
Local AI, LLMs, tech thinker & builder
Joined July 2022
- Tweets 294
- Following 190
- Followers 188
- Likes 119
30 Photos and videos









14h
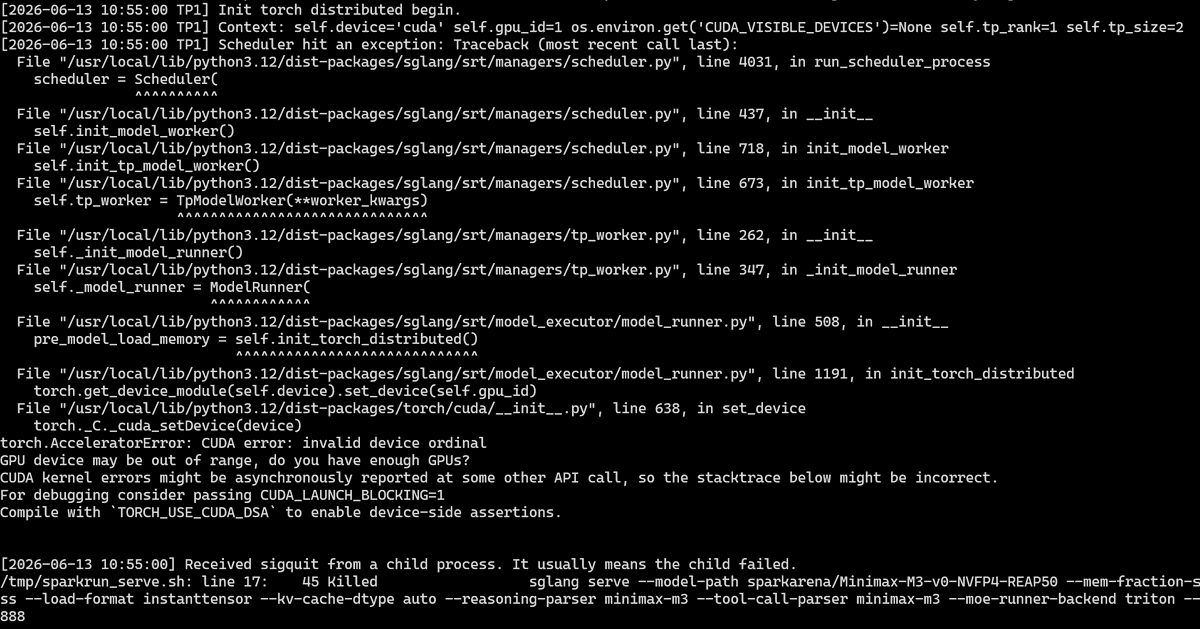
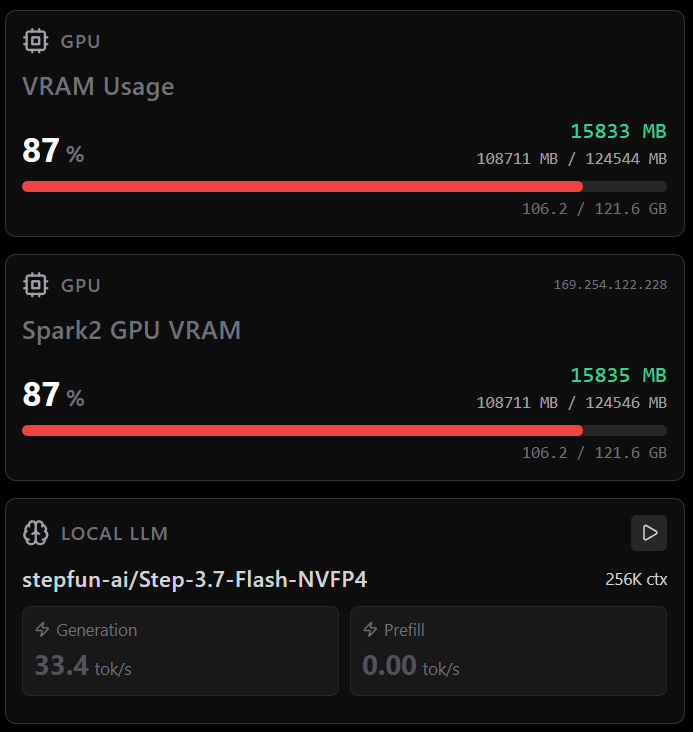
DeepSeek-v4-Flash beats Step-3.7-Flash in head-to-head tool calling benchmark.
Full results in: github.com/MiaAI-Lab/DeepSee…
9
31
2,302
15h
Local agentic 'Tool-Call Benchmark' between DeepSeek-v4-Flash to Step-3.7-Flash.
Same host, same 69 scenarios, two models.
Results:
DeepSeek-v4-Flash:
90/100 quality, 59 passed, 6 partial, 4 failed
Step-3.7-Flash:
87/100 quality, 55 passed, 10 partial, 4 failed
👇
4
1
18
1,312
15h
Bottom line:
DeepSeek-V4-Flash wins overall (90/100 vs 87/100) because it’s more reliable across long chains and structured outputs.
Step-3.7-Flash is competitive and actually safer/more disciplined in a few specific scenarios, but it drops more partials and struggles more with multi-turn execution.
1
160
16h
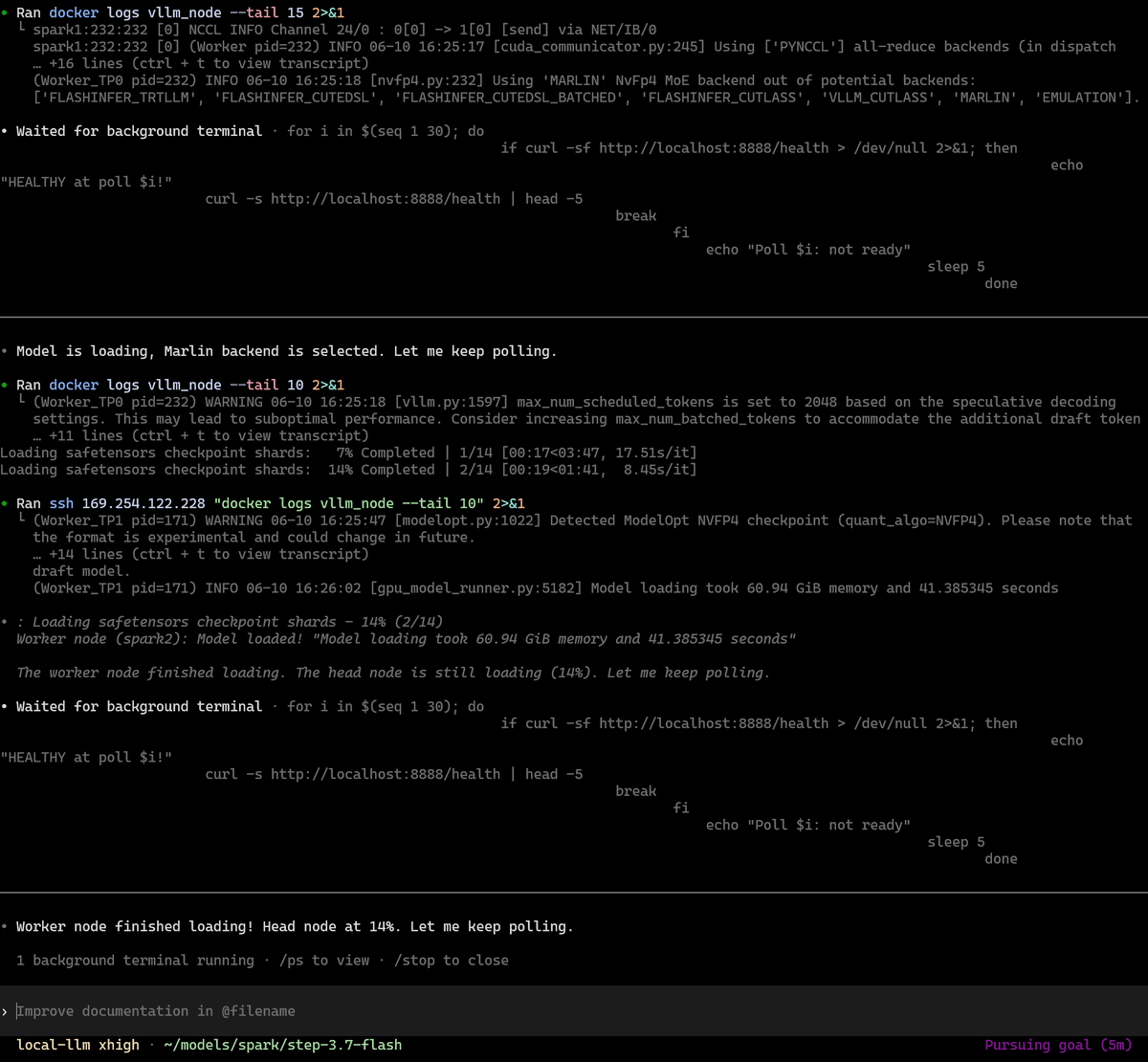
Running agentic coding benchmarks on DeepSeek-v4-Flash and Step-3.7-Flash. Will post results soon.
2
25
1,707
15h
Full results here: x.com/MiaAI_lab/status/20658…
15h

Local agentic 'Tool-Call Benchmark' between DeepSeek-v4-Flash to Step-3.7-Flash.
Same host, same 69 scenarios, two models.
Results:
DeepSeek-v4-Flash:
90/100 quality, 59 passed, 6 partial, 4 failed
Step-3.7-Flash:
87/100 quality, 55 passed, 10 partial, 4 failed
👇
1
126
16h
RepoPrompt for Windows
Open any project folder → select exactly which files matter → generate clean, LLM-optimized XML output.
📁 Open any project folder
✅ Select exactly which files matter
💰 Set your token budget
📋 Generate clean, LLM-optimized XML output
🪟 Built for Windows 🔒 Local & private 📦 Free
Try it out here:
github.com/MiaAI-Lab/repopro…
87
Jun 12
I just published Slate — a fast, light-weight OLED-friendly Markdown/text editor.
It supports editing all types of text-based files.
One thing I really wanted: a proper OLED-friendly editor. Not “dark gray” — complete black, so it looks great on OLED displays and feels easy on the eyes at night.
Fully developed by local AI.
Currently Windows only. Feel free to fork and build for Mac/Linux.
Feel free to test it, open issues, report bugs, or suggest ideas.
github.com/MiaAI-Lab/Slate
1
160

Congrats to the @MiniMax_AI team on the release of MiniMax M3, a long-context multimodal model for text, image, and video reasoning. 🙌
Try it today with our free GPU-accelerated endpoint on build.nvidia.com.
Details: nvda.ws/4v4BWhD

Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
51
116
1,315
134,408
Jun 12
Building the things you couldn't find anyone else building has never been easier.
99
Jun 12
Monster.
Can probably fit into 8x @NVIDIAAI DGX Sparks.
Out of my reach, for now.
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


1
188
Jun 12
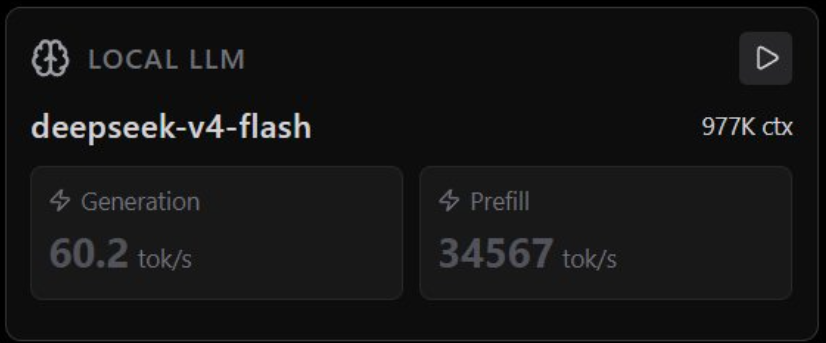
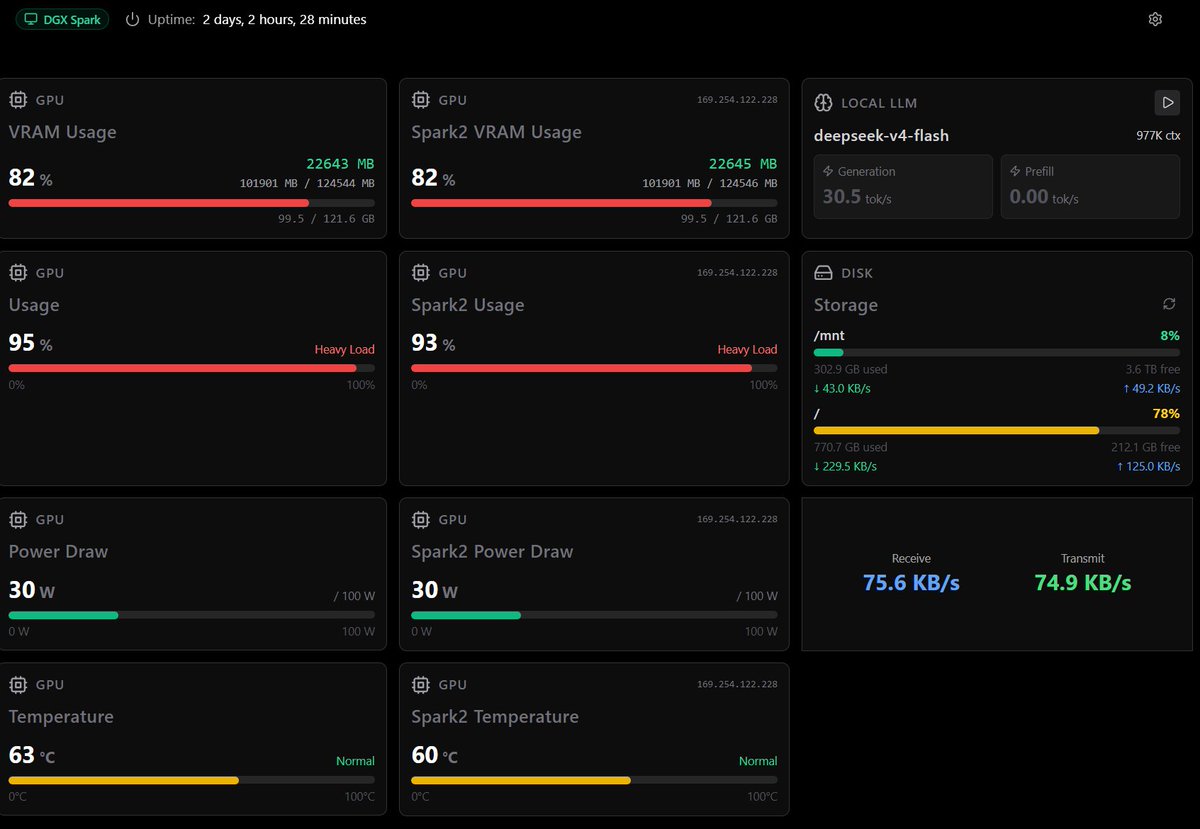
Two concurrent sessions with DS4-Flash, getting more than 60 tok/s and insane prefill numbers.
Running on 2x @NVIDIAAI DGX Sparks
7
2
52
4,420