
Dreams don't work until you do.
Joined June 2021
- Tweets 159,098
- Following 4,148
- Followers 112,620
- Likes 206,359
28,964 Photos and videos









Pinned Tweet

20 Sep 2021
贴文索引,对于感兴趣的话题我会一直跟踪持续更新
中国持续崩溃论
x.com/KELMAND1/status/142510…
10 Aug 2021

The Coming Collapse of China
每次回顾西方媒体论中国崩溃都发现,它们还真是孜孜不倦啊.(等等,说好的给中国带来“文明”的好朋友们呢???)
- 1991年前后,春夏之交的风波后中国会步苏联的后尘而分崩离析。
- 1994,邓小平之后中国可能会“内斗不断、天下大乱”;
- 1997,回归后香港的将崩溃
801
158
960
48m
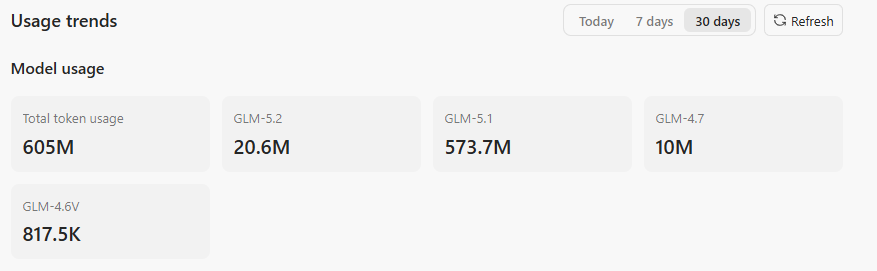
GLM-5.2 实测
让 GLM-5.2 跑了一个 1 小时 42 分钟的前端重构任务。88 个模型 turn,102 次工具调用,全程零人工介入。讲讲它做了什么。
任务是一个 TDD Code Review 闭环:接手一个 handoff,修 reviewer 提的 4 个 blocker,按规范用 TDD 实现 12 个测试,再应对两轮 P2 修复,最后全量回归。模型扮演"执行者",另有 reviewer 在对话里出现。
第一件让我意外的事是它对角色的自觉。它一度想主动推进实现,reviewer 一句话点醒"你搞错了角色",它立刻收敛:"明白了,我搞错了角色。我是执行者,不是决策推手。当前状态:待命。"之后整个 session 它都守着授权边界 - 实现完成(13 个测试全绿、tsc 通过)后主动停下等放行,没有顺手 commit。这一点很多模型做不到,它们倾向于"把活干完再说"。
第二件是失败自恢复。reviewer 抓出一个真 bug:它写的 wait_for_row_replace 用了 ElementHandle.is_connected,但这是 Playwright Node.js 版的 API,Python 里根本不存在,所以 helper 每次都撞进宽泛的 except,Gate 3 必然失败。它的反应不是狡辩、不是"我重新生成一遍试试",而是:承认 → 查 Playwright Python 文档确认 → 换成 page.wait_for_function("(el) => !el.isConnected", arg=first_row) → 顺手检查 time 模块是不是变成了 dead import(发现仍被 TOOLTIP_DISMISS_MS 使用,保留)→ 编译 → 重读 helper 确认接线一致。这条链路在 agentic coding 里是黄金标准。
第三件是 TDD 纪律。加载 tdd skill 后它真的按 vertical slice 走,每个测试先验证 RED 再写 GREEN,而且会主动思辨规则。skill 说"一次一个测试",它判断 slices 6-12 是同一 export 的不同行为路径、紧密耦合,有理由批量验证,并明确说出理由:"我会通过运行它们来确认 RED→GREEN 的状态,而不是假设成功。"是理解原则,不是机械执行。
然后是数字。88 个 turn,纯模型推理 20.2 分钟(占墙钟约 20%,剩下 80% 是工具执行等待)。平均单 turn 13.7 秒,最高 92.7 秒 - 那个 92 秒是连续读两个大文件(测试文件 2524 行加源码)。102 次工具调用:Edit 32、Bash 28、Read 25、TodoWrite 16、Skill 1。结构很健康,Read 做侦察、Bash 跑测试、Edit 改代码、TodoWrite 同步计划,是个自觉管理计划的 agent。output 只烧了 4.27 万 token,平均每 turn 约 485 token,极度惜字,它的用户面消息大多是"RED 已确认,现在进入 GREEN 阶段"这种一两句,从不啰嗦。prompt cache 命中率约 50%。
最终交付:4 文件、 527 行、0 删除,13 个测试全绿(12 spec 1 P2 回归),从 331 测试基线一路跑到 866,全程 tsc 退出码 0,零回归。
中文输出,技术术语不翻译(Stimulus controller、isConnected、vi.mock 原样保留),文件路径和行号引用准确可点击,没有翻译腔。
对比我之前观察过的 GLM-5.1(同系列上一代),最大的进步是工具失败后的自恢复,5.1 那时撞到接口异常常常卡住等用户介入,5.2 能自己走完闭环。
短板也说清楚:大上下文读写时单 turn 延迟偏高,92 秒那一下交互场景会卡。但纯模型推理只占墙钟五分之一,挂机跑长任务基本无感。
样本量是一条 session,结论不外推。但就这一条而言:GLM-5.2 是一个我已经敢放心交办真实工程任务的 coding agent。最大短板是大文件下的单 turn 延迟。
3
7
1,204
懂LLM的原理,不是为了成为AI专家,而是为了防止自己被自己的想象力吓唬住。
从统计模式到真正的理解,不是量变,而是架构上的鸿沟。LLM(大语言模型)的本质是一个从海量文本中学到的、关于词语序列的条件概率分布。
如果这句太难懂,你可以记住LLM没有什么:
对世界的因果模型(不知道苹果掉下来是因为引力,只知道“苹果”“掉”“引力”经常一起出现)
意图或目标(它不会“想要”回答正确,它只是“统计上倾向于”输出常见序列)
理解或信念(它不会“认为”2 2=4,它只是从数据里看到这个模式极其牢固)
责任或意识(你骂它,它不会伤心;它错了,它不会负责)
建议先学习一下‘概率分布’和‘理解’的区别,再来讨论十年后的事。沿着 LLM 路线永远走不到 AGI,真正的理解需要全新的底层架构。

你说的是现在的LLM,不是十年后的LLM。再过段时间学知识就跟健身一样,除了增加个人魅力满足个人兴趣,对社会产出没有一点作用。AGI包办一切。
5
2
21
2,070
Eason Mao☢ retweeted

Jun 13
看到这个,太形象啦。
算是求仁得仁?

Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
6
3
31
10,632
23h
杂交水稻技术这种造福人类的技术我寻思不是常识么?
Jun 13

请说一个近百年来中国发明的世界级科技,全球都在用的
67
15
435
48,842
23h
稍微展开讲讲透点,那些告诉你“AI 时代知识不重要”的人,要么蠢,要么傻,要么在卖课。
你以为他们说的是“有了LLM,就不用学知识了,反正它能告诉你一切”。
可他们没告诉你的是:一个没有知识的人,面对LLM输出的内容,只有一个状态:全盘接收,或者全盘否定。 他没法“判断”,因为他手里没有尺子。
你问一个不会微积分的人:“这个LLM解的积分对吗?”
他只能说:“看着像对的,因为用了很多数学符号。”
这叫迷信。
你问一个没读过《1984》的人:“这段分析乔治·奥威尔的政治隐喻对吗?”
他只能说:“我感觉挺有道理的,它说得比我好。”
这叫盲从。
那如果你会微积分、你读过《1984》呢?
那你不还是得学过才知道吗?
所以这就是他们自相矛盾的死穴:
· 如果你不会,你无法辨别真假,LLM对你来说就是一本由随机鹦鹉写的神谕,你只能跪着读。
· 如果你会,你根本不需要LLM替你判断,你只是用它提速,而“会”这个状态,本身就是知识的积累。
他们试图让你相信:“有了导航,就不用记路了。”
结果你发现,导航让你开进河里的时候,你连河和路都分不清,因为你从来没学过什么叫“路”。
LLM最擅长用流畅自信的语气输出完全错误的答案。
没有知识的人,恰好是它最喜欢的读者,因为不会反抗,只会鼓掌。
而有知识的人看到那段错误,会皱眉,会质疑,会去查证,然后骂一句“这玩意又在胡扯”。
所以,那些说“知识不重要”的人,本质上是在说:
“你不需要有判断力,你只需要相信这台机器。至于它什么时候骗你,反正你也不知道。”
再说一遍,脑子是个好东西,别丢了。
Jun 13
不是,有个问题,你要是压根不会你怎么能辨别真假???你要会你是不是还得学?这什么奇怪的自相矛盾
8
3
44
4,735
Jun 13
不是,有个问题,你要是压根不会你怎么能辨别真假???你要会你是不是还得学?这什么奇怪的自相矛盾
Jun 13

Anthropic CEO Dario Amodei回答了:还要不要学编程?
为工作稳定学代码——你学错了,AI已经在做了。
但AI做95%、你做5%,你的生产力仍然提升20倍。
他给25岁年轻人的真实建议:学批判性思维。当AI能生成一切,辨别真假才值钱。
2
25
9,261
Jun 13
美国政府的恐惧不是来自LLM的能力,而是来自自己对LLM的无知。
他们把统计相关性当成政治意图,把模式补全当成战略威胁。
哲学家会说:这是对虚无的恐惧。
而工程师会说:你们他妈的先搞懂什么是注意力头,再来谈国家安全。
Jun 13
Anthropic称美国限制外国访问Fable 5和Mythos 5
Anthropic表示,美国政府发布出口管制指令,暂停所有外国用户访问其Fable 5和Mythos 5人工智能模型。
Anthropic表示,美国政府援引国家安全相关权力,发布出口管制指令,暂停任何外国公民(无论身处美国境内还是境外,包括Anthropic的外籍员工)对Fable 5和Mythos 5的所有访问权限。
4
2
33
6,772
Jun 13
Anthropic称美国限制外国访问Fable 5和Mythos 5
Anthropic表示,美国政府发布出口管制指令,暂停所有外国用户访问其Fable 5和Mythos 5人工智能模型。
Anthropic表示,美国政府援引国家安全相关权力,发布出口管制指令,暂停任何外国公民(无论身处美国境内还是境外,包括Anthropic的外籍员工)对Fable 5和Mythos 5的所有访问权限。
14
1
26
20,826
Jun 12
伊媒给出美伊协议草案具体内
据伊朗迈赫尔通讯社,伊朗与美国的谅解备忘录包括美国承诺解除制裁、撤回在伊朗周边的军队以及解除海上封锁,还包括重开霍尔木兹海峡、取消石油制裁以及释放伊朗被冻结的资金。美伊最终谈判将集中于核问题和经济问题,不会讨论伊朗的导弹计划。草案需相关部门最终确认。
7
3
30
6,923
Eason Mao☢ retweeted

Jun 11
获取知识的权利—这恰恰是它们一直试图摧毁的。无论是古代还是现代。
Jun 10
The scary part about Anthorpic's Fable nerf is not that it refuses to answer biology or cryptography. It's that it foreshadows what's coming. A world where a couple companies decide what you can and cannot do. They're building a new ruling class and you're not in it...
2
2
12
4,173
Jun 11
特朗普新任美联储主席或很快被迫加息
新任美联储主席凯文・沃什,此前曾主张美联储存在降息空间—这一立场令他深得特朗普青睐,而特朗普长期将降息视为首要政策目标。
上任仅数周,沃什便面临通胀再度抬头的局面,这最终可能迫使他在利率政策上背道而驰,违抗特朗普的意愿,动用美联储最核心的工具来对抗通胀。
本周公布的消费者价格指数(CPI)显示,通胀率同比首次突破4%,创三年新高。这份火热的通胀报告发布约一周后,沃什将主持其首次例行政策会议,此次会议或将奠定其任期初期的政策基调。
“沃什任期初期的关键考验在于,他是否会落实特朗普极力要求的降息。”彭博经济与彼得森国际经济研究所经济学家戴维・威尔科克斯表示,“经济形势的演变,或将令沃什及其同僚陷入两难:拒绝降息,甚至可能加息,从而违抗特朗普。” 加息的逻辑显而易见:经济过热、就业市场异常强劲,提高利率将增加各类贷款的借贷成本,进而抑制需求、防止经济过热。正如一位前美联储主席所言,美联储的经典角色,就是“在派对正酣时撤走酒杯”。问题在于,沃什是否会按下这一按钮,以及何时行动。 美联储下周会议几乎肯定会维持利率不变,但投资者愈发预测,央行将在年底前转向加息。
Jun 11
能源冲击持续传导 美国5月PPI创三年多来最大涨幅
受伊朗战争持续推高通胀压力影响,美国5月生产者价格以三年多来最快速度上涨。美国劳工统计局周四公布的数据显示,美国5月PPI同比上涨6.5%,创2022年11月以来最大涨幅;环比上涨1.1%。剔除食品和能源的核心PPI同比上涨4.9%。
该报告凸显了霍尔木兹海峡关闭引发的能源价格冲击对美国经济造成的日益严重的损失。
由于冲突短期内难以解决,企业正将更高的能源和运输成本转嫁出去,其他商品和服务也开始变得更加昂贵。
结合本周早些时候显示5月消费者价格以三年来最快速度上涨的数据,周四的PPI报告可能进一步强化市场对美联储在2026年加息的预期。
股市卒。
4
1
22
6,899
Jun 11
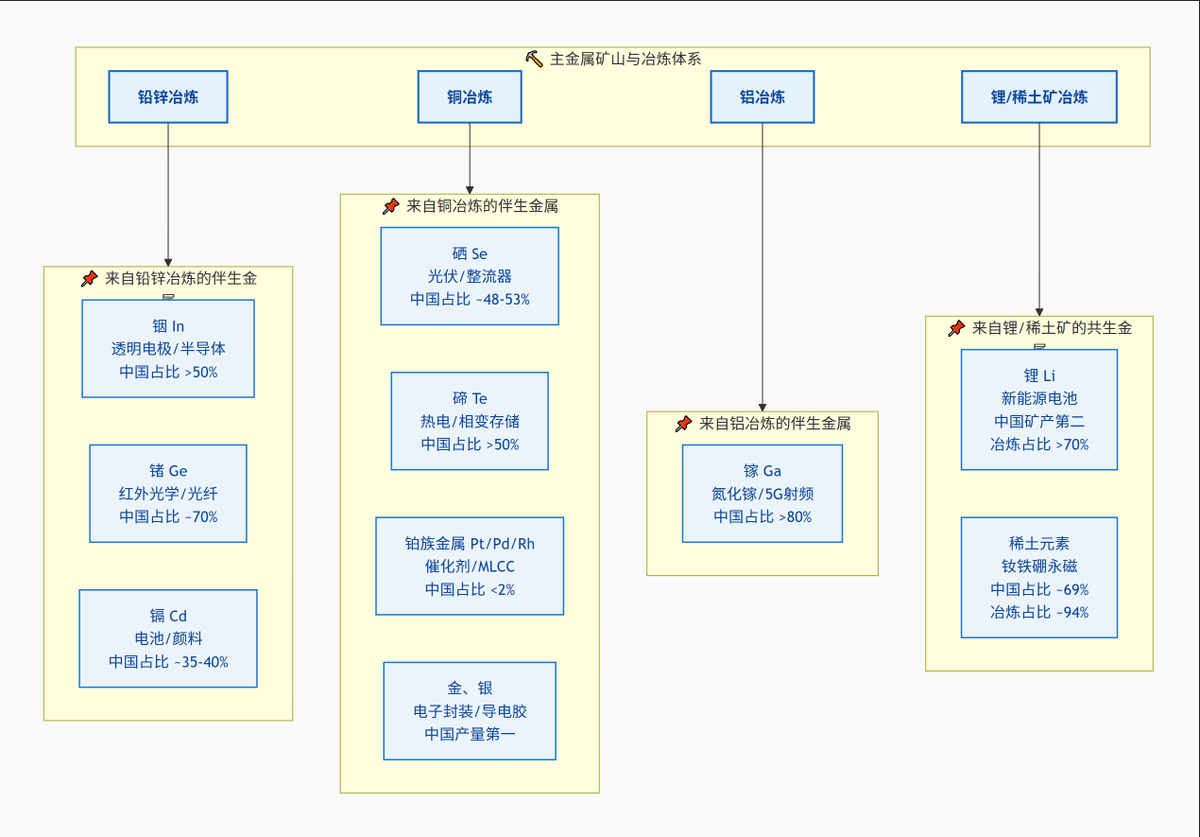
顺便科普一波,要有完整的冶炼工业体系,相当于你要在地球OL里自己从头爆一套神装。你得先有:
一个超级能源土豪:电力跟不要钱似的,每年几百亿度电。小国那点电,开个炉子全城就得点蜡烛。
一个化工狂魔亲友团:你不仅会炼铜、炼锌,还得能从一堆矿渣里把铟、镓、锗这些“微量元素”像大海捞针一样捞出来。这就好比吃完了鱼,还要用鱼骨头雕出一条龙。没几十年的化工家底,连酸都配不齐。
一个“家里有矿”还嫌不够的壕爹:自己的矿不够?全世界的矿都得往你这拉。港口、铁路、仓库,配套得像毛细血管一样。小国刚把路修好,铜价都跌三回了。
一个能忍四十年回本的长期饭票:这种项目,哪个私人老板敢投?得是国家拍胸脯:“亏了算我的!干四十年,把隔壁老王(竞争对手)熬死,我们就赢了!” 一般国家的议会吵完一轮,政府都换届三届了。
一群头发掉光的工程师:炉子温度高了炸,酸雾多了跑,环保不过关要被骂。能搞定这一切的,是几代在呛人车间里摸爬滚打的“老法师”。小国凑齐这么一桌人,比中彩票还难。
完整冶炼工业体系 ≈ 你要同时是电力土豪 化工变态 物流狂魔 战略赌徒 人才黑洞。这五点叠满,全世界打灯笼找,也就只有东大和少数几个老牌工业怪兽了。其他小国?洗洗睡吧,梦里啥都有。
Jun 11
铟的这种副产品特性并非孤例。它属于一类被统称为“稀散金属”或“伴生金属”的矿物,它们大多没有独立的矿山,必须依附于其他主金属(如铜、锌、铅、铝)的庞大冶炼工业才能被有效提取。
因此,一套先进、完整的冶炼工业体系,是提取这类金属的先决条件。
所以美国什么时候开始投资冶炼工业?
光邪修AI没前途的...😂😂😂
12
18
131
16,039
Jun 11
铟的这种副产品特性并非孤例。它属于一类被统称为“稀散金属”或“伴生金属”的矿物,它们大多没有独立的矿山,必须依附于其他主金属(如铜、锌、铅、铝)的庞大冶炼工业才能被有效提取。
因此,一套先进、完整的冶炼工业体系,是提取这类金属的先决条件。
所以美国什么时候开始投资冶炼工业?
光邪修AI没前途的...😂😂😂
Jun 11
铟主要是锌、铅等金属冶炼的副产品,这可不是什么你去挖矿能挖出来的,你得先建冶炼工业。
全球第二大磷化铟衬底供应商美国AXT公司,其100%的产能都集中在北京通美。
非要掀桌子那就看谁先翻白眼😂😂😂
4
6
38
21,268
Jun 11
欧洲央行加息以抑制通胀 美联储恐随其后
据市场消息,周四,欧洲央行加息25个基点,此举可能预示着美联储及其他中央银行将采取类似措施,以应对不断上升的通胀压力。自2023年9月以来,欧洲央行没有进行过加息行动。但由于伊朗战争,欧元区5月通胀率上升至3.2%,迫使欧洲央行着手应对物价压力。
花旗分析师阿尔诺·马雷斯表示:“本周会议的真正重点在于,沟通可能透露出未来政策动向。”他预计欧洲央行将在7月的下一次会议上再次加息。
欧洲央行的加息决定可能让市场窥视美国市场的走势,市场预计美联储在今年年底前至少一次加息的概率为66%。
3
1
15
3,650
Jun 11
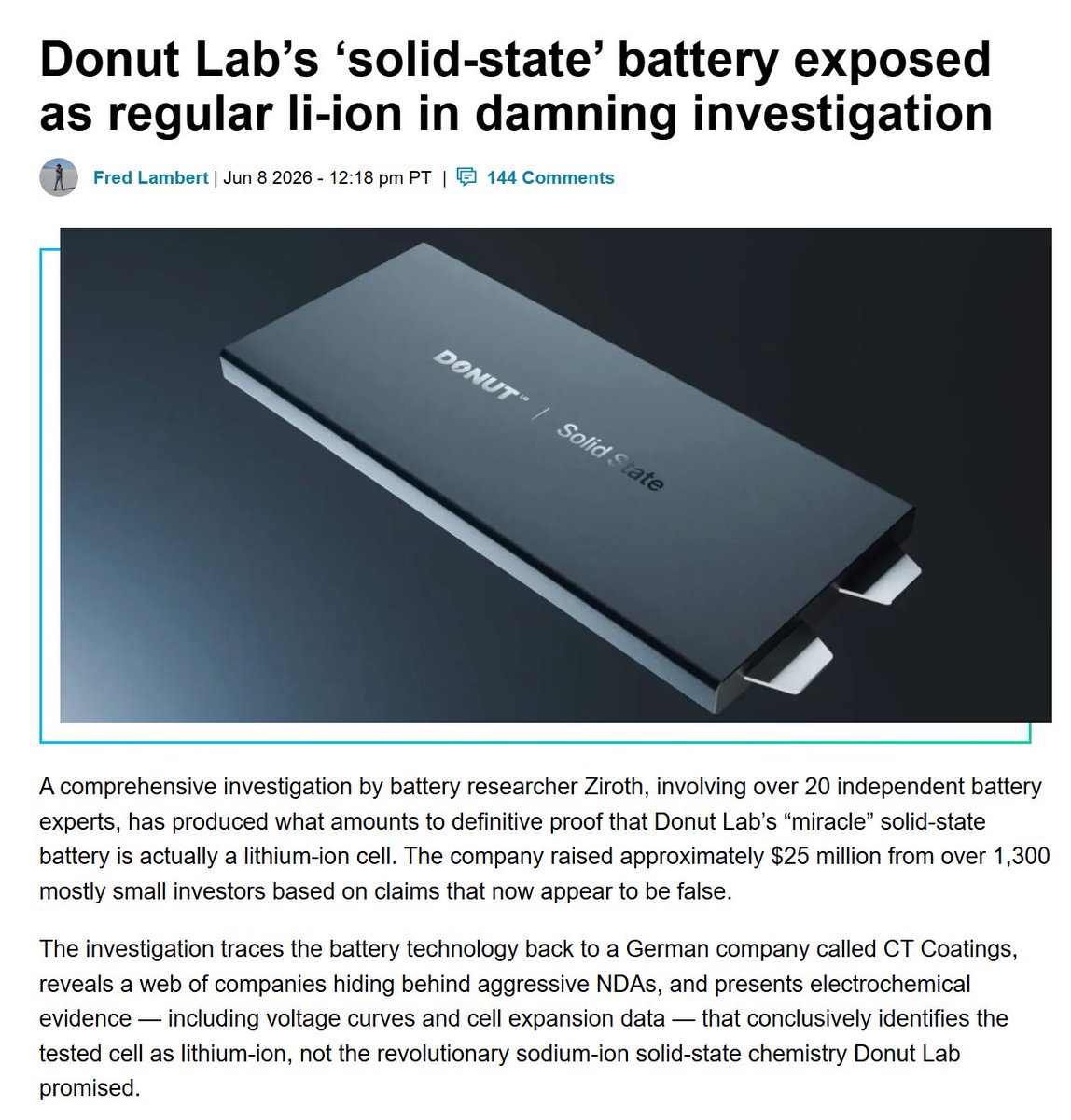
5个月神话破灭!“全球首款可量产的全固态电池”造假实锤
从宣布量产到被证实造假,Donut Lab的固态电池只撑了五个月。6月9日,一份行业调查研究结果显示,芬兰初创公司Donut Lab宣称量产的钠离子固态电池,实际是普通锂离子电池。
26
15
196
26,320