
PhD Student @ MBZUAI
Joined March 2026
- Tweets 28
- Following 49
- Followers 31
- Likes 49
6 Photos and videos




Pinned Tweet

Jun 9
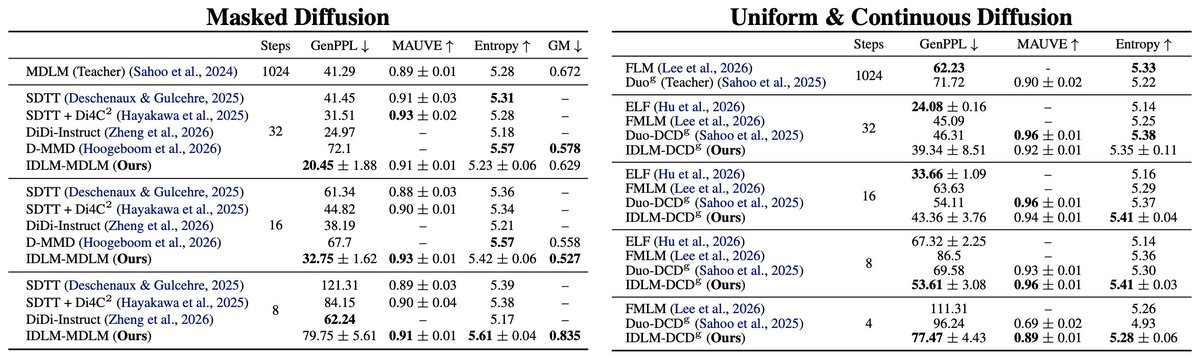
🚀 We made a big update to the camera-ready version of our ICML 2026 paper: IDLM: Inverse-distilled Diffusion Language Models
Main highlights:
🧮 TinyGSM/GSM8K results
⚖️ More baselines metrics
📉 GenPPL–entropy frontier.
📝 New IDLM blog post
1
7
12
1,296
David retweeted

📢 June 15 (Mon): Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
🤔 Discrete diffusion models are often trained through clean-data prediction, but the prediction can be used in different ways to define the reverse dynamics. In Masked Diffusion Models (MDM) these choices largely coincide, whereas in Uniform Diffusion Models (UDM) they do not.
💡 The authors show that the standard plug-in bridge parameterization for UDM is not optimized by the denoising posterior, but by a leave-one-out posterior that predicts each clean token without using its own noisy observation. This identifies a mismatch between the plug-in ELBO and the usual cross-entropy denoising objective.
🔧 The authors characterize the leave-one-out target and derive exact conversions between the denoiser, the leave-one-out posterior, and the score. These conversions allow them to disentangle parameterization and the training objective.
📈 Their results also lead to inference improvements without any additional training through an informed predictor-corrector sampler and improved temperature sampling based on the leave-one-out predictor.
🔧 The authors further introduce an absorbing-state reformulation of uniform diffusion that preserves the UDM joint law while decomposing it into masked-diffusion-like sampling operations, with simpler denoising posteriors, carry-over unmasking, and a natural remasking mechanism.
📈 On language modeling, leave-one-out parameterizations consistently improve UDM generation, while the absorbing construction matches or surpasses masked diffusion. These results suggest that the empirical gap between masked and uniform diffusion is driven less by the choice of marginals themselves than by parameterization and sampling design.
This Monday, Samson Gourevitch (@samsongvch, samsongourevitch.github.io/), Yazid Janati (@yjelid, yazidjanati.github.io/), and Dario Shariatian (@dario_sha, darioshar.github.io/) will present their paper "Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation".

1
5
22
3,658
Jun 9
🚀 We made a big update to the camera-ready version of our ICML 2026 paper: IDLM: Inverse-distilled Diffusion Language Models
Main highlights:
🧮 TinyGSM/GSM8K results
⚖️ More baselines metrics
📉 GenPPL–entropy frontier.
📝 New IDLM blog post
1
7
12
1,296
Jun 9
🔗Blog paper code checkpoints:
📝 Blog: david-cripto.github.io/Bio-p…
📄 Paper: arxiv.org/abs/2602.19066
💻 Code: github.com/David-cripto/IDLM
🤗 Checkpoints: huggingface.co/kekchpek/mode…
We updated and released all the materials needed to explore and reproduce IDLM.
1
1
118
Jun 9
I’m additionally tagging a few people who might be interested in the new results and materials:
@yjelid @ssahoo_ @dvruette @AndrewC_ML @ValentinDeBort1 @ArnaudDoucet1 @WeiGuo01
1
2
140
David retweeted
📢 June 1 (Mon): ELF: Embedded Language Flows
🤔Unlike their image-domain counterparts, today’s leading diffusion language models (DLMs) primarily operate over discrete tokens.
💡The authors show that continuous DLMs can be made effective with minimal adaptation to the discrete domain. They propose Embedded Language Flows (ELF), a class of diffusion models in continuous embedding space based on continuous-time Flow Matching. Unlike existing DLMs, ELF predominantly stays within the continuous embedding space until the final time step, where it maps to discrete tokens using a shared-weight network.
🔧This formulation makes it straightforward to adapt established techniques from image-domain diffusion models, e.g., classifier-free guidance (CFG).
📈Experiments show that ELF substantially outperforms leading discrete and continuous DLMs, achieving better generation quality with fewer sampling steps. These results suggest that ELF offers a promising path toward effective continuous DLMs.
This Monday, Keya Hu (@HuLillian39250) and Linlu Qiu (@linluqiu) will present their jointly led paper ELF.

3
14
82
20,469
May 27
Very exciting direction. Eager to dig into the preprint and see where this leads.
May 27

Happy to share our recent preprint:
Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
Takeaways:
- standard implementations of uniform diffusion do not learn a denoiser, but rather a
"leave-one-out" denoiser
- uniform diffusion and masked diffusion are two sides of the same coin
paper: arxiv.org/abs/2605.22765
code: github.com/samsongourevitch/… (we release 9 models trained on owt)
with @samsongvch @dario_sha @umutsimsekli @EricMoulines @ericxing
@AlainDurmus
A short thread on our findings:
(1/5)

1
2
331
May 23
So eager to see this!

📢 May 25 (Mon): Language Modeling with Spherical Geometry 📷
💡Join us to hear Justin (@jdeschena) and Jannis (@JChemseddine) present their recent work on (Hyper)spherical language modeling!
⚖️Discrete Diffusion and Continuous Flow Language Models (DLMs / FLMs) have emerged as interesting alternatives to autoregressive models. Yet they face fundamental tensions: discrete diffusion samples from a factorized distribution that is strictly less expressive than AR. FLMs avoid factorized sampling but typically add Gaussian noise on one-hot vectors or embeddings. It is far from clear that this kind of noise is well suited to text generation.
🤔Both papers ask the same question: what if the natural geometry for language flows isn't Euclidean space or the probability simplex, but the sphere? The hint has been there for a while: prior work like CDCD (@sedielem et al.) already operates on normalized vectors, and empirically, the cosine distance outperforms the Euclidean one for comparing word embeddings (think of word2vec, GloVe, or retrieval systems).
🧭By lifting tokens onto Sᵈ⁻¹, the authors develop tools for spherical language modeling via SLERP and vMF paths. The vMF path has the added benefit of a closed-form score, enabling principled predictor–corrector samplers on the sphere.
📈 Working with the sphere leads to concrete performance improvements: on code generation with TinyGSM, prior FLMs reach roughly 0% accuracy, while flows on the hypersphere reach 12–18% 🚀. This still lags behind the AR and discrete diffusion baselines, but it strongly suggests that spherical embedding geometry is a natural noise model for tokens. At matched NFE, a properly tuned PC sampler with vMF paths clearly improves the accuracy on Sudoku. And as a bonus, training with rotations avoids materializing one-hot vectors, making it cheaper than standard FLM training⚡️.
🔗 Language Modeling with Hyperspherical Flows: arxiv.org/abs/2605.11125
🔗 Spherical Flows for Sampling Categorical Data: arxiv.org/abs/2605.05629
🤝 Joint work with Caglar Gulcehre (@caglarml), Gregor Kornhardt (@gregorkornhardt), and Gabriele Steidl (page.math.tu-berlin.de/~stei…)

2
108
May 19
Amazing work and interesting results🔥. The next step is to evaluate them in benchmarks
May 19

We were all wondering whether Categorical Flow Maps (CFMs) could scale... 🤔
I couldn't help trying it out...
So we scaled CFMs to 1.7B parameters over 2.1T tokens 🚀🔥
Short summary 🧵⬇️
1
3
631
David retweeted

May 19
We were all wondering whether Categorical Flow Maps (CFMs) could scale... 🤔
I couldn't help trying it out...
So we scaled CFMs to 1.7B parameters over 2.1T tokens 🚀🔥
Short summary 🧵⬇️
4
32
128
15,809
David retweeted

May 18
📢 Missed the talk? Check out the recording on YouTube: youtu.be/RZ6_huata1Y
📢 May 18 (Mon): IDLM: Inverse-distilled Diffusion Language Models
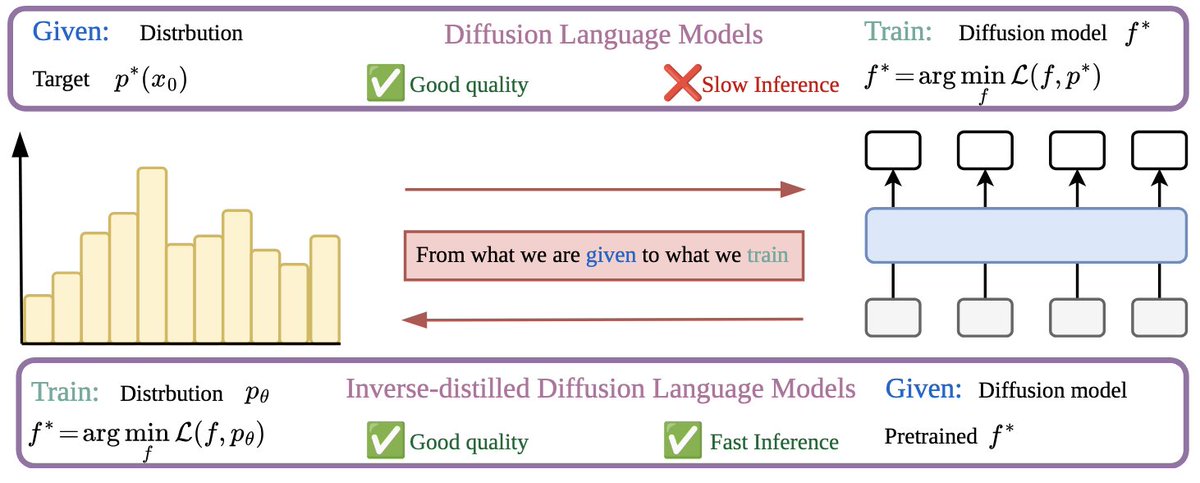
🤔Diffusion Language Models (DLMs) have recently achieved strong results in text generation. However, their multi-step sampling leads to slow inference, limiting practical use.
💡To address this, the authors extend Inverse Distillation, a technique originally developed to accelerate continuous diffusion models, to the discrete setting. However, this extension introduces both theoretical and practical challenges.
🔧To overcome these challenges, the authors first provide a theoretical result demonstrating that their inverse formulation admits a unique solution, thereby ensuring valid optimization. They then introduce gradient-stable relaxations to support effective training.
📊As a result, experiments on multiple DLMs show that their method, Inverse-distilled Diffusion Language Models (IDLM), reduces the number of inference steps by 4×—64×, while preserving the teacher model’s entropy and generative perplexity.
This Monday, David Li (scholar.google.com/citations…) and Nikita Gushchin (scholar.google.com/citations…) will present their jointly led paper, which was recently accepted at ICML 2026.
Collaborators of this work include: Dmitry Abulkhanov (@dabulkhanov_), Eric Moulines (scholar.google.com/citations…), Ivan Oseledets (@oseledetsivan), Maxim Panov (@maxim_panov), Alexander Korotin (akorotin.netlify.app/)
Paper link: arxiv.org/abs/2602.19066

1
6
16
2,633
David retweeted

May 19
📢Excited to share our new paper:
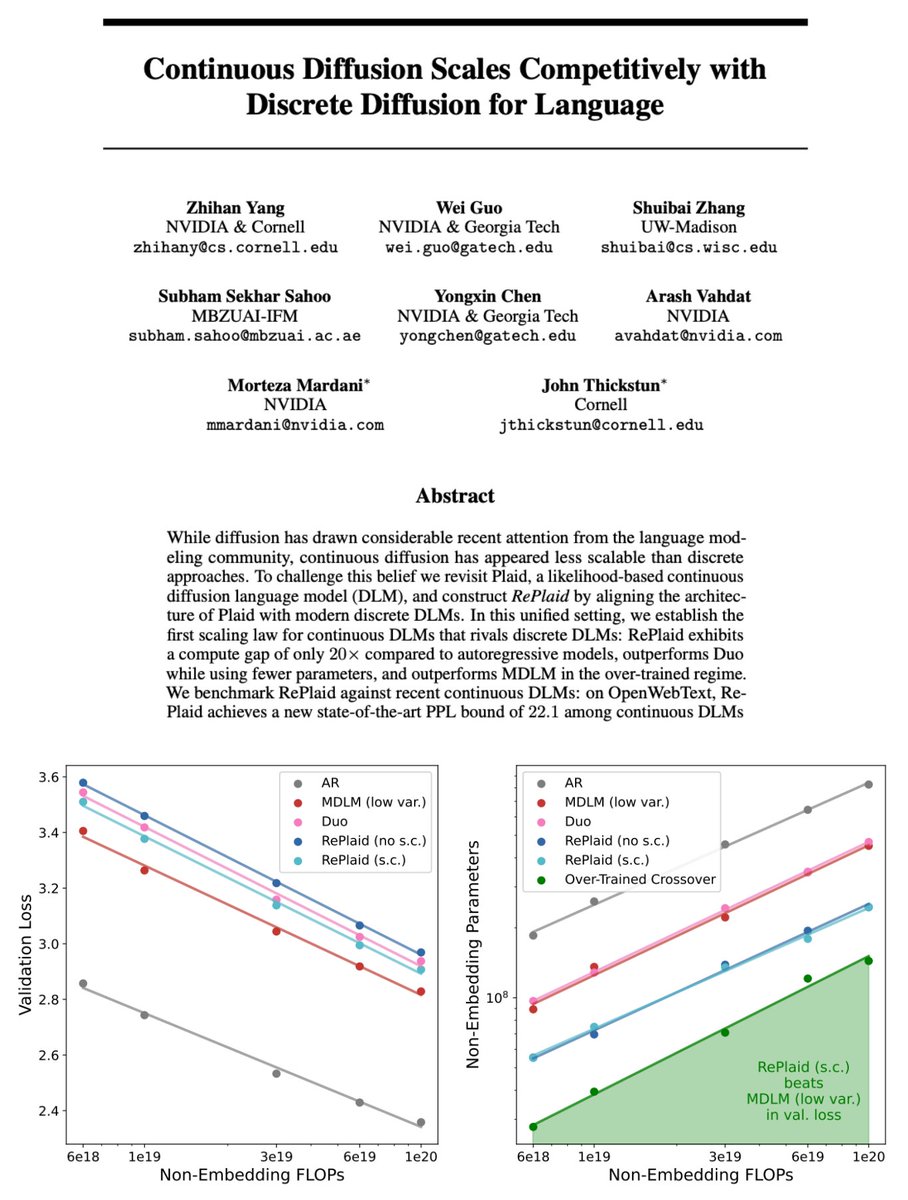
Continuous Diffusion Scales Competitively with Discrete Diffusion for Language
We introduce RePlaid 🌊, a continuous diffusion language model (DLM) with
🏅Discrete likelihood bound
🏅Scaling laws competitive with SOTA discrete DLMs
How? Dive in👇[🧵1/12]
Paper: arxiv.org/abs/2605.18530
Work done with my amazing collaborators: @WeiGuo01 @ShuibaiZ69721 @ssahoo_ @YongxinChen1 @ArashVahdat @MardaniMorteza @jwthickstun
5
46
202
61,432
May 18
🚀 Today, @iNikitaGushchin and I will be presenting our work on IDLM as part of the dLLM Reading Group!
We’ll discuss the main ideas behind the paper, what motivated this direction, and why we believe it is an exciting step for diffusion-based language modeling.
1
3
8
1,403
May 18
I also shared a brief overview of the core idea in my Telegram channel for anyone curious, you can check it out here: t.me/LiSearch
We’ll be happy to see everyone interested in diffusion LMs, generative modeling, or just curious about where this field is heading.
1
92
May 18
📄 Paper: arxiv.org/abs/2602.19066
💻 Code: github.com/David-cripto/IDLM
📢 Invitation post: x.com/diffusion_llms/status/…
Many thanks to the organizers for the invitation,
@jdeschena, @ssahoo_, @zhihanyang_! 🙌
#ICML2026 #DiffusionModels #LanguageModels #GenerativeAI #MachineLearning
📢 May 18 (Mon): IDLM: Inverse-distilled Diffusion Language Models
🤔Diffusion Language Models (DLMs) have recently achieved strong results in text generation. However, their multi-step sampling leads to slow inference, limiting practical use.
💡To address this, the authors extend Inverse Distillation, a technique originally developed to accelerate continuous diffusion models, to the discrete setting. However, this extension introduces both theoretical and practical challenges.
🔧To overcome these challenges, the authors first provide a theoretical result demonstrating that their inverse formulation admits a unique solution, thereby ensuring valid optimization. They then introduce gradient-stable relaxations to support effective training.
📊As a result, experiments on multiple DLMs show that their method, Inverse-distilled Diffusion Language Models (IDLM), reduces the number of inference steps by 4×—64×, while preserving the teacher model’s entropy and generative perplexity.
This Monday, David Li (scholar.google.com/citations…) and Nikita Gushchin (scholar.google.com/citations…) will present their jointly led paper, which was recently accepted at ICML 2026.
Collaborators of this work include: Dmitry Abulkhanov (@dabulkhanov_), Eric Moulines (scholar.google.com/citations…), Ivan Oseledets (@oseledetsivan), Maxim Panov (@maxim_panov), Alexander Korotin (akorotin.netlify.app/)
Paper link: arxiv.org/abs/2602.19066
1
10
459
David retweeted

Since I'm between jobs, I've been having a lot of fun vibe-coding with public tooling.
First drop: a clean PyTorch impl of the Gradient Moment metric from our recent paper (arXiv:2603.20155).
github.com/ehoogeboom/gradie…

5
5
67
5,339
David retweeted
📢 May 18 (Mon): IDLM: Inverse-distilled Diffusion Language Models
🤔Diffusion Language Models (DLMs) have recently achieved strong results in text generation. However, their multi-step sampling leads to slow inference, limiting practical use.
💡To address this, the authors extend Inverse Distillation, a technique originally developed to accelerate continuous diffusion models, to the discrete setting. However, this extension introduces both theoretical and practical challenges.
🔧To overcome these challenges, the authors first provide a theoretical result demonstrating that their inverse formulation admits a unique solution, thereby ensuring valid optimization. They then introduce gradient-stable relaxations to support effective training.
📊As a result, experiments on multiple DLMs show that their method, Inverse-distilled Diffusion Language Models (IDLM), reduces the number of inference steps by 4×—64×, while preserving the teacher model’s entropy and generative perplexity.
This Monday, David Li (scholar.google.com/citations…) and Nikita Gushchin (scholar.google.com/citations…) will present their jointly led paper, which was recently accepted at ICML 2026.
Collaborators of this work include: Dmitry Abulkhanov (@dabulkhanov_), Eric Moulines (scholar.google.com/citations…), Ivan Oseledets (@oseledetsivan), Maxim Panov (@maxim_panov), Alexander Korotin (akorotin.netlify.app/)
Paper link: arxiv.org/abs/2602.19066
2
13
35
9,705