
Member of Technical Staff @SemiAnalysis_
Joined December 2017
- Tweets 678
- Following 860
- Followers 3,533
- Likes 12,383
276 Photos and videos













Pinned Tweet

18 Dec 2025
We are looking for talented engineers to work on ClusterMAX 3.0 and related consulting projects.
If you like ClusterMAX, InferenceMAX, or any of our other research on ML Systems and Performance, please consider applying at the link below!
8
26
20,824
Jun 11
went to a friend's wedding last weekend and there was quite a bit of contrast framing in the pastor's homily

went to a wedding this weekend
heard the hand of chatgpt in the wedding vows
cringed in multiple dimensions as i realized this will be every wedding for the rest of time
2
782
Jun 9
my friend Tanj posting stuff like this into the LinkedIn ether is such a shame
1
9
1,083
Jun 9
Interesting to see given the administration’s recent trip to China
Jun 8

The DoD just added Unitree to its Section 1260H list of Chinese military companies. BYD, Alibaba, Baidu, and Tencent are on there too. (1/2)🧵

3
787
Jun 9
Even if Unitree doesn't dominate global robotics, American startups still depend on the Chinese hardware supply chain
Unitree’s Verticalization Is Remarkable - Even In China
"Unitree self-develops BLDC motors, planetary gearboxes, LiDARs, and depth cameras, each typically (or even previously for Unitree) outsourced by other Chinese humanoid OEMs. Instead, Unitree’s self-produced motors can run as low as 30-40% of equivalent Western motors, and they now make some of the cheapest humanoid gearboxes in the world."
Jun 8
China's Unitree Will Dominate Global Robotics
The Fastest Iteration Cycle In Next-Gen Robotics Should See Unprecedented Acceleration
newsletter.semianalysis.com/…
5
8
42
10,095
Jun 7
People ask this question all the time and then don’t accept valid answers, likely because there are many overlapping reasons to make your own chip.
Different chips have different perf/$ on different workloads. With a custom chip you can:
- save money on a given workload
- improve performance on a given workload (same thing)
- have a more predictable supply chain
- gain control over software and IP
- learn a lot
- potentially sell it to other companies
The reasons that different companies make custom chips are specific to them.
TPU and Trainium are competitive on perf/$ and as a result are largely sold out. But depending on who you are, perf and $ are different. For a lab building a 10k cluster, stacking Broadcom/Marvell GCP/AWS margins is not always better than NVIDIA neocloud. But if you’re GDM, it almost always is because no GCP margin. Also the NVIDIA sw stack is the default. Why take that risk?
For MTIA or MAIA or AMD GPUs or Groq or Cerebras or whatever else, the perf/$ on the most important workloads is just not competitive today. So MTIA is used for recsys, and the others are used for single node, small model inference only. And then they don’t produce enough of them for it to matter anyway.
For OpenAI and Anthropic, if you’re spending 100B on compute, and a chip program costs 1B for a tapeout why not give it a go? Pick a workload you care about, make some customizations for it (which are all just tradeoffs anyway), establish a new supply chain, and learn some things make some friends along the way.
Jun 7

Can someone give me a clear answer to why everyone wants their own custom silicon. I kinda get wanting to be less dependent on Nvidia, but then aren’t you just moving your dependency one layer up to tsmc? Or are there genuinely performance gains to be had with model-chip aligned?
2
6
68
22,872
Jun 4
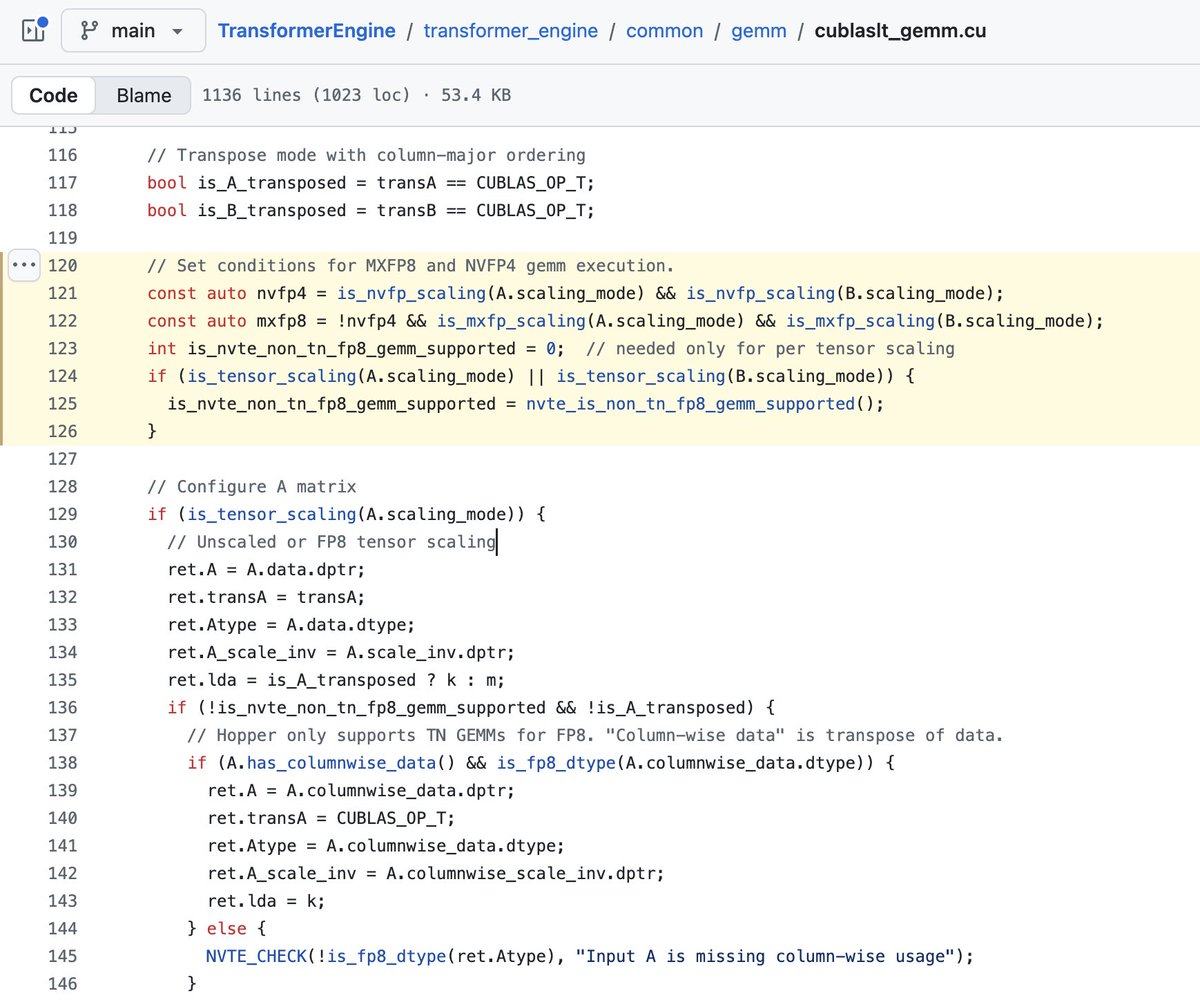
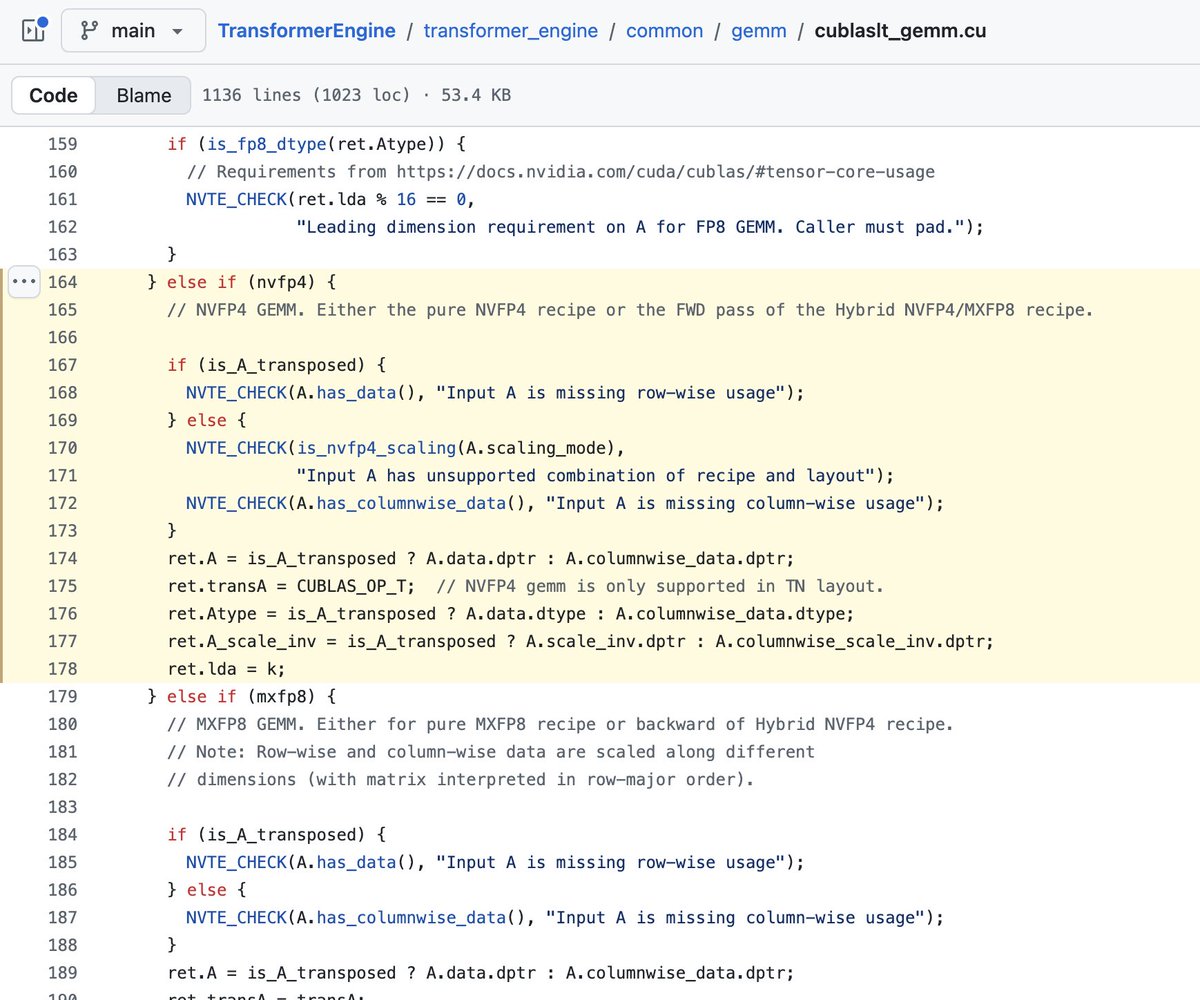
some of the open source kernels in the TransformerEngine repo that were used, showing the fallback to MXFP8 for the bwd pass
from: github.com/NVIDIA/Transforme…
2
251
Jun 4
worth going back to the original paper in December where this is described.
> Weight, activation, and gradient tensors are quantized to NVFP4 which enables use of NVFP4 GEMMs in fprop, dgrad, and wgrad.
> We kept latent projections in BF16 as its impact to step-time is minimal. We also keep MTP layers in BF16 due to their positioning at the end of the network and to preserve MTP capabilities.
> The Nemotron 3 family of models features a small ratio of attention to Mamba-2 layers, and each attention layer uses GQA with only 2 KV heads. To maintain the fidelity of these few attention layers, we kept the QKV and attention projections in BF16. We observed that Mamba output projection layers have high flushes to zero (up to 40% on Nano) when quantized to NVFP4. To prevent loss of information, we keep these layers in MXFP8.
1
211
Jordan Nanos retweeted

Apr 27
What are they asking for? I'll do it
10
2
227
27,934
Jordan Nanos retweeted

Mar 13
We’re the first cloud to bring up an NVIDIA Vera Rubin NVL72 system for validation, another big step in building the next generation of AI infrastructure with NVIDIA.

466
714
6,403
783,247
Jordan Nanos retweeted

May 31
151
381
3,428
1,333,231
May 27
Laguna M.1/XS.2 tech report from Poolside has lots of details on their infrastructure!

2
4
36
4,018
May 27
Nice to see the upstream to help improve public evals resistance to reward hacking
1
1
369
May 27
So good to see this much detail, great to see Apache 2.0, and excited for more
I skipped a bunch of stuff about the model design, data, evals, quantization etc.
Full report is here poolside.ai/assets/laguna/la…
1
6
374