
Photos and videos

Jun 6
Very cool! Congrats @HaojunQiu !
Jun 5

📢📢📢We introduce Efficient-SID⚡️: training-free single-image diffusion model that generates images by sampling directly from an input image's patch distribution. Our method enables megapixel generation in <1s and scales to gigapixel generation. We also enable stylization, editing, and other applications. The outputs are constrained to follow exactly the patch distribution of the input — something that is very difficult to do with large models!
#CVPR2026 Highlight
🌐 haojunqiu.github.io/efficien…
📄 arxiv.org/abs/2606.04299
[1/6]
1
107
Junru Lin retweeted

17 Oct 2025
Excited to announce a new track of accelerating Generative AI:
pi-Flow: Policy-Based Few-Step Generation via Imitation Distillation
github.com/Lakonik/piFlow
Distill 20B flow models now using just an L2 loss via imitation learning for SOTA diversity and teacher-aligned quality.

2
27
155
36,290
Junru Lin retweeted

3 Aug 2025
Woohoo! Imagine, Verify, Execute (IVE) is accepted to CoRL 2025! 🎉
Congrats to the incredible @umdcs students Seungjae Lee @JayLEE_0301, Daniel Ekpo (@daniekpo7), Haowen Liu!
13 May 2025

Exploration is key for robots to generalize, especially in open-ended environments with vague goals and sparse rewards.
BUT, how do we go beyond random poking? Wouldn't it be great to have a robot that explores an environment just like a kid?
Introducing Imagine, Verify, Execute (IVE)!
IVE leverages Vision-Language models to
• extract semantic scene graphs,
• imagine novel scenes,
• predict their physical plausibility, and
• generate executable sequences.
IVE is a memory-guided agentic exploration framework that operates fully automatically, enabling more diverse and meaningful exploration.
1
10
57
15,757
Junru Lin retweeted

11 Jul 2025
We will present FlexTok at #ICML2025 on Tuesday! Drop by to chat with @JRAllardice and me if you're interested in tokenization, flexible ways to encode images, and generative modeling.
📆 Tue, Jul 15, 16:30 PDT
📍 East Exhibition Hall, Poster E-3010
🌐 flextok.epfl.ch
20 Feb 2025

Have you ever been bothered by the constraints of fixed-sized 2D-grid tokenizers? We present FlexTok, a flexible-length 1D tokenizer that enables autoregressive models to describe images in a coarse-to-fine manner.
flextok.epfl.ch
arxiv.org/abs/2502.13967
🧵 1/n

5
24
1,262
Junru Lin retweeted

12 Apr 2025
Which multimodal LLM should you be using to edit graphics in Blender?
Today, we’re releasing our #CVPR2025 Highlight🌟 work, #BlenderGym 🏋️♀️, the first agentic 3D graphics editing benchmark that will tell you exactly how multimodal LLMs compare in their Blender-editing skills.
What'd we find? 🧵👇
8
36
83
22,903
Junru Lin retweeted
8 Apr 2025
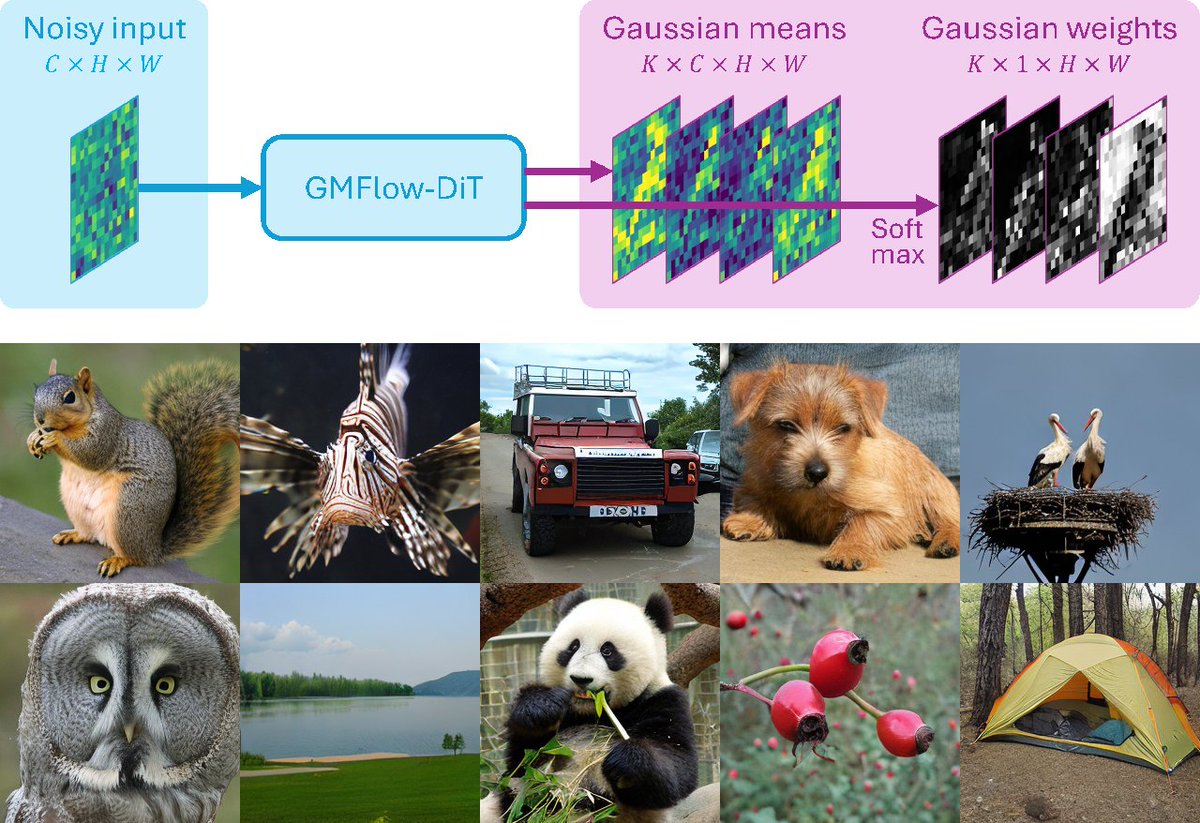
Excited to share our work:
Gaussian Mixture Flow Matching Models (GMFlow)
github.com/lakonik/gmflow
GMFlow generalizes diffusion models by predicting Gaussian mixture denoising distributions, enabling precise few-step sampling and high-quality generation.
1
31
127
13,431
Junru Lin retweeted
6 Apr 2025
Happy to share that we released FlexTok code and models on github.com/apple/ml-flextok.
Try them with our interactive @huggingface demo on huggingface.co/spaces/EPFL-V…
4 Apr 2025

Excited to share that we have recently released the source code for FlexTok, bringing a fresh perspective to tokenization.
Code on GitHub: lnkd.in/g4iNJFmU.
Project Page: flextok.epfl.ch/
#FlexTok #Tokenization #MachineLearning #MLResearch #OpenSource #AI
15
73
13,589
Junru Lin retweeted

26 Mar 2025
🏡Building realistic 3D scenes just got smarter!
Introducing our #CVPR2025 work, 🔥FirePlace, a framework that enables Multimodal LLMs to automatically generate realistic and geometrically valid placements for objects into complex 3D scenes.
How does it work?🧵👇
22
84
374
117,073
Junru Lin retweeted

12 Mar 2025
Meet Gemini Robotics: our latest AI models designed for a new generation of helpful robots. 🤖
Based on Gemini 2.0, they bring capabilities such as better reasoning, interactivity, dexterity and generalization into the physical world. 🧵 goo.gle/gemini2-robotics
170
444
2,116
642,151
Junru Lin retweeted

11 Mar 2025
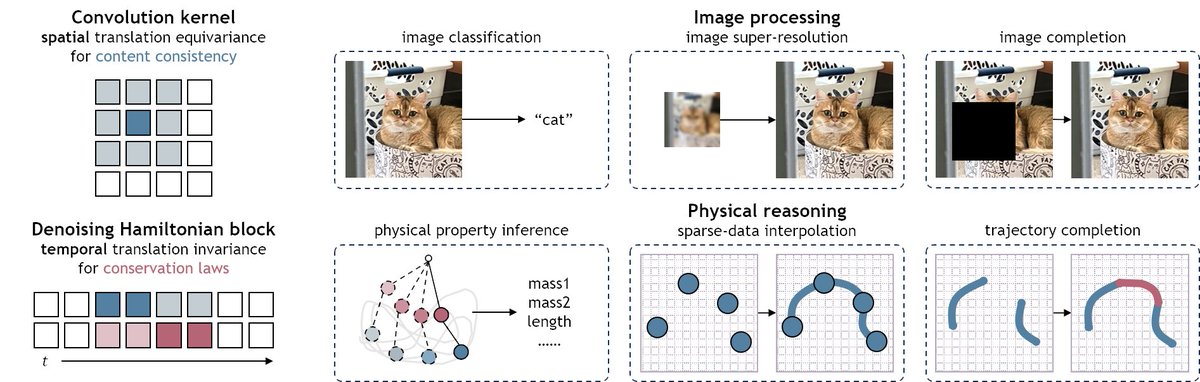
In the past, we extended the convolution operator to go from low-level image processing to high-level visual reasoning. Can we also extend physical operators for more high-level physical reasoning?
Introducing the Denoising Hamiltonian Network (DHN): arxiv.org/pdf/2503.07596
6
58
314
41,148
Junru Lin retweeted

22 Jan 2025
Thrilled to announce that SG-I2V has been accepted at #ICLR2025 ! Huge thanks to the collaborators, reviewers, and ACs. Looking forward to presenting this in Singapore!
8 Nov 2024

Thrilled to share SG-I2V, a tuning-free method for trajectory-controllable image-to-video (i2v) generation, solely built on the knowledge present in a pre-trained i2v diffusion model !
kmcode1.github.io/Projects/S…
w/ @sherwinbahmani @Dazitu_616 @yash2kant @igilitschenski @DaveLindell
4
9
42
5,143
Junru Lin retweeted

Congratulations to @UofTCompSci undergrads Helen Li, Junru Lin, Leo Tenenbaum and Sarah Walker who have received honourable mentions in the @CRAtweets 2024-2025 Outstanding Undergraduate Researcher Award program! cra.org/about/awards/outstan…

1
2
5
593

🔥 Introducing MVLift: Generate realistic 3D motion without any 3D training data - just using 2D poses from monocular videos! Applicable to human motion, human-object interaction & animal motion. Joint work w/ @jiajunwu_cs & Karen
💡 How? We reformulate 3D motion estimation as generating consistent multi-view 2D pose sequences. Our framework uses 2D motion diffusion to progressively establish multi-view consistency, requiring only single-view 2D pose sequences for training.
Project: lijiaman.github.io/projects/…
Video with demonstration: youtube.com/watch?v=nffTJHUR…
Paper: arxiv.org/abs/2411.18808
2
38
213
15,826
Junru Lin retweeted

17 Dec 2024
Introducing 🧢CAP4D🧢
CAP4D turns any number of reference images (single, few, and many) into controllable real-time 4D avatars. 🧵⬇️
Website: felixtaubner.github.io/cap4d…
Paper: arxiv.org/abs/2412.12093
13
97
574
76,390
Junru Lin retweeted

9 Dec 2024
Do large multimodal models understand how to make dresses for your winter holiday party💃?
We introduce AIpparel, a vision-language-garment model capable of generating and editing simulation-ready sewing patterns from text and images. Project page at georgenakayama.github.io/AIp….
[1/n]
1
17
67
11,835
Junru Lin retweeted

4 Dec 2024
[Hiring!] I am hiring multiple PhDs @CSatUSC @USCViterbi for this cycle. If you're interested in scene representations, neural simulation, generative AI, and robotics, feel free to mention my name in your application (no need to email). For USC masters/undergrads who're interested in our research, feel free to fill in this form forms.gle/RerZfDqCqmCj8As27.
1
47
270
32,650
Junru Lin retweeted

28 Nov 2024
Sharing something exciting we've been working on as a Thanksgiving gift: Diffusion Self-Distillation (DSD), which redefines zero-shot customized image generation using FLUX.
DSD is like DreamBooth, but zero-shot/training-free. It works across any input subject and desired context—character consistency, item/asset adaptation, scene relighting, and more.
It even enables the creation of comics/mangas without any effort in fine-tuning or training a personalized model!
📰 Paper: arxiv.org/abs/2411.18616
🌐 Website: primecai.github.io/dsd/
Team effort with @ericryanchan, @zhang_yunzhi, @GuibasLeonidas, @jiajunwu_cs, and @GordonWetzstein.
24
73
435
60,565
Junru Lin retweeted

27 Nov 2024
📢 Excited to share our new work: AC3D: Analyzing and Improving 3D Camera Control in Video Diffusion Transformers
snap-research.github.io/ac3d
We analyze what pre-trained video diffusion transformers understand about 3D and demonstrate dynamic scene generation with 3D control.
6
23
119
15,707
Junru Lin retweeted

26 Nov 2024
I'm recruiting graduate students for Fall 2025 to work at the intersection of Computer Vision, Deep Learning, and Robotics.
If you are interested in building a controllable organic simulation engine and enabling safe robot learning, consider applying to UofT's CS PhD program 1/n

11
82
426
49,679
Junru Lin retweeted

21 Oct 2024
Check out our new paper in feed-forward 3DGS model for large scenes! And the code is also available
This tweet is unavailable
1
6
84
8,222