
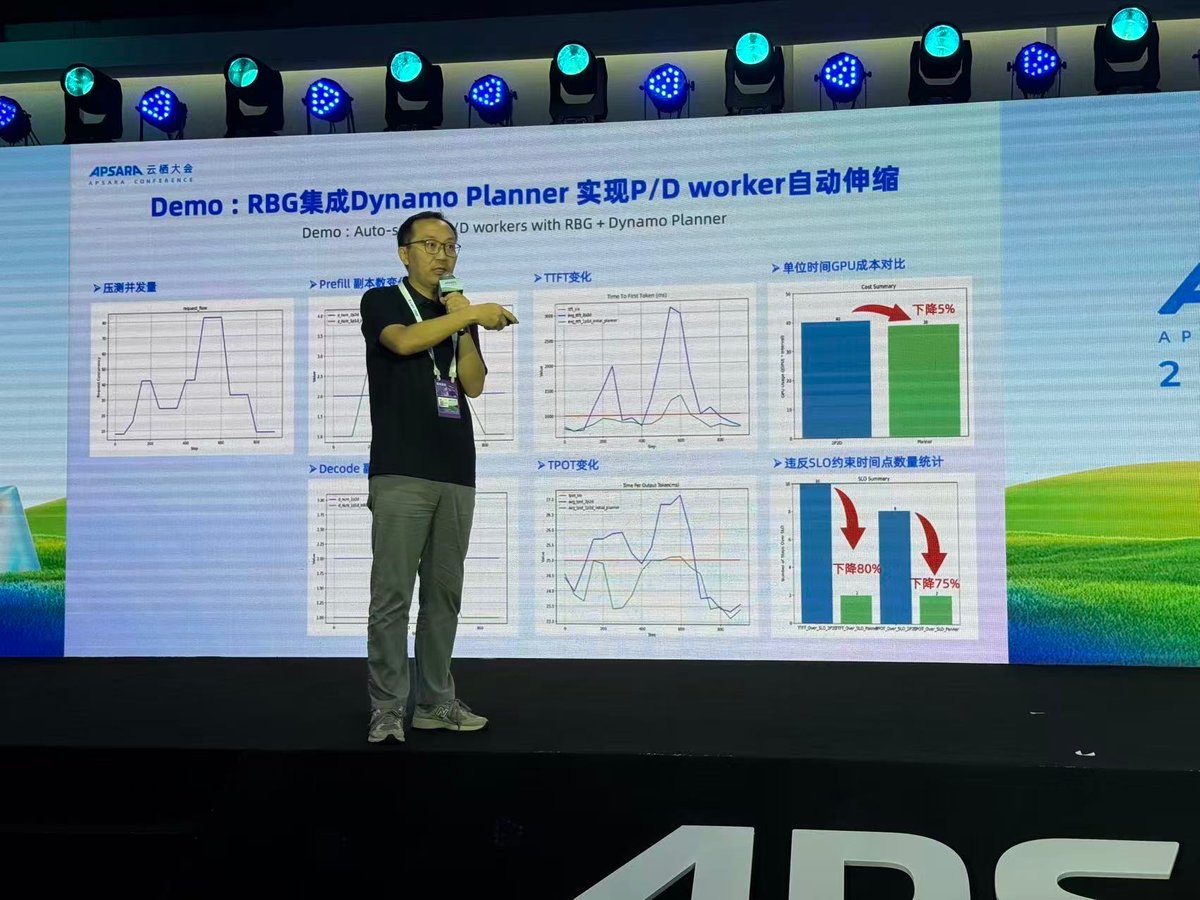
Engineering Leader for Planetary Scale Inference with NVIDIA Dynamo
Joined March 2021
- Tweets 196
- Following 93
- Followers 568
- Likes 386
6 Photos and videos





Kyle Kranen retweeted

Jun 4
🎉It's finally here!
You can also deploy the model disaggregated with Dynamo too - check it out! github.com/ai-dynamo/dynamo/…
Jun 4

🚀 Day-0 support for NVIDIA Nemotron 3 Ultra on vLLM!
Ready to be served with the latest vLLM stable release, the new open frontier reasoning model is built for long-running autonomous agents:
🧠 550B total / 55B active — Hybrid Transformer-Mamba MoE
📚 Up to 1M token context
⚡ NVFP4 BF16
🛠️ Tool calling, coding, deep research, orchestration
Read our detailed model launch blog and recipes! recipes.vllm.ai/nvidia/NVIDI…
1
10
1,157

Jun 3
If one had 4 inoperative V100 SXM2 GPUs, what would one do with them?
Asking for a friend…
1
3
754
Kyle Kranen retweeted

Jun 1
Excited to share that ThunderAgent has been integrated into NVIDIA Dynamo as an experimental router for agentic workloads!
ThunderAgent was designed to schedule at the granularity of agent runs, making agentic serving/rl upto 4x faster!
Huge thanks to @0xishand , @KranenKyle , and the Dynamo team. They have been exceptionally efficient and proactive — the team had already started pushing this forward even before I officially joined @nvidia .
Looking forward to seeing ThunderAgent ideas further evolve within Dynamo. And thanks for the help from @togethercompute
Link: github.com/ai-dynamo/dynamo/…
@simran_s_arora @Chenfeng_X @_weilix @yinfang_chen
#AI #MLsys #Agent #Nvidia

14
8
86
15,723
May 31
Alt use: use this to prototype new algorithms for scheduling in Dynamo and tag us!
We’ve used this successfully to design some improvements with auto research and are just starting to push into how far this can go!

If folks are trying to break into inference -> see if you can figure out where we differ from engines and fix it. Send me PR showing our perf before and after compared to the engine
1
1
19
2,242

May 30
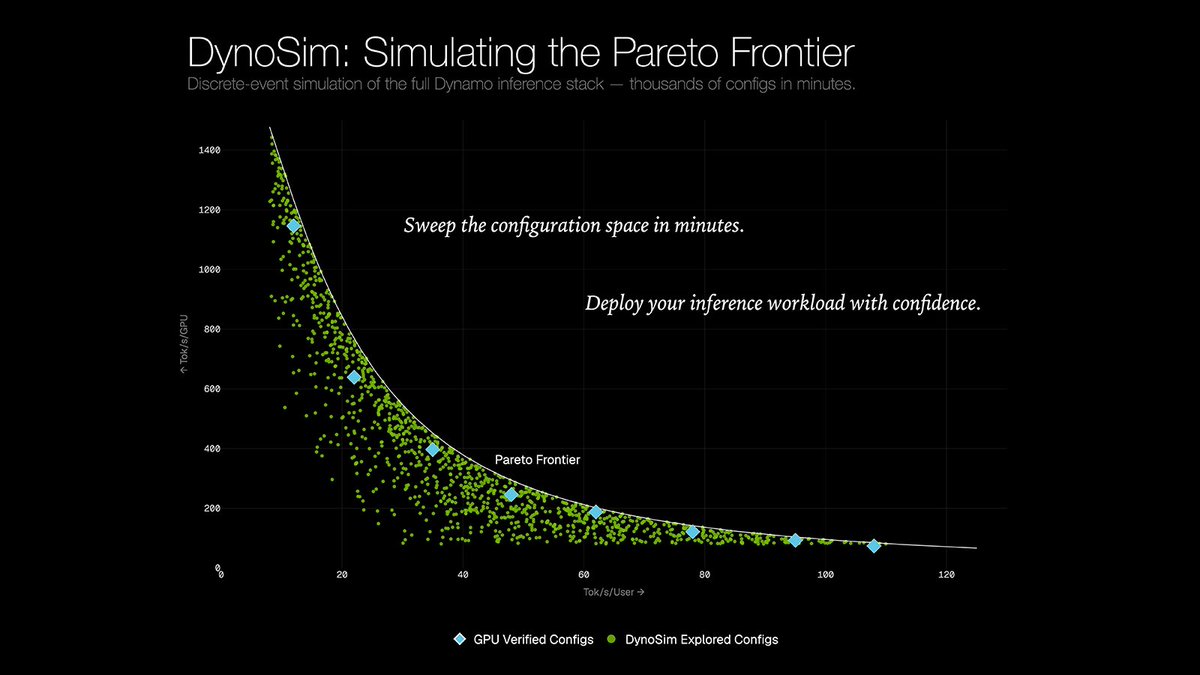
About a month ago I posted about ongoing work on datacenter scale inference simulation. People seemed to like it so we wrote more about it!
Check out this awesome blog post from the Dynamo team!

There's a better way to serve your inference stack, you just haven't found it yet.
DynoSim is a workload-driven simulation of the Dynamo serving stack that turns exhaustive deployment search into a simulate-then-verify loop.
Instead of testing every deployment choice, teams can model the whole stack on one virtual timeline, screen thousands of configurations in high fidelity simulation, then validate only the best candidates on real hardware.
And because it's a full Rust implementation, it runs extremely fast. In our testing, 1,500x faster than real time.
3
3
23
2,213

There's a better way to serve your inference stack, you just haven't found it yet.
DynoSim is a workload-driven simulation of the Dynamo serving stack that turns exhaustive deployment search into a simulate-then-verify loop.
Instead of testing every deployment choice, teams can model the whole stack on one virtual timeline, screen thousands of configurations in high fidelity simulation, then validate only the best candidates on real hardware.
And because it's a full Rust implementation, it runs extremely fast. In our testing, 1,500x faster than real time.
20
43
371
57,494
May 30
If you legitimately have hit RSI, is it better to minimize latency or maximize throughput for your inference?
My mental model leans towards maximizing throughput, as A) parallel search is a thing and B) real world interactions tend to cause an Amdahl’s Law problem.
4
15
2,185
Kyle Kranen retweeted

May 28
"/goal rewrite jax in rust"


SpaceX has almost finished writing V1.0 of an in-house AI training stack in C that exact-maps to 220k GB300s with 800G NICs, making heavy use of pipeline parallelism and getting as close to bare metal as possible.
The potential speed improvement vs JAX for large training runs is over an order of magnitude.
10
14
518
29,172

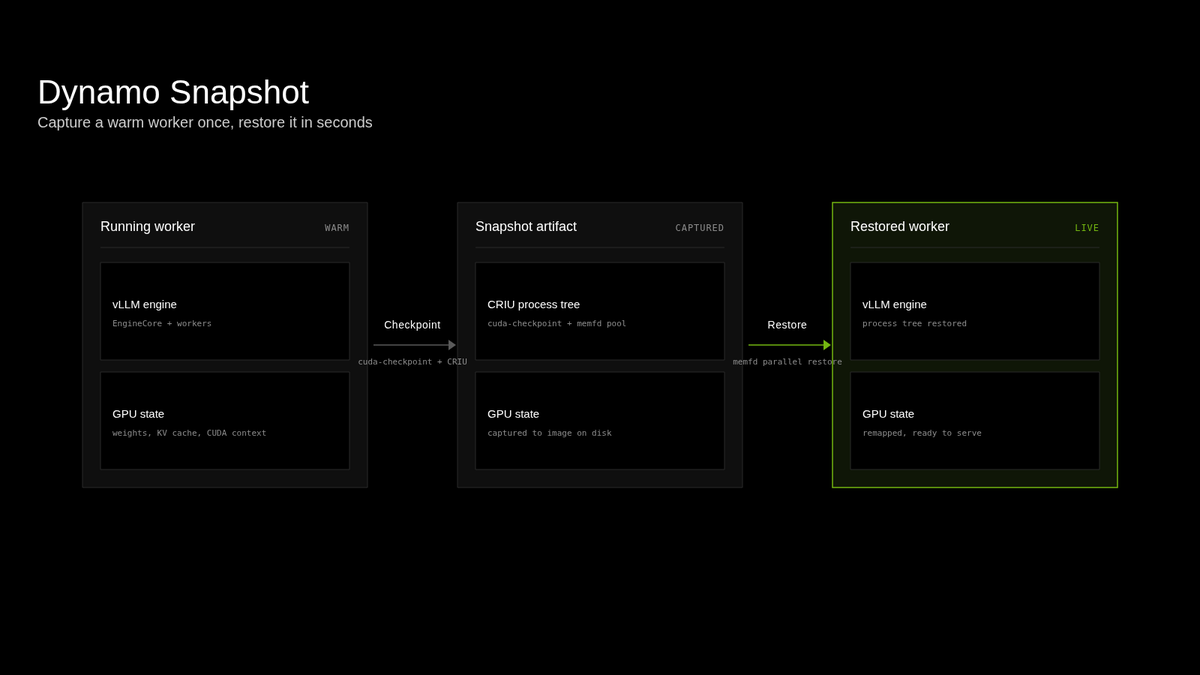
Super excited to share one of the projects I’ve been leading over the past few months.
We can now get a single-GPU gpt-oss-120b vLLM instance up in under 5 seconds after container start.
Next stop: multi-GPU checkpoint/restore!
Introducing Dynamo Snapshot, our approach for fast startup for inference workloads on Kubernetes, which reduces startup time from minutes to under 5 seconds.
In production inference deployments demand fluctuates over time. Cold-starting inference workloads can take minutes, leaving idle GPUs that generate no tokens and serve no requests.
Snapshot leverages GMS to enable concurrent weight restoration over a high-speed interconnect, while using Linux native AIO and parallel memfd restoration to accelerate CRIU restore performance.
2
4
27
3,792
May 28
Cold starts are super painful for scaling LLM workers.
Check out our work at restoring inference workers (including AOT traces) in seconds, not 10s of minutes!
Introducing Dynamo Snapshot, our approach for fast startup for inference workloads on Kubernetes, which reduces startup time from minutes to under 5 seconds.
In production inference deployments demand fluctuates over time. Cold-starting inference workloads can take minutes, leaving idle GPUs that generate no tokens and serve no requests.
Snapshot leverages GMS to enable concurrent weight restoration over a high-speed interconnect, while using Linux native AIO and parallel memfd restoration to accelerate CRIU restore performance.
1
4
54
6,336
@kylekuzma curious to get your thoughts on disaggregated serving and kv cache offloading to CPU/SSD?
4
2
16
1,051
May 25
A good memory from the LLama 3 days is that one of the best drafters for 405B was the 1B model because they were trained on the same distribution of data :)
May 24

In speculative decoding the drafter just needs to be as fast as possible and its predictions be matching the verifier's
I heard of drafters that are 2-layers 4B models, can anyone confirm?
3
1
62
8,924
May 24
Ever wished you could adapt your EP size on the fly for fault tolerance of scaling purposes?
Now you can with NIXL-EP!
Check it out:
1
1
30
2,963
May 24
I’m really excited by the amount of non bipedal/quadruped home robotics projects these days
The humanoid/animal form factors are well-studied, but leave so much on the table!
Give me a refrigerator sized food replicator or self-loading dishwasher!
9
1,035
May 19
No matter the amount of full attention sparsity, decreased attention dim, MLA/GQA, infinite long context will always have to deal with quadratic prefill cost.
Kind of begs the question on if we can successfully train a model with local prefill and global decode?
8
31
3,782
May 17
High fidelity performance simulation allows you to do some really cool stuff, especially auto research!
Sim is a first-class citizen in Dynamo! On a MacBook, you can run simulations of 1000 GPUs l against real a trace in virtual time 1000x faster than real
Check it out:
2
2
22
2,724