
Sparse and efficient • Deus eXperiments • 🇮🇳
Joined July 2014
- Tweets 13,885
- Following 925
- Followers 12,170
- Likes 49,326
1,897 Photos and videos









Pinned Tweet

Jun 7
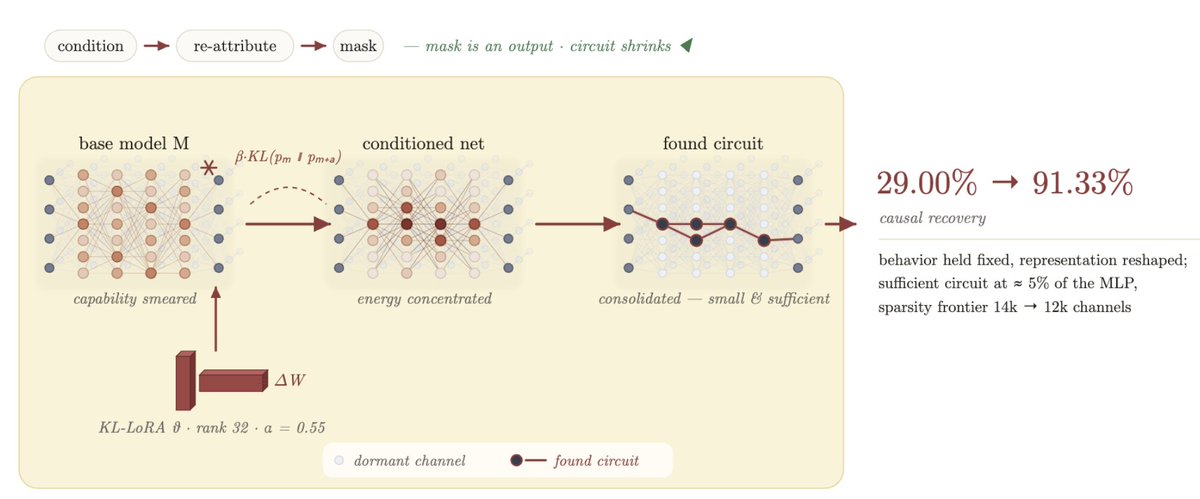
We are releasing a fully reproducible early preprint of "Prism: Unlocking Language Model Capability Extraction".
A trained language model knows many things at once, but deployment usually asks for one behavior at a time. Enterprise scenarios often have few products, workflows, features, or use-cases matter disproportionately.
Prism asks and answers a simple question - "Is it possible to isolate and deploy only capabilities that are driven by Pareto principle and cut down costs by a huge margin while preserving most of the performance?"
This paper discusses a novel approach to efficiency, understanding model behavior and opens up capability extraction.
21
40
210
21,694
i wanted to post an update on research progress on capability extraction today but i just keep on improving it every day so yall just have to wait until i hit a short plateau.
2
12
421
Jun 13
i actually do not care about Fable, it underperformed in my agentic silkroad that weaves my business, research, knowledge gathering/harvesting completely.
if you try taking gpt 5.5 xhigh away, that is when I turn into the Joker.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
6
3
70
3,652
Jun 11
tune your hparams hard.
RNGesus is waiting for you in the loss valley somewhere.
Jun 11

I just submitted a PR to modded-nanogpt with better hyperparams. With them, Muon can reach the target loss after 3250 steps instead of 3325.
Always tune your baseline well when doing research. Weak baselines can make any idea look promising
1
1
24
3,760
Jun 11
we nearly do not have enough bounties and hack leaderboards for the AI-human collab era we live in.
we need oai parameter golf like problems but 100x and every problem that gets solved, leads to a snowball.
too much agent lottery, not enough recognition for creativity.
1
3
32
1,094

Jun 10
oai does not need anything from anthropic and vice versa.
it is the chinese companies/emerging neolabs that are being barred from potentially distilling this next step of intelligence.
you, the peasant who just wants to vibe code and sip a drink, is just collateral damage.
8
70
3,209
Jun 10
is there anybody else who gets annoyed more at how lame anthropic classifiers are than actually worrying about being barred access from some category?
3
30
959
Jun 9
mythos version being 2x the price of opus means it is more like diet mythos or something.

Scoop: A neutered version of Mythos called Claude Fable is coming today. It's expensive—2x the price of Opus—but perhaps not as pricey as people might have thought from the initial Mythos pricing (5x Opus).
More on that and Apple WWDC in AI Agenda:
theinformation.com/newslette…
3
30
2,602
tokenbender retweeted

Jun 9
x dot com in 2026 is miles ahead of slopmaxxed academic peer review culture
feels like im back in the 17th century watching newton & leibniz argue via public letters
Jun 9

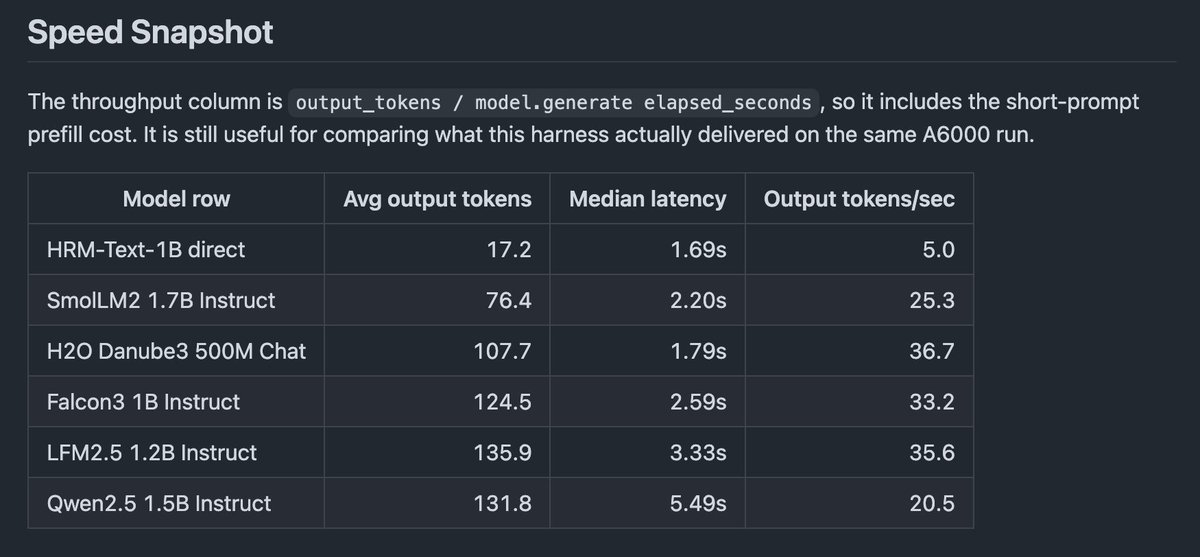
Here you go, sir. Muon is a good optimizer.
I think Keller's attempt at implementing it is great -- this primarily helped me look at why his effort produced much worse looking curve than what I could get.
This ended up being a nerdsnipe into hyper parameters, grafting, and eigh calls in the distributed shampoo package from Meta in my car ride home.
The main delta's are below:
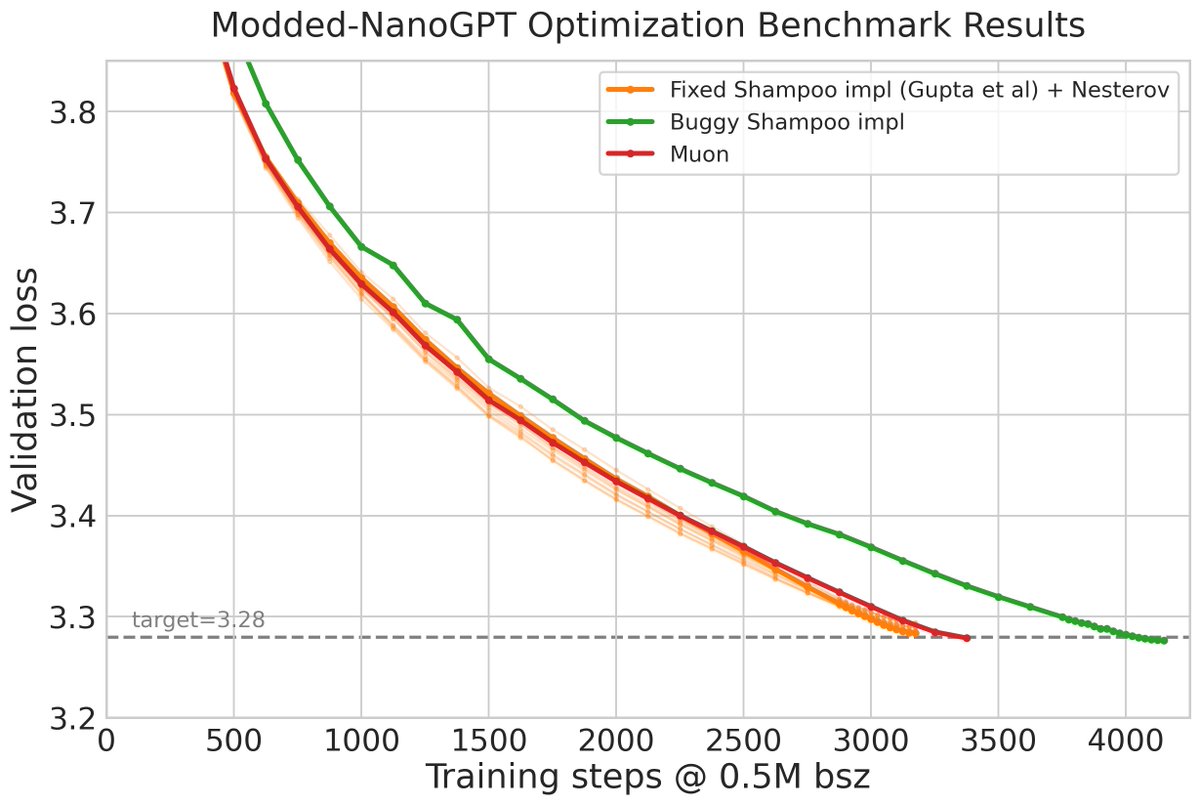
4
8
403
29,167
Jun 9
don’t listen to doom scenarios, don’t let it sap your joy.
find the juiciest problem you can within your means and wage war on it as jf every wish was granted.
2
2
22
578
Jun 9
more than half of the year has passed and everything here seems to on-trend.
everything except last 2 points, let's see how does the rest of the year go.
1
30
1,404
Jun 9
we need more ai architecture beefs.
Jun 9

Thank you for this result! Here's one initial correction:
In this post, Rohan states that I made an attempt to implement Shampoo, and labels my Shampoo training run `Buggy shampoo impl`.
But this is incorrect: I did not implement my own version of Shampoo.
Instead -- as can be seen in the reproducible log I provided in the original post -- I used, out-of-the-box, the official DistributedShampoo implementation provided by Facebook research. This is the most commonly-used Shampoo implementation that I could find on the internet.
The extent of my use of this implementation can be seen in the few lines of code below. If there are indeed bugs in this implementation, I can safely say that they were not created by me.
The remaining mystery, for anyone interested, might naturally become something like the following - How did Rohan today achieve a significantly better result compared to the official 2022-era DistributedShampoo implementation?
I am grateful for the comments he has already made regarding the deltas between his version and the 2022 one, and I am looking forward to things becoming fully precise/detailed soon once he releases the reproducible logfiles generated by his runs.


1
1
30
2,977

why would you build something that you yourself would not use, fine-tune and perfect (whether you use AI or not).
the more you use your tool, the more of your soul it imbibes, giving it a life of its own.
this is a lesson i had to learn the hard way.
Jun 7

This is the tough lesson that a lot of people are learning the hard way
AI might have made building apps a lot easier, but it also set the barrier to entry at zero
Because anyone can do it, there is no moat left
The only edge left in the future will be sales and marketing

6
5
61
3,444
Jun 8
deep learning is scale and efficiency.
since scale has been working, the incentive to go up has been higher than trying to be clever.
as we cross the threshold where >90% current human work would be met by oss models itself and it would - then we cut cost by 1000x or more.

I think you’re wrong and there’s 1,000x efficiency gains leftover in deep learning research that could lead to much smarter faster more agentic models given the same inputs
1
25
1,684

this is great btw, because it aligns with the understanding that:
- it's easy to notice that in both SFT and even during RL, gradient updates get sparser the longer the training gets, meaning we don't update the weights with exact knowledge of what is "wrong" or "missing", so we waste a lot of computation here
- we have so many OSS models already, a lot with shared knowledge or unique ones in their weights, why not just find a way beyond model merging to deeply understand the way knowledge is stored and extract that and stack it in a cheaper way inside a single model?
if done properly, at one point we wouldn't even need to pretrain anymore
Jun 7

Our future work aims to extend it further to more complex use cases and behaviors and create a new axis for model efficiency that can be stacked over existing methods with minimal loss.
Code - github.com/e-xperiments/pris…
Paper - github.com/e-xperiments/pris…
1
15
2,495
tokenbender retweeted

Jun 7
have been working on this with @tokenbender for the past two months
PLEASE CHECK IT OUT.
it so fucking cool you can litterally extract capabilites and run them on a fraction of the model. will write a blog on everything i learnt working with token and on this challenging problem soon

Jun 7
We are releasing a fully reproducible early preprint of "Prism: Unlocking Language Model Capability Extraction".
A trained language model knows many things at once, but deployment usually asks for one behavior at a time. Enterprise scenarios often have few products, workflows, features, or use-cases matter disproportionately.
Prism asks and answers a simple question - "Is it possible to isolate and deploy only capabilities that are driven by Pareto principle and cut down costs by a huge margin while preserving most of the performance?"
This paper discusses a novel approach to efficiency, understanding model behavior and opens up capability extraction.
3
6
39
4,050
Jun 7
We are releasing a fully reproducible early preprint of "Prism: Unlocking Language Model Capability Extraction".
A trained language model knows many things at once, but deployment usually asks for one behavior at a time. Enterprise scenarios often have few products, workflows, features, or use-cases matter disproportionately.
Prism asks and answers a simple question - "Is it possible to isolate and deploy only capabilities that are driven by Pareto principle and cut down costs by a huge margin while preserving most of the performance?"
This paper discusses a novel approach to efficiency, understanding model behavior and opens up capability extraction.
21
40
210
21,694
Jun 7
In the one month since then, we cracked how to isolate function calling capabilities on 8B scale. On Qwen3-8B BFCL, raw recovery at the 36.2 percent substrate was 19.1 percent. With the right post-attribution objective, recovery rose to 84.6 percent at the same channel budget.
1
1
15
811
Jun 7
Our future work aims to extend it further to more complex use cases and behaviors and create a new axis for model efficiency that can be stacked over existing methods with minimal loss.
Code - github.com/e-xperiments/pris…
Paper - github.com/e-xperiments/pris…
6
28
3,784