
124 Photos and videos

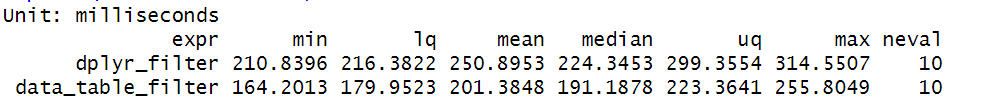











40
When you realize data.table is not just fast…
but also lets you:
- filter like a ninja
- group like a boss
- update in place like magic
- chain like you're riding 🚲 downhill
And all with [i, j, by].
Name a tidier feeling. I’ll wait.
#rstats #datatable
33
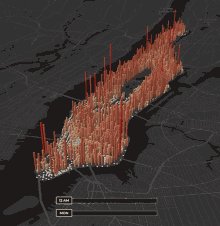
I took a photo of a USAID nutrition pack. Nothing weird… until I looked closer.
The image had hidden GPS data.
Using Python, I pulled the coordinates and put a pin on the map.
What I found was… strange.
Should foreign aid be ending up here? 👇
ALT An USAID nutrition pack in the right place? Is this evidence of fraud?
1
62
I broke down how to extract location data from any image — and revealed the exact location of this USAID pack.
🧭 Want to see where it was taken?
📍Check the map story here:
marsja.se/how-to-extract-gps…
Should it be there? Let me know!
3/3
45
✅ Fast, readable, and works beautifully with large datasets.
🔗 Full #Rstats tutorial with examples:
marsja.se/how-to-sum-multipl…
15
Filtering large datasets in R? You might be using dplyr::filter(), but there's a faster way. 🚀 Let's compare dplyr and data.table for big data filtering. 👇 #rstats #DataScience
1
1
2
160
Want to learn how to filter using data.table? Check out our full post here: marsja.se/how-to-filter-in-d…
#Dtascience #Rstats
33
How to Select Columns from data.table in #R marsja.se/how-to-select-colu… via @MarsjaSe #rstats #datascience
1
36
Mediation Analysis in Rstats: How to Run it with two Packages marsja.se/mediation-analysis… via @MarsjaSe #r
46