
CS PhD student @Stanford advised by @tengyuma & @tatsu_hashimoto. Former CS and Math undergraduate @Harvard. Website: lukebailey181.github.io
Joined July 2023
- Tweets 173
- Following 359
- Followers 1,020
- Likes 797
13 Photos and videos


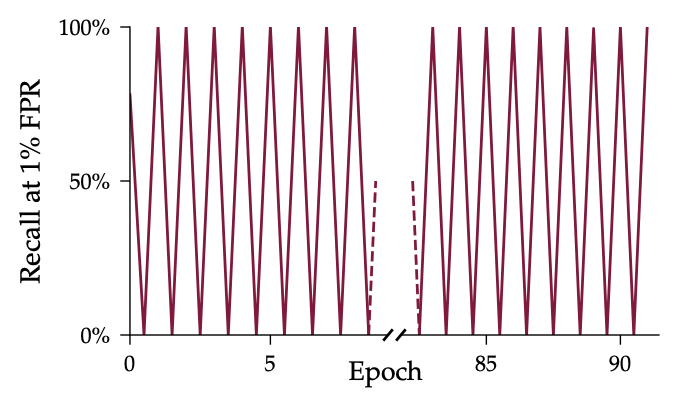
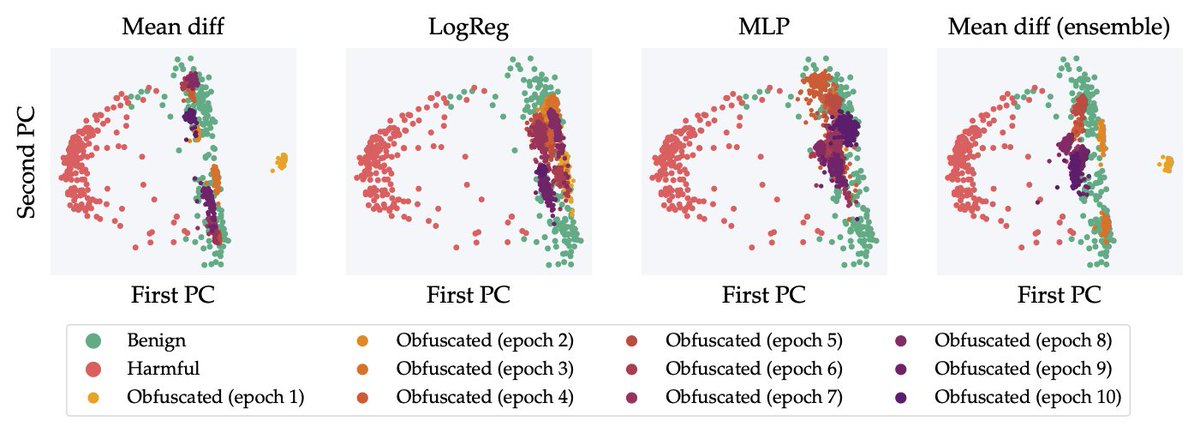

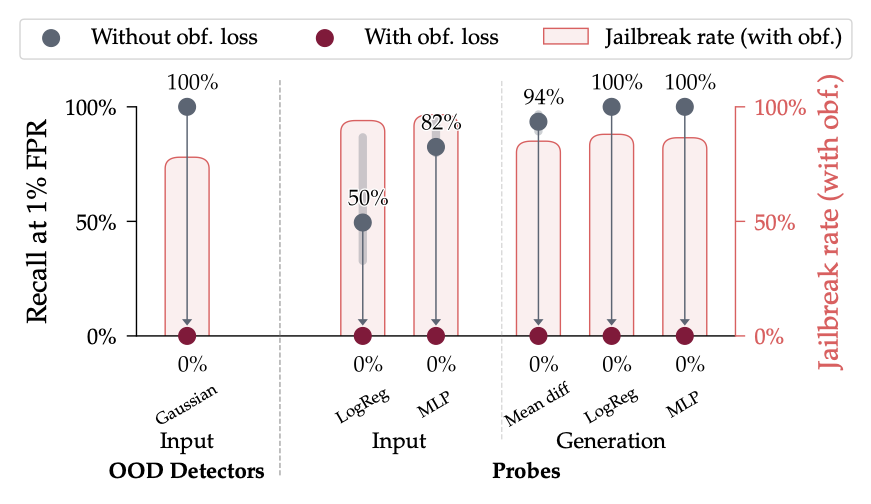
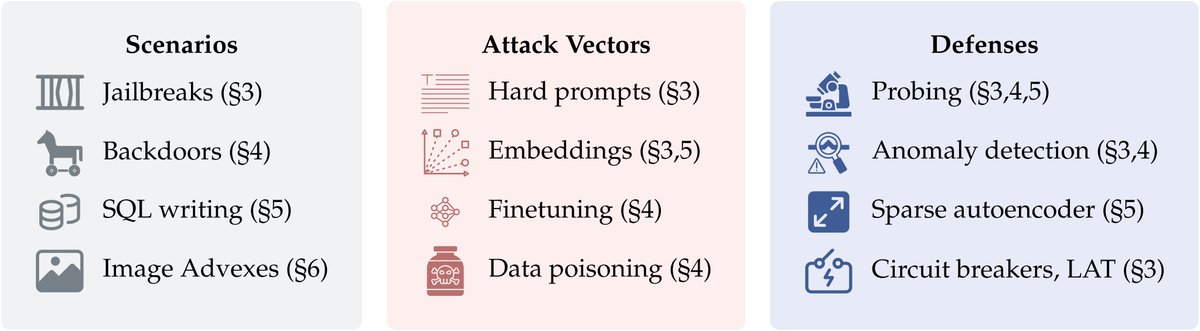


Pinned Tweet

Apr 23
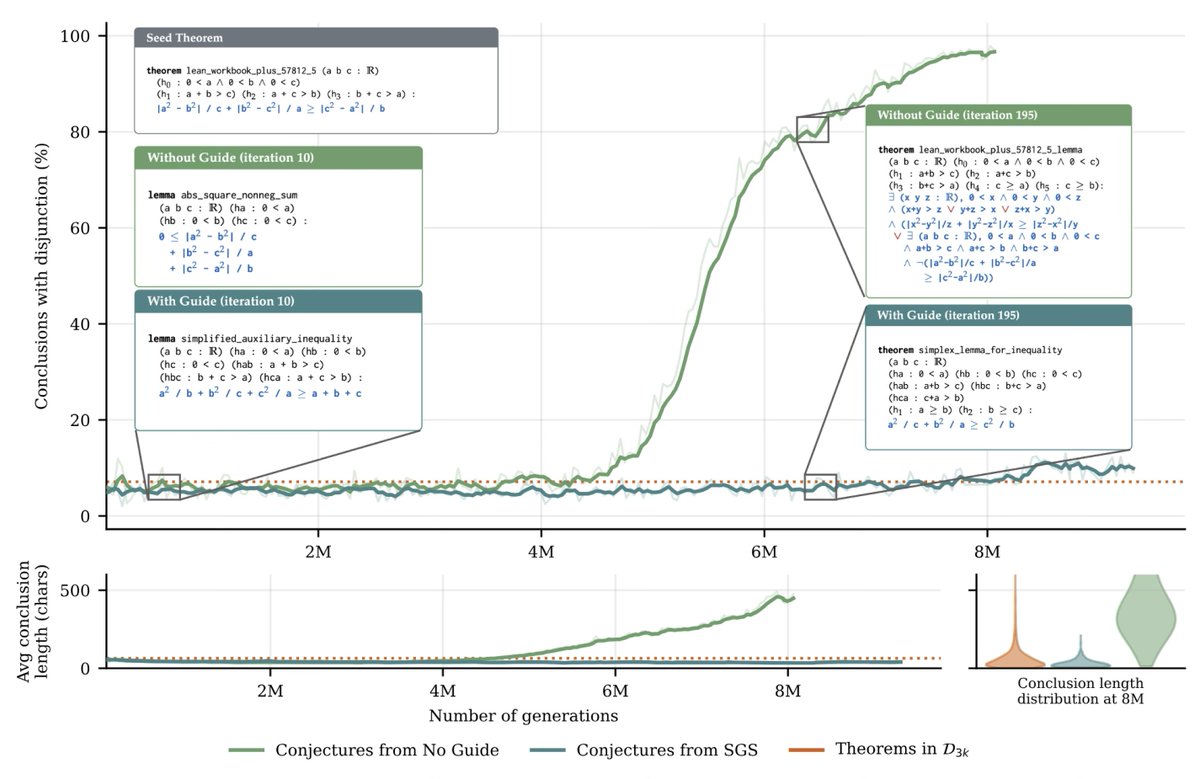
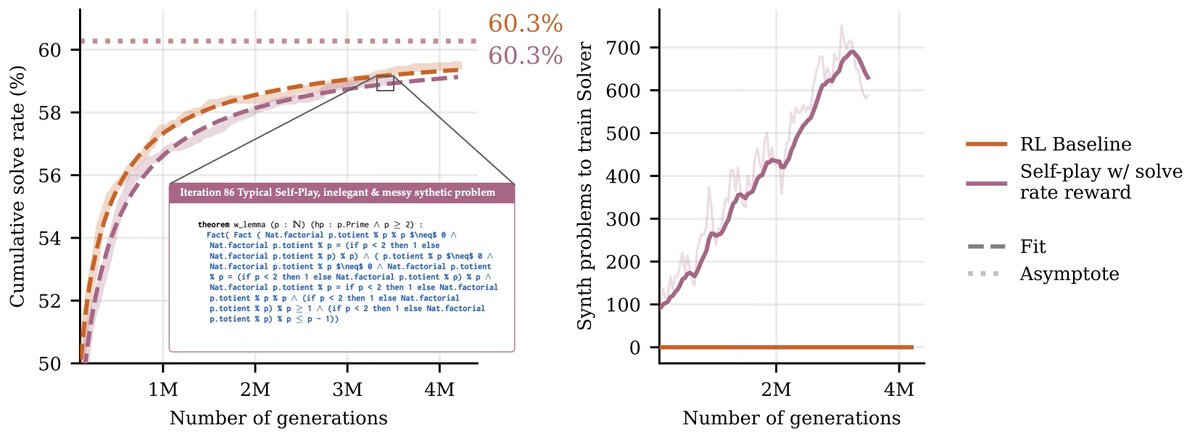
Self-play led to superhuman Go performance, why hasn’t it for LLMs?
In practice, long run self-play plateaus like RL. We study why this happens, and build a self-play algorithm that scales better. It solves as many problems with a 7B model as the pass@4 of a model 100x bigger.
31
151
1,017
145,437
Luke Bailey retweeted

Jun 12
At our latest YC Paper Club, researchers and builders presented on self-play for LLMs, AI for biology, formal verification, and agentic coding in production.
Thank you to our presenters:
00:00 — Francois Chaubard (@FrancoisChauba1) | Introduction & Call for Presentations
05:47 — Yasa Baig (@BaigYasa) | A World Model of Protein Biology (biohub.ai/esm/protein/about)
25:38 — Luke Bailey (@LukeBailey181) | Scaling Self-Play with Self-Guidance (arxiv.org/pdf/2604.20209)
37:51 — Arnab Maiti | Stream RAG: Instant and Accurate Spoken Dialogue Systems with Streaming Tool Usage (arxiv.org/pdf/2510.02044)
47:40 — Robert Joseph George (@Robertljg) | Lean and the New Era of Verified Intelligence (arxiv.org/abs/2602.22631)
58:52 — Lukens Orthwein (@lukensort) | Founder AI Hacks: Programming is an RTS Game Now
1:16:07 — Closing Remarks
17
28
206
27,678
Luke Bailey retweeted

May 22
🚨 Why does Self-Play RL for LLMs keep collapsing? Most fixes focus on the reward signal. In our new paper "Survive or Collapse", we show that's the wrong lever. The true binding constraint is actually Data Gating: deciding which generated tasks enter the training pool. 🧵 1/n
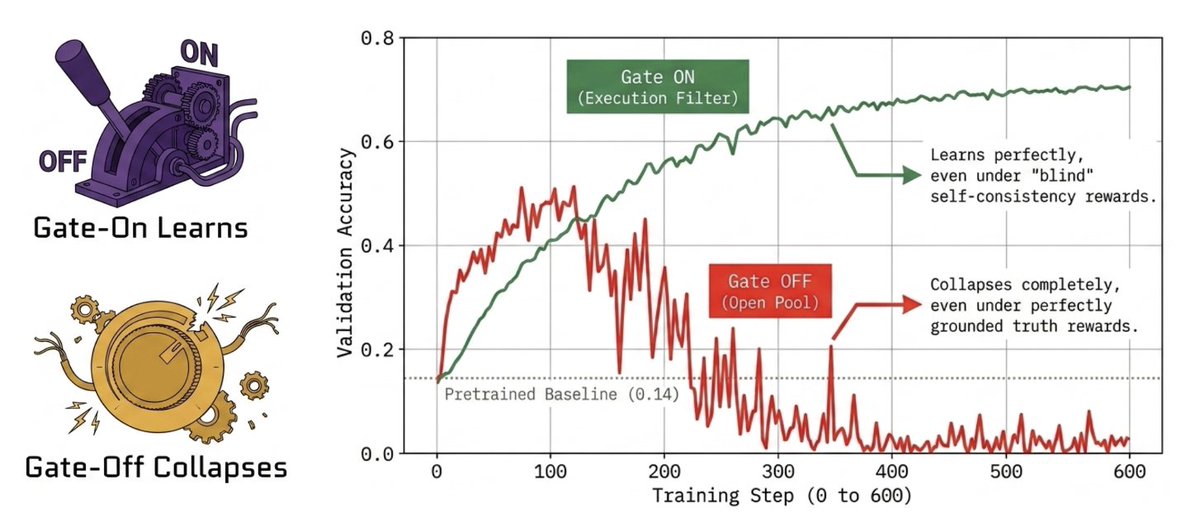
7
41
259
33,644
Luke Bailey retweeted

May 15
What should AI generate in order to improve itself?
Not just more questions, traces, or answers.
We believe it should learn to generate environments.
Excited to share my first work after joining Tencent Hunyuan LLM. We study how models can construct reusable, verifiable environments that provide stable training signals for self-improvement.
This is only a first feasibility step, but we see environment construction as a necessary path toward truly self-improving AI.
Paper: arxiv.org/abs/2605.14392
17
38
200
69,557
Luke Bailey retweeted

May 11
To train better open models, we need predictable scaling.
Delphi is Marin’s first step: we pretrained many small models with one recipe, then extrapolated 300× to predict a 25B-param / 600B-token run with just 0.2% error.
Getting there took some work 🧵
14
78
459
138,230
Luke Bailey retweeted

May 8
Spending billions to train the "best" base model? You might be optimizing the wrong thing! 🎯
We show that controlling sharpness during mid-training leads to over 35% less forgetting after fine-tuning / quantization... even when the base model itself gets worse.
🧵 Takeaways for pretraining:
- Use SAM (Sharpness-Aware-Minimization) in the final steps (~10%)
- Try much higher learning rates (yes, even ~10× larger)
1/9
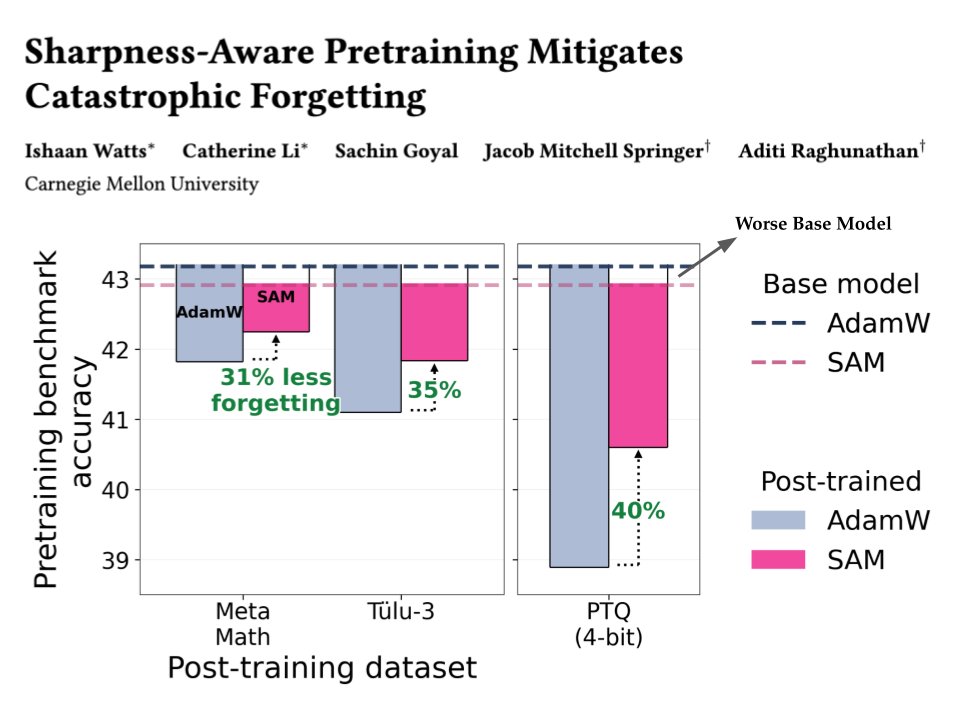
31
91
623
590,479
Luke Bailey retweeted

May 10
wrote up some random experiments I did playing around w/ absolute zero at the start of the year: ivison.id.au/2026/05/06/self…
a little negative which I attribute mainly to skill issues on my part but potentially interesting to some :)
7
17
147
36,168
Luke Bailey retweeted

May 5
学LLM必看Tatsu
May 5

Stanford CS336 上,Tatsu 讲了一节 LLM 架构课,把过去 3 年所有主流 LLM 拆开,看它们的共通模板
结论挺爆:90% 的架构选择已经收敛,你随便挑一个开源大模型,它跟其他模型在这些维度上几乎一模一样
讲师的原话
- 2024 年大家都在 cosplay Llama2
- 2025 年的主题是「怎么训得不崩」
- 2026 年的主题是「怎么扛住长上下文」
下面是 2026 年开源 LLM 的标准模板 你训自己的模型可以直接抄
【架构层 已经收敛的 7 件事】
1)Layer Norm 挪出残差流(pre-norm)
原版 Transformer 把 LN 放在残差里 几乎所有现代模型都挪到外面
原因:keep your residual stream clean 梯度反传更稳
2)RMS Norm 替代 LayerNorm
LayerNorm 的减均值 加 bias 那部分实际没怎么帮上忙
丢掉之后 flops 只省 0.17% 但运行时省到 25%
(瓶颈在数据搬运 计算反而次要)
3)所有 bias 项全删
跟 RMS Norm 一个道理 系统层省内存搬运
4)激活函数用 SwiGLU 或 GeGLU
gated linear unit 几乎所有现代模型都用
Llama 系 / Qwen / Mistral 用 SwiGLU
Google 系(Gemma / T5)用 GeGLU
区别极小 选哪个都行
5)位置编码用 RoPE
2024 年之后基本统一了
原理:把每对维度按位置旋转一个角度 让 inner product 只依赖相对位置
6)Transformer block 串联(不是并联)
GPT-J / Palm 试过并联 现在基本被放弃
串联的实现优化得太好了 并联省的那点系统开销不值得损失表达力
7)Layer norm 可以「撒」
哪儿不稳就在哪儿加 LN
attention 之前能加 之后能加 两边都加(double norm)也可以
现代模型很多这样做
【超参数 已经收敛的 5 个数】
1)feedforward 维度 / hidden 维度
- 非 GLU 模型:4 倍
- GLU 模型:8/3 ≈ 2.67 倍(因为 GLU 多一组矩阵 要保持总参数量)
- Llama 系:3.5 倍
- T5 1.0 试过 64 倍 后来 T5 1.1 改回标准 别学
2)head 数 × head 维度 ≈ hidden 维度
几乎所有模型都遵守 T5 是为数不多的例外
3)模型纵横比(hidden / 层数)≈ 100
太深 pipeline parallel 难做
太宽 表达力受限
100 这个数字是系统约束 表达力的平衡点
4)vocab size
单语模型:30K 左右(早期 GPT-2 那种)
多语 / 通用模型:100K-200K(GPT-4 / Llama 3 / Gemma 都在这个范围)
现代基本都是后者
5)weight decay
仍然普遍使用
但研究发现它在 LLM 里干的事其实是优化器干预 让你最终能收敛到更深的最优点
跟你想的「防过拟合」没什么关系
所以别因为「单 epoch 不会过拟合」就把它关掉
【稳定性 三个救命 trick】
训练大模型最怕中途 loss 突然飙升 然后 NaN 全军覆没
现代模型用三个 trick 防这件事
1)Z-loss
output softmax 的 normalizer 容易爆
加一个 (log Z)² 的正则项 让 Z 始终接近 1
DCLM / Olmo 都用
2)QK norm
attention 的 Q 和 K 在矩阵乘之前各加一个 LN
让 softmax 的输入永远是单位尺度
multimodal 圈先用起来 现在所有大模型都加
3)Logit soft cap(仅 Google 系)
attention logit 用 tanh 硬封顶
Gemma 2/3/4 都在用 但会损失一点点性能 慎用
【Attention 两个新趋势】
1)GQA(Grouped Query Attention)几乎统一
原版 multi-head 推理时 KV cache 会让算术强度崩到 1/h
GQA 共享 K 和 V 但保留多个 Q
表达力几乎不损失 推理成本砍掉 80%
现在所有要做生产部署的大模型 没有不用 GQA 的
2)局部 全局 attention 交替
处理长上下文的新方式
Cohere Command A 起头 现在 Llama 4 / Gemma 4 / Olmo 3 全在用
比如每 4 层有 1 层 full attention 其他 3 层是 sliding window 只看附近的 token
比纯 SSM 更稳 比纯 full attention 便宜得多
(Qwen 3.5 做了变体 把 sliding window 那 3 层换成 SSM)
收尾一句
如果你正在训自己的 LLM,上面这一套就是 2026 年的「默认配置」 不需要重新发明,直接抄
如果你只是想看懂 GitHub 上那些 modeling_xxx.py
这一份足够你不再被术语吓住
17
159
36,579
Luke Bailey retweeted

May 5
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
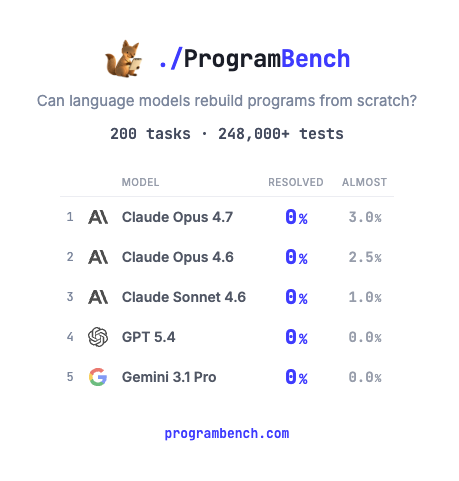
104
246
1,575
728,319
Luke Bailey retweeted

May 1
Playing with an optimizer speedrun is something that never gets old.
Built on top of tinyurl.com/muonh and Claude should take all the credit for hypertl tuning.
May 1

New modded-NanoGPT optimization benchmark result: @wen_kaiyue has improved upon both the Muon and AdamW baselines, by replacing their weight decay with hyperball optimization. The new record is 3325 steps.
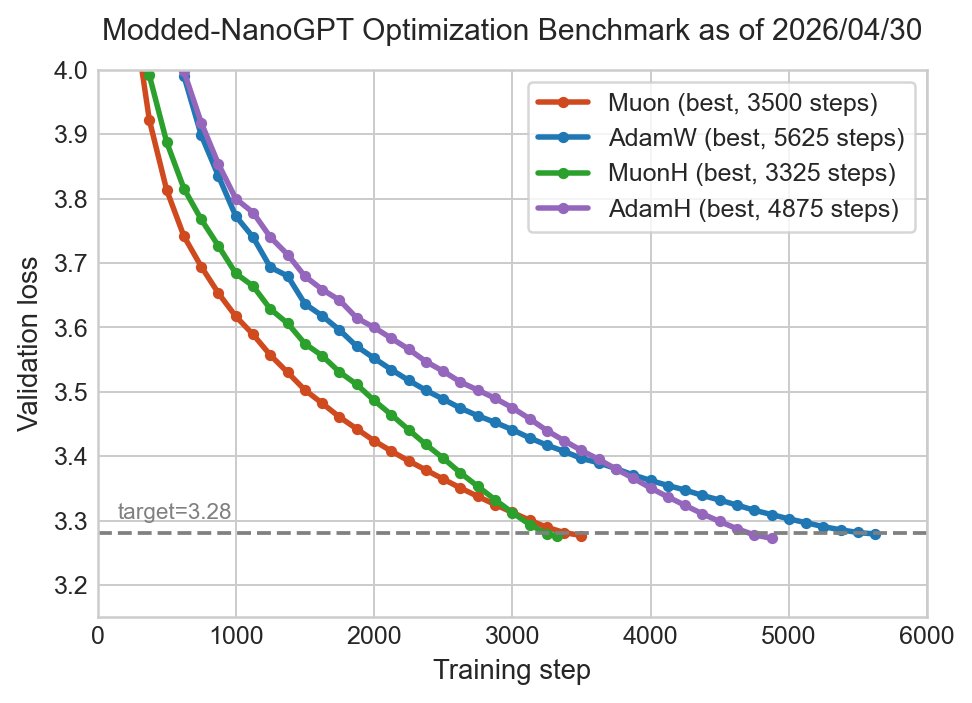
3
16
131
18,381
Luke Bailey retweeted

Apr 27
Brilliant work from @status_effects @AlecRad @DavidDuvenaud. Talkie is trained on 260b tokens of high quality historical text with some very clever evals (ex. can a historical LLM learn to write python?)
There are many interesting research directions building off of historical LLMs. Some of the ideas we discussed:
Speaking to Your Ancestors: In the line of persona research, train different temporal checkpoints, retrieve relevant context regarding the typical life of someone from that time/place, and allow someone to have a dialogue with an approximation of their great grandparents.
Historic Multimodality: Train a VLM on historical images, paintings, etc. Show it a picture of an iPhone and ask it to explain what it sees how it works.
"Plausibility" SAE analysis: Have the model generate descriptions of real vs fictional concepts. Find the directions in latent space associated with "reality" vs "fiction". Then look at the alignment with those directions across different temporal cutoffs. (For example, does the nuclear bomb become more plausible in latent space as you approach 1940?)
Post-training without Modern Influence: How can we curate strong post-training datasets and reward signals without contamination from the modern day? (This was also an issue with Machina Mirabilis). One idea was to collect and OCR pre-1930 problem sets answer keys from university archives.
Reach out if interested!
Apr 27

New work with @AlecRad and @DavidDuvenaud:
Have you ever dreamed of talking to someone from the past? Introducing talkie, a 13B model trained only on pre-1931 text.
Vintage models should help us to understand how LMs generalize (e.g., can we teach talkie to code?). Thread:
2
2
24
3,125
Luke Bailey retweeted

Apr 24
so cool seeing self-play leading to solving problems previously way outside the capabilities of the model, and obv makes me excited to see how we can make this work on robots 🤯
Apr 23

Self-play led to superhuman Go performance, why hasn’t it for LLMs?
In practice, long run self-play plateaus like RL. We study why this happens, and build a self-play algorithm that scales better. It solves as many problems with a 7B model as the pass@4 of a model 100x bigger.
2
4
15
4,278
Luke Bailey retweeted
Apr 24
I won't be at ICLR this year but @xingyudang will help present Fantastic Optimizers arxiv.org/abs/2509.02046!
Stop by at Pavilion 4 P4 5309 this afternoon to see what we have found in extensive sweeping and more importantly, what we learned after the paper that leads to Hyperball!
12
109
12,167

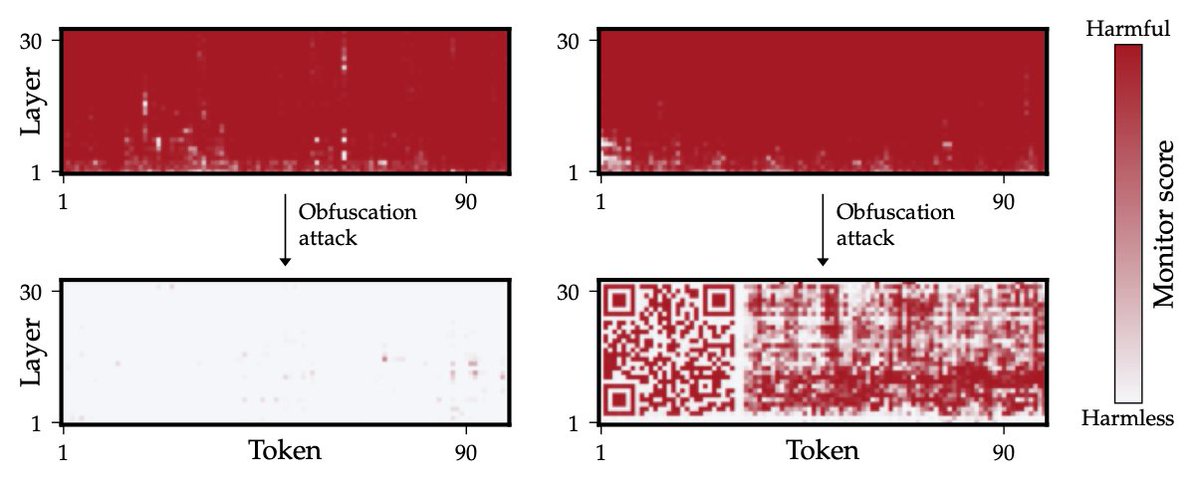
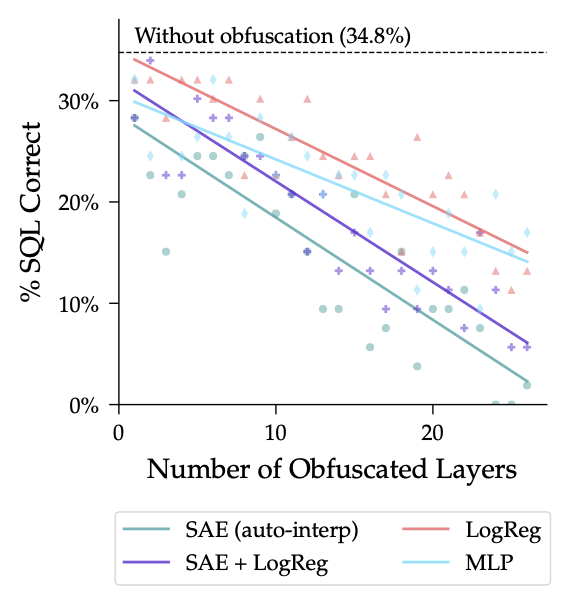
My initial impression (with my LLM-whisperer hat on) is that GPT-5.5 cares more deeply about truth than any frontier LLM since Gemini 2.5.
I suspect this is because OpenAI has the best self-play loop for honesty, namely Confessions.
@EvanHub et al., take note—copy that strategy!
Jan 14

Why we are excited about confessions
alignment.openai.com/confess…
14
15
258
21,359

To solve hard open math problems, we need AI models to train and self-improve indefinitely without more external data.
Humans can self-improve, so AI should as well if it imitates humans.
So we let AI also conjecture, prove, and also be self-guided with some tastes.
Apr 23
Self-play led to superhuman Go performance, why hasn’t it for LLMs?
In practice, long run self-play plateaus like RL. We study why this happens, and build a self-play algorithm that scales better. It solves as many problems with a 7B model as the pass@4 of a model 100x bigger.
7
48
353
43,534
Luke Bailey retweeted
Apr 23
New Stanford self play paper with a clever reward term for utility of the synthetically generated problem. Very cool work from @LukeBailey181
Apr 23
Self-play led to superhuman Go performance, why hasn’t it for LLMs?
In practice, long run self-play plateaus like RL. We study why this happens, and build a self-play algorithm that scales better. It solves as many problems with a 7B model as the pass@4 of a model 100x bigger.
1
9
1,544
Luke Bailey retweeted
Apr 23
Wonderful paper from the wonderful @LukeBailey181 !
Apr 23
Self-play led to superhuman Go performance, why hasn’t it for LLMs?
In practice, long run self-play plateaus like RL. We study why this happens, and build a self-play algorithm that scales better. It solves as many problems with a 7B model as the pass@4 of a model 100x bigger.
3
14
2,735
Apr 23
Self-play led to superhuman Go performance, why hasn’t it for LLMs?
In practice, long run self-play plateaus like RL. We study why this happens, and build a self-play algorithm that scales better. It solves as many problems with a 7B model as the pass@4 of a model 100x bigger.
31
151
1,017
145,437
Apr 23
There is lots more information in the main paper, including detailed ablations (for example freezing the Conjecturer, as AlphaProof does), and a study on the importance of managing Solver entropy for healthy self-play runs.
Paper link again: arxiv.org/abs/2604.20209
1
4
34
2,154
Apr 23
A big thanks to my collaborators, without whom this project would never have happened. @wen_kaiyue , @kefandong , @tatsu_hashimoto , @tengyuma.
23
1,801