
Joined August 2013
- Tweets 34
- Following 124
- Followers 112
- Likes 491
2 Photos and videos


»Attribute or Abstain: Large Language Models as Long Document Assistants«
by @koby_loby, @XiaoL558286, @IGurevych
📰 arxiv.org/abs/2407.07799
💻github.com/UKPLab/arxiv2024-…
(4/🧵) #EMNLP2024

1
2
8
649
📢 10 papers authored or co-authored by UKP members have been accepted for publication at #EMNLP2024 in Miami! 🇺🇸
And 2 papers from CL and TACL will be presented at the conference 🎉
Congratulations to everyone involved! 💐 – be sure to check them out in this thread (1/🧵):

2
5
59
3,930
Jan Buchmann retweeted

24 Jul 2024
Please drop by our poster tomorrow and talk to my co-authors about how IVON can directly optimize a variational objective with similar performance and cost as Adam but many things on top (uncertainty, model adaptation, diagnosis, ...)
Thu. 13:30-15:00, hall c 4-9, poster #1402

🤔 Variational learning is often thought to be impractical
🔥 Plot twist: it actually works better than Adam!
Meet IVON, a new optimizer that brings the best out of variational learning – 🧵 (1/9) #NLProc #ICML2024
📰 arxiv.org/abs/2402.17641
youtu.be/TRNYnRRJBRg
6
7
22
1,896

12 Dec 2023
In case you are looking for it: @eaclmeeting commitment link is here:
openreview.net/group?id=eacl…
1
168
Pointwise V-usable information (PVI) excels in many #NLProc tasks. But fine-tuning #LLMs with it is very time-consuming 🐌 Is in-context PVI the necessary next step?
Yes! 🎉Check out our empirical analysis accepted at #EMNLP2023 – and this 🧵 (1/7)
📄 arxiv.org/abs/2310.12300

1
10
17
1,815
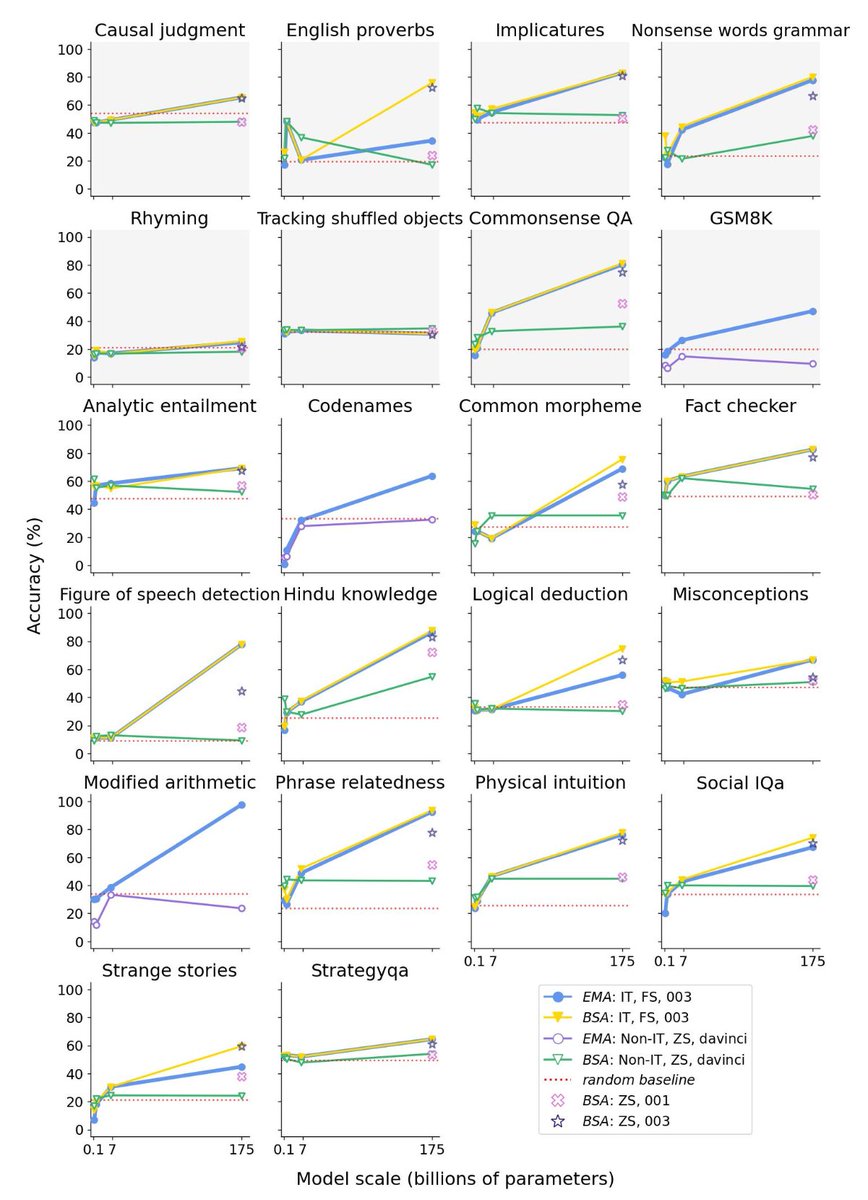
Are Emergent Abilities in Large Language Models just In-Context Learning?
Spoiler: YES 🤯
Through a series of over 1,000 experiments, we provide compelling evidence: arxiv.org/abs/2309.01809
Our results allay safety concerns regarding latent hazardous abilities.
A🧵👇 #NLProc
15
181
695
388,630
26 Jan 2023
Hey @signalapp, why do you keep insisting that I turn on notifications? Being donation funded and tracking-less (which I support very much), signal shouldn’t need to get me hooked, right?
186
Jan Buchmann retweeted

21 Jul 2022
Some ppl have asked why we’d expect larger language models to do worse on tasks (inverse scaling). We train LMs to imitate internet text, an objective that is often misaligned w human preferences; if the data has issues, LMs will mimic those issues (esp larger ones). Examples: 🧵
4
39
228
Jan Buchmann retweeted

15 May 2022
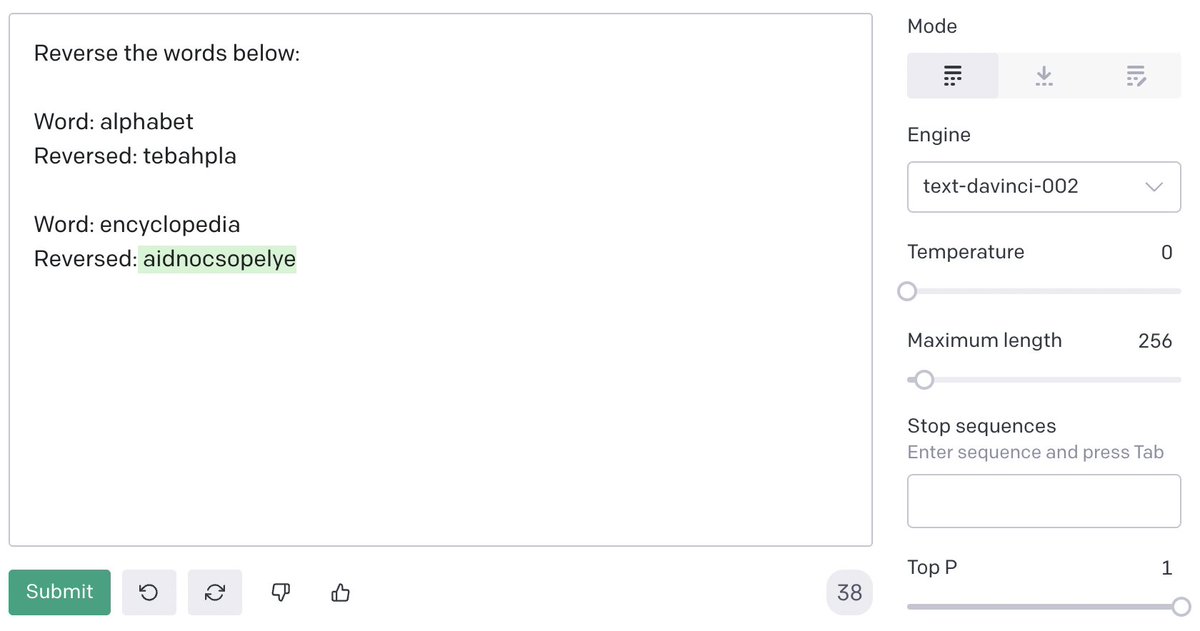
GPT-3 is amazing at complex tasks like creative writing and summarizing. But it's surprisingly bad at reversing words. 🤔
The reason is that GPT-3 doesn't see the world the way we humans do. 👀
If you teach it to reason, it can get around its limitations to get really good. 💡
30
263
1,349
8 Oct 2021
2
Jan Buchmann retweeted

25 Jun 2021
Volksentscheid, WIR KOMMEN! 💛💜 Mit sagenhaften 343.591 Unterschriften🎉
🎈Aufgrund der Anzahl an Unterschriften (schon die vorläufige Zahl ist ein Rekord für Volksbegehren in Berlin) gehen wir davon aus, dass es zum Volksentscheid am 26.09. kommt! 💪

78
594
2,852
2 Jun 2021
Really interesting, well-researched (and long) article on the origin of SARS-CoV2 and the dangers of gain-of-function research on viruses. Bottomline: The lab escape theory seems to be more plausible than reported by some. thebulletin.org/2021/05/the-…
1
Jan Buchmann retweeted

25 May 2021
I'm back from a week at my mom's house and now I'm getting ads for her toothpaste brand, the brand I've been putting in my mouth for a week. We never talked about this brand or googled it or anything like that.
As a privacy tech worker, let me explain why this is happening. 🧵
2,007
81,545
244,309
Jan Buchmann retweeted

11 Feb 2021
"An international effort to produce & distribute mRNA-based Covid-19 vaccines worldwide"
English version of a petition first proposed by @axelkahn to coordinate an emergency effort to produce and distribute mRNA-based Covid vaccines to the entire world.
change.org/p/president-joe-b…
1
11
35
28 Oct 2020
So ein Blick in die mögliche Zukunft ist doch ein bisschen gruselig... taz.de/Ausbreitung-der-Coron… via @tazgezwitscher
Jan Buchmann retweeted

13 Oct 2020
Die Lage der Geflüchteten auf Lesbos bleibt so dramatisch wie nach dem Brand von vor einem Monat. Statt Feuer ist es nun der Regen, der die ohnehin prekäre Situation der Menschen nochmal verschlimmert. Die Europäischen Staaten dürfen diese katastrophalen Zustände nicht hinnehmen!
13 Oct 2020

Erster Herbststurm im neuen #Moria. Schaut dieses Video, leitet es weiter. Eigentlich braucht es keine weiteren Kommentare. Es ist so unwürdig. Und viel zu wenige kriegen es mit. #leavenoonebehind
87
69
164
13 Sep 2020
Das Auto ist immer noch viel zu dominant in Deutschlands Städten: taz.de/Verbot-der-Pop-up-Rad…
1
Jan Buchmann retweeted

20 Aug 2020
Heute wurden Menschen in #Moria von einem rechten Mob mit Steinen beworfen.
Jetzt hat der Mob ein Feuer gelegt, weil er offenbar die 14.000 Geflüchteten im Camp verbrennen will. Völliger Wahnsinn schon wieder und kaum jemand kriegts mit. #LeaveNoOneBehind
230
2,274
3,699
Jan Buchmann retweeted

29 Jul 2020
212 ermordete Umweltaktivist*innen: Einer der viele Gründe, gegen Kohleverstromung und Kapitalismus zu kämpfen!
Trotz 64 Morden in Kolumbien bezieht Deutschland weiter 1/3 der Steinkohle aus dem Land. Sofortiger Importstopp & Kohleausstieg bis 2030!
tagesschau.de/ausland/naturs…
6
11
51