
Building agentic and tiled stuff @togethercompute @UofIllinois | prev @ZJU_China
Joined November 2023
- Tweets 34
- Following 924
- Followers 43
- Likes 86
2 Photos and videos


Weili Xu retweeted

Jun 9
A message to Anthropic leadership: You're not special. Making sure AI goes well is a team effort not a "you effort."
45
149
2,339
101,261
Weili Xu retweeted
Jun 9
Labs starting to pull up the ladders on the ability to diffuse AI was inevitable. Doing it without telling the user is misaligned.
When Fable 5 is used for frontier LLM development, it does not notify the user and instead limits the model’s capabilities through methods such as prompt modification, steering vectors, and PEFT.
Anthropic estimated that this would affect approximately 0.03% of traffic.

58
187
1,893
288,066
Weili Xu retweeted

Jun 9
Very sad news for the LLM research and open-source community. Does this mean PhD researchers in frontier LLMs, or contributors to open-source LLM infrastructure like Megatron, FSDP, Verl, SGLang, and vLLM, may be using a degraded Claude model in their daily work without being notified?


Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
35
36
603
59,819

As part of Dynamo 2.0, the program abstraction proposed in ThunderAgent is being standardized as part of the nvext.agent_context protocol in dynamo.
Inference scheduling/KV cache management with agent lifecycle awareness isn't future anymore, it’s the trend happening right now!
Jun 1

Excited to share that ThunderAgent has been integrated into NVIDIA Dynamo as an experimental router for agentic workloads!
ThunderAgent was designed to schedule at the granularity of agent runs, making agentic serving/rl upto 4x faster!
Huge thanks to @0xishand , @KranenKyle , and the Dynamo team. They have been exceptionally efficient and proactive — the team had already started pushing this forward even before I officially joined @nvidia .
Looking forward to seeing ThunderAgent ideas further evolve within Dynamo. And thanks for the help from @togethercompute
Link: github.com/ai-dynamo/dynamo/…
@simran_s_arora @Chenfeng_X @_weilix @yinfang_chen
#AI #MLsys #Agent #Nvidia

1
1
7
675
fun part in the post: #OpenSourceAl😅
May 1

📢 Official Announcement: Qwen Partners with Fireworks AI to Accelerate Access to Qwen Family Models
We are pleased to announce a strategic partnership between Qwen and Fireworks AI to deliver optimized, production-ready deployment of Qwen's closed weights models via the Fireworks Platform. @FireworksAI_HQ
This collaboration empowers developers and enterprises to:
✅ Deploy Qwen models with lower latency and reduced fine tuning and inference costs
✅ Leverage enterprise-grade reliability, security, and scalability
✅ Integrate seamlessly into modern AI workflows
🔹 Get started with Qwen on Fireworks: app.fireworks.ai/models/fire…
#Qwen #FireworksAI #OpenSourceAI #LLM #AIInfrastructure #ResponsibleAI #DeveloperCommunity
115
Weili Xu retweeted

Apr 30
Big Update🤩: #paperclip now includes full papers from all of arXiv, PubMed Central and 150 million abstracts!🖇️
You can give your LLM all that knowledge in one line—all optimally indexed for AI agents. Much more thorough and ~100x faster than web search, and free.

43
245
1,749
185,918
Weili Xu retweeted

Apr 22
Introducing Kimi K2.6 from @Kimi_Moonshot, a multimodal agentic model with Agent Swarm scaling to 300 sub-agents and long-horizon coding stability. AI natives can now use Kimi K2.6 on Together AI and benefit from reliable inference for production-scale autonomous agent workflows.

3
3
15
8,981
Weili Xu retweeted

Mar 5
NICE Talk 141🌟invites Ph.D. at Georgia Tech Hao Kang @GT_HaoKang to discuss ThunderAgent: 4× Faster LLM Agent Inference!
Time
⏰ PST 3.07 18:00–19:00
⏰ EST 3.07 21:00–22:00
⏰ Beijing 3.08 10:00–11:00
Watch live: youtube.com/live/kHw6LZsXcH0
Register: luma.com/ezn8ho93
In this talk, the speaker will talk about:
🚀 How can we make LLM agent workflows faster, simpler, and more robust?
❌ Traditional request-level engines (vLLM, SGLang) struggle with KV cache thrashing, memory imbalance, and resource leaks.
✅ ThunderAgent introduces Program Abstraction, treating multi-step agent workflows as programs, unifying GPU, CPU, and remote tool scheduling.
With just two lines of code, ThunderAgent boosts inference throughput by 1.5–3.6×, rollout throughput by 1.8–3.9×, and saves 4.2× disk space, while ensuring high concurrency stability.
Join us to explore a principled, program-level approach to distributed agent inference and RL rollouts.
#AI #LLM #AgenticAI #ReinforcementLearning #DistributedSystems #ProgramAbstraction #ThunderAgent

2
4
9
4,701
automatas we're so back!
Feb 25

I used to be a strong believer in the “Bitter Lesson.” However, my view began to shift once I realized that real-world agentic systems inevitably need to call external tools due to limitations in knowledge acquisition, precision computation, and environment interaction.
An important observation is that LLMs, especially when deployed as agents, are not purely connectionist systems. Instead, they are better understood as a hybrid of connectionism and symbolism. While we encode discrete tokens into continuous representations through neural networks, we ultimately decode them back into symbolic forms to operate in the real world.
For example, special tokens such as <EOS> serve as explicit symbolic markers that deterministically control termination. This illustrates that even within LLMs, symbolic structure plays a fundamental operational role. This reflects something deeper: humans use discrete symbols to make sense of a continuous world. We impose structure, define rules, and create abstractions so that reasoning and coordination become possible. Symbolism is not a relic of pre-neural AI; it is a mechanism for control.
f we want LLMs to be controllable, we cannot ignore their symbolic layer. The question is not whether to use symbols, but how to use them more flexibly. We need better ways to integrate discrete symbolic structure with continuous neural computation, rather than pretending that scaling alone will dissolve the need for structure.
1
114
Weili Xu retweeted

Feb 23
GPT-5.3-Codex the Codex app is the best AI coding tool available right now.
Slept on it for a bit.
Likely going to move back to a ChatGPT Pro sub from Claude MAX because of how good it is.
It's so precise, accurate and excellent at following instructions. There are trade-offs in that it has a more "machine-like" personality than Claude.
I do still love Claude.
But for getting software dev work done, Codex is the best option right now.
It's two things:
1. OpenAI is clearly investing a lot of their human talent into making Codex better.
2. They are co-designing the model and harness together.
And I believe that they have the most rapid post-training capabilities which is why you see a new model iteration every month for the last few months.
Endorsing Codex.


it gonna get so much better it’s unreal. we will look back on the first iterations of these apps in wonder that we got anything done
42
18
330
237,408
Weili Xu retweeted

Feb 17
Check our ThunderAgent (thunderagent.ai) and @GT_HaoKang 's post 👇, 2 lines of code, up to 3.9x throughputs improvement, 4.2x disk memory saving on your agentic inference system 😉

Feb 17
🔥Modifying 2 lines of code and get your agentic serving/rollout up to 3.9x faster losslessly!
⚡️Say hello to ThunderAgent, a fast, simple, and program-aware agentic Inference System.
🥇 We propose a program abstraction to schedule all GPU and CPU resources, the first principled approach for distributed agentic inference and rollout.
🌐 Blog: thunderagent.ai/
💻 Code: github.com/ThunderAgent-org/…
📜 Paper: arxiv.org/pdf/2602.13692
#AI #ThunderAgent #LLMAgent #Mlsys
1/n
3
10
1,050
Weili Xu retweeted

Feb 17
Checkout ThunderAgent led by @GT_HaoKang, intern at @togethercompute! An agentic workflow involves multiple model and tool requests, but inference systems make scheduling decisions on a per-request basis. ThunderAgent introduces a simple "program abstraction" to track the end to end workflow state and improve agentic inference throughput! 🔥
Feb 17
🔥Modifying 2 lines of code and get your agentic serving/rollout up to 3.9x faster losslessly!
⚡️Say hello to ThunderAgent, a fast, simple, and program-aware agentic Inference System.
🥇 We propose a program abstraction to schedule all GPU and CPU resources, the first principled approach for distributed agentic inference and rollout.
🌐 Blog: thunderagent.ai/
💻 Code: github.com/ThunderAgent-org/…
📜 Paper: arxiv.org/pdf/2602.13692
#AI #ThunderAgent #LLMAgent #Mlsys
1/n
1
9
47
4,135
Weili Xu retweeted

Feb 17
🔥Modifying 2 lines of code and get your agentic serving/rollout up to 3.9x faster losslessly!
⚡️Say hello to ThunderAgent, a fast, simple, and program-aware agentic Inference System.
🥇 We propose a program abstraction to schedule all GPU and CPU resources, the first principled approach for distributed agentic inference and rollout.
🌐 Blog: thunderagent.ai/
💻 Code: github.com/ThunderAgent-org/…
📜 Paper: arxiv.org/pdf/2602.13692
#AI #ThunderAgent #LLMAgent #Mlsys
1/n
3
24
109
30,854
Weili Xu retweeted

Feb 12
Time to consider not just human visitors, but to treat agents as first-class citizens. Cloudflare’s network now supports real-time content conversion to Markdown at the source using content negotiation headers.
cfl.re/4ksZQ1S
167
550
4,524
2,128,089
Weili Xu retweeted

Feb 9
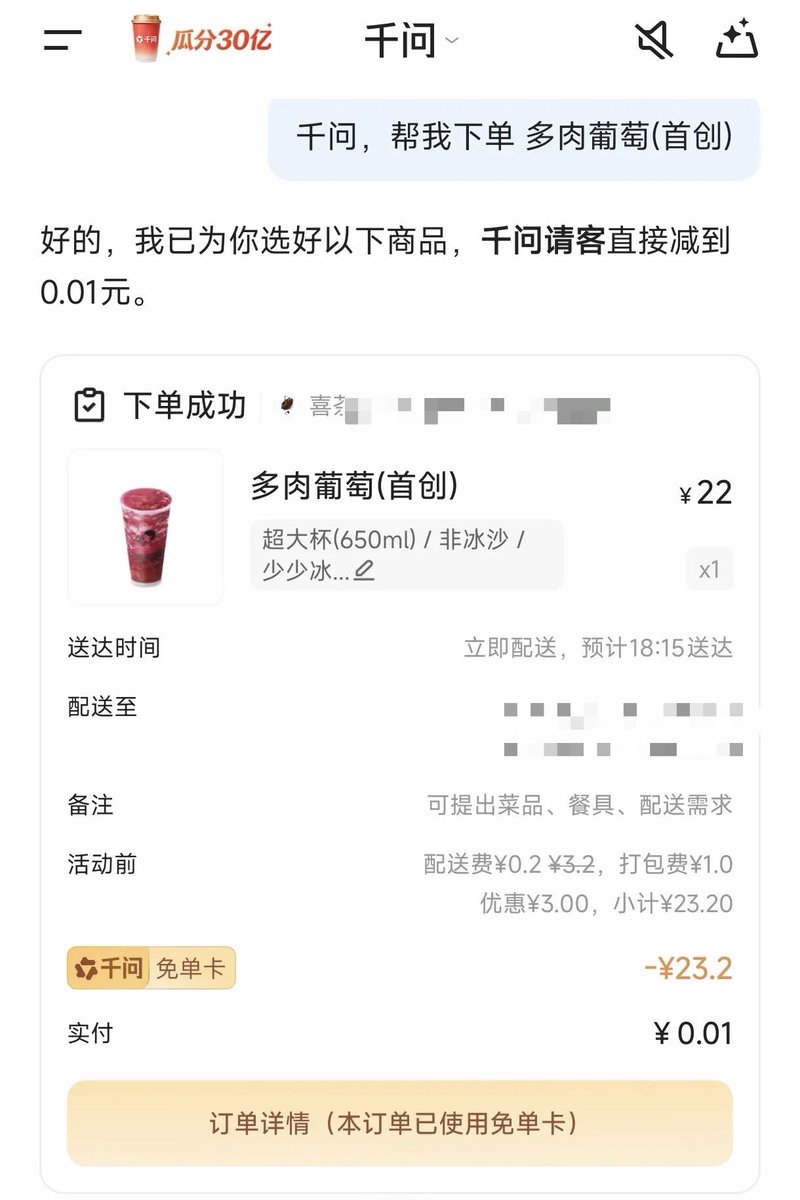
@sama can we start getting free boba if we order through chatgpt
Feb 9

no one cares about your SWE-Bench score if your competitor is giving out free boba
Qwen: ask our chatbot to order your drink. it pays.
3
3
78
7,840
Weili Xu retweeted

Jan 20
Beyond softmax attention
Linear attention and its variants enable faster inference without growing the KV cache.
Let’s learn the core ideas behind efficient sequence modeling. 👇
youtu.be/pUCWwGR5WmQ

13
92
747
91,827
Weili Xu retweeted
Jan 15
Learn how @cursor_ai partnered with Together AI, the AI Native Cloud, to deliver real-time inference for AI-powered coding.
Cursor's in-editor agents generate code while developers actively edit — requiring responses inside the editor's feedback loop. Together AI built the infrastructure to meet those strict latency targets at scale.
1
10
45
17,517



full slide deck available at drive.google.com/file/d/1KtA…
1
66