the back and forth.
1
3
64

🖐️ ロボットに"人間レベルの器用さ"を
Khosla出資のGenesis AIが、人間スケールの
器用なロボットハンド+データエンジンを統合した
基盤モデル GENE-26.5 を公開。
ロボティクスFM最大のボトルネック=データ問題に
正面から挑む。
#FoundationModel #Manipulation
techcrunch.com/2026/05/06/kh…
1
2
273

May 8
Local #AI orchestration using tuned #SLM #FoundationModel — Extract > learn > generate #macOS #AIAgents
smartloop.ai/?utm_source=twi…
1
3
4
244

May 7
Today, RLWRLD unveils RLDX-1 — our proprietary Robotics Foundation Model.
Across all 8 public benchmarks, RLDX-1 outperforms leading SOTA models including #NVIDIA #GR00T and Physical Intelligence #π0 — delivering state-of-the-art performance among open robotics foundation models.
🎯 A 'Dexterity-First' Philosophy
The industry assumes dexterity will follow once intelligence is solved. We see it the other way around.
Dexterity isn't downstream of intelligence — it's the path intelligence must take to act in the physical world. Real industrial work with five-finger robotic hands depends on signals vision alone can't capture: force (torque), tactile feedback, and the precise moment of contact.
🧠 MSAT — Multi-Stream Action Transformer
Where conventional VLAs collapse every input into a single transformer stream, MSAT gives each modality — vision, language, action, touch, memory — its own dedicated stream, then unifies them through joint attention. Force, tactile signals, and long-term memory are handled by purpose-built Physics and Memory modules.
The result: one model that can see, feel, remember, and adapt.
📊 Performance Highlights
RoboCasa Kitchen — 70.6: the first VLA model to cross the 70-point threshold
GR-1 Tabletop — 58.7: 10.7 percentage points over NVIDIA GR00T N1.6
LIBERO-Plus — 86.7%: top score across 7 robustness variables
Pot-to-Cup Pouring on WIRobotics ALLEX — 70.8%: nearly 2× the comparison models, which remained in the high-30% range.
We're also releasing DexBench — our industry-grounded benchmark for dexterous manipulation, defined across five domains: Grasp Diversity, Spatial Precision, Temporal Precision, Contact Precision, and Context Awareness.
🔓 Open Release
Three checkpoints (8.1B parameters each), live now on GitHub and Hugging Face:
RLDX-1-PT — pre-training
RLDX-1-MT-ALLEX — mid-training for ALLEX
RLDX-1-MT-DROID — mid-training for DROID
⚙️ Built on NVIDIA's Cloud-to-Edge Stack
Training and simulation on Isaac GR00T, Isaac Lab, Isaac Sim, and cuRobo. Compute on NVIDIA H100 and A100 GPUs. Edge inference on Jetson AGX Thor with TensorRT. Our collaborations with NVIDIA, AWS, and Microsoft continue across both research and deployment.
🌍 What's Next: The 4D World Model
Video-based world models will never surface what isn't in the pixels — contact torque, tactile signals, robot state. Our 4D World Model integrates these directly with vision, language, and action across the temporal dimension, predicting and generating the full physical world. RLDX-1 is the first milestone on that roadmap.
📍 Join us at Dexterity Night in San Francisco on May 13 — followed by launch events in Japan and Korea.
🔗 Explore RLDX-1 on GitHub and Hugging Face.
rlwrld.ai/ko/rldx-1
#RLWRL #RLDX1 #PhysicalAI #RoboticsFoundationModel #VLA #Humanoid #Dexterity #FoundationModel #Robotics #AI
14
48
3,480

Apr 23
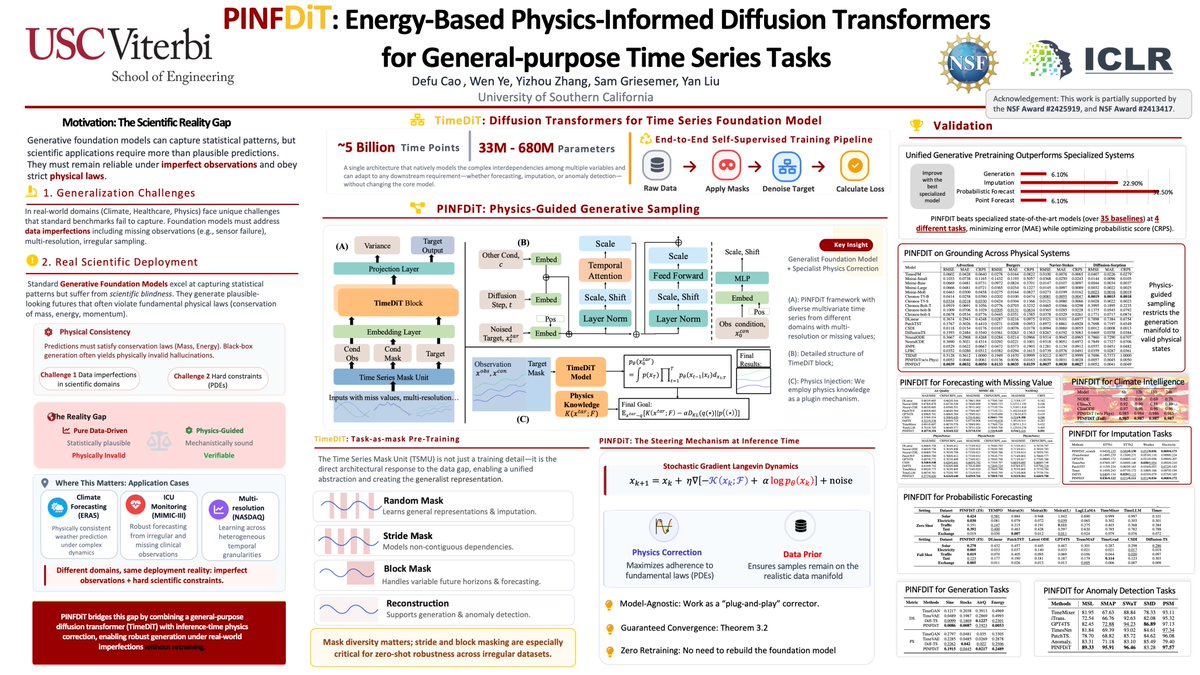
PINFDiT at #ICLR2026!
How do we bridge the "Scientific Reality Gap" in AI? Current models generate plausible data but often ignore physical laws. PINFDiT is a Diffusion Transformer designed to fix that.
#FoundationModel #TimeSeries #PhysicsInformed
1
8
216

New from the Vasty Deep: The importance of the REFINE checklist for foundation and large language models radiologyai.substack.com/p/w… #FoundationModel #ML #MachineLearning

3
290



I'm excited to share our latest work: AeroTransformer — a step toward bringing the foundation model paradigm to real-world aerodynamic design.
Code & models: github.com/tum-pbs/AeroTrans… Paper: arxiv.org/abs/2604.18062
1
9
848