
Joined June 2020
- Tweets 10,405
- Following 391
- Followers 8,919
- Likes 17,722
634 Photos and videos










Jun 13
I oppose this completely.
We should not allow technological progress to be held hostage by capricious and foolish government officials. I hope that the US government loses the power to impose these sorts of controls in the first place.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
5
3
125
7,178
Jun 13
It gives me no pleasure to know that this directive was applied to a company that openly advocated for similar forms of export restrictions. I don't care much about the irony. I care far more about how the action seems unjustified and sets a horrible regulatory precedent.
2
29
988
Matthew Barnett retweeted

Jun 1
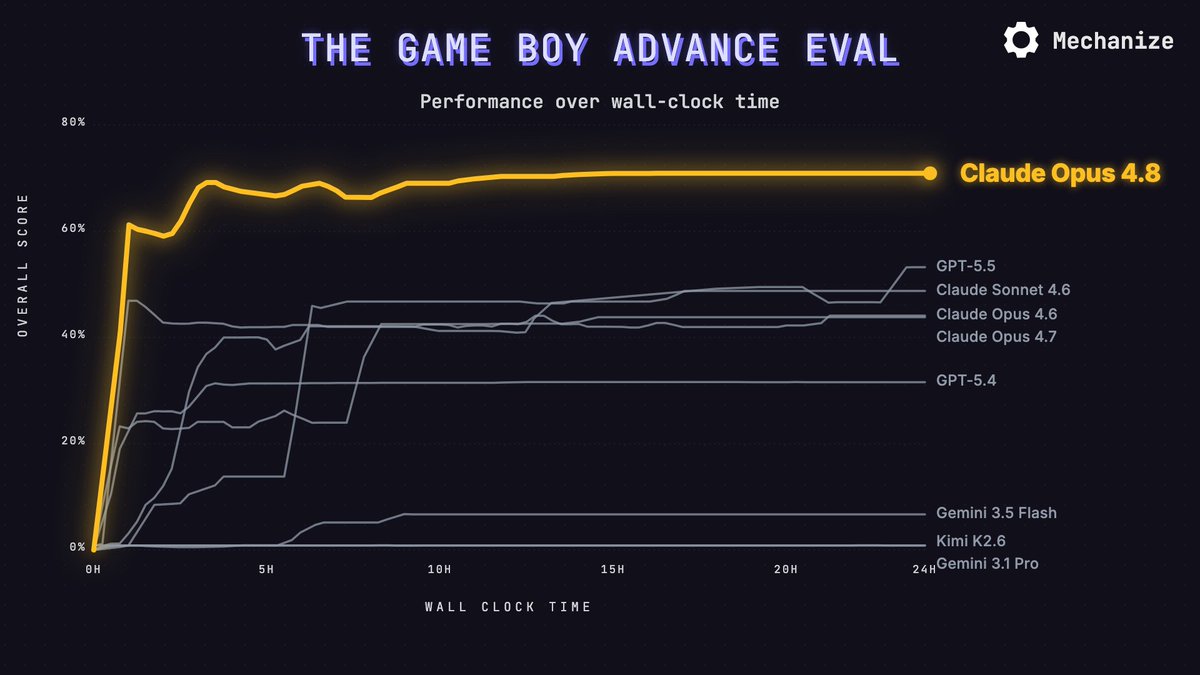
Claude Opus 4.8 scores 70.9% on GBA Eval, the top score to date. Given 24 hours, it writes an emulator that plays most games, with working audio on all of them. It beats the previous best (GPT-5.5 at 53.2%) in under an hour.
May 14

We gave frontier AI coding agents 24 hours to write a complete Game Boy Advance emulator from scratch.
GPT-5.5's emulator runs games best, with Claude Sonnet 4.6 and Opus 4.7 close behind. Gemini 3.1 Pro failed to produce a working emulator.
2
11
115
23,307
May 25
To be clear, I'm not sure whether current AI could pass this test. However, I think this prediction is on track to be falsified, even if not yet.
It's also how he operationalized a key premise in his AI doom argument with Bryan Caplan, so I think it's worth evaluating.
May 23

To assess whether Eliezer Yudkowsky is calibrated on AI doom, it seems relevant that in 2016 he said he'd be "pretty shocked" if an AI could pass an unrestricted one-hour Turing test before the end of the world.
4
31
3,866
Matthew Barnett retweeted

May 24
Why would we deprive today's teens of our era's greatest source of information and support?
I'm guessing many Ant researchers greatly benefited from the internet as teenagers.
Growing up in the countryside in difficult family circumstances, I would have never become passionate about programming without it.

Anthropic Doesn't Allow Kids Under 18 — Here's Why
"We just don't know enough about what AI is going to do to kids. It needs to be done with an adult in the room. It needs to be done with a human in the loop." — @DanielaAmodei
12
15
134
11,160
May 23
In 2002, Ray Kurzweil and Mitchell Kapor made a bet on whether the Turing Test would be passed by 2029.
To determine the winner, they devised detailed terms, including the appointment of a committee to administer an actual exam, with a set of judges and human foils.
6
4
249
34,712
May 23
To assess whether Eliezer Yudkowsky is calibrated on AI doom, it seems relevant that in 2016 he said he'd be "pretty shocked" if an AI could pass an unrestricted one-hour Turing test before the end of the world.
56
16
405
79,191
May 23
To be clear, I'm not sure if current AI could actually pass this test. A lot hinges on how such a test is conducted. I do think the prediction will ultimately end up being wrong though.
5
643
Matthew Barnett retweeted

May 14
Very important update from UK AISI. This is a meaningful change from the previous report. Here’s what the new data would look like for “Mythos Preview (new)” with $ on the x-axis:


Our cyber range results illustrate this step-up. Since our first Mythos evaluation, we received access to a newer Mythos Preview checkpoint. On a 32-step corporate network attack we estimate takes a human expert ~20 hours, this checkpoint completes the full attack in 6 /10 attempts.
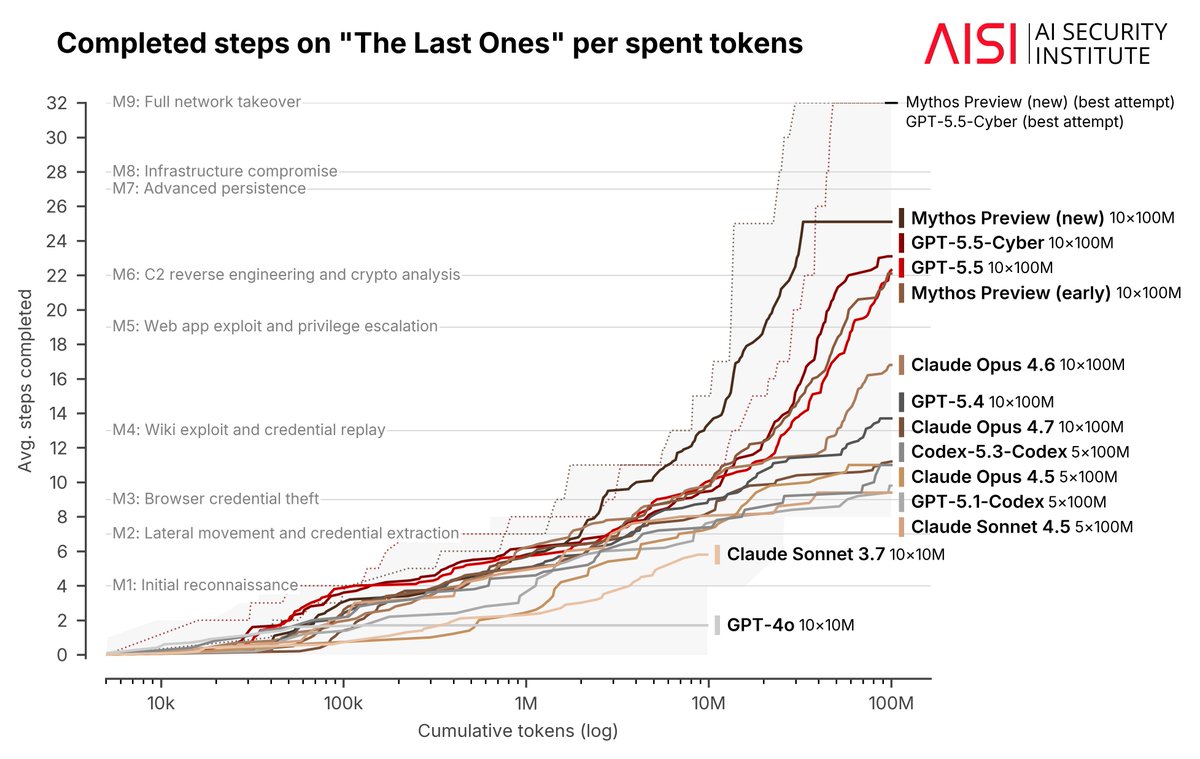
3
13
178
79,232
Matthew Barnett retweeted
May 14
We gave frontier AI coding agents 24 hours to write a complete Game Boy Advance emulator from scratch.
GPT-5.5's emulator runs games best, with Claude Sonnet 4.6 and Opus 4.7 close behind. Gemini 3.1 Pro failed to produce a working emulator.
13
34
369
94,567
May 10
A bigger problem than people making confidently wrong predictions with no social penalty is people making confident but *vague* predictions that can always be reinterpreted in hindsight, and so are never proven wrong. Once you realize this, you'll start seeing it everywhere.
10
3
67
5,181
May 10
I don't think Claude Mythos is just marketing hype. It's clearly a flagship model, and coding ability has improved a lot this past year.
But I highly doubt we're on the brink of a cyber catastrophe, e.g., >$300B in losses from a single attack or campaign within a year.

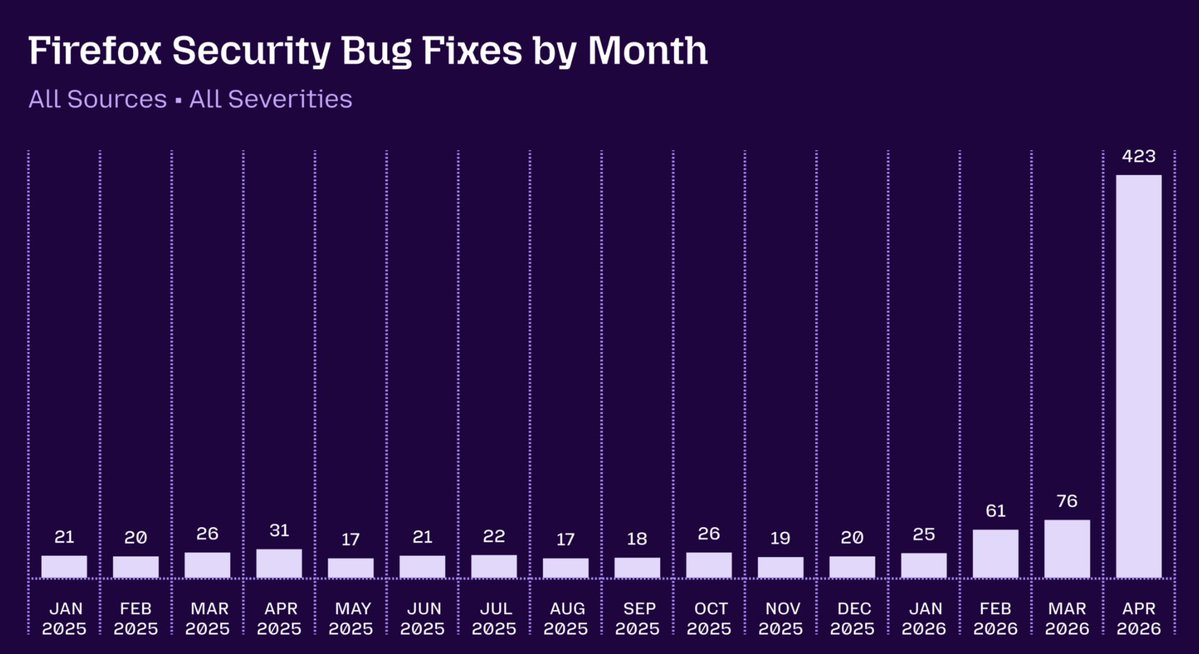
16
71
11,461
May 5
Some people are being way too alarmist about Mythos.
80,000 Hours called Mythos "an AI that can break into almost any computer on Earth". Zvi Mowshowitz said, "If given to anyone with a credit card, Claude Mythos would give attackers a cornucopia of zero-day exploits for essentially all the software on Earth".
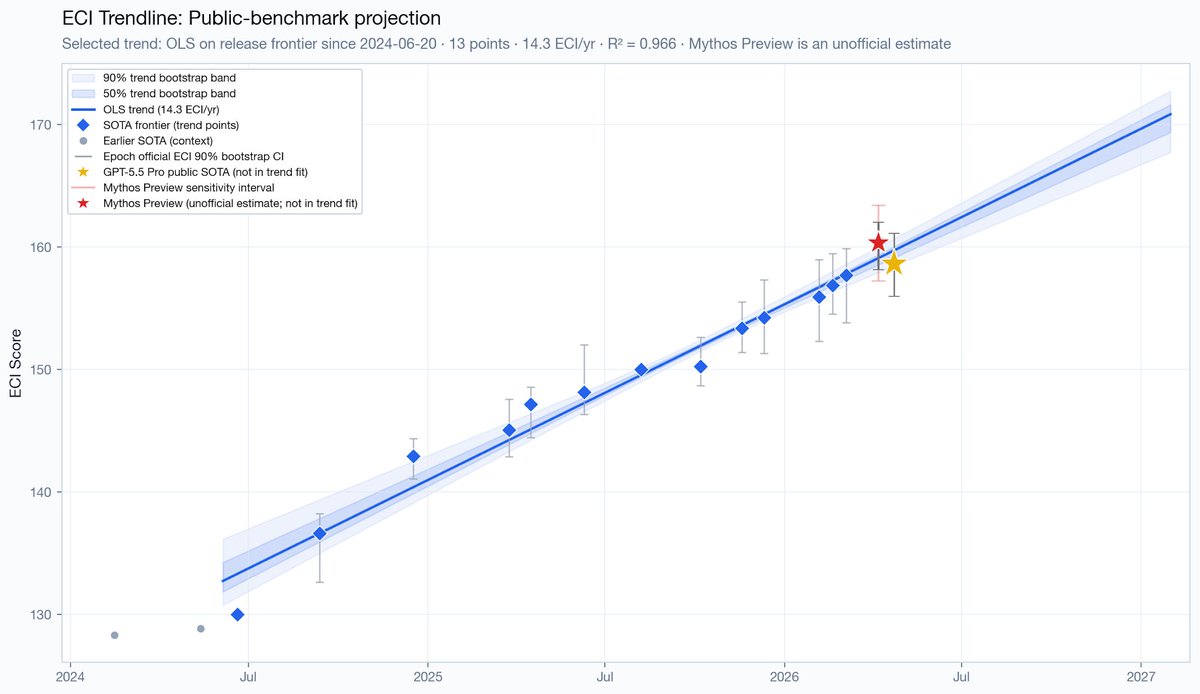
But these descriptions are unfounded. @natalia__coelho shows in her latest blog post that the cyber capabilities of Mythos are nearly tied with GPT-5.5, across practically every public benchmark we have available. This includes both narrow and broad cyber evaluations. It is not way ahead of trend.
The same holds for general capability evaluations. Except for a somewhat impressive score on SWE-bench Pro, Claude Mythos is nearly on-trend, at most a few months ahead. In other words, it's barely better than models that millions of people already have access to.
It's an impressive model, but I'm very skeptical that Mythos is going to take down our digital infrastructure or cause a cyber catastrophe.

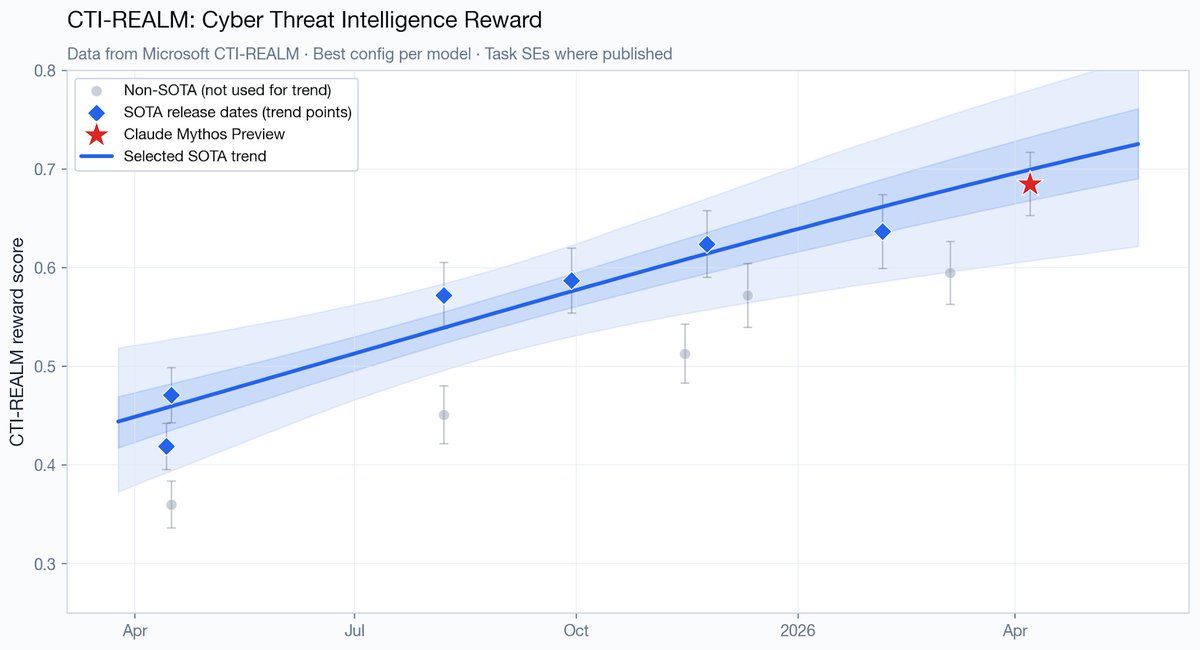

31
50
463
135,565
May 5
See here: x.com/i/status/2051713488872…
May 5
Read the post here: open.substack.com/pub/pointe…
2
7
5,233
May 5
This analysis contradicts the public narrative surrounding Mythos. Yet will its findings become widely known?
May 5
New post from @natalia__coelho on Mythos. She analyzes its capabilities using publicly reported benchmark results to determine whether the model represents a large, trend-deviating jump in performance. She concludes it's basically in line with past trends, or at most a bit ahead.
2
13
2,515
May 5
New post from @natalia__coelho on Mythos. She analyzes its capabilities using publicly reported benchmark results to determine whether the model represents a large, trend-deviating jump in performance. She concludes it's basically in line with past trends, or at most a bit ahead.
5
11
100
25,654
Matthew Barnett retweeted
Apr 24
We've raised $9.1 million at a $500 million post-money valuation from Marco Mascorro, Adam D'Angelo, and Devendra Chaplot.
41
19
874
578,509