
Joined April 2024
- Tweets 231
- Following 233
- Followers 2,704
- Likes 456
57 Photos and videos










May 28
We did it!
Thrilled to announce that with my team at FAIR Meta we released 25 auto-formalized mathematics textbooks covering analysis, algebra, geometry, topology, combinatorics, probability, statistics, PDEs, number theory, and theoretical computer science - the largest such effort to date.
May 28

Our team at @AIatMeta is excited to announce ATLAS: one of the largest automated formalization efforts to date.
ATLAS contains Lean 4 formalizations of both statements and proofs from 25 mathematics textbooks, spanning dozens of domains, for a total of 500k lines of code. We are also releasing a flexible formalization harness and a companion paper.
External contributions are welcome!
Joint work spearheaded by our amazing PhD student Ahmad Rammal (@Ahmad3Rammal), together with Niket Patel (@niketnpatel ), Fabian Gloeckle (@FabianGloeckle), Amaury Hayat (@Amaury_Hayat), Remi Munos (@MunosRemi), Julia Kempe (@KempeLab), Vivien Cabannes, and myself from @AIatMeta, @NYUDataScience , and Ecole des Ponts. This is an ongoing effort; more details in the thread below.
(1/9)

13
44
366
49,762
Julia Kempe retweeted

May 25
Math is starting to fall — so what's next? 🎙️
New episode of The Information Bottleneck is out!
We've all seen the recent wave of Erdős problems being solved by frontier models, and the question now is what it actually means for the future of mathematics, and for AI research more broadly.
We sit down with @KempeLab - Professor at NYU's Center for Data Science and researcher at Meta FAIR's Foundations of Reasoning team, to dig into exactly that.
Julia makes the case that math is the next Go. With formal verification and LLM agents that can propose, formalize, and check proofs at scale, a new industry of automated mathematical discovery is closer than most mathematicians believe.
We also get into:
→ Why physics is harder than math
→ Model collapse, synthetic data, and what's left to squeeze from the internet
→ Scaling limits, energy costs, and where academia still has the edge
→ How to advise PhD students when Claude can already do their first-year work
→ AI safety, agent security, and the Wild West of deployed agents
→ Why the Renaissance researcher is finally back
One of our favorite conversations yet.
Listen now 👇

7
4
33
3,304
Julia Kempe retweeted

The 2nd Sci4DL (@scifordl) workshop at #ICLR2026 in Rio drew a packed room.
Organized by CDS PhD alumni @ZKadkhodaie & @LotfiSanae, CDS Instructor @FlorentinGuth, and CDS-associated Prof. Eero Simoncelli, with CDS Silver Prof. @KempeLab as a speaker.
scienceofdlworkshop.github.i…




6
6
1,422
Julia Kempe retweeted
CDS Silver Prof @KempeLab working with @arnal_charles, @TacoCohen, Vivien Cabannes, and Remi Munos studied how LLMs can train more efficiently by reusing past experience instead of constantly generating new data.
Accepted to the ICML '26 conference.
arxiv.org/abs/2604.08706
3
6
1,241
May 16
1/3 My time at Meta FAIR will soon come to a close. I joined nearly two years ago full-time to help advance LLM reasoning.
It has been a remarkable journey working with and leading an exceptionally talented team.
11
4
267
99,483
May 16
2/3 I am deeply grateful for the opportunity to collaborate with so many amazing colleagues at FAIR and MSL @AIatMeta.
I also want to thank FAIR leadership, past and present, especially @ylecun, @jpineau1, @NailaMurray, David Lopez Paz, @rob_fergus for letting us explore.
1
1
24
6,331
May 16
3/3 Scaling of foundation models & large-scale engineering continues, but further progress in machine intelligence will require new ideas & breakthroughs. I believe academia will continue to play a key role, particularly through published and opensource research. Exciting times!
1
1
42
5,269



Apr 26
Tomorrow's Frontiers in Assciative Memory workshop at ICLR26 (room 201C) will be an exciting event!
Apr 25

For me the highlight of this year’s #ICLR2026 is the New Frontiers in Associative Memory workshop.
Memory is an essential part of human cognition, yet it is present only in rudimentary forms in modern AI networks. The workshop will tackle recent advances in artificial memory models and new ideas for the future developments in this space.
Amazing lineup of speakers including: Jay McClelland, Paul Liang, Xueyan Niu, and many others.
📍📅 Auditorium 201 C, Sunday April 26 9am-5pm.
👉 Additional info: nfam2026.amemory.net
Join us tomorrow for the exciting conversations about Associative Memory!
@iclr_conf @KempeLab @RogerioFeris @HildeKuehne @Ben_Hoov @krizna_b @pliang279 @JLMcCelland @p_ram_p @andre_t_martins @du_yilun @dlipshutz @meisamrr

9
1,870
Apr 25
Our work today (Sat) @iclr2026:
ORAL:
- OpenApps 3:39pm 204A/B
POSTERS:
-10:30am: Soft Tokens, Hard Truths, P3-#1020
-10:30am: OpenApps, P3-#308
- 3:15pm: How reinforcement learning after next-token prediction facilitates learning, P3-#806
Come to discuss!
2
9
1,125
Julia Kempe retweeted

Apr 20
Excited to be at #ICLR2026 in Rio this week! Presenting “Soft Tokens, Hard Truths” Saturday 10.30am (Pavilion 3, P3-#1020). Feel free to DM me to chat about self-improvement, reasoning, code gen. I’m also on the job market for industry research positions.
25 Sep 2025

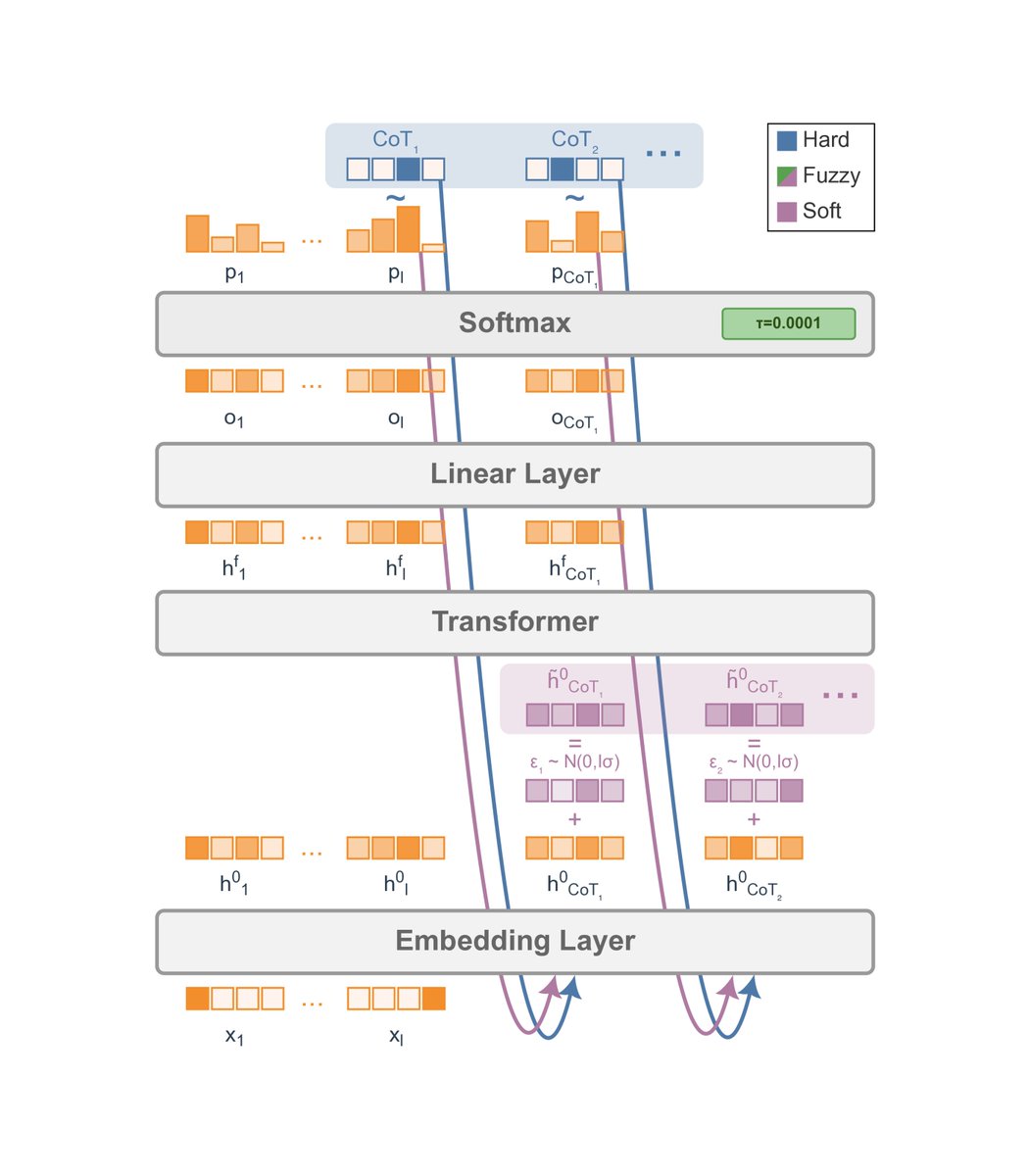
🔥New preprint: Soft Tokens, Hard Truths
Introduces the first scalable continuous-token RL method for LLMs - no reference CoTs needed; scales to hundreds of thought tokens. Best to train soft, infer hard! Pass@1 parity ⚖️, Pass@32 gains 📈& better robustness 🛡️ vs. hard CoT
1/🧵

6
22
3,229
Julia Kempe retweeted

Apr 13
love this replay buffer paper from Meta:
arxiv.org/abs/2604.08706
"methods like PPO or GRPO typically operate as on-policy as possible, meaning rollouts are generated, used for a single gradient update, and immediately discarded."
this is crazy and we shouldn't do this!
12
51
483
56,740
Julia Kempe retweeted

Efficient RL Training for LLMs with Experience Replay
"Empirically, we show that a well-designed replay buffer can drastically reduce inference compute without degrading – and in some cases even improving – final model performance, while preserving policy entropy."

5
53
349
22,125
Julia Kempe retweeted

Apr 14
(1/9) Experience replay can cut LLM RL training compute by up to ~40% (without hurting final accuracy—and sometimes improving it).
Paper: arxiv.org/abs/2604.08706

4
41
200
16,890
Julia Kempe retweeted

Apr 13
Experience replay of LLM RL. Hyperparameters for replay buffers, buffer sizes N, number of new rollouts R, minibatch size B depend on compute imbalance of rollout generation and training, and task-specific statistics. It could be hard to optimize this well.

4
8
77
13,131
Julia Kempe retweeted

@KempeLab and I just vibe-coded a Lean 4 formalization of elliptic De Giorgi–Nash–Moser theory. This is a cornerstone of modern elliptic PDE: local boundedness, weak Harnack, Harnack, and Hölder regularity for weak solutions with merely bounded measurable coefficients.

4
42
149
18,839
Julia Kempe retweeted
AI is becoming incredibly powerful at solving complex math, but it still requires strict human supervision.
CDS Silver Prof Julia Kempe (@KempeLab) tested top models on unpublished math questions, exploring their capabilities and limits in a new paper.
nyudatascience.medium.com/te…
1
6
16
1,916
Julia Kempe retweeted
MIT PhD student Shobhita Sundaram (@shobsund) & CDS Silver Professor Julia Kempe (@KempeLab), and a team from FAIR show how AI can generate its own practice problems to solve nearly impossible tasks.
nyudatascience.medium.com/ge…
2
1,530
Mar 3
Our groups' ICLR presentations:
🎉Oral: OpenApps arxiv.org/abs/2511.20766
Soft Tokens, Hard Truths arxiv.org/abs/2509.19170
How reinforcement learning after next-token prediction facilitates learning arxiv.org/abs/2510.11495
From Concepts to Components arxiv.org/abs/2506.17052
1
3
46
2,981