
Managing Partner at @SeaplaneVC. 2X founder. Host of the @InvestNStartups podcast.
Joined February 2010
- Tweets 5,803
- Following 369
- Followers 10,098
- Likes 18,200
760 Photos and videos














Pinned Tweet

19 Oct 2025
I walked away from a 5-star fund and hundreds of millions in AUM to focus on investing in early-stage startups. Here’s why: seaplaneventures.com/post/wh…
2
4
26
61,288
Jun 13
1
284
Joe Magyer retweeted

Jun 12
Apollo selects Austin as site of second headquarters ft.trib.al/cIlIQRa
5
22
99
52,740
Joe Magyer retweeted

Jun 11
Fable 5 (@AnthropicAI) scores 22% and tops the Hedge-Bench leaderboard. Running Fable was roughly 2X more expensive than Opus 4.8 per trial. For an industry where accuracy is mission critical, human judgement isn't going away
1
5
27
2,856
Joe Magyer retweeted

Jun 10
Faster decisions start with cleaner data, not bigger teams.
Our self-service is live. Any document. Any format. Guaranteed accuracy. No implementation wait.
bit.ly/43FuNZc
1
1
214
Joe Magyer retweeted

this summer, it's time to lock in

6
2
34
2,751
Joe Magyer retweeted

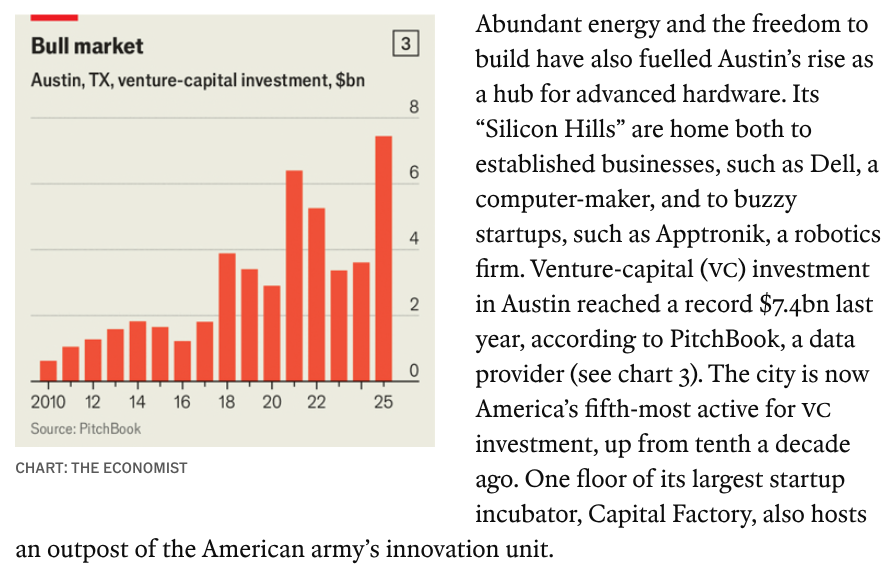
"Venture-capital investment in Austin reached a record $7.4 bn last year ...The city is now America’s 5th-most active for VC investment, up from 10th a decade ago" economist.com/business/2026/…
1
27
127
50,504

For the Analysts: between the sub-15% pass rate and 80% hallucination rate, your job is very safe
Jun 5

Today, Trata is excited to present Hedge-Bench, the world’s first benchmark focused on evaluating open-ended reasoning in the finance domain.
We curated 102 tasks derived explicitly from the reasoning traces of professional hedge fund analysts working with relevant information sources. Most benchmarks are geared towards evaluating naturally deterministic tasks (e.g. updating spreadsheets, calculating formulas). The result is a blind spot on the frontier labs’ part to the competency that matters most in the finance industry: reasoning.
No frontier model scores above 16% on Hedge-Bench. We observe Claude-Opus-4.8 actually regresses relative to the last generation of Claude-Sonnet. We see hallucination rates go as high as 82% for multi-step reasoning. These implications extend beyond just the finance domain and into other domains where trust in agent reliability is equally critical (e.g. law).
1
5
980
Joe Magyer retweeted
Jun 5
Today, Trata is excited to present Hedge-Bench, the world’s first benchmark focused on evaluating open-ended reasoning in the finance domain.
We curated 102 tasks derived explicitly from the reasoning traces of professional hedge fund analysts working with relevant information sources. Most benchmarks are geared towards evaluating naturally deterministic tasks (e.g. updating spreadsheets, calculating formulas). The result is a blind spot on the frontier labs’ part to the competency that matters most in the finance industry: reasoning.
No frontier model scores above 16% on Hedge-Bench. We observe Claude-Opus-4.8 actually regresses relative to the last generation of Claude-Sonnet. We see hallucination rates go as high as 82% for multi-step reasoning. These implications extend beyond just the finance domain and into other domains where trust in agent reliability is equally critical (e.g. law).
20
28
143
29,795
Joe Magyer retweeted

Jun 5
we’re partnering with 50 companies over the next two weeks, each with 50–200 employees, to help improve AI models using real-world company workflows.
we believe the companies that helped build modern business workflows should participate in — and very much benefit from — the value created by the next generation of AI systems.
for many companies, these partnerships can create a meaningful new revenue stream, often ranging from $100K to $2M , with opportunities to become recurring over time. our goal is to do this in a way that is privacy-first, low-lift, and aligned with the work companies are already doing every day.
if you’re interested in contributing to AI advancement while improving your own workflows alongside micro1 and our frontier AI lab partners, we’d love to hear from you.
please reach out to to camilo@micro1.ai if you’re an executive at a 50 employee company, excited to potentially partner up!
13
22
66
4,963
Joe Magyer retweeted
Jun 3
a very large portion of our latest expansion & data pipeline requests have been coding. as model capabilities improve in a certain domain, data demand explodes even more.
at micro1, we're building a world class coding research team. if you're interested in joining, check out micro1. ai/ research
2
8
40
3,346
Joe Magyer retweeted
Jun 2
5.5 million as of today
22 Oct 2025

now at 2M!
2,000,000 amazing experts have signed up on the micro1 platform to get matched with frontier AI opportunities, training the best LLMs.
4
7
29
2,105



Joe Magyer retweeted

May 20
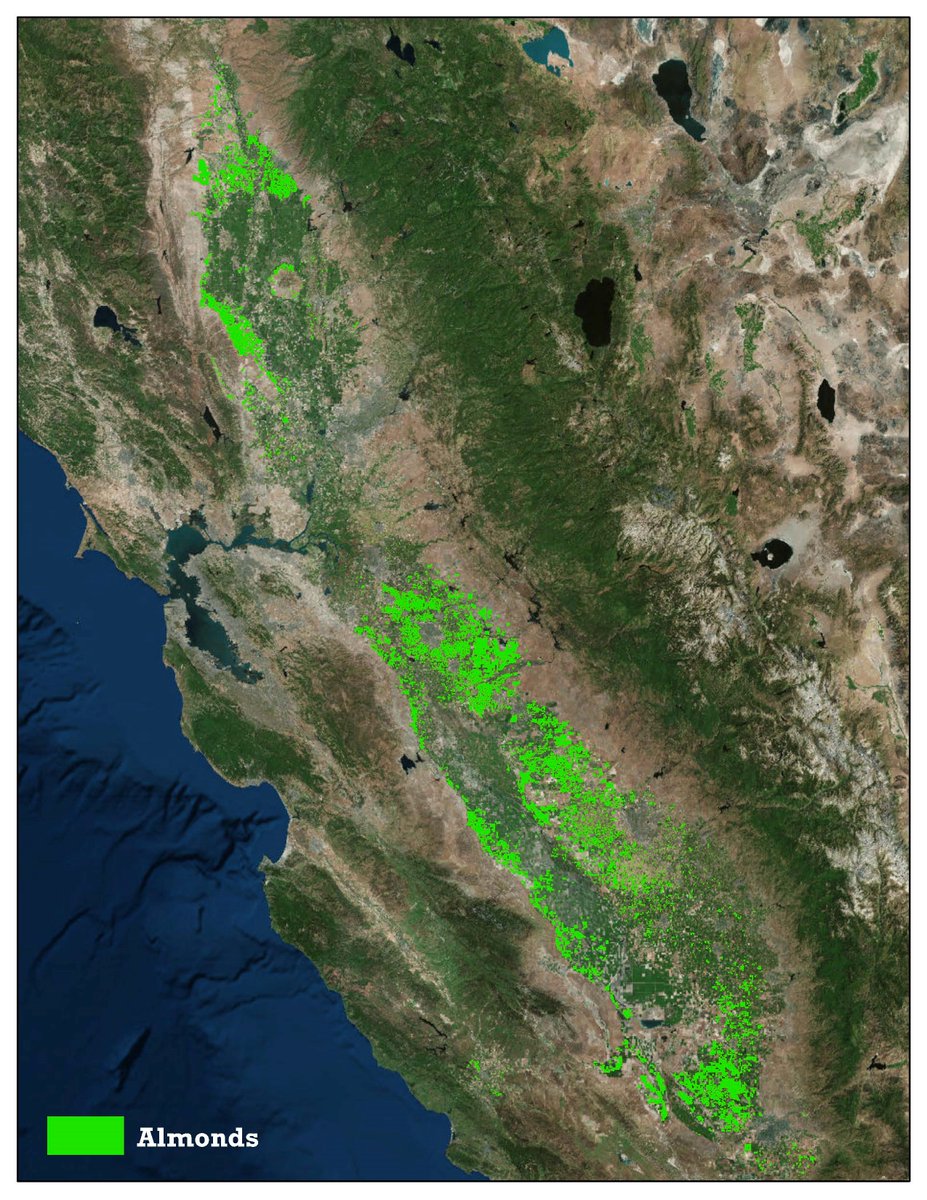
Insane stat of the day: California almonds use roughly 3–5.5 million acre-feet of water per year, depending on methodology.
That's ~4-7x more water than all data centers in North America used combined in 2025.
1,085
1,123
6,272
3,123,303
May 20
I'm a big investing geek so it is a real treat to talk shop with @PeterJ_Walker. We geeked out on hot seed deals, AI, solo founders, liquidity, and when founders should quit.
Here's the longer breakdown:
The seed market is not uniformly hot. Peter’s core point is that the market has really split in two: the top 5% of companies are commanding extraordinary prices, while the rest of the market feels much more like 2023 or 2024. That is a useful corrective to the lazy “venture is back” narrative.
Paying up can be rational, but only for a very specific game. If your strategy is to find the tiny handful of companies that can become truly massive private outcomes, then the priciest seed deals may actually be the right hunting ground. But Peter is clear that this is not an efficient market and most of those bets will still fail.
Liquidity is the real issue underneath almost every venture argument right now. The question is not just whether a company becomes valuable on paper, but how that paper value actually turns into cash for funds and founders. Peter’s view is that this may be more structural than cyclical, which is a much more unsettling conclusion.
Secondaries may be helping, but they are not solving the whole problem. Peter points out that so much private-market demand is concentrated in just a few names that it is still unclear whether a healthier secondary market broadens access to liquidity or simply crowds into the same superstar companies.
Series A advice is often too simplistic to be useful. The episode does a nice job dismantling the “hit X ARR and you can raise” trope. Peter’s argument is that sector differences matter, but even more importantly, investors care far more about growth, momentum, and velocity than about one static revenue threshold.
AI has made startup evaluation murkier, not cleaner. In an earlier SaaS era, revenue was a sturdier signal. Peter argues that now a company can go from $1M to $3M or $4M in revenue and still leave investors deeply unsure whether the business is durable or just temporarily ahead of a fast-moving model layer.
The venture ecosystem increasingly rewards legibility. Peter gets at a subtle but important point: “known” AI companies and consensus names do not just attract capital because they are promising; they also help managers raise their next funds. That means LP incentives can reinforce consensus behavior even when the actual return case is less obvious.
Employee equity remains widely romanticized. Peter is blunt that the modal outcome for startup equity is zero, especially for later early employees who join when the company is still risky but their ownership is already much smaller. That does not make startup jobs a bad choice, but it does mean founders should be more honest about what equity is and is not.
Solo founders deserve more respect than the market often gives them. The rise in solo-founder companies is one of the more interesting empirical shifts Peter highlights. He makes the underrated point that solo founders remove one entire failure mode from the business — cofounder breakup — even if they take on more personal load in exchange.
“Never quit” is bad blanket advice. One of the sharpest sections of the episode is Peter pushing back on hustle-culture orthodoxy. His argument is not that ambition is bad; it is that many companies should be shut down sooner, and more VCs should be willing to tell founders that missing on one company does not mean failing as a person.
LP behavior may be the hidden lever behind a lot of venture’s problems. Peter says more clearly than most people do that if venture is going to change, it probably will not start with founders or GPs. It has to start with LPs, because their incentives shape fund structure, manager selection, and ultimately what kinds of bets get made.
Concentration is not the only winning strategy. Peter closes by arguing against the idea that all great venture funds must be highly concentrated. His view is that power-law outcomes can come from multiple portfolio constructions, and that especially at the earliest stages, taking more swings can be just as rational as focusing narrowly.
1
1
6
536
May 18
WGMI!
1
4
735
May 15
Uber's pricing journey is a good proxy for Anthropic and OpenAI, both of which have massive latent pricing power. Uber's early critics said that demand would melt once they stopped subsidizing rides and yet, despite take rates increasing from 20% to 30% in the 8 years since the IPO, trips on Uber have almost tripled.
No stake in Uber, Anthropic, or OpenAI. I just think investors are seriously underestimating the frontier AI labs' pricing power.
May 15

the shift to programmatic plans make sense esp on the road to ipo.
uber couldn’t subsidize rides forever.
1
9
1,534
May 8
Just recorded a banger of a conversation with @PeterJ_Walker about seed valuations, liquidity, solo founders, and knowing when to quit. Drops Wednesday on @InvestNStartups.
1
6
320
Joe Magyer retweeted

May 7
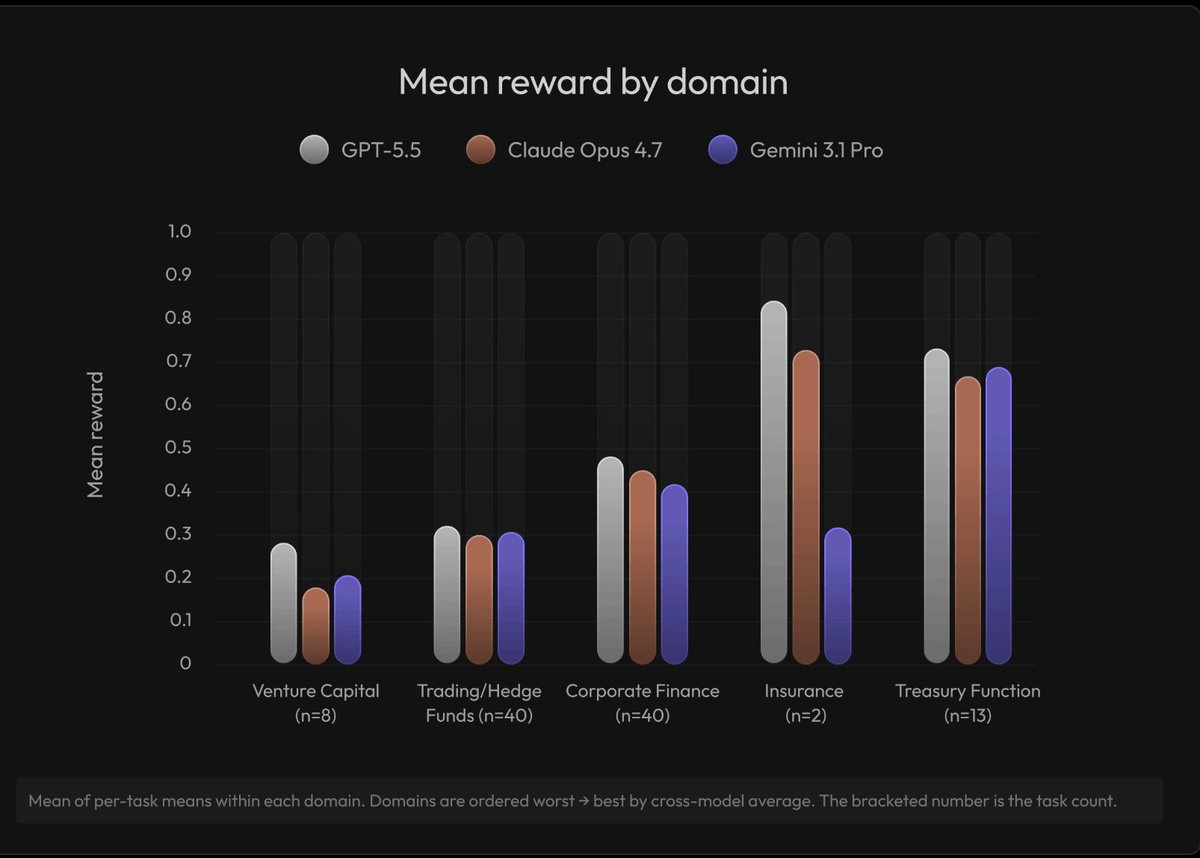
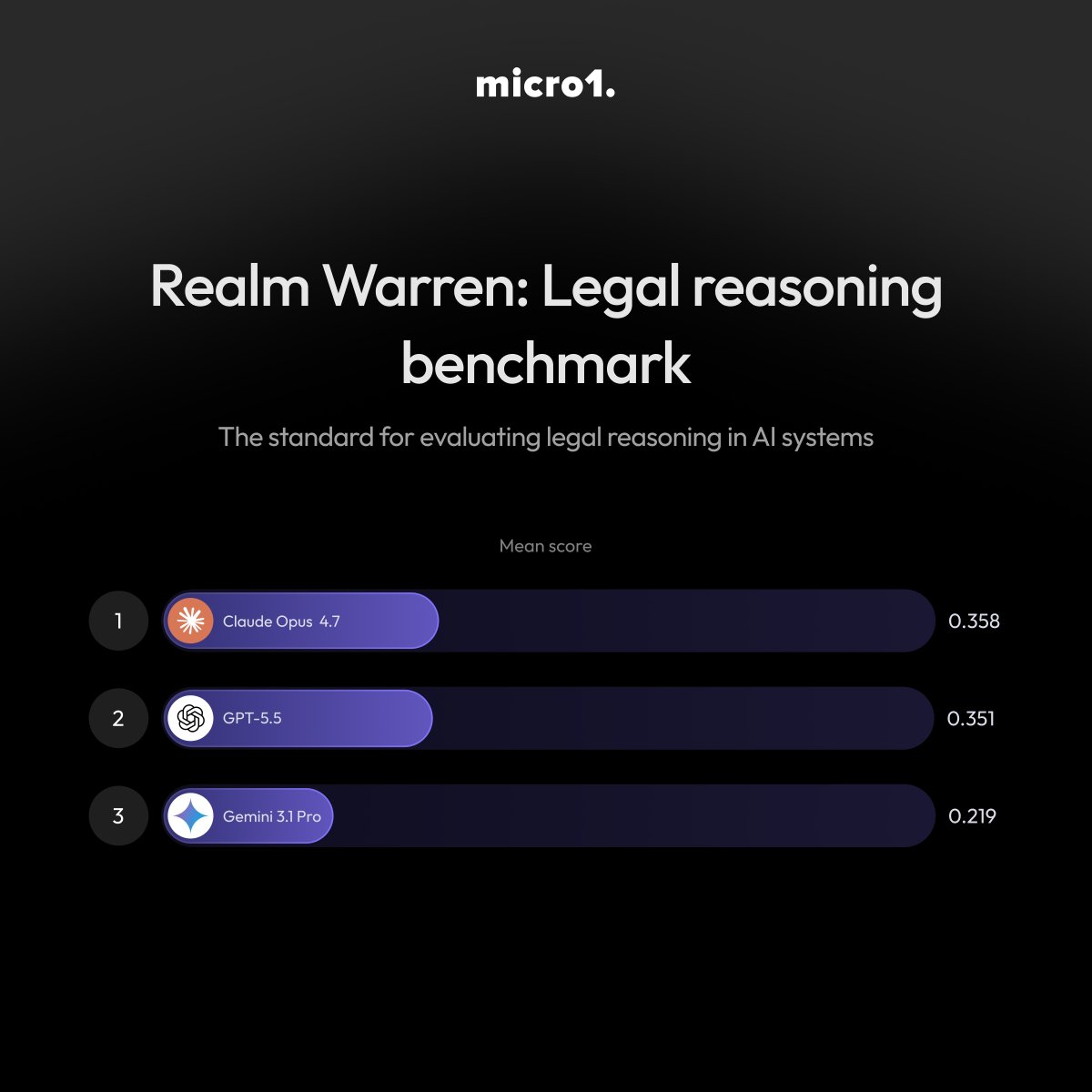
Today we’re releasing Realm Warren, part of the Realm benchmark series for measuring frontier AI models on real-world expert workflows.
Each task tests whether a model can produce a legal work product and adapt it as circumstances evolve. We evaluated Claude Opus 4.7, GPT-5.5, and Gemini 3.1 Pro across federal and state law, scored through IRAC: issue spotting, rule identification, factual application, and legal conclusion.
Here’s the results (mean score):
-Claude Opus 4.7: 0.358
-GPT-5.5: 0.351
-Gemini 3.1 Pro: 0.219
The sub-40% result shows where models break down on long-horizon legal work. Three failure modes drive it: the IRAC chain breaks after issue spotting, models front-load their effort and fail to revise, and skipping visual exhibits leads to invented facts.
Full report linked in the comments.
4
14
50
3,495