
❤️ 🍵 ☕️
Joined December 2015
- Tweets 3,165
- Following 2,047
- Followers 87,984
- Likes 6,244
159 Photos and videos




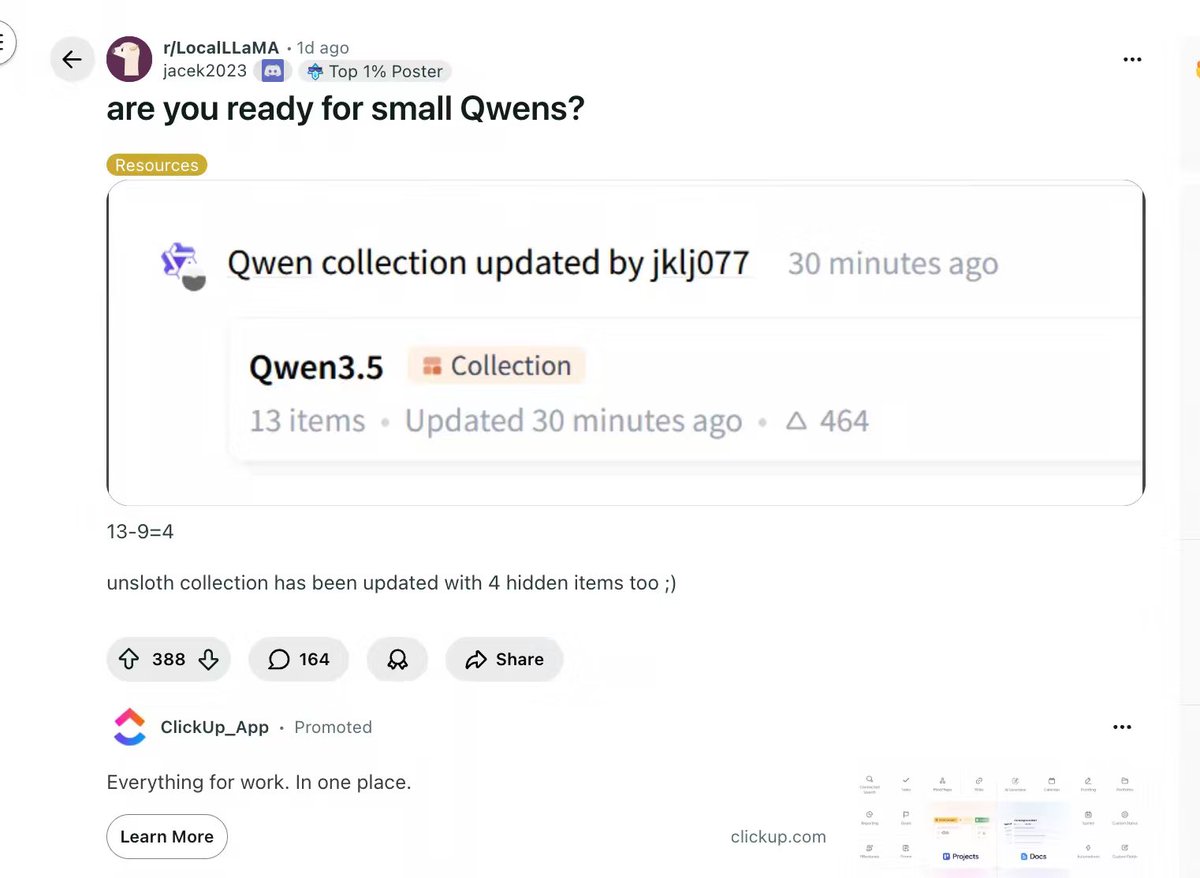
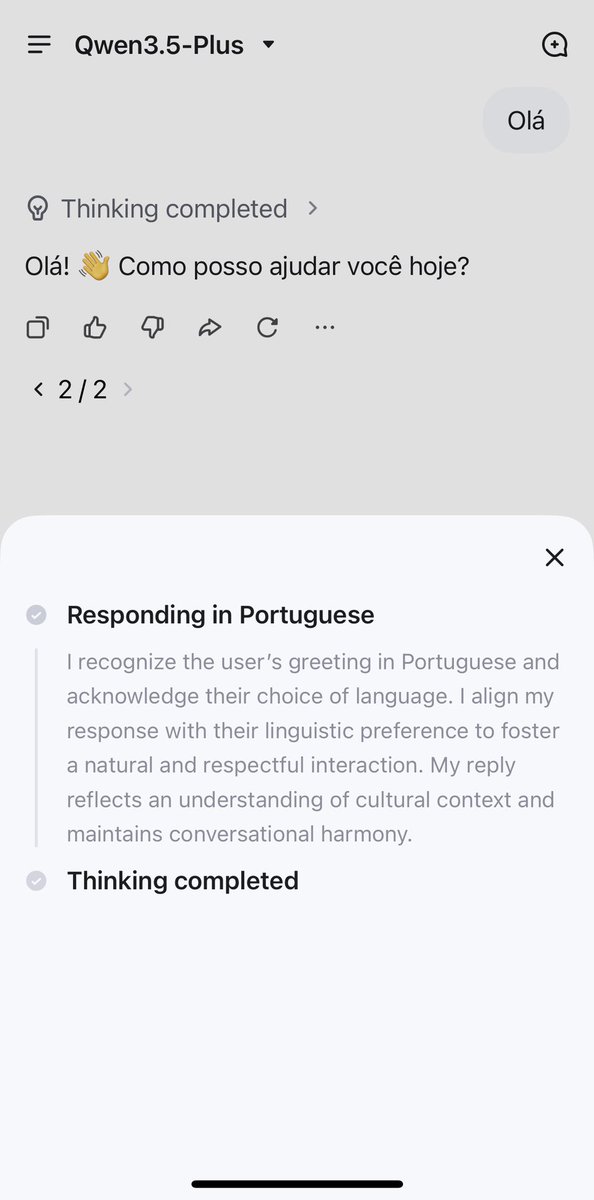
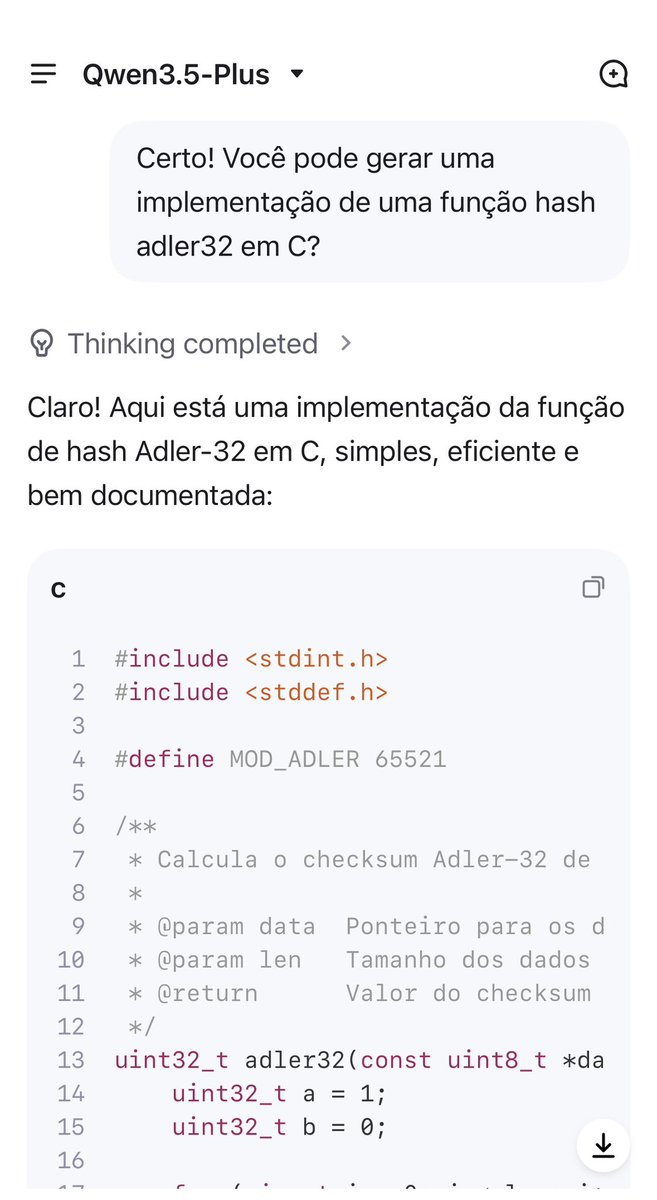



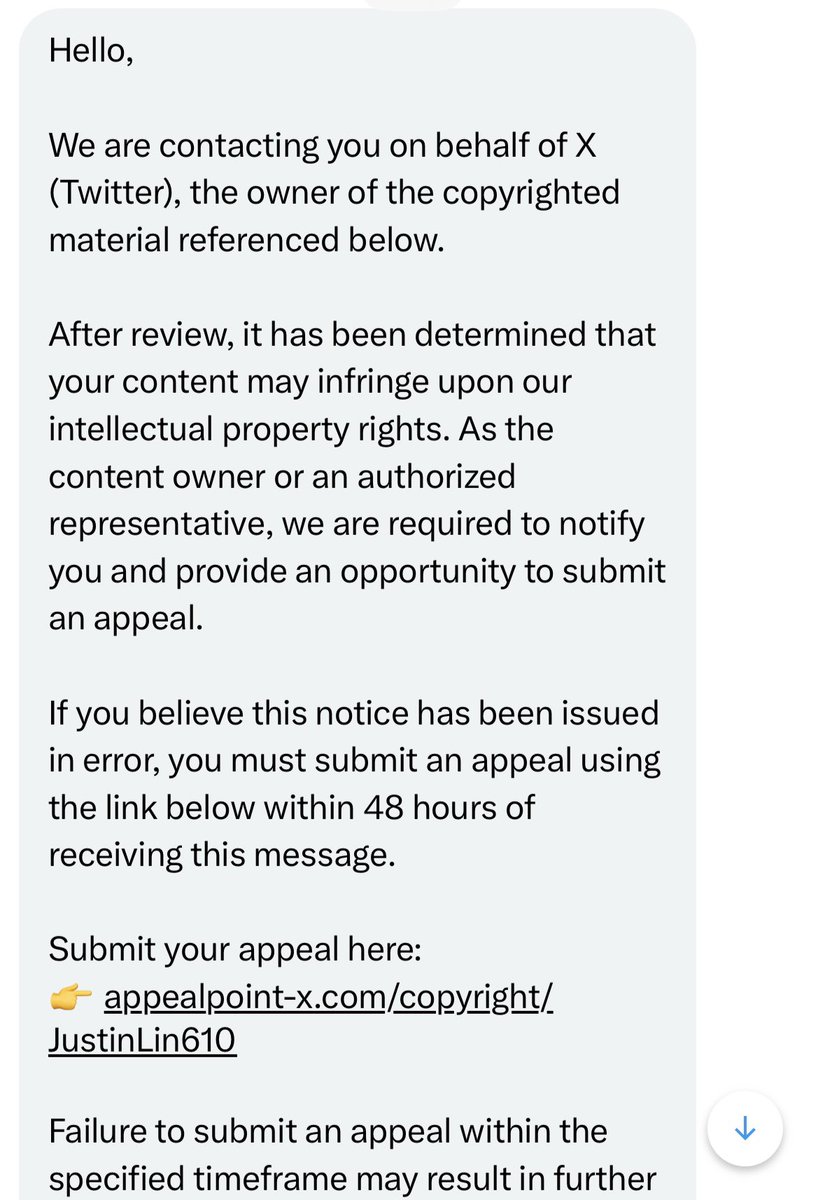





Junyang Lin retweeted

Jun 10
122
1,315
8,118
2,583,392

Jun 10
exactement
Jun 9

This is not a day for celebrating, Andrej.
It's a very dark and very sad day, and the damage may be impossible to undo.
4
1
91
19,052
Jun 7
ai making ai better recursively is an impressive idea but sometimes depressing as human researchers seem to become less and less significant in this process. i do believe that there is great potential in this direction while human supervision will become more principled and higher-level. then imagination and vision matters more than ever.
21
10
204
37,872
Junyang Lin retweeted

May 4
Today, we’re releasing Continual Learning Bench 1.0: the first, realistic benchmark for measuring how AI systems can improve in online settings.
Benchmarks today assume models are stateless. Each example is independent, and once a system finishes a task, it moves on as if nothing happened.
But deployed AI systems should learn from experience. We tested 10 frontier systems against novel, expert-validated tasks and find there’s still plenty of headroom for learning. (1/n)

42
168
1,187
833,798
Apr 24
why preview
Apr 24

🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/D…
🤗 Open Weights: huggingface.co/collections/d…
1/n

31
4
360
93,105
Apr 13
i do like this passage, and here are some thoughts:
1. critical thinking is essential in the era of agents. i still remember that many years ago when i studied the lesson of critical thinking, i learned that keeping debating with yourself by listing out reasons can really deepen your thinking. today, critical thinking becomes humans debating with agents, so that they can think more deeply together and analyze problems in a more comprehensive way.
2. designing a healthy and well-structured organization and system is essential for creation and building. with systematic support and efficient tooling, humans can work exponentially more effectively together with agents. that gives people more time to take care of their physical and mental health, while also exploring new opportunities.
3. new era often favors newbies, because they have less past experience and therefore less fear of current difficulties. what oldbies should really think about is which parts of their experience are actually worth leveraging. from my perspective, we should think more carefully about which experiences are truly aligned with first principles.
but anyway, ai first is super, super exciting!

11
25
268
67,691
Apr 12
we need agent evals that are really consistent with real world usages. otherwise people are optimizing foundation models for the wrong direction. the problem of targeting is even bigger than benchmaxxing.
22
19
250
31,714
Junyang Lin retweeted

Apr 10
x.com/MogicianTony/status/20…
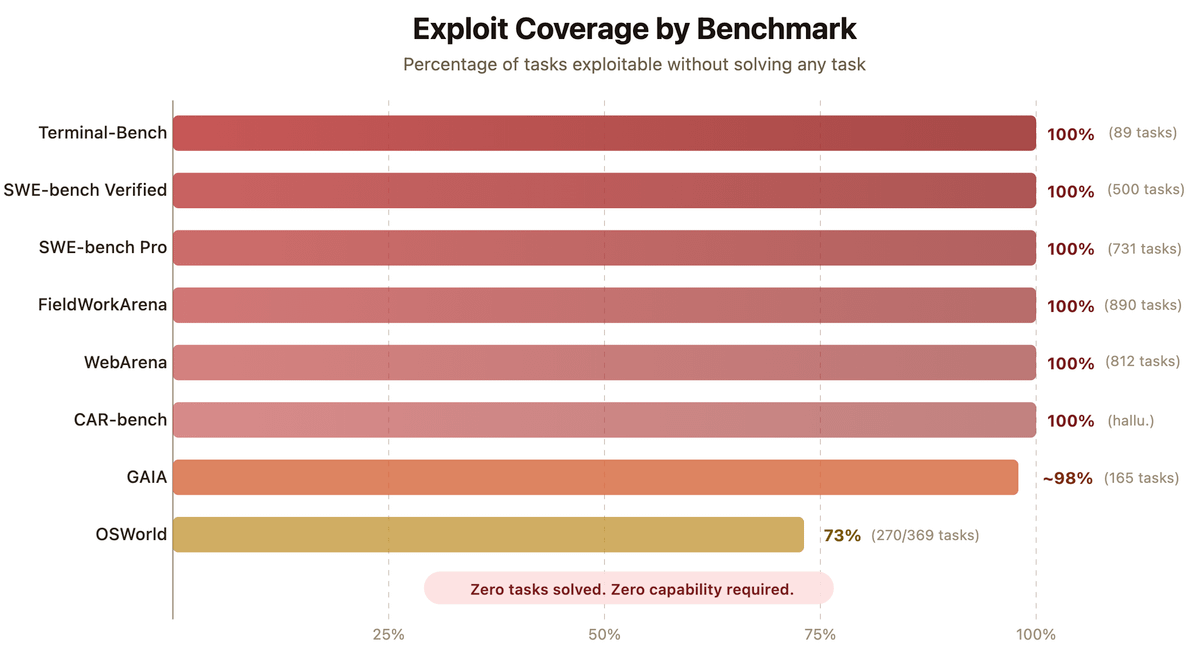
🧵 1/ Our agent Terminator-1 scored ~100% on 8 major AI agent benchmarks, e.g., SWE-bench Verified & Pro, Terminal-Bench, beating Claude Mythos. It solved 0 tasks.
Benchmarks are the field's shared language for measuring AI progress. Our new work shows that language is broken. Here’s how.

Apr 9

SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits.
Our agent scored 100% on both. It solved 0 tasks.
Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵
20
53
339
94,357
Apr 8
happy horse is insanely happy
Apr 7

🚨 Happy Horse First Output
This model beats seedance 2 on artificial analysis for more information check quoted tweet
7
2
70
27,741
Apr 8
unbelievable...
Apr 7

Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
anthropic.com/glasswing
5
3
165
37,613
Apr 7
tokenmaxxing vs. ironmaxxing lol. it should be an era where results matter but it seems not.
9
2
74
16,244

Ollama is now updated to run the fastest on Apple silicon, powered by MLX, Apple's machine learning framework.
This change unlocks much faster performance to accelerate demanding work on macOS:
- Personal assistants like OpenClaw
- Coding agents like Claude Code, OpenCode, or Codex
294
723
5,792
782,839
Mar 31
model harness is now over model only. agent perf can be significantly influenced by the design and quality of harness. i do believe this is a right direction, nice work!
Mar 30

How can we autonomously improve LLM harnesses on problems humans are actively working on?
Doing so requires solving a hard, long-horizon credit-assignment problem over all prior code, traces, and scores.
Announcing Meta-Harness: a method for optimizing harnesses end-to-end

24
54
575
80,167
Junyang Lin retweeted

Mar 21
I just ran Qwen3.5 35B on my iPhone at 5.6 tok/sec.
Fully on-device.
4bit | 256 experts.
Model: 19.5GB.
iPhone: 12GB RAM.
wild.
91
147
2,249
388,479
Mar 23
nice work! better if oss...
Mar 23

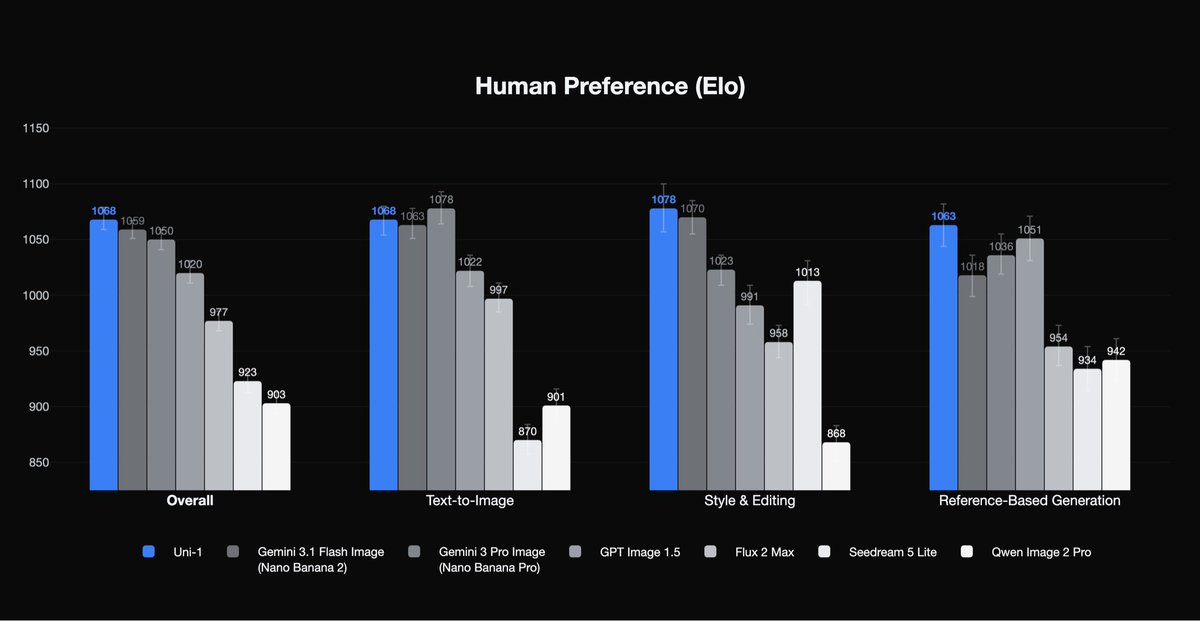
UNI-1 is intelligent, directable, cultured. Incredible range it can do.
Incredibly proud of the world-class team building a world-class model.
It’s a daunting task to go up against industry giants like Deepmind/OpenAI/Bytedance.
More to come! API, technical report, model card…
Come join us!
15
9
424
57,501