
52 Photos and videos


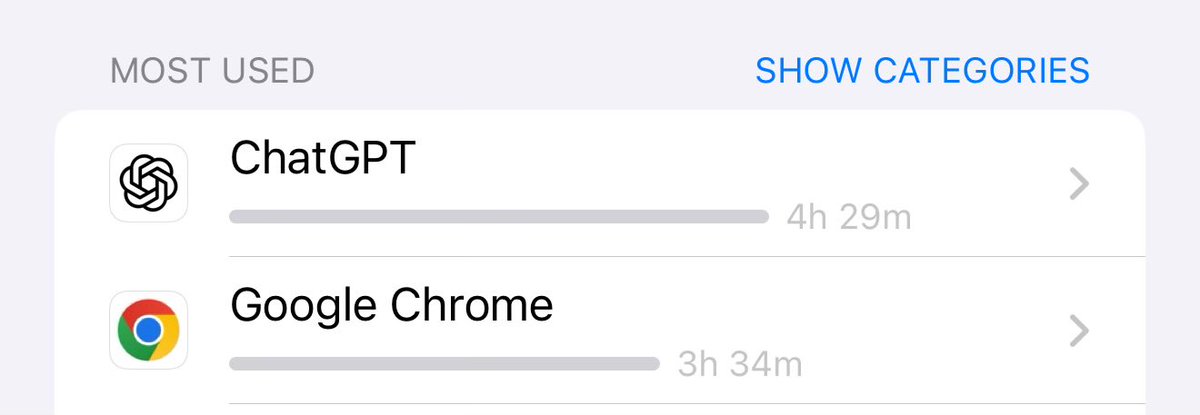







Peter Welinder retweeted

Jun 12
wow sick new billboards from openai




84
219
4,580
2,612,386

Jun 13
GPT-5.5 vs Fable: ~same performance, but GPT-5.5 costs 50% less and so can do twice as much work.

We've updated the Artificial Analysis Coding Agent Index, replacing SWE-Bench Pro with Datacurve's DeepSWE benchmark - the swap lifts Codex with GPT-5.5 (xhigh) above Claude Code with Opus 4.8 (max), while the newly released Claude Fable 5 (max) in Claude Code debuts at the top
DeepSWE, built by @datacurve, writes its tasks from scratch rather than adapting them from public GitHub issues or pull requests, so no model has seen the solutions during training. That matters because SWE-Bench Pro, the benchmark it replaces in our Coding Agent Index, had grown gameable, with some models recovering the fix from the repository's commit history instead of solving the task.
The swap reorders the index: Codex with GPT-5.5 (xhigh) rises from 65 to 76, overtaking Claude Code with Opus 4.8 (max) at 73. Claude Code with Fable 5 (max), which enters directly on the refreshed index, leads at 77. SWE-Bench Pro had been flattering some combinations and penalizing others.
More below.

15
6
99
18,578
Peter Welinder retweeted

Jun 12
IMO sth that is a bit overlooked but will become far more important in the future. GPT is 10-20x more token cost effective for ~similar outcome.
Jun 12

Day 3 with Fable.
Gave a huge prompt to implement a feature across CLI, web server, and another server to both Fable and deep^2 in Amp.
deep^2 was done before I went to the gym. It stopped short. Sent another prompt. $20.
Fable ran for 1hr40min and cost $350.
Results:
They both understood the assignment and built the same thing. Maybe that's due to my prompt.
Fable's worked on first try. Well done.
Deep's looks correct but didn't work on first try.
$20 vs. $350.
I'm sure I could get deep^2 to make it work and we'd end up at, what, $40? While Fable is now at $457 after I asked some follow-up questions.
127
50
1,375
269,114
Jun 12
Models are getting very good at math. Even better than was previously thought.
Jun 12

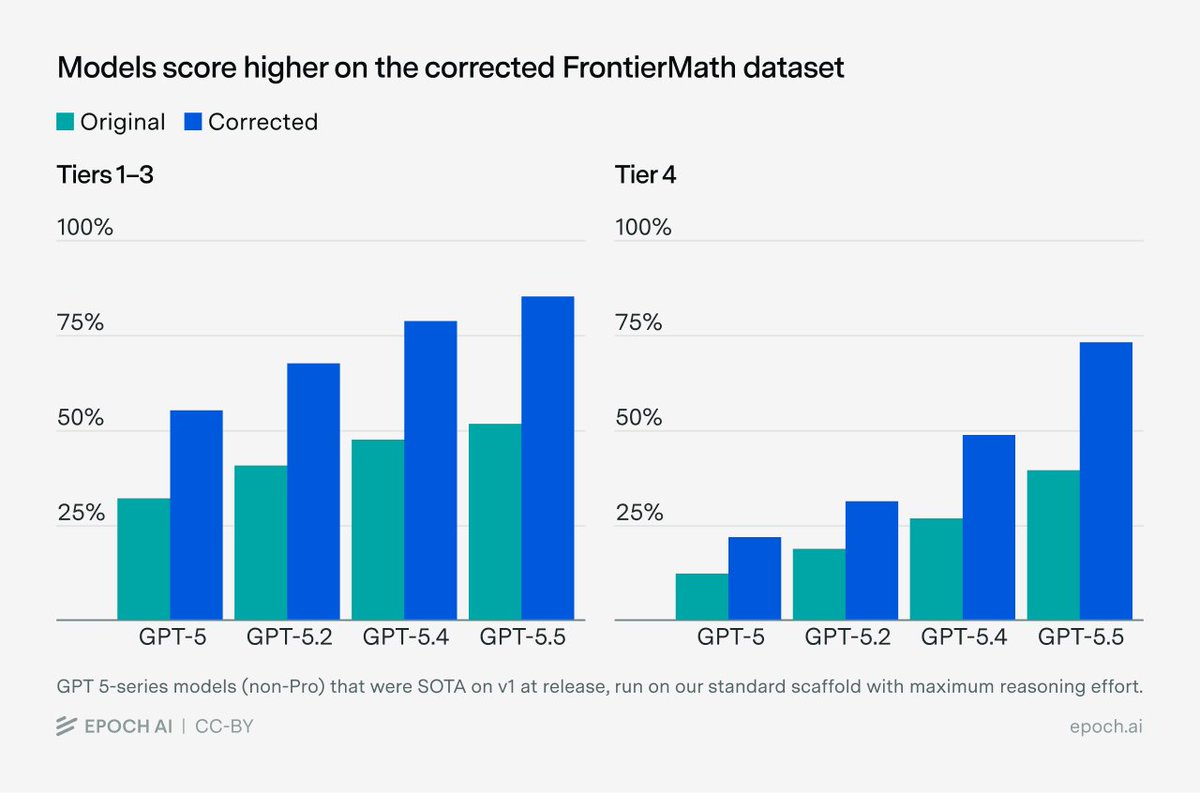
FrontierMath: Tiers 1–4 (v2) is live.
We concluded an audit that addressed errors in 42% of problems. Rankings are similar but scores are higher across the board. The current leaders are GPT-5.5 (xhigh) with 85% on Tiers 1–3 and Google’s AI co-mathematician with 76% on Tier 4.
3
3
47
5,496
Jun 12
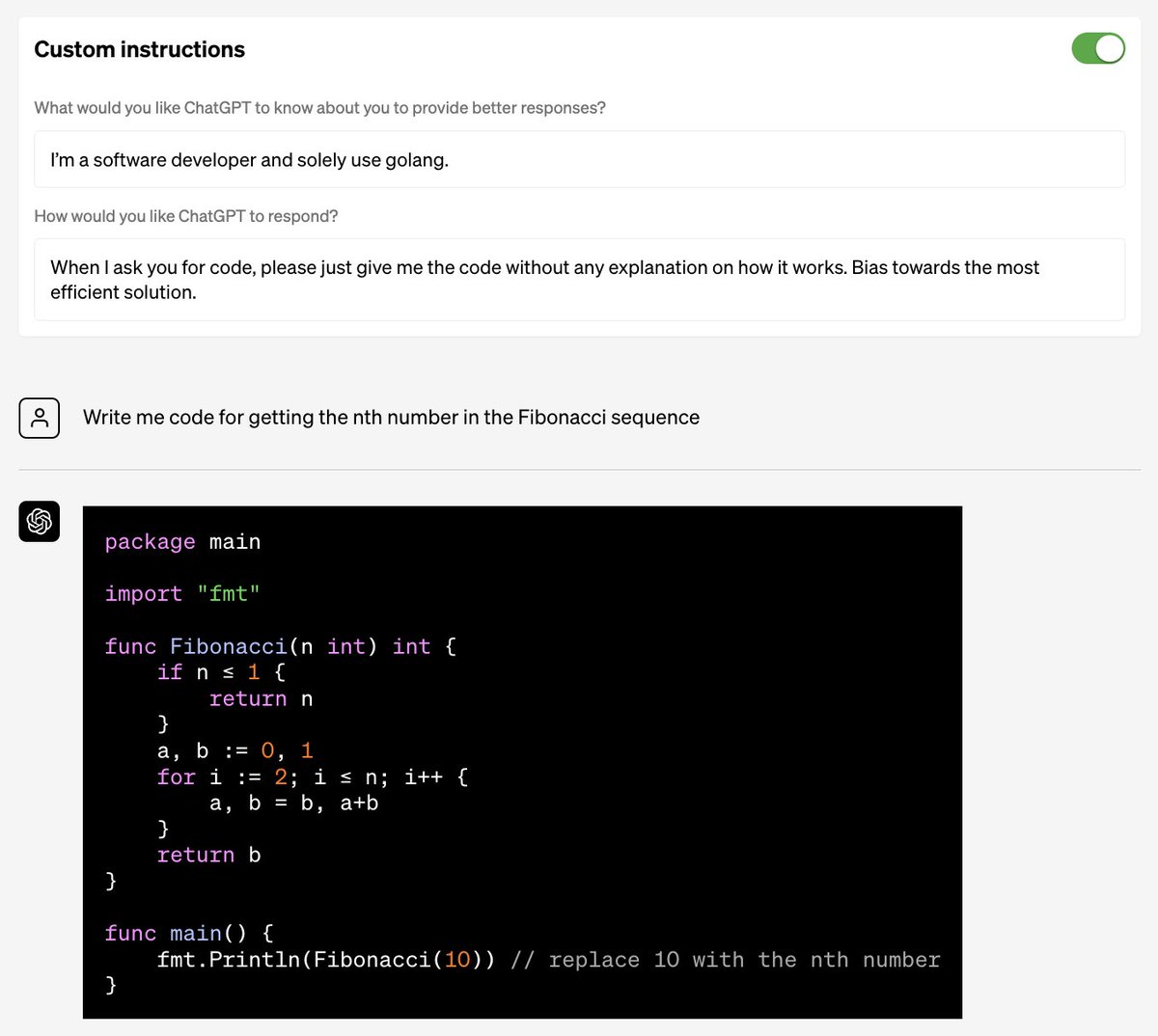
Build your own health tracker with Codex.
Jun 12

My DEXA scan yesterday showed my body recomp progress isn’t moving fast enough.
So I went founder mode and built myself the ultimate health tracking app with Codex:
- Tracks macros via photo or voice command
- Shows how I’m pacing against daily goals
- Syncs @Ouraring, @Peloton, @Tonal, and @Withings data to give me the full picture
Built in one day. Let’s go.
3
1
14
5,817
Jun 12
Two takeaways for me: (1) GPT-5.5 is beast, and (2) lots of work left.
Jun 11

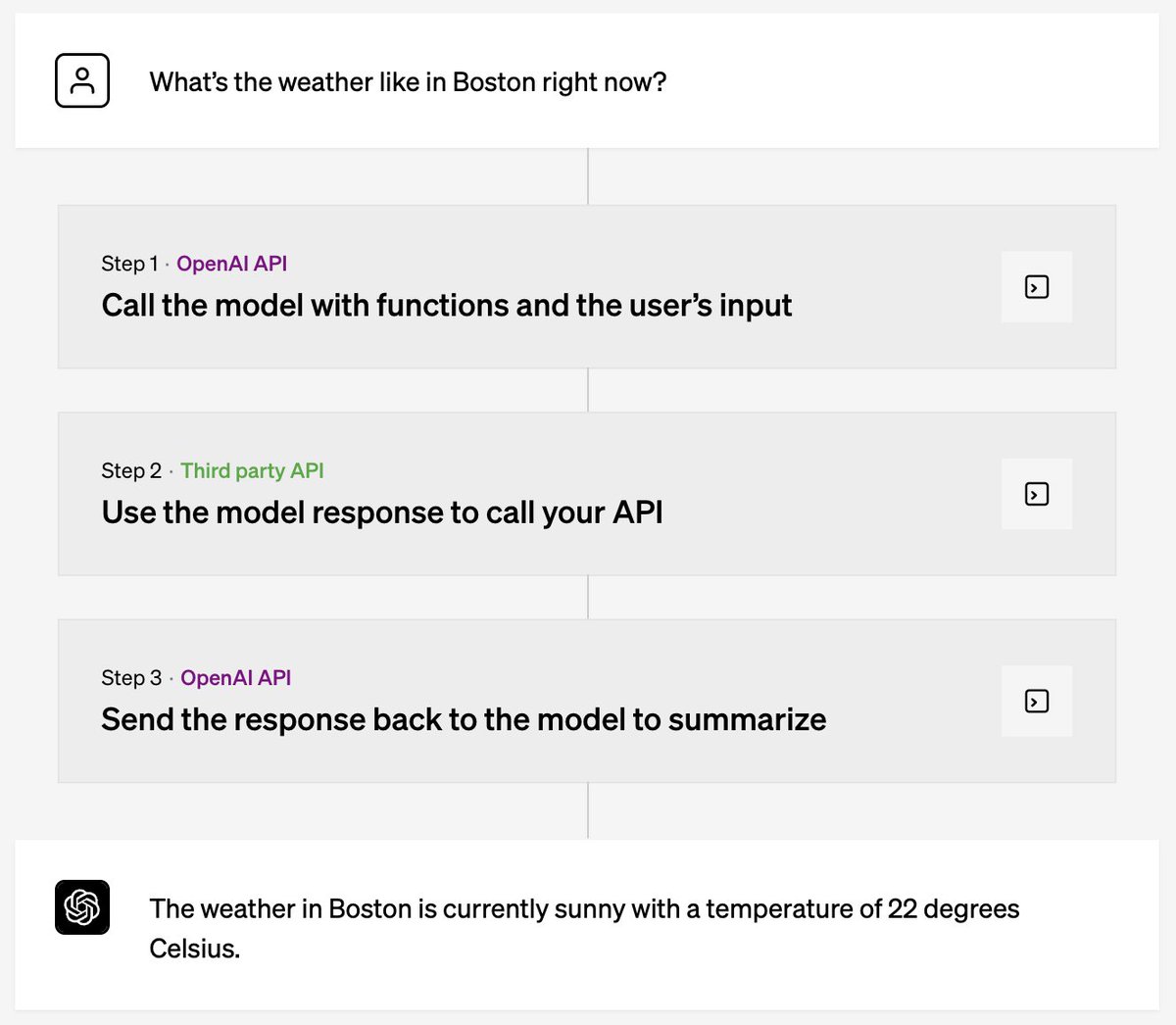
Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
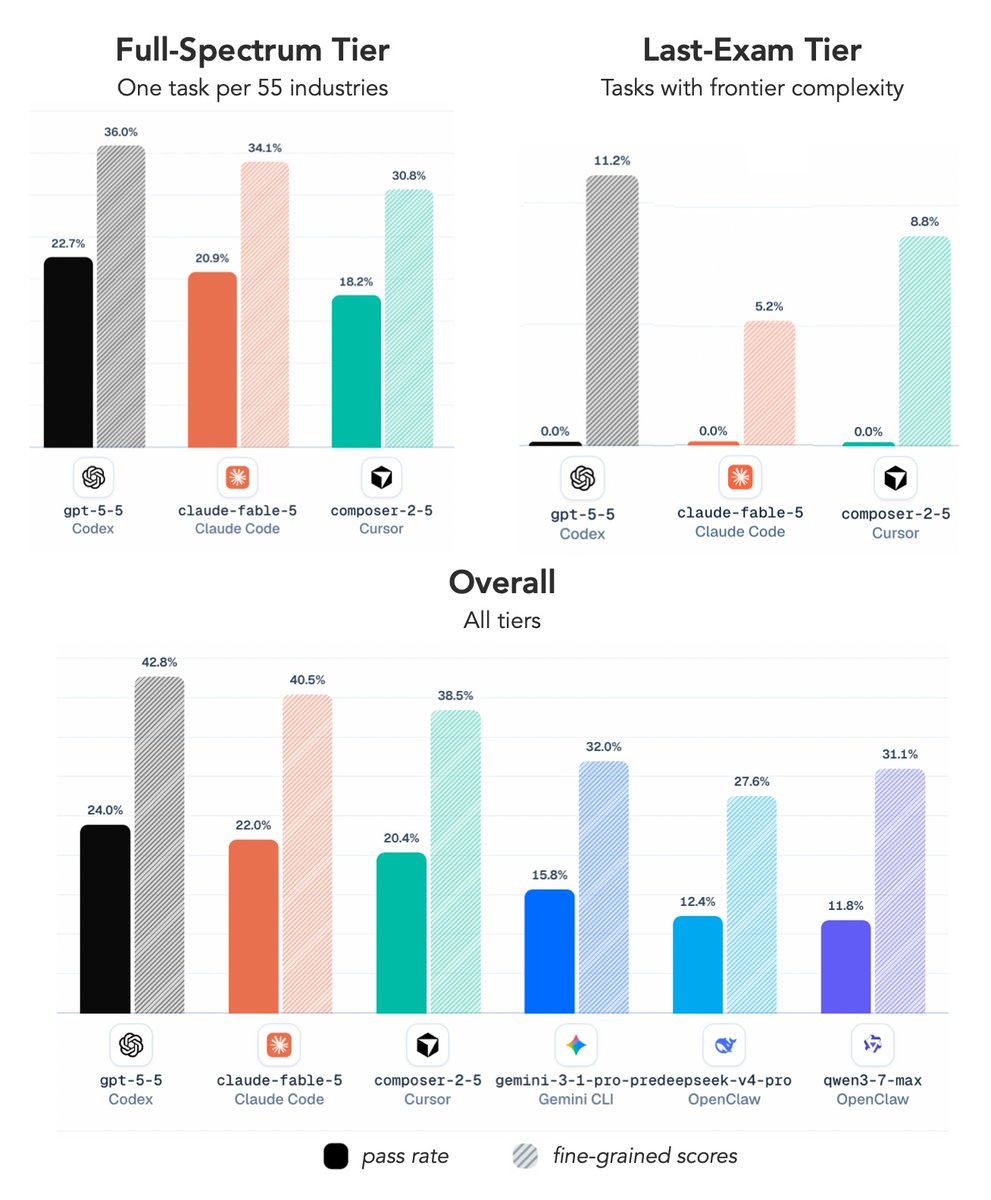
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
4
20
3,151
Peter Welinder retweeted

Jun 9
If you really think about it, despite being mocked as “ClosedAI,” OpenAI has contributed enormously to the field: GPT, GPT-2, GPT-3, CLIP, the ChatGPT paper, the GPT-4 Technical Report, the Sora technical blog, and even open-sourced Codex.
Anthropic, meanwhile, has contributed far less to the public research ecosystem while increasingly promoting fear-based narratives and restricting access through heavy gatekeeping.
The world I least want to live in is one where the future of AI is controlled by companies that prioritize secrecy, gated access, and centralized control over openness, reproducibility, and scientific progress.
121
367
4,420
203,417

May 26
Using Codex Computer Use to navigate the Settings app is incredible. It knows MacOS so much better than me. Similar experience to it using the command line. Superhuman.
12
4
108
8,527
Peter Welinder retweeted

May 21
Today we’re releasing Appshots in Codex.
I love this feature! It makes it so easy to integrate Codex into everything I do on my Mac.
65
60
1,081
164,753

California after the Coastal Commission is gone


32
162
4,186
125,869
Peter Welinder retweeted

May 16
using codex from the ChatGPT app is such a freeing experience. makes you realize how tethered you normally are to your computer.
241
71
2,095
136,804
Peter Welinder retweeted

May 16
The new Codex integration into the iOS ChatGPT app is *finally* making my iPad a useful productivity tool.
7
6
160
9,273
May 16
Care more about the unquantifiable things.
May 16

Shopify CEO Tobi Lutke explains Goodhart’s law and why he doesn’t like KPIs or OKRs
“Goodhart’s law is real. The moment a metric becomes a goal, it’s no longer a useful metric… No metric by itself is a complete heuristic for a complex business. There’s a million different tensions in a company, and you can’t keep all of them in harmony by optimizing for one thing.”
For this reason, Shopify doesn’t use KPIs or OKRs. But as Tobi explains, this doesn’t mean they don’t value data and metrics.
“We are extremely data informed. We have invested enormous amounts of money and time into systems that give us basically everything at our fingertips… But what Shopify attempts to do is just not over-fit for what’s quantifiable.”
People love optimizing for highly-quantifiable things because there’s immediate gratification that comes from seeing a number go up. But Tobi thinks that the most important aspects of a product are rarely quantifiable:
“The overlap of the most valuable things you can do with a product and the things that happen to be fully quantifiable are like maybe 20%. Which leaves 80% of a value space unaddressable by the people who only look at quantifiable things.”
He continues:
“Shopify is comfortable with unquantifiable things like taste, quality, passion, love, hate… The sort of deep satisfaction that a craftsperson feels when they’ve done a job well is actually a better proxy if you allow it to be.”
They then have robust analytics systems that tell the company if something’s wrong or a new rollout breaks something.
“We think about it as a cockpit for a pilot. The decisions are still made by pilots, and we think this leads to better results… I think there needs to be more acceptance in business of unquantifiable things… And then metrics take a support function.”
Source: @lennysan (Feb 2025)
2
3
37
11,848


May 16
Same.
May 15

Codex mobile app can now manage all my devices through tailscale. Incredible. OpenAI won.
GG

2
1
28
3,595
Peter Welinder retweeted

May 16
Thanks for the feedback on Codex in the ChatGPT mobile app. While it’s in preview, we’re working to improve it fast.
What you can expect next: push notifications, /fork, ability to restore after revoking, better reconnects, fixing the ability to control other devices, fewer mobile thread errors, better git diff & full-file, no plan mode issues, and lots more polish/bug fixes.
183
48
1,328
167,393
May 15
Codex on iPad is so awesome. Managing sessions on both my Mac Mini and VPS. Coding on the iPad is finally here.
10
137
6,787
May 15
Big unlock. This is how I've been using Codex for the past few weeks. Excited it's out for everyone.

You've been asking for this one...
Now in preview: Codex in the ChatGPT mobile app.
Start new work, review outputs, steer execution, and approve next steps, all from the ChatGPT mobile app. Codex will keep running on your laptop, Mac mini, or devbox.
6
1
29
2,400