
agi is here but it got an email job
Joined August 2025
- Tweets 3,077
- Following 969
- Followers 260
- Likes 10,915
49 Photos and videos







Pinned Tweet

7 Nov 2025
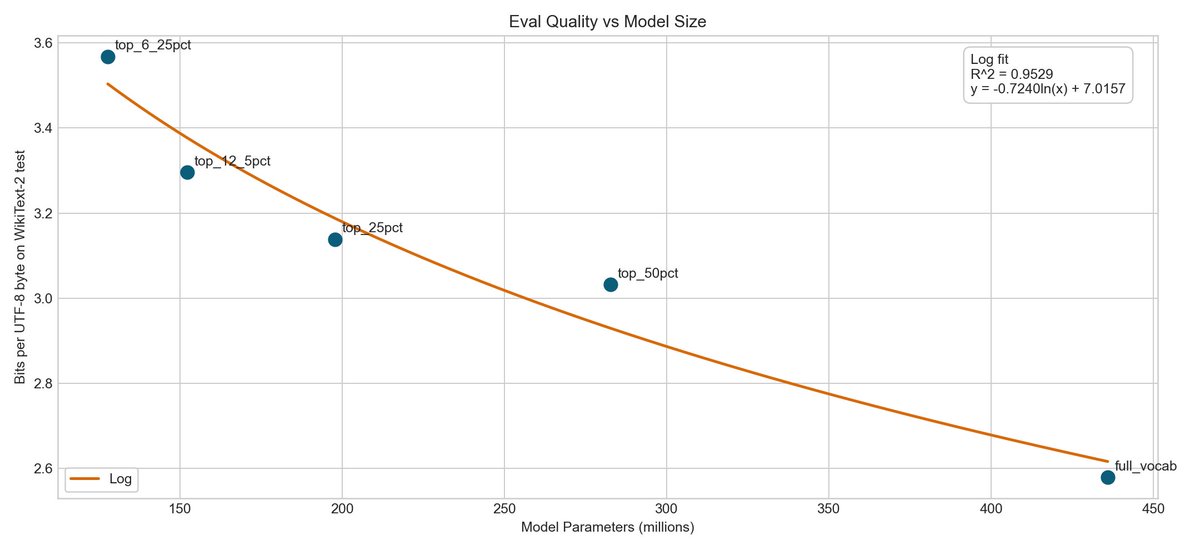
Personalized Arxiv feed
I built a system that allows you to create a personalized feed or search over recent listings. I use a two tower architecture with a preference model and a re-ranker.
uror.io
4 Nov 2025

Got a nice kick in the butt yesterday to do something I've been putting off.
Re-ranker for Arxiv articles is trained and ~industry standard
3
1
18
3,029
Jun 13
Potential soft pause which makes the new frontier price (if status quo holds)

So does this mean no one can ever release a model better than Fable now, lest they get banned/regulated.
At the same time, you can’t really release a model and show that it loses to an existing model on all benchmarks…
1
116
Jun 13
x.com/i/status/2065651072836…
But likely doesn't last long tbh
Jun 13

Parsing this evening's events:
- The U.S. government approved the release of Fable 5 to the public, clearly under the presumption that the model's cybersecurity capabilities cannot be accessed by hackers, authoritarian regimes, etc.
- Recently (today?), "another company" showed the U.S. government that a jailbreak of Fable 5 *is possible*. Yes, a minor jailbreak - but how can a non-technical government official be assured that there aren't also other, more dangerous, jailbreaks in this model that won't be discovered by the CCP?
- Anthropic states, completely correctly, that: "We suspect that perfect jailbreak resistance is not currently possible for any model provider. Every safeguard used in the industry is vulnerable to non-universal jailbreaks (which can elicit some cyber information in specific circumstances), and it is likely that universal jailbreaks will eventually be found in the future. We stated this clearly when we released Fable 5."
- My best guess is that the U.S. government did not fully realize this at the time when the release of Fable 5 was approved.
- Per Axios, the government contacted Anthropic and asked to "pause releasing the... models but was unsuccessful" - i.e., Anthropic told the government to pound sand.
- Per Axios, this "prompt[ed] the export control letter".
- Per Axios, the U.S. government is *NOT* looking to restrict access to Fable to U.S. nationals forever. "The model needs to remain locked down until the U.S. governent's national security apparatus is hardened", which "could happen in a few weeks".
- I interpret Anthropic's reaction as challenging the government: "we believe the government should have the ability to block unsafe deployments, as part of a statutory process that is transparent, fair, clear, and grounded in technical facts. This action does not adhere to those principles."
If the Axios article is correct, I do not think any other model providers have anything to fear based solely on this evening's events, because: (1) they would hopefully be smarter than downright rejecting a request by the U.S. government to pause releasing a model, and (2) they will be required anyway under the recent executive order to give the U.S. government at least 30 days to test the model for cybersecurity capabilities - during which time the U.S. government would also be able to shore up its own cybersecurity defenses with the same model.
I remain extremely concerned that actions by one particular U.S. lab over the last few months might be moving us closer and closer to the scenario where at least that lab - and potentially all others - will be nationalized.

1
95
Jun 9
I don't think its me. Codex has been more proactive which is bad for engineering but good for 'car guy' agentic users. I find it constantly reaching for something to do. reaching for the most hyper engineered solution. I don't want this.
there is a tension in agent systems around the idea of motion. consumers want to feel like things are getting done. they want to be moving and moving fast. Codex had gone too far in following directions exactly. now it has gone too far in moving without direction but with assumptions.
1
48
Jun 8
Codex side chats is how interactivity evolves. You don't need real time if you can spin up another instance with full access to the original models outputs. The UI and mechanisms need work but I could see an RLM formalization appear in this direction
3
27
Matt retweeted

Jun 7
We are releasing a fully reproducible early preprint of "Prism: Unlocking Language Model Capability Extraction".
A trained language model knows many things at once, but deployment usually asks for one behavior at a time. Enterprise scenarios often have few products, workflows, features, or use-cases matter disproportionately.
Prism asks and answers a simple question - "Is it possible to isolate and deploy only capabilities that are driven by Pareto principle and cut down costs by a huge margin while preserving most of the performance?"
This paper discusses a novel approach to efficiency, understanding model behavior and opens up capability extraction.

21
40
211
21,967
Jun 6
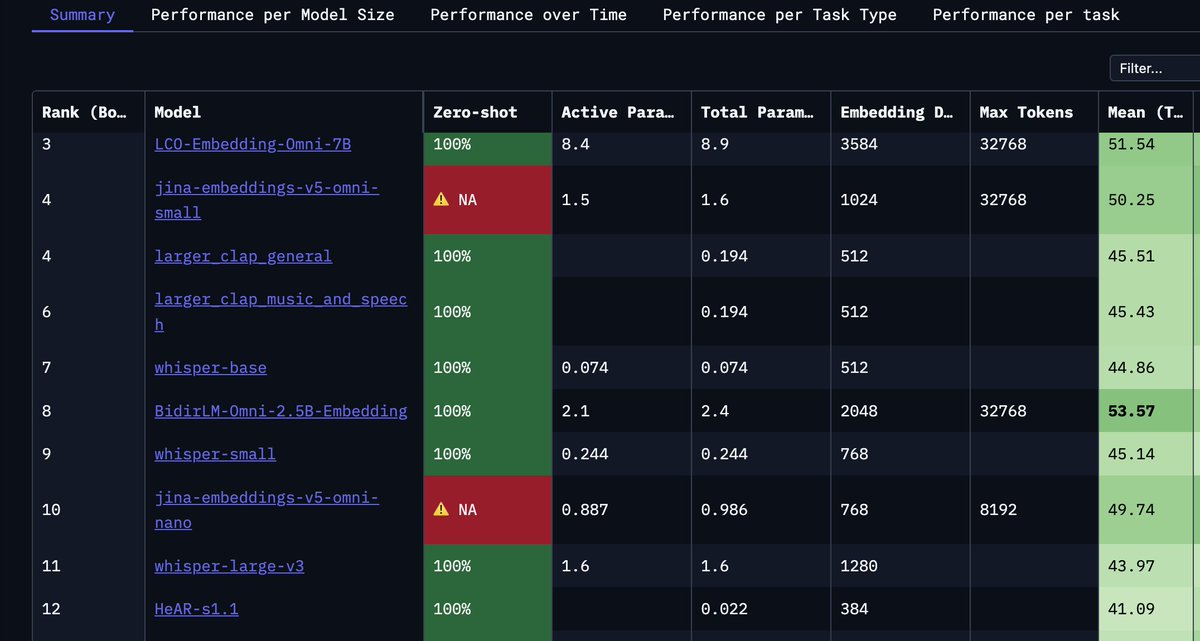
Finally got my hear-s1.1 model on the MTEB leaderboard (audio only) and it ranks 12th overall!
hear-s is only 22m parameters and is pareto frontier in audio encoding
1
8
595
Jun 6
I trained it for a hackathon (which I lost) but it's an interesting example because in open source niche you can fairly easily get to the pareto frontier
1
32
Jun 6
I've found a lot of signal in the finephrase work
Jun 6

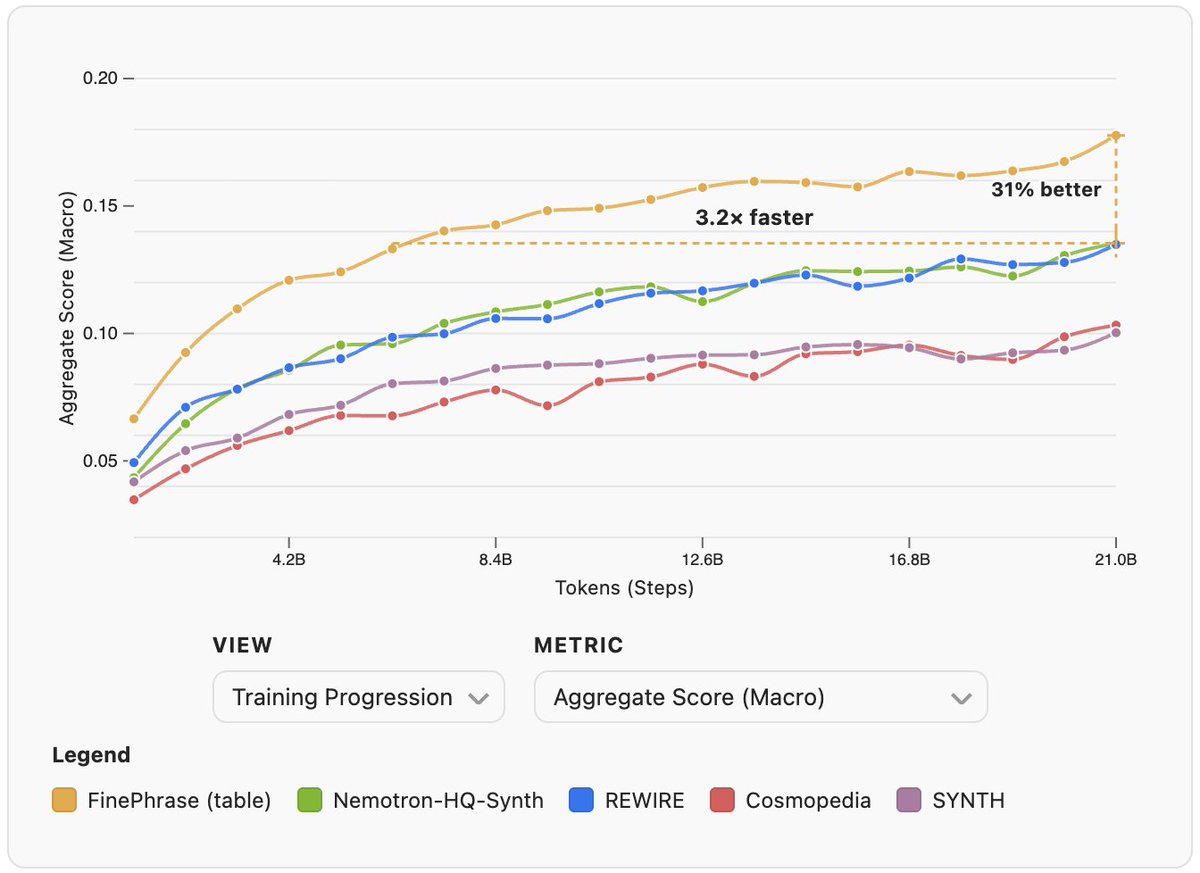
New FinePhrase result: the best synthetic-to-real ratio for pretraining isn't 50/50.
Quick context: FinePhrase is our open 486B-token synthetic pretraining dataset. We take FineWeb-Edu web text, rephrase it with a small 1.7B model (SmolLM2) into four structured formats (FAQs, math problems, tables, tutorials), and then train on a mix of original and synthetic data. The whole recipe came out of 90 controlled pretraining experiments.
The new question we tackled: how much of that mix should actually be synthetic? We swept the synthetic fraction from 10% to 90% for each format. Every format's optimum sits higher than the uniform 50/50, and it's format-dependent: tables peak at 70% synthetic, math at 80%, FAQ and tutorials at 60%. The curves climb to their peak and then plateau rather than collapsing, so there's a wide safe band and no sign of the "too much synthetic = model collapse" failure mode.
This also sets a new state of the art among synthetic pretraining data. Our best config (tables at 70% synthetic) is 31% better and reaches the same quality 3.2x faster than REWIRE, the strongest rephrasing baseline, which used a 70B-parameter model. We get there with a 1.7B rephraser that also generates tokens roughly 30x cheaper.
A caveat: these results are at small scale (1.7B parameters, 21B training tokens) so might not transfer to larger training runs.
Read the updated playbook: huggingface.co/spaces/Huggin…

1
410
Jun 5
"GPUs of the AI, by the AI, for the AI, shall not perish from the Datacenter."
Abraham Lincoln
25
Jun 4
Some interesting claims

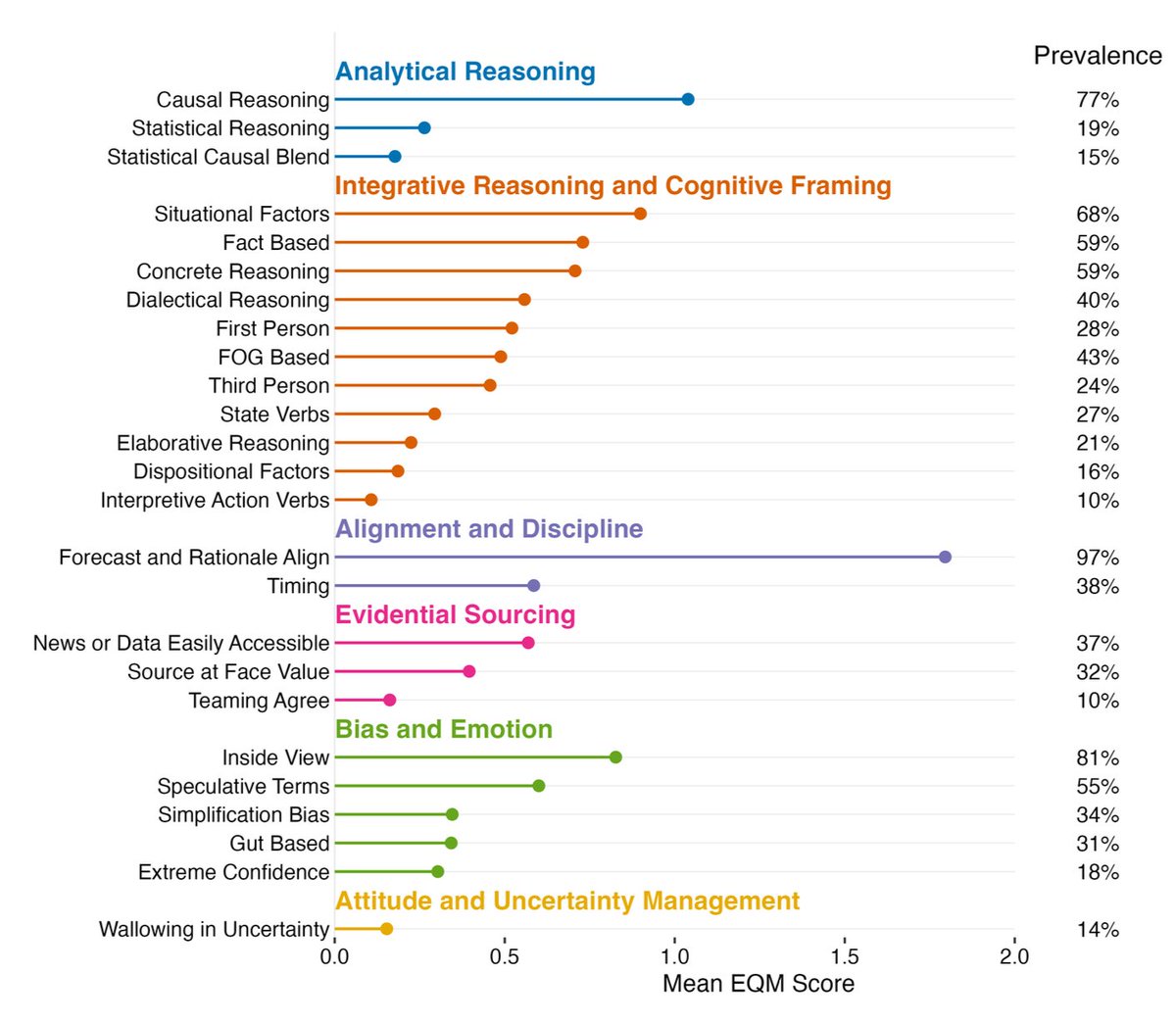
Is it possible to spot a good forecast by its rationale?
We used LLMs to score the reasoning behind 55,000 forecasts and test the link between forecast accuracy and written rationales.
We found that:
• Causal reasoning is much more prevalent than statistical argumentation
• It's easier to identify poor forecasters rather than excellent ones
• Human ratings of rationale quality can be unreliable.
🧵A thread on the results:
88
Jun 2
this is pretty neat
Jun 2

By now, everyone knows that single-vector embedding models are hugely limiting for modern workflows.
But they contain than you think: you can extract sparse Latent Terms from them.
And it turns out that BM25 is all you need to turn this vocabulary into a strong retriever.
1
79
Jun 2
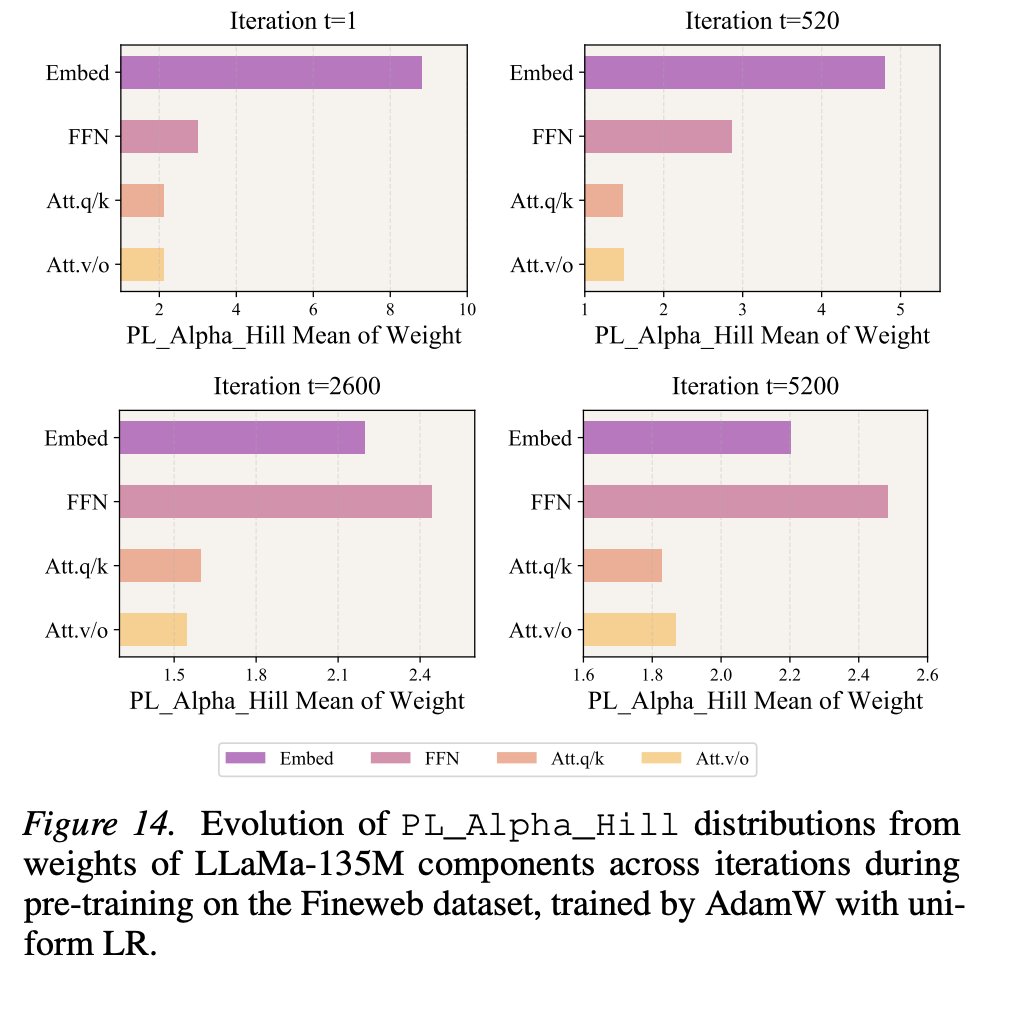
I've been coming back to arxiv.org/abs/2605.22297 because it rightfully points out that each layer may need different learning rates than a singular global rate. However, most of the reported impact might just be early embedded learning. If you smash Embed early and decay it to FFN over like 20% of your training and don't change the other layer LRs from the initial computation then it looks like you might get the same effect with no need to recalculate LRs during training.
However this is interesting because you can generally estimate a global LR using hessian/critical curvature so you should be able to estimate layerwise now as well. If you're not pretraining you likely don't need to hit embedding so hard either which makes this very interesting to pursue a data-model method for LR determination without hyperparameter tuning.
1
1
159
Jun 1
really interesting. if the reasoning could be done in parallel then this can likely learn it

We unlocked the working memory of LLMs 💥
Reasoning in Memory (RiM) replaces autoregressive "thinking out loud" with fixed memory blocks that form a task-specific workspace for latent reasoning.
The key idea is simple: reasoning should happen inside the LLM, not in its output!
2
87
May 29
Why isn't ES as popular as RL? infra appears to be a big answer.
If you look at async then you can get up to like 85% inference load. With clever ES you can get up over 95%. But there's no big ES libraries which is partly because of the social cascade of RL. They also find different signals.
If you combine all those ideas then the 10% isn't compelling to earn attention and I bet isn't widely known. So you get engineering applied more focused on RL
2
1
1,100
May 27
This is where you end up in these types of games. There's a reward/effort curve and you just need to make the effort enough. The bars not high.
It's still interesting that there isn't much demand outside of cheating for non-slop yet.
May 27

if a student fine tunes their own open source LLM, then they deserve it
1
89
May 26
"You waste years by not being able to waste hours." except its days because I didn't check the AI's work
2
43