
Joined July 2020
- Tweets 30,157
- Following 397
- Followers 25,332
- Likes 9,679
9,502 Photos and videos










Pinned Tweet

18 Sep 2025
Public portfolio and X Subscription
I'm still waiting for X Subscription approval. I decided to only focus on @X as my main platform to share what I learn.
After years of posting DDs, I still have a lot to learn as content creator. While i'm figuring that out, I will keep all my posts at Free.99. I don't like the idea of paywall where my goal is to share helpful information. And I'm addicted to misunderstood companies. I will try my best to include the TLDR for my long threads. It its very difficult for me to explain my take in a few sentences.
When X approves my account, I will discuss the detail for that group later. Most likely:
-Option(Cash Secure Put, Covered Call)
-More Frequent 13f updates
-More Frequent Buy update
-Frequent takes on Macro/Catalyst
-Hedging, longer term analysis
-Useful analysis on new/existing Long Term
Current Public portfolio:
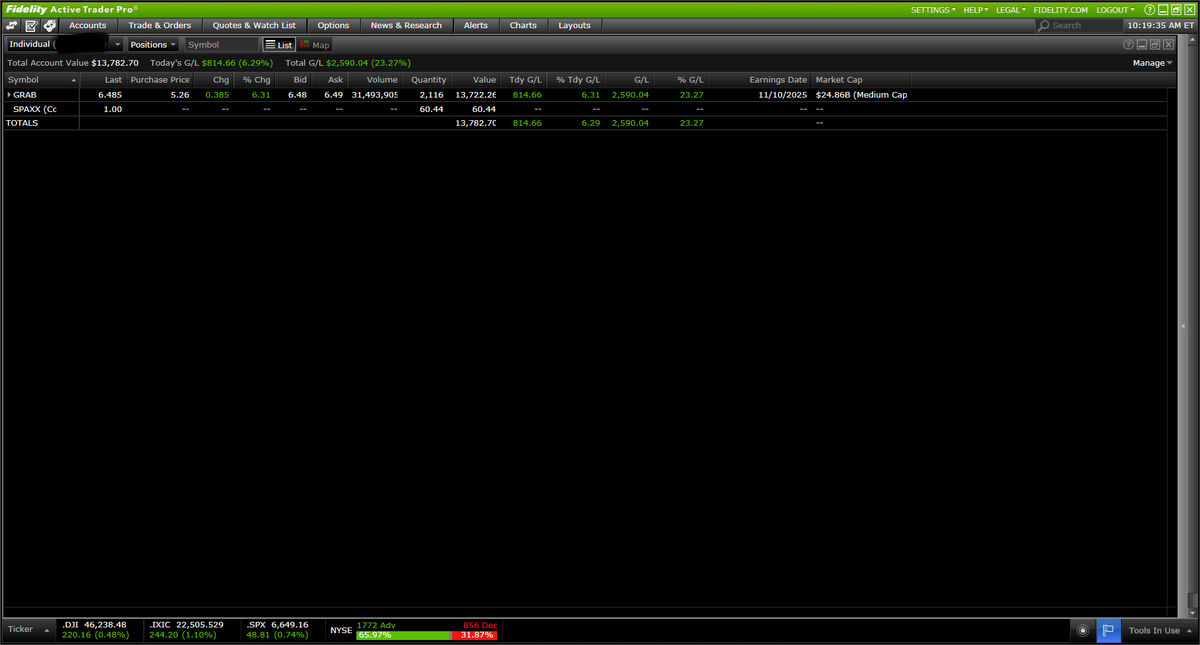
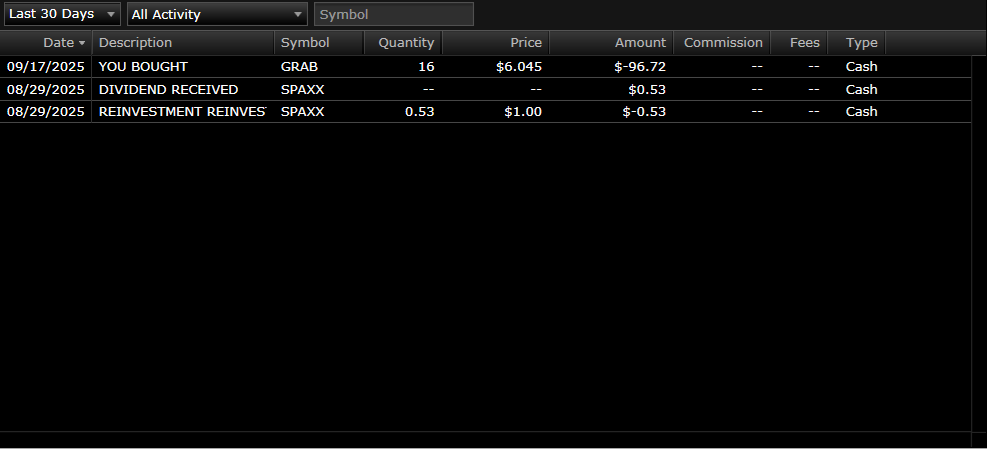
2,116 shares on $GRAB at average $5.26
Account value: $13,782.70
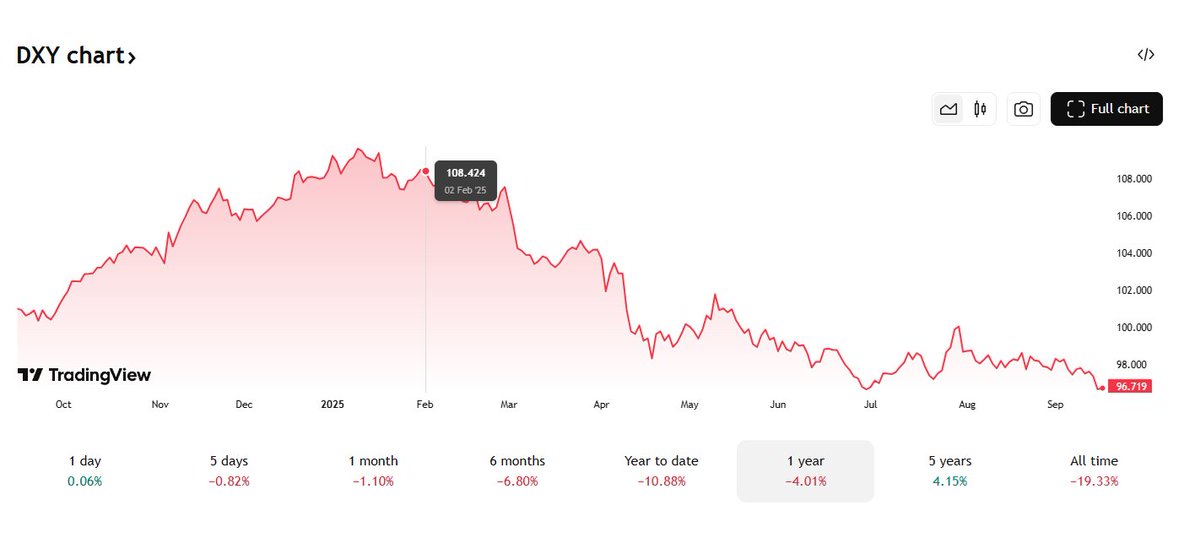
1. Precisely, I spent nearly 1000 hours learning about $GRAB. You can read below thread on why I chose $GRAB as the biggest hedge, and also a high quality growth long term story. I think the community knows where i'm at with $GRAB as the @federalreserve rate cut path just began.
Regarding Public portfolio, this is $500-$1,000 a month of my own money contribution on @Fidelity. I may change this broker, as it is so outdated, I can't do anything here except buying shares 😅. $GRAB on private portfolio, and it is nearing 7% position(major position). I believe $40B market cap is a fair valuation for its potential(SuperApp, B2B, Organic Growth), especially after @Alipay and @OpenAI partnerships.
My private portfolio average is lower than public due to the advantage of capital. I will not time the market. I learnt that a long time ago.
Many said it would take me 7 years to get to $100k(Challenge accpeted). Even at $500-$1,000 a month, it may take only 3 years or less. This public portfolio is not meant to be just pure 100% Grab, it is just so undervalued right now, and I couldnt find anything better FOR ME in 10-15 years horizon. As soon as Grab gets to fair valuation, I may have to find 2nd undervalued/high quality business, if not I will continue to DCA into GRAB.
This public portfolio could get to $100k when $Grab hit $30, assuming I couldnt find any alternative and just DCAing into it. I will try to keep this public portfolio under 10 companies, as it is hard to keep up with more than 10 companies earning/filing for folks that have 9-5 job.
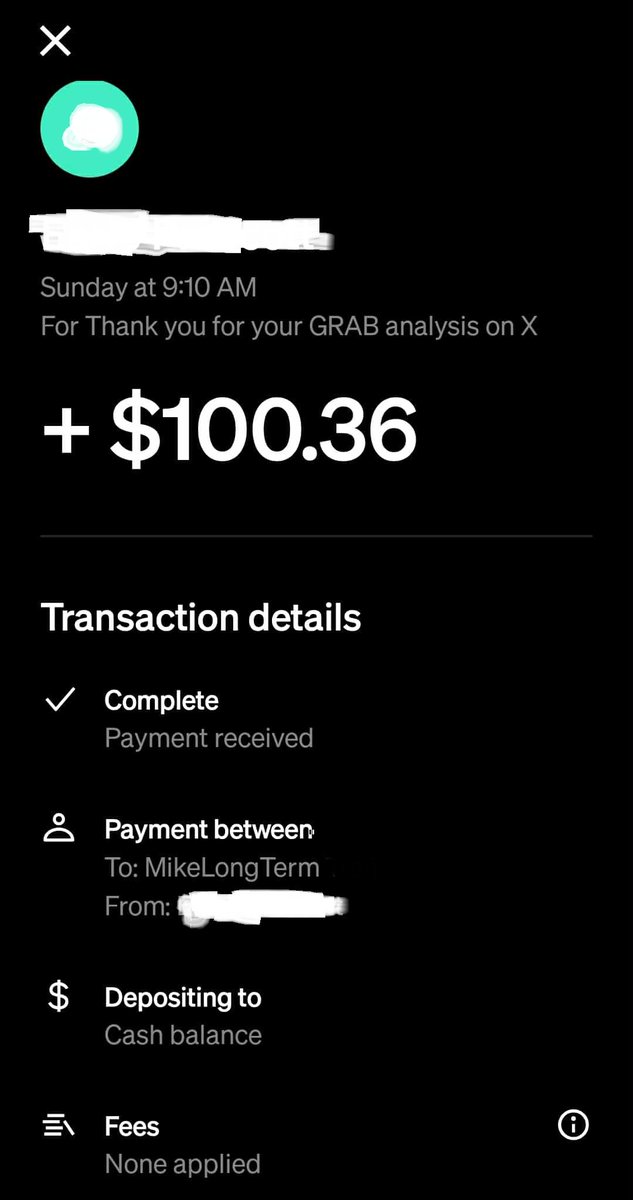
2. A kind gentleman, I blurred his name for privacy @CashApp me for DD I provide for the community(never expected this). I want you to know, I appreciate you. And this is a kind gesture, and I decided to buy more $GRAB (16 shares) to show my conviction. I believe I have to put my capital on the line. I don't play around with my capital, none of what I do is based on luck. I'm very picky when it comes to high quality long term like $PLTR $AMD $TSLA $XYZ $HIMS.
My @MikeLongTerm account is near 13k Follow as of today. I would like to thank everyone for supporting this account.
I believe in accumulating wealth early, as early as you can. Investing early leverages time and compounding to build wealth, reduce financial dependence on a job, and achieve financial freedom. Financial freedom allows us to do more things that we love, or spend more time with family.
The key is consistency. I have shared over 21,000 posts/tweet on various companies. I may write a long thread on how I identify high quality long term. That will be for later.
Alright that is it.
Everything I do/write is NOT Financial Advice.
And Happy Investing!
17 Sep 2025

$GRAB as the biggest hedge Updated 🧵
We are just getting start on the rate cut path, meaning the dollar will decline even more. Meaning $GRAB revenue & profitability will skyrocket as it collects revenue in other currencies. 5% increase to 7% due to increased conviction and updated thesis to $500B MC long term.
$GRAB is somewhat detached from US equity, and the least volatile when it comes to correction.
Nearly 7% position can be a substantial position sizing if this spike to $20-$25(2026-2027). That is exactly the plan. I'm very concentrated in US equity, especially the AI top dogs. This $GRAB hedge bet should balance out the volatility along with Silver and $ETH.
Grab has 5-year beta of 0.84 relative to SP500, which has a premium or high valuation. Not only GRAB is muted to recent volatility, GRAB is now up 82% from April selloff. I will link the thread where I explained it in detail, when I said this is my biggest high quality growth hedge bet in the next 10-15 years.
These are other factors to hedge with $GRAB:
1. Anti recession business model that prioritizes affordability as core.
2. US is now down 11% from the day I decided to hedge with GRAB. Further USD decline will only amplify Grab profitability.
3. I also been talking about Silver and $ETH to hedge with $GRAB. It is doing well as of today for all 3.
4. SEA with 6-10% GDP growth will double to triple their income, as of now $GRAB margin is already higher than $UBER with only 6.5% penetration and 14% thesis of 5 billion people for bottom of pyramia core. 700m people are plenty to grow for remaining 93.5% with wide range of services.
5. Unlimited potential on GrabFin, GrabUnlimited, GrabAds,Grab Drone, Grab tourism
6. Outperformance to SP500 or Nasdaq by 300-500% depending on your entry.
Overall, $GRAB should have boost revenue of 5-7% and EPS by 8-12% from this 11% decline due to most revenue collected by foreign denominated. It is going to be a long time until we are back to QT again with energy price this stable. The @federalreserve should worry about employment more.
Acclerated rate cut path will only help SEA economy, but it has risk of rising inflation, which could trigger higher interest in SEA central banks. Which will also benefit GRAB enormous cash balance to earn 7-10% interest on $7B cash or $500m-$700m interest income.
Very little headwind ahead for $GRAB SuperApp, the biggest risk is bad M&A, where management is keeping the high bar, and prioritize Organic growth(B2B, B2C in house). I talked about Macro a lot, i know it can get boring, but it does help navigating complex investment strategy. And this is one of my biggest hedge in this decade.
Alright, that is it.
Not Financial Advice!
40
17
140
409,646

1
6
4
1,795
10h
$AMD shareholders after reading @AnthropicAI Q2 2026 Financial Numbers and realized Token costs on @awscloud @googlecloud and $NVDA chips are way too high(Not what they claimed for years) that $10.9B Revenue Anthropic generated only 5% Adj Operating margin or Equivalent to Grocery store margin.
This is only helping the biggest winner in Agentic AI
=> @AMD if AI Natives and Sovereign AI or Enterprises want to truly gain operating leverage with the best AI Racks in the world!
Or Hyperscalers can buy lots of $AMD chips so that Anthropic can't buy any.
It is only winning from here.
11h
$AMD $TSM $WFC on AI Token cost 🧵
Not Financial Advice! DYOR
Wells Fargo's chief equity strategist Ohsung Kwon highlighted the "end of token-maxxing" as a key risk. As subsidies fade and enterprises (Walmart, Uber, etc.) become cost-sensitive, demand growth for AI services could slow. This will hit hyperscalers hard.
Now Most should know that, $GOOGL $AMZN $MSFT are mostly in-house chips or $NVDA chips and Agentic AI sent Inference costs by 50-1000x more tokens per task than simple chat queries.
$META is the new Hybrid Hyperscaler, and the first to adotp @AMD At large scale. $META and @OpenAI have cited AMD with superior Inference cost, precisely what Dr. Su bet on since 2022/2023.
The core issue in practice for many enterprises: total AI bills (especially for inference) are rising sharply despite per-token price drops and heavy use of Nvidia GPUs or in-house custom silicon. The "reality" on the ground often doesn't match vendor claims of dramatic TCO or $/M token savings, largely because of volume explosion from agentic/reasoning workflows, rather than hardware alone failing. AMD is frequently ignored for years but now positioned as delivering strongest real-world TCO advantages in owned or optimized inference setups, as Inference cost can collapse to $0.0003-$0.0005/ M tokens unlike rental rate effectively at $0.02-$0.25/M Tokens.
Ohsung Kwon core argument is high Token costs will kill demand, and may destroy the AI CapEx. However
in-house/Nvidia setups haven't fully delivered the promised token-cost relief at enterprise scale yet, contributing to bill shock. AMD's focus on accessible TCO (cheaper chips, high memory, open approaches) makes it a stronger "unlike" option for cost-sensitive inference, which is why Meta & @OpenAI (and soon all others) are scaling it AMD Racks aggressively
$NVDA, $MSFT $AMZN $GOOGL in-house chips rack-scale efficiency, Google on TPU perf/$, and AWS on Trainium 30-50% better price-performance) haven't fully translated into controlled OpEx for high-volume inference at places like OpenAI and Anthropic or to Enterprises.
Excellent raw throughput and ecosystem (CUDA), but premium pricing (~40k /GPU), high power, and rack-scale (NVL72) still leads to high OpEx at extreme volumes. Blackwell delivers big gains (e.g., 35-100x in some agentic benchmarks), but not enough to offset token explosion for loss-making labs
Custom ASICs (TPU/Trillium, Trainium): Strong claims in cloud benchmarks (Google often best $/token for sustained inference; AWS 30-50% better price-perf), but locked to provider, optimization overhead, and less flexible for frontier model iteration. Anthropic's higher-than-expected costs on these show the gap
The exploding demand for Agentic AI (multi-step reasoning, tool use, branching workflows, reinforcement learning...) has dramatically shifted the CPU-to-GPU ratio in clusters, turning CPUs into a major bottleneck and driving up overall OpEx, even on high-end GPU/custom setups often cited at 1:1 Ratio. However, I believe the ratio or shortage is much worse than Media outlets or Hyperscalers reported. We can connect the dots from Enterprises complaining about Token Budget rised too much to this.
Under provisioned CPUs → low GPU utilization (often <10–20% in real serving), higher tail latency, more GPUs needed to compensate, and wasted power. Adding CPUs is much cheaper relative to GPUs, but shortages force over-provisioning or premium pricing. This directly inflates token costs for OpenAI/Anthropic-scale operations.
This explains part of why in-house/custom silicon (TPU, Trainium, Maia) and Nvidia-heavy setups haven't delivered the expected OpEx relief because the full stack isn't balanced.
The Helios rack (with next-gen MI450/MI455X Instinct GPUs, 6th Gen EPYC "Venice" CPUs, and Pensando Vulcano NICs) is explicitly engineered for agentic AI workloads, addressing the exact CPU/GPU imbalance and systemic inefficiencies that have driven high OpEx at OpenAI, Anthropic, and many enterprises.
This setup aims to deliver higher tokens per dollar, better GPU utilization, and lower overall rack TCO compared to unbalanced or premium-priced alternatives directly attacking the bill shock for Enterprsies.
Why $AMD is the only system that can boost Token Consumption again?
As costs per token stabilize or drop further via better balance hardware efficiency like AMD Helios Rack and Agentic AI Rack, enterprises that paused or throttled "token-maxxing" will ramp usage again. Agentic AI becomes more economically viable when the full stack (CPU GPU networking) doesn't waste resources.
The difference is massive between $0.0003-$0.0005/M tokens vs $0.02-$0.25/M Tokens. That would mean token consumption to 10-50x, hence we won't see Enterprises slowing down token consumption. @OpenAI of course has the advantage here, but @Citi cited Anthropic to sign a deal with $AMD soon, so we will find out soon at Advancing AI event in July.
$META and Hypersaclers are also scaling AMD EPYC or Agentic AI Rack with $AMD, that should also help lowering token costs.
Conclusion:
AMD’s Helios rack powered by next-gen MI450/MI455X Instinct GPUs, high-core EPYC Venice CPUs, and full-stack integration directly tackles the systemic issues that have kept inference costs stubbornly high despite vendor claims from Nvidia and custom silicon players. By delivering superior rack-level balance, massive HBM4 memory advantages, lower TCO, and optimized handling of agentic workflows (with proper CPU provisioning for orchestration, retries, and tool calls), Helios is positioned to normalize enterprise AI bills where in-house and Nvidia-heavy setups have fallen short so far.
This cost relief will trigger a virtuous cycle: as OpEx stabilizes and tokens-per-dollar improve, enterprises are likely to resume (and expand) “token-maxxing” and agentic deployments driving higher overall consumption, infrastructure demand, and sustainable AI growth across the ecosystem.
Dr. Lisa Su said:
“In the past the CPU to GPU ratio was primarily just as a host node in like a one to four or one to eight configuration, now changing and getting closer to a one-to-one configuration or, even, you can even imagine if you get lots and lots of agents that you could have more CPUs than GPUs.”
She has also called Helios “truly a game changer,” noting it is “architected every part of the rack as a unified system... purpose built for the most demanding AI workloads.”
The biggest winner in Agentic AI already won when we saw this many enterprises capping token budget or trying to justify the token bills vs economic gains. Only AMD could fix this, because Dr. Su made this bet ~4 years ago, that at some point, Inference will be 90-95% of all AI compute long term.
Not Financial Advice! DYOR
1
8
44
11,413
11h
$AMD $TSM $WFC on AI Token cost 🧵
Not Financial Advice! DYOR
Wells Fargo's chief equity strategist Ohsung Kwon highlighted the "end of token-maxxing" as a key risk. As subsidies fade and enterprises (Walmart, Uber, etc.) become cost-sensitive, demand growth for AI services could slow. This will hit hyperscalers hard.
Now Most should know that, $GOOGL $AMZN $MSFT are mostly in-house chips or $NVDA chips and Agentic AI sent Inference costs by 50-1000x more tokens per task than simple chat queries.
$META is the new Hybrid Hyperscaler, and the first to adotp @AMD At large scale. $META and @OpenAI have cited AMD with superior Inference cost, precisely what Dr. Su bet on since 2022/2023.
The core issue in practice for many enterprises: total AI bills (especially for inference) are rising sharply despite per-token price drops and heavy use of Nvidia GPUs or in-house custom silicon. The "reality" on the ground often doesn't match vendor claims of dramatic TCO or $/M token savings, largely because of volume explosion from agentic/reasoning workflows, rather than hardware alone failing. AMD is frequently ignored for years but now positioned as delivering strongest real-world TCO advantages in owned or optimized inference setups, as Inference cost can collapse to $0.0003-$0.0005/ M tokens unlike rental rate effectively at $0.02-$0.25/M Tokens.
Ohsung Kwon core argument is high Token costs will kill demand, and may destroy the AI CapEx. However
in-house/Nvidia setups haven't fully delivered the promised token-cost relief at enterprise scale yet, contributing to bill shock. AMD's focus on accessible TCO (cheaper chips, high memory, open approaches) makes it a stronger "unlike" option for cost-sensitive inference, which is why Meta & @OpenAI (and soon all others) are scaling it AMD Racks aggressively
$NVDA, $MSFT $AMZN $GOOGL in-house chips rack-scale efficiency, Google on TPU perf/$, and AWS on Trainium 30-50% better price-performance) haven't fully translated into controlled OpEx for high-volume inference at places like OpenAI and Anthropic or to Enterprises.
Excellent raw throughput and ecosystem (CUDA), but premium pricing (~40k /GPU), high power, and rack-scale (NVL72) still leads to high OpEx at extreme volumes. Blackwell delivers big gains (e.g., 35-100x in some agentic benchmarks), but not enough to offset token explosion for loss-making labs
Custom ASICs (TPU/Trillium, Trainium): Strong claims in cloud benchmarks (Google often best $/token for sustained inference; AWS 30-50% better price-perf), but locked to provider, optimization overhead, and less flexible for frontier model iteration. Anthropic's higher-than-expected costs on these show the gap
The exploding demand for Agentic AI (multi-step reasoning, tool use, branching workflows, reinforcement learning...) has dramatically shifted the CPU-to-GPU ratio in clusters, turning CPUs into a major bottleneck and driving up overall OpEx, even on high-end GPU/custom setups often cited at 1:1 Ratio. However, I believe the ratio or shortage is much worse than Media outlets or Hyperscalers reported. We can connect the dots from Enterprises complaining about Token Budget rised too much to this.
Under provisioned CPUs → low GPU utilization (often <10–20% in real serving), higher tail latency, more GPUs needed to compensate, and wasted power. Adding CPUs is much cheaper relative to GPUs, but shortages force over-provisioning or premium pricing. This directly inflates token costs for OpenAI/Anthropic-scale operations.
This explains part of why in-house/custom silicon (TPU, Trainium, Maia) and Nvidia-heavy setups haven't delivered the expected OpEx relief because the full stack isn't balanced.
The Helios rack (with next-gen MI450/MI455X Instinct GPUs, 6th Gen EPYC "Venice" CPUs, and Pensando Vulcano NICs) is explicitly engineered for agentic AI workloads, addressing the exact CPU/GPU imbalance and systemic inefficiencies that have driven high OpEx at OpenAI, Anthropic, and many enterprises.
This setup aims to deliver higher tokens per dollar, better GPU utilization, and lower overall rack TCO compared to unbalanced or premium-priced alternatives directly attacking the bill shock for Enterprsies.
Why $AMD is the only system that can boost Token Consumption again?
As costs per token stabilize or drop further via better balance hardware efficiency like AMD Helios Rack and Agentic AI Rack, enterprises that paused or throttled "token-maxxing" will ramp usage again. Agentic AI becomes more economically viable when the full stack (CPU GPU networking) doesn't waste resources.
The difference is massive between $0.0003-$0.0005/M tokens vs $0.02-$0.25/M Tokens. That would mean token consumption to 10-50x, hence we won't see Enterprises slowing down token consumption. @OpenAI of course has the advantage here, but @Citi cited Anthropic to sign a deal with $AMD soon, so we will find out soon at Advancing AI event in July.
$META and Hypersaclers are also scaling AMD EPYC or Agentic AI Rack with $AMD, that should also help lowering token costs.
Conclusion:
AMD’s Helios rack powered by next-gen MI450/MI455X Instinct GPUs, high-core EPYC Venice CPUs, and full-stack integration directly tackles the systemic issues that have kept inference costs stubbornly high despite vendor claims from Nvidia and custom silicon players. By delivering superior rack-level balance, massive HBM4 memory advantages, lower TCO, and optimized handling of agentic workflows (with proper CPU provisioning for orchestration, retries, and tool calls), Helios is positioned to normalize enterprise AI bills where in-house and Nvidia-heavy setups have fallen short so far.
This cost relief will trigger a virtuous cycle: as OpEx stabilizes and tokens-per-dollar improve, enterprises are likely to resume (and expand) “token-maxxing” and agentic deployments driving higher overall consumption, infrastructure demand, and sustainable AI growth across the ecosystem.
Dr. Lisa Su said:
“In the past the CPU to GPU ratio was primarily just as a host node in like a one to four or one to eight configuration, now changing and getting closer to a one-to-one configuration or, even, you can even imagine if you get lots and lots of agents that you could have more CPUs than GPUs.”
She has also called Helios “truly a game changer,” noting it is “architected every part of the rack as a unified system... purpose built for the most demanding AI workloads.”
The biggest winner in Agentic AI already won when we saw this many enterprises capping token budget or trying to justify the token bills vs economic gains. Only AMD could fix this, because Dr. Su made this bet ~4 years ago, that at some point, Inference will be 90-95% of all AI compute long term.
Not Financial Advice! DYOR
Jun 11
$AMD| The FOMO to buy @AMD Chips is NOW 🧵
Not Financial Advice! DYOR! Research Purpose Only!
The Inference Queen is the biggest winner in Agentic AI where all other CPUs are struggling to compete with a 2yr old EPYC Turin and EPYC Venice is in mass production phase. AMD stresses deployability today on standard x86 platforms (no proprietary architectures required), full software compatibility, and open standards. This positions Venice Helios as a practical, high-density alternative to competing solutions while underscoring that agentic AI shifts the balance toward CPU-rich racks alongside GPUs, and most importantly, lowering the cost of token to accelerate adoption and innovation.
Context: @WSJ yesterday came out with an article that @OpenAI is condiering drasstically lowering the token prices to win more customers from Anthropic. The narrative "they" are trying to exacerbate the current AI selloff won't last long. This is a fundamental misunderstanding of what is going on, or what I already discussed for months and years. Followers and Subscribers already knew this for years, that this day would come, where token cost will bcome the central discussion among enterprises as there is no such thing as unlimited budget or Tokenmaxxing when they use $NVDA chips or In-house Hyperscalers chips.
I will link various threads if you are interested in understanding the full picture from supply chain to recent TSMC Rapid 2nm expansion up to 12 Fabs total by 2027/2028.
Hyperscalers and AI natives effectively have no choice but to buy more AMD system for Agentic AI as leadership in economical, power-aware, high-volume internal agentic use. However, due to supply constraints where Supply is far behind Demand, this makes multi-vendor reality along with in-house chips drive faster industry progress, lower overall costs, and better sustainability.
NVIDIA’s Vera Rubin cannot compete with a 2 years old EPYC Turin, but AMD under Dr. Lisa Su has engineered the lowest cost-per-million-tokens, highly competitive energy-efficient solutions, and superior CPU orchestration for agentic AI at scale with Helios. Dr. Su has championed this shift since at least 2023, foreseeing the rise of agentic workflows that demand far more orchestration, parallel agents, and balanced compute well before the industry fully embraced it. Her long-term vision of AI moving from simple prompts to always on, multi-agent systems has driven AMD’s investments in high-core EPYC CPUs and integrated rack-scale solutions, perfectly positioning the company for today’s realities.
The OpenAI-AMD 1GW Helios deployment (starting H2 2026) represents a pivotal vertical integration move that directly supercharges the inference economics. This isn't incremental; it's a structural shift toward ownership of massive, optimized rack-scale capacity, enabling the lowest token costs and triggering the enterprise adoption flywheel.
We need to be honest, $AMD is the only company that made a big bet on Inference since the day Chatgpt became sensational where $NVDA and others were betting big on Training. At the end of the day, Token bill from @AnthropicAI has to obey economics. Meaning the bills rise, companies have to get more out of it to justify the cost. It cannot be an unlimited inference budget, and it has to show up on efficiency, profitability and operating leverage.
1. Tokenomics
After you understand this, you will understand why Citi cited @AnthropicAI is likely to sign a deal with $AMD along with Hyperscalers, AI Labs, Sovereign AI like Softbank 5GW in France and many other countries. However, OpenAI and $META are now wanting faster deployment, and they are AMD shareholders now, they have prioritized allocation. Anthropic and Hyperscalers just cannot compete when Helios Rack lower token cost to$0.0003–$0.0005 per million tokens at GW scale.
Cost to build 1GW data center
1GW Helios Rack full build is estimated $30-$35B 1GW Rubin Rack full build is estimated $45-$55B
Inference (Cost per Million Tokens)
~$NVDA B200 / HGX: ~$0.02–$0.08 on optimized workloads (FP4/MXFP4, speculative decoding). Significant improvement over Hopper but still premium-priced. GB200 NVL72 rack-scale: $0.05–$0.25
~$AMD Helios Racks: $0.0003-$0.0005 per M tokens, dramatically lower than NVIDIA equivalents in owned infra. MI355X node-level: Up to 40% more tokens per dollar vs. competing solutions ( B200), driven by higher memory capacity (up to 288GB HBM), strong bandwidth, and lower acquisition costs.
Training
~$NVDA Rubin Rack is estimated $0.7-$1.2/M Tokens
~$AMD Helios Rack is estimated $0.65-$1.0/M Tokens
Now, OpenAI, META and Hyperscalers can lower Inference cost even further with $AMD EPYC Venice "dense rack" or Agentic AI Rack. AMD published a detailed technical blog emphasizing that the future of agentic AI autonomous, multi-step AI systems requiring heavy orchestration, databases, caching, APIs, and control planes demands massive CPU-dense rack-scale infrastructure, not just GPUs. The catalyst prominently positions their upcoming 6th Gen EPYC "Venice" processors as the key enabler for next-generation dense racks, delivering leadership throughput under real-world power, cooling, and density constraints.
~EPYC Venice (Zen 6 architecture, up to 256 cores / 512 threads per socket) is projected to deliver exceptional rack-level performance. In AMD’s modeled 100 kW rack comparisons, Venice-powered systems are expected to achieve ~3.30x the throughput of NVIDIA’s Vera (88-core Olympus) baseline across a broad mix of agentic-supporting workloads.
~This builds on current-generation 5th Gen EPYC "Turin" (up to 192 cores), which already delivers ~2.37x rack throughput vs. Vera and ~1.6x vs. Intel’s Xeon 6980P (128 cores).
~ Liquid-cooled Turin deployments already support >27,000 CPU cores per rack today. Venice is architected to push this beyond 36,000 cores in the same rack class, dramatically increasing concurrent agent capacity and overall infrastructure efficiency.
2. Ownership vs renting compute from Hyperscalers matter to OpenAI and only owning $AMD chips can meaningfully lower token cost for enterprises.
~Eliminates cloud overhead: No provider margins, utilization buffers, or egress fees. Direct control over power contracts, cooling, scheduling, and orchestration at dedicated facilities.
~Helios optimizations at GW scale: Rack-level density (1.4 exaFLOPS FP8 per rack), high HBM4 bandwidth, EPYC orchestration for agentic workloads, and superior TCO/TDP. AMD's long-standing focus on tokens per dollar/watt shines here 20-40% efficiency edges in inference-heavy scenarios.
~At 1GW optimized deployment, inference hits $0.0003–$0.0005 per million tokens (community/analyst models tied to Helios metrics). This is dramatically lower than typical rented/cloud equivalents, especially for high-volume output tokens in agentic flows.
High token bills today, enterprises running heavy agentic/coding/analysis workloads can face $50-100M /month at current API rates (flagship models $5-30 /M output, scaled to massive volumes).
Post-Helios compression, same volume will drop to $10-15M/month (or better) via lower underlying costs passed through as pricing flexibility, volume tiers, caching, or batch discounts.
ROI thresholds collapse. More companies greenlight pilots → production → massive scaling. Agentic AI (autonomous workflows) multiplies token demand exponentially, but affordability removes the friction.
OpenAI gains flexibility, Unlike more cloud-dependent rivals (Anthropic), they can lower effective pricing, offer aggressive enterprise bundles, or absorb volume without margin destruction directly tackling "high token bill" complaints while maintaining profitability as usage explodes.
3. Agentic AI Models shifted CPU:GPU Ratio to 1:1 toward 3-5:1 with Explosively Token-Hungry Workloads
Agentic AI (autonomous, multi-step agents with planning, tool use, iteration, and self-correction) is fundamentally more compute and token intensive than conversational or single-turn generative AI.
Agentic AI. autonomous, multi-step workflows with orchestration, tool use, parallel agents, data movement, and enterprise integration has dramatically increased the importance of strong host CPUs alongside GPUs. This shifts the CPU-to-GPU ratio higher and makes balanced systems critical toward 1:1 to 5:1 as enterprises testing more than 5-10 agents.
AMD EPYC Venice excels
~Leadership core density (up to 256 Zen 6 cores per socket) for running many agents in parallel, orchestration layers, and high-throughput control-plane tasks.
~Superior performance-per-core and power efficiency ( up to 2.1x higher perf/core and 2.26x better SPECpower vs. NVIDIA Grace in benchmarks).
~Tight integration in Helios: One Venice CPU multiple MI450 GPUs per node, enabling efficient data feeding to GPUs ("zero-copy"), parallel execution, and full rack utilization for complex agentic loops.
Hyperscalers (Meta, Microsoft, Amazon, Google, Softbank) and AI natives (OpenAI, Anthropic...) are adopting high-core EPYC at scale specifically for these agentic demands, as CPUs now handle a larger share of non-model work (orchestration, policy enforcement, tool calls). This complements AMD’s lower-cost GPUs for overall TCO wins.
~Agents often generate 10–100x more tokens per task due to iterative reasoning chains, multiple tool calls, verification loops, and long-context orchestration.
~Goldman Sachs forecasts token consumption multiplying 24x by 2030 (to 120 quadrillion tokens/month) largely driven by agentic adoption in consumer and enterprise.
~Enterprise data shows agent-pattern workloads growing at 680% annualized rates, projected to surpass conversational AI in token volume by Q3 2026.
~Daily enterprise agent token consumption is already in the billions, with complex workflows (coding, workflows, analysis) amplifying this dramatically.
4. Competitive Edge: Winning Customers from Anthropic
Anthropic’s Claude models (especially Opus/Sonnet) excel in complex reasoning and agentic coding, commanding premium positioning. However, their higher underlying costs (heavier reliance on third-party cloud with margins) limit pricing flexibility compared to OpenAI’s owned Helios capacity.
Anthropic is on track to generate $10.9 billion in Q2 revenue. The company expects to achieve its first-ever quarterly adjusted operating profit of $559 million. However, sustaining full-year profitability remains challenging due to immense computing and model training costs
The truth is, Anthropic has no choice but to buy as much $AMD chips as possible if they want to compete with OpenAI or get investors attention. This 5% adjusted operating profit to revenue ratio is just pathetic.
Current pricing dynamics (2026): OpenAI already undercuts on many tiers ( flagship output tokens significantly cheaper than equivalent Claude Opus). Nano/mini models offer 5–10x advantages for volume work. Anthropic holds edges in long-context flat pricing and certain reasoning quality.
OpenAI after Helios Rack Ownership, At $0.0003–$0.0005/M effective costs, OpenAI gains massive headroom to:
~Aggressively discount high-volume agentic tiers or bundles.
~Offer “unlimited” enterprise plans or usage-based models that Anthropic struggles to match without margin erosion.
~Target cost-sensitive, high-throughput agent deployments (dev tools, automation platforms) where token bills explode.
Enterprises facing $ millions in monthly agentic bills will migrate to the provider delivering better economics at scale. OpenAI’s combination of strong models (o-series reasoning) lowest TCO positions it to erode Anthropic’s enterprise share, especially as agentic becomes the dominant token consumer.
Cheaper tokens expand the total addressable market dramatically. This feeds the data/model improvement loop, justifying further capex. AMD benefits from proven scale pulling in more customers (Meta, Oracle, Microsfot, Amazon, Softbank, TensorWave, LumaAI ... already aligned on Helios).
Conclusion:
Dr. Lisa Su has been laser focused on inference economics since at least 2022–2023, repeatedly emphasizing that the real battleground for AI scalability would be TCO, power efficiency (TDP), and ultimately tokens per dollar and per watt not just raw training FLOPS. While many viewed inference as a secondary, commoditized workload, Dr. Su architected AMD’s roadmap around rack-scale systems optimized for high-volume, sustained inference that would dominate as models matured and usage exploded. Helios represents the culmination of that multi-year bet: a fully integrated, open platform designed precisely for the economics of massive token throughput.
This deep, strategic partnership with OpenAI starting with the 1GW Helios deployment in H2 2026 and scaling to 6GW, is the embodiment of that shared vision. Both companies foresaw a future where agentic AI models evolve to become extraordinarily token-hungry: autonomous agents executing complex, iterative workflows with planning, tool use, verification loops, and long-context reasoning. These workloads can consume 100x more tokens per task than traditional chat or single-turn generation, driving exponential demand as capabilities improve and enterprises deploy them at scale.
By owning and optimizing this massive Helios capacity at GW scale, OpenAI achieves inference costs as low as $0.0003–$0.0005 per million tokens. This structural cost advantage allows OpenAI to absorb the coming token explosion profitably, dramatically lower effective pricing for enterprises, and win high-volume agentic workloads from higher-cost competitors like Anthropic. What was once a prohibitive monthly token bill becomes an affordable accelerator for productivity and innovation.
The OpenAI-AMD alliance validates Dr. Su’s prescient strategy and turns the Agentic flywheel into reality:
Collapsing inference costs
→ explosive token consumption
→ richer data and better models
→ accelerate greater demand.
This partnership doesn’t just address today’s economics, it positions both leaders at the center of the infrastructure buildout that will power AI’s next decade. By delivering the lowest inference economics at scale, OpenAI not only solves enterprise bill pain but gains a decisive weapon to win share from higher-cost rivals like Anthropic. And that is why @OpenAI and $META will deploy EPYC Dense Rack
Not Financial Advice! DYOR! Research Purpose Only!
4
9
35
16,138
11h
1
217
11h
1
159
19h
RIP Bears Monday
19h

TRUMP:
- SIGNING DEAL WITH IRAN TOMORROW
- STRAIT OF HORMUZ WILL BE OPEN TO EVERYONE
- LOOKING FORWARD TO WORKING WITH THE ENTIRE MIDDLE EAST
bro saved the deal signing for his birthday 😂
1
2
21
1,632
19h
$GRAB Taiwan | $UBER | Delivery Hero conversation✍️
I believe this deal will be approved.
The argument: The Taiwan Fair Trade Commission (FTC) blocked Uber's deal because combining the two dominant players would have eliminated meaningful competition. Grab's entry should increase competition by bringing a well-funded, tech-savvy operator (with ride-hailing SuperApp capabilities) against Uber Eats/Ride
The core problem is, Delivery Hero has too much debt and overextnded its operation where it does not have the financial mean to support. Debt is more than x2 the cash is not sustainable. Delivery would continue to compete if they were profitable and have little to 0 debt, but this is not the reality.
Now when it comes to ownership:
$UBER has 535.9m $GRAB shares w/ 4-5% voting right
$UBER has 36.83% of voting right Delivery Hero
Uber does not participate in day-to-day operations in Taiwan, and its board nominees recuse themselves from Taiwan-related decisions.
Grab has un independently from Uber in Southeast Asia (post-2018 merger). They compete aggressively in many markets despite the shareholding. Grab's CEO Anthony Tan has majority voting control, which helps maintain operational independence.
Post-deal Grab ~50-52% market share vs. Uber Eats ~47-48%.
Grab brings SuperApp ecosystem firepower (Ride, Food delivery, Quick commerce, Grab Fin like payments, mobility, AI tools, Tourism and B2B solution ) that Foodpanda lacked. Expect better innovation, more promotions, and improved service for consumers and drivers.
Grab’s proven SEA playbook (managing complex logistics in dense cities) fits Taiwan perfectly. Expected to add jobs, expand merchant reach, and bring proven SuperApp features that benefit consumers long term. Stable earnings & safety tools for couriers (weekly payouts, rest reminders, multi-rider heavy orders). Better tools for merchants (AI assistant, analytics, marketing).
Blocking this will eventually give Taiwan entire market to $UBER. Blocking this would hurt Taiwanese consumers, merchants, and gig workers the most fewer promotions, slower innovation, and less choice. Approving it (with sensible behavioral conditions) strengthens competition, creates jobs, and signals Taiwan remains open to quality foreign investment.
$GRAB and $UBER will compete, but $GRAB is an entirely different and superior business model where it offers a full-range of affordable services with subscription flywheel while $UBER is not. They certainly will compete on Ride and Food Delivery.
Not Financial Advice! DYOR!
Jun 10
BREAKING $GRAB-Taiwan to compete aggressively🚀
Taiwan would be Grab’s first market outside Southeast Asia if the deal is approved.
Grab group managing director Yee Wee Tang (余偉騰) told the company’s first news conference in Taipei that the entry into Taiwan’s food delivery market “makes a lot of sense,” as Taiwan, like other countries in Southeast Asia, has many densely populated urban areas.
“Taiwanese, in general, are tech-savvy and use mobile phones on a daily basis. The nation also has a very diverse food culture, and people are used to ordering food through mobile phones,” Yee said.
The government is scheduled to implement the Delivery Workers’ Rights Protection and Delivery Platform Management Act (外送員權益保障及外送平臺管理法) next month.
Asked whether the act would hurt the platform’s bottom line, and if it would affect the acquisition price for Foodpanda and food delivery fees, Yee said that Grab would comply with the act if the company secures regulatory approval to operate in Taiwan.
“Our understanding is that the acquisition is still ongoing and a lot of details are still being worked out, so it is not the right time to comment or speculate,” he said.
Yee was also asked how the company plans to win consumer trust and convince the FTC that the deal would create greater value for the market.
He was also asked whether the company would pledge not to increase delivery fees or leverage its dominant position in the market to claim a larger share of profits from other firms.
“Grab currently does not have any presence in Taiwan. We would be a new, independent player in this market. If we get the approval for the deal, we would compete fairly, but aggressively,” he said.
Source: Taipeitimes

2
2
14
2,268
20h
Jun 13

Google has an internal Fable- or GPT-5.6-level model and there's no reason to release it because it's negative margin
1
1
23
2,935
20h
$AMD| Read more here to understand
x.com/MikeLongTerm/status/20…
Jun 11
$AMD| The FOMO to buy @AMD Chips is NOW 🧵
Not Financial Advice! DYOR! Research Purpose Only!
The Inference Queen is the biggest winner in Agentic AI where all other CPUs are struggling to compete with a 2yr old EPYC Turin and EPYC Venice is in mass production phase. AMD stresses deployability today on standard x86 platforms (no proprietary architectures required), full software compatibility, and open standards. This positions Venice Helios as a practical, high-density alternative to competing solutions while underscoring that agentic AI shifts the balance toward CPU-rich racks alongside GPUs, and most importantly, lowering the cost of token to accelerate adoption and innovation.
Context: @WSJ yesterday came out with an article that @OpenAI is condiering drasstically lowering the token prices to win more customers from Anthropic. The narrative "they" are trying to exacerbate the current AI selloff won't last long. This is a fundamental misunderstanding of what is going on, or what I already discussed for months and years. Followers and Subscribers already knew this for years, that this day would come, where token cost will bcome the central discussion among enterprises as there is no such thing as unlimited budget or Tokenmaxxing when they use $NVDA chips or In-house Hyperscalers chips.
I will link various threads if you are interested in understanding the full picture from supply chain to recent TSMC Rapid 2nm expansion up to 12 Fabs total by 2027/2028.
Hyperscalers and AI natives effectively have no choice but to buy more AMD system for Agentic AI as leadership in economical, power-aware, high-volume internal agentic use. However, due to supply constraints where Supply is far behind Demand, this makes multi-vendor reality along with in-house chips drive faster industry progress, lower overall costs, and better sustainability.
NVIDIA’s Vera Rubin cannot compete with a 2 years old EPYC Turin, but AMD under Dr. Lisa Su has engineered the lowest cost-per-million-tokens, highly competitive energy-efficient solutions, and superior CPU orchestration for agentic AI at scale with Helios. Dr. Su has championed this shift since at least 2023, foreseeing the rise of agentic workflows that demand far more orchestration, parallel agents, and balanced compute well before the industry fully embraced it. Her long-term vision of AI moving from simple prompts to always on, multi-agent systems has driven AMD’s investments in high-core EPYC CPUs and integrated rack-scale solutions, perfectly positioning the company for today’s realities.
The OpenAI-AMD 1GW Helios deployment (starting H2 2026) represents a pivotal vertical integration move that directly supercharges the inference economics. This isn't incremental; it's a structural shift toward ownership of massive, optimized rack-scale capacity, enabling the lowest token costs and triggering the enterprise adoption flywheel.
We need to be honest, $AMD is the only company that made a big bet on Inference since the day Chatgpt became sensational where $NVDA and others were betting big on Training. At the end of the day, Token bill from @AnthropicAI has to obey economics. Meaning the bills rise, companies have to get more out of it to justify the cost. It cannot be an unlimited inference budget, and it has to show up on efficiency, profitability and operating leverage.
1. Tokenomics
After you understand this, you will understand why Citi cited @AnthropicAI is likely to sign a deal with $AMD along with Hyperscalers, AI Labs, Sovereign AI like Softbank 5GW in France and many other countries. However, OpenAI and $META are now wanting faster deployment, and they are AMD shareholders now, they have prioritized allocation. Anthropic and Hyperscalers just cannot compete when Helios Rack lower token cost to$0.0003–$0.0005 per million tokens at GW scale.
Cost to build 1GW data center
1GW Helios Rack full build is estimated $30-$35B 1GW Rubin Rack full build is estimated $45-$55B
Inference (Cost per Million Tokens)
~$NVDA B200 / HGX: ~$0.02–$0.08 on optimized workloads (FP4/MXFP4, speculative decoding). Significant improvement over Hopper but still premium-priced. GB200 NVL72 rack-scale: $0.05–$0.25
~$AMD Helios Racks: $0.0003-$0.0005 per M tokens, dramatically lower than NVIDIA equivalents in owned infra. MI355X node-level: Up to 40% more tokens per dollar vs. competing solutions ( B200), driven by higher memory capacity (up to 288GB HBM), strong bandwidth, and lower acquisition costs.
Training
~$NVDA Rubin Rack is estimated $0.7-$1.2/M Tokens
~$AMD Helios Rack is estimated $0.65-$1.0/M Tokens
Now, OpenAI, META and Hyperscalers can lower Inference cost even further with $AMD EPYC Venice "dense rack" or Agentic AI Rack. AMD published a detailed technical blog emphasizing that the future of agentic AI autonomous, multi-step AI systems requiring heavy orchestration, databases, caching, APIs, and control planes demands massive CPU-dense rack-scale infrastructure, not just GPUs. The catalyst prominently positions their upcoming 6th Gen EPYC "Venice" processors as the key enabler for next-generation dense racks, delivering leadership throughput under real-world power, cooling, and density constraints.
~EPYC Venice (Zen 6 architecture, up to 256 cores / 512 threads per socket) is projected to deliver exceptional rack-level performance. In AMD’s modeled 100 kW rack comparisons, Venice-powered systems are expected to achieve ~3.30x the throughput of NVIDIA’s Vera (88-core Olympus) baseline across a broad mix of agentic-supporting workloads.
~This builds on current-generation 5th Gen EPYC "Turin" (up to 192 cores), which already delivers ~2.37x rack throughput vs. Vera and ~1.6x vs. Intel’s Xeon 6980P (128 cores).
~ Liquid-cooled Turin deployments already support >27,000 CPU cores per rack today. Venice is architected to push this beyond 36,000 cores in the same rack class, dramatically increasing concurrent agent capacity and overall infrastructure efficiency.
2. Ownership vs renting compute from Hyperscalers matter to OpenAI and only owning $AMD chips can meaningfully lower token cost for enterprises.
~Eliminates cloud overhead: No provider margins, utilization buffers, or egress fees. Direct control over power contracts, cooling, scheduling, and orchestration at dedicated facilities.
~Helios optimizations at GW scale: Rack-level density (1.4 exaFLOPS FP8 per rack), high HBM4 bandwidth, EPYC orchestration for agentic workloads, and superior TCO/TDP. AMD's long-standing focus on tokens per dollar/watt shines here 20-40% efficiency edges in inference-heavy scenarios.
~At 1GW optimized deployment, inference hits $0.0003–$0.0005 per million tokens (community/analyst models tied to Helios metrics). This is dramatically lower than typical rented/cloud equivalents, especially for high-volume output tokens in agentic flows.
High token bills today, enterprises running heavy agentic/coding/analysis workloads can face $50-100M /month at current API rates (flagship models $5-30 /M output, scaled to massive volumes).
Post-Helios compression, same volume will drop to $10-15M/month (or better) via lower underlying costs passed through as pricing flexibility, volume tiers, caching, or batch discounts.
ROI thresholds collapse. More companies greenlight pilots → production → massive scaling. Agentic AI (autonomous workflows) multiplies token demand exponentially, but affordability removes the friction.
OpenAI gains flexibility, Unlike more cloud-dependent rivals (Anthropic), they can lower effective pricing, offer aggressive enterprise bundles, or absorb volume without margin destruction directly tackling "high token bill" complaints while maintaining profitability as usage explodes.
3. Agentic AI Models shifted CPU:GPU Ratio to 1:1 toward 3-5:1 with Explosively Token-Hungry Workloads
Agentic AI (autonomous, multi-step agents with planning, tool use, iteration, and self-correction) is fundamentally more compute and token intensive than conversational or single-turn generative AI.
Agentic AI. autonomous, multi-step workflows with orchestration, tool use, parallel agents, data movement, and enterprise integration has dramatically increased the importance of strong host CPUs alongside GPUs. This shifts the CPU-to-GPU ratio higher and makes balanced systems critical toward 1:1 to 5:1 as enterprises testing more than 5-10 agents.
AMD EPYC Venice excels
~Leadership core density (up to 256 Zen 6 cores per socket) for running many agents in parallel, orchestration layers, and high-throughput control-plane tasks.
~Superior performance-per-core and power efficiency ( up to 2.1x higher perf/core and 2.26x better SPECpower vs. NVIDIA Grace in benchmarks).
~Tight integration in Helios: One Venice CPU multiple MI450 GPUs per node, enabling efficient data feeding to GPUs ("zero-copy"), parallel execution, and full rack utilization for complex agentic loops.
Hyperscalers (Meta, Microsoft, Amazon, Google, Softbank) and AI natives (OpenAI, Anthropic...) are adopting high-core EPYC at scale specifically for these agentic demands, as CPUs now handle a larger share of non-model work (orchestration, policy enforcement, tool calls). This complements AMD’s lower-cost GPUs for overall TCO wins.
~Agents often generate 10–100x more tokens per task due to iterative reasoning chains, multiple tool calls, verification loops, and long-context orchestration.
~Goldman Sachs forecasts token consumption multiplying 24x by 2030 (to 120 quadrillion tokens/month) largely driven by agentic adoption in consumer and enterprise.
~Enterprise data shows agent-pattern workloads growing at 680% annualized rates, projected to surpass conversational AI in token volume by Q3 2026.
~Daily enterprise agent token consumption is already in the billions, with complex workflows (coding, workflows, analysis) amplifying this dramatically.
4. Competitive Edge: Winning Customers from Anthropic
Anthropic’s Claude models (especially Opus/Sonnet) excel in complex reasoning and agentic coding, commanding premium positioning. However, their higher underlying costs (heavier reliance on third-party cloud with margins) limit pricing flexibility compared to OpenAI’s owned Helios capacity.
Anthropic is on track to generate $10.9 billion in Q2 revenue. The company expects to achieve its first-ever quarterly adjusted operating profit of $559 million. However, sustaining full-year profitability remains challenging due to immense computing and model training costs
The truth is, Anthropic has no choice but to buy as much $AMD chips as possible if they want to compete with OpenAI or get investors attention. This 5% adjusted operating profit to revenue ratio is just pathetic.
Current pricing dynamics (2026): OpenAI already undercuts on many tiers ( flagship output tokens significantly cheaper than equivalent Claude Opus). Nano/mini models offer 5–10x advantages for volume work. Anthropic holds edges in long-context flat pricing and certain reasoning quality.
OpenAI after Helios Rack Ownership, At $0.0003–$0.0005/M effective costs, OpenAI gains massive headroom to:
~Aggressively discount high-volume agentic tiers or bundles.
~Offer “unlimited” enterprise plans or usage-based models that Anthropic struggles to match without margin erosion.
~Target cost-sensitive, high-throughput agent deployments (dev tools, automation platforms) where token bills explode.
Enterprises facing $ millions in monthly agentic bills will migrate to the provider delivering better economics at scale. OpenAI’s combination of strong models (o-series reasoning) lowest TCO positions it to erode Anthropic’s enterprise share, especially as agentic becomes the dominant token consumer.
Cheaper tokens expand the total addressable market dramatically. This feeds the data/model improvement loop, justifying further capex. AMD benefits from proven scale pulling in more customers (Meta, Oracle, Microsfot, Amazon, Softbank, TensorWave, LumaAI ... already aligned on Helios).
Conclusion:
Dr. Lisa Su has been laser focused on inference economics since at least 2022–2023, repeatedly emphasizing that the real battleground for AI scalability would be TCO, power efficiency (TDP), and ultimately tokens per dollar and per watt not just raw training FLOPS. While many viewed inference as a secondary, commoditized workload, Dr. Su architected AMD’s roadmap around rack-scale systems optimized for high-volume, sustained inference that would dominate as models matured and usage exploded. Helios represents the culmination of that multi-year bet: a fully integrated, open platform designed precisely for the economics of massive token throughput.
This deep, strategic partnership with OpenAI starting with the 1GW Helios deployment in H2 2026 and scaling to 6GW, is the embodiment of that shared vision. Both companies foresaw a future where agentic AI models evolve to become extraordinarily token-hungry: autonomous agents executing complex, iterative workflows with planning, tool use, verification loops, and long-context reasoning. These workloads can consume 100x more tokens per task than traditional chat or single-turn generation, driving exponential demand as capabilities improve and enterprises deploy them at scale.
By owning and optimizing this massive Helios capacity at GW scale, OpenAI achieves inference costs as low as $0.0003–$0.0005 per million tokens. This structural cost advantage allows OpenAI to absorb the coming token explosion profitably, dramatically lower effective pricing for enterprises, and win high-volume agentic workloads from higher-cost competitors like Anthropic. What was once a prohibitive monthly token bill becomes an affordable accelerator for productivity and innovation.
The OpenAI-AMD alliance validates Dr. Su’s prescient strategy and turns the Agentic flywheel into reality:
Collapsing inference costs
→ explosive token consumption
→ richer data and better models
→ accelerate greater demand.
This partnership doesn’t just address today’s economics, it positions both leaders at the center of the infrastructure buildout that will power AI’s next decade. By delivering the lowest inference economics at scale, OpenAI not only solves enterprise bill pain but gains a decisive weapon to win share from higher-cost rivals like Anthropic. And that is why @OpenAI and $META will deploy EPYC Dense Rack
Not Financial Advice! DYOR! Research Purpose Only!
4
1,298
21h
$HIMS Hims & Hers at The Economist's Inaugural Economics of Obesity and Metabolic Health Summit
Written by Craig Primack, MD, FACP, FAAP, FOMA
This week, I joined global policymakers, clinicians, and health innovators in Brussels for The Economist's inaugural The Economics of Obesity and Metabolic Health Summit. The gathering marked a recognition, at the highest levels of global health discourse, that obesity demands the same urgency, rigor, and systemic investment we bring to other chronic diseases. I joined the conversation to share what Hims & Hers has learned building access to care at scale and what modern care in Europe can and should look like.
The Access Crisis Is Real –and Getting Worse.
For decades, patients have been told obesity is a failure of willpower. It isn't. It is a chronic, relapsing disease, and the consequences of treating it as anything less are written in the data. Sixty four percent of UK adults are overweight or living with obesity, but NHS specialist weight management services are so overwhelmed that waiting lists have closed entirely across multiple regions, and where services remain open, the average wait is two to three years. This isn't a UK-specific problem. Traditional health systems around the world, the US included, were not designed to absorb this level of demand.
Digital health exists precisely to reach the people who aren’t getting the care they need because the traditional system wasn’t built with them in mind. A platform that someone can access from their phone, without the barriers of geography, cost, stigma, or a multi-year wait, can extend specialist-level support to populations that the current system simply cannot serve. That is not a disruption of healthcare. It is an expansion of it.
Getting Started Is Hard – but sticking to it is harder.
The statistic I shared that seemed to land hardest in the room was this: across the industry, roughly 80% of GLP-1 patients discontinue within six months. Not because the medication stopped working, but because they hit a side effect, or a plateau, or a moment of real doubt and didn’t have support in that moment. That is a system failure, not a patient failure. And it's where I think the conversation about access has to go deeper. Starting treatment is the easy part. Keeping someone in it is where traditional care fails because the model was never built for the moments between appointments.
The average wait time to see an obesity medicine specialist in the U.S. is approximately five months. Our customers have exchanged millions of messages with their care teams, most answered within three hours. That support and proximity helps change both experience and outcomes: a patient struggling at 9pm on a Tuesday can reach their care team at their time of need, not at their next scheduled visit, weeks or even months away. If treatment is going to work, people have to stay in it long enough for it to work. That means meeting them when they need support, not when the system happens to be available.
Medication Is Not Enough. Integrated Care Is.
One of the things I kept coming back to in Brussels is that GLP-1s are a genuine breakthrough, but they are not a complete solution on their own. When you suppress appetite, every meal has to do more work. Patients need to be eating enough protein, preserving lean muscle, and maintaining energy. That requires guidance and support, not just a prescription.
The challenge I raised with the group is that in traditional settings, building that kind of integrated care means sending a patient to multiple providers, multiple referrals, multiple appointments. Most people don't follow through, not because they don't want to get better, but because the system makes it too hard. What we've built at Hims & Hers helps remove that friction. Medication, nutritional coaching, activity guidance, clinical support, all in one place, on the patient's schedule. Those aren't small details. They're what can turn a treatment plan into a lasting outcome.
Expanding Access and Doing It Safely Are Not Competing Goals
There was a lot of discussion in Brussels about standards, and rightly so. As digital health grows, not every platform operates the same way, and that gap has real consequences for patients. It’s critical to understand that accessibility and clinical rigor are not in tension. At Hims & Hers, every customer completes a structured, comprehensive medical intake before their provider makes a treatment decision — medical history, current medications, relevant conditions, lifestyle factors, all of it reviewed by a licensed clinician. If treatment isn't appropriate, we don't prescribe. Full stop. Technology is how we reach more people. Independent clinical judgment is how we take care of them. That should be the baseline expectation for the entire sector, not a differentiator. It's what every patient deserves, and it's what earns the trust of the health leaders we want to work alongside.
The conversation in Brussels reinforced what the data already shows: the gap between the scale of the obesity epidemic and the capacity of traditional care systems is not closing on its own. Closing it will require clinical rigor, genuine accessibility, and the kind of sustained support that keeps patients in treatment long enough for it to change their lives. That is what Hims & Hers is building and why conversations like this one matter.
Source: hims dot com
Jun 12
$HIMS got trashed by analysts, and retail influencers at Feb/March low.
This business is going to grow 60-70% with Eucalyptus and more in 2027. It should not be trading at
TTM P/S 2.8x
Fwd P/S 1.6x
This kind of multiple is pricing $HIMS to die or declining revenue, which is completely false.
2026 is scaling/expanding year internationally.
2027 will have much better profitability, where I will be actively using P/E more. However, I still believe P/E is not really a good indicator for a young, disruptive company, we can use it 5-6 years after IPO.
Most of these folks will never remind you that they were bearish and failed. And then they will not mention $HIMS business that trying its best to grow and limit dilution, while their own holdings diluting the shit of out shareholders.
I dont want to say names, but you can roll back those clips/video in Feb/March.
It is really a bad idea to short @MikeLongTerm high conviction long term.
Because I know what I own. And I dont offer Financial Advice!
DYOR!
Video source: youtube.com/watch?v=2LRzttI1…
3
5
45
5,103
23h
$AMD shareholders just realized $TSM is on track to meet 140k WPM on N2(2nm) toward end of 2026 with 75-80% yield. (Analysts are still at 70-90k)
EPYC Venice and MI455X are on 2nm. Demand for EPYC Venic or Agentic AI Rack(CPUs dense) is extremely high. TSMC Expansion momentum is @AMD momentum.
Read more below
Jun 13
BREAKING $AMD| $TSM Expands Production🚀
TSMC, together with seven supply chain partners including Fanxuan System, has broken ground on facilities in the Pingtung Science Park. During the ceremony on June 12, TSMC Chairman Wei Zhejia stated that semiconductor demand will remain strong for the long term, and Taiwan is the most important place for semiconductor development. TSMC continues to expand domestically, extending from Chiayi and Kaohsiung further to Pingtung as part of its comprehensive island-wide layout.
A. Taiwan remains the core for TSMC’s most advanced processes and R&D, even as the company expands overseas.
~2nm process: Primary production bases in Hsinchu (Baoshan) and Kaohsiung.
~3nm process: Largest manufacturing center at Tainan’s Fab 18
~Tainan and Kaohsiung are becoming key hubs for upgrading Taiwan’s semiconductor cluster.
B. Expanding Advanced Packaging
~Strong growth in CoWoS and SoIC capacity to meet surging demand from NVIDIA, AMD, Broadcom, and cloud providers’ self-developed ASICs.
~New/expanded sites include Chiayi AP7 and Southern Taiwan Science Park (Nanke) AP8.
~This will drive demand across equipment, materials, plant engineering, substrates, and testing supply chains.
C. Aggressive Expansion
~Full north-to-south expansion covering Hsinchu, Taichung, Chiayi, Tainan, and Kaohsiung.
~Dual focus on advanced wafer manufacturing advanced packaging.
~Analysts view this as not just capacity growth, but a strategic integration of advanced tech, packaging, and supply chain clustering.
~With global AI infrastructure booming, Taiwan will continue as TSMC’s most critical base for R&D and volume production, further strengthening Taiwan’s central role in the global semiconductor supply chain.
Source: Ctee
4
2
48
7,029
Jun 13
$QQQ $SPY @TheCompoundNews
Why the Knockout Punch Never Comes | TCAF 246
youtube.com/watch?v=olbnxPdO…
2
2
2,178
Jun 13
BREAKING $AMD| $TSM Expands Production🚀
TSMC, together with seven supply chain partners including Fanxuan System, has broken ground on facilities in the Pingtung Science Park. During the ceremony on June 12, TSMC Chairman Wei Zhejia stated that semiconductor demand will remain strong for the long term, and Taiwan is the most important place for semiconductor development. TSMC continues to expand domestically, extending from Chiayi and Kaohsiung further to Pingtung as part of its comprehensive island-wide layout.
A. Taiwan remains the core for TSMC’s most advanced processes and R&D, even as the company expands overseas.
~2nm process: Primary production bases in Hsinchu (Baoshan) and Kaohsiung.
~3nm process: Largest manufacturing center at Tainan’s Fab 18
~Tainan and Kaohsiung are becoming key hubs for upgrading Taiwan’s semiconductor cluster.
B. Expanding Advanced Packaging
~Strong growth in CoWoS and SoIC capacity to meet surging demand from NVIDIA, AMD, Broadcom, and cloud providers’ self-developed ASICs.
~New/expanded sites include Chiayi AP7 and Southern Taiwan Science Park (Nanke) AP8.
~This will drive demand across equipment, materials, plant engineering, substrates, and testing supply chains.
C. Aggressive Expansion
~Full north-to-south expansion covering Hsinchu, Taichung, Chiayi, Tainan, and Kaohsiung.
~Dual focus on advanced wafer manufacturing advanced packaging.
~Analysts view this as not just capacity growth, but a strategic integration of advanced tech, packaging, and supply chain clustering.
~With global AI infrastructure booming, Taiwan will continue as TSMC’s most critical base for R&D and volume production, further strengthening Taiwan’s central role in the global semiconductor supply chain.
Source: Ctee
Jun 12
$AMD could reach $2 Trillion Market Cap FY2027 🧵
W/ $TSM to solve @OpenAI @AnthropicAI Tokenomic Crisis
Not Financial Advice! DYOR!
“As these agents do work, they spawn more CPU tasks... We certainly see the movement towards where in the past the CPU to GPU ratio was primarily just as a host node in like a 1:4 or 1:8 configuration, now changing and getting closer to a 1-to-1 configuration or even... you can even imagine if you get lots and lots of agents that you could have more CPUs than GPUs.”
— Dr. Lisa Su, AMD Chair and CEO
Dr. Lisa Su’s observation captures the seismic shift now driving the tokenomic crisis, the transition from GPU-centric training to CPU-intensive, always-on agentic AI. What was once a supporting role for CPUs has become a primary bottleneck, colliding with severe supply constraints and fueling unsustainable inference costs for enterprises.
1. Primary Causes of the Tokenomic Crisis
A.Explosive Agentic AI Demand and Token Multiplication
Agentic workflows with multi-step reasoning, tool calling, orchestration, retries, and long-horizon autonomy consume 5–100x more tokens per task than traditional prompting. Frontier models like Anthropic’s Fable 5 (premium pricing verbose outputs) and OpenAI’s advanced variants amplify this effect. Projections show global token demand potentially rising ~24x by 2030, with enterprises reporting budgets exhausted in weeks rather than years.
Anthropic Fable 5 (Mythos-class): $10 / $50 per million input/output tokens explicitly ~2x their prior flagship (Opus 4.8 at $5/$25). It's positioned as a premium agentic/reasoning model. This is unsustainable, hence we are seeing companies crying about Tokens bills.
OpenAI GPT-5.5 (current flagship): $5 / $30 per million, more affordable on a direct sticker-price basis than Fable 5. They also offer cheaper tiers like GPT-5.4 ($2.50/$15) and mini/nano variants for cost-sensitive work
B. CPU Supply Crunch as the Hidden Bottleneck
Traditional AI favored GPU-heavy ratios (1 CPU : 4–8 GPUs). Agentic systems reverse this dynamic to 1-5 CPU to 1 GPU,where CPUs manage orchestration, data loading, state management, external calls, and parallel task spawning, often leaving expensive GPUs idle while waiting on the host. The industry is rapidly shifting toward higher CPU ratios (or AMD new Agentic AI Rack). Server CPUs from AMD (EPYC) and Intel are largely sold out for 2026, with lead times stretching weeks to months and prices rising 10–35% in tight markets. TSMC’s heavy focus on AI accelerators has further squeezed CPU wafer capacity, raising overall cluster costs that flow directly into higher token pricing. Luckily, EPYC Venice has arrived and currently in mass production.
C. Power, Networking, and Systemic Inefficiencies
Poor utilization, high power draw, and legacy networking overhead compound the problem. Hyperscalers and enterprises now demand balanced, power-efficient rack-scale solutions to scale sustainably without exploding operational expenses.
Surging consumption meets hardware scarcity
→ elevated marginal costs
→ provider pricing pressure and enterprise ROI scrutiny.
2. Why Increased TSMC 2nm Allocation for AMD Will Significantly Ease Token Costs
AMD has secured strong early access to TSMC’s 2nm (N2) process and significant allocation, positioning EPYC Venice as one of the first major HPC products to ramp on it, with production already advancing in Taiwan and Arizona. This allocation advantage delivers immediate relief on supply, performance, and efficiency. Bringing token cost at GW Scale to as low as $0.0003-$0.0005/M Tokens. TSMC is ramping up 2nm Fabs at the faster pace than prior 3nm expansion, up to 12 2nm/1.4nm Fabs by 2027/2028 to service $AMD Agentic AI demand.
~Core Density & Performance Up to 256 Zen 6 cores per socket, substantial compute uplifts, and higher memory bandwidth directly alleviating the orchestration bottleneck in agentic workloads.
~2nm GAA transistors provide major improvements in performance-per-watt, critical for power constrained data centers and lower energy-per-token economics.
~Accelerated volume ramp (with Verano as the follow-on) will ease the 2026–2027 crunch, allowing hyperscalers like OpenAI and Meta to deploy more balanced clusters faster than allocation-constrained competitors.
3. The AMD Agentic AI Rack and Helios: Purpose-Built for the Agentic Era
AMD is addressing the exact gap Dr. Su highlighted with dense EPYC Venice “Agentic AI Racks”, high-core-count CPU-optimized racks positioned between traditional servers and full GPU racks. These deliver massive orchestration capacity for fleets of agents.
~Optimized CPU:GPU Balance, Designed for 1:1 to 3–5:1 ratios that eliminate idle time and maximize end-to-end throughput.
~Rack-Scale Density, Current EPYC Turin racks already exceed 27,000 cores; Venice pushes beyond 36,000 cores per rack, delivering up to 3.30x rack-level throughput versus NVIDIA Vera baselines in agentic workloads.
~Efficiency Gains, Lower power per token through superior density, liquid cooling compatibility, and system-level optimizations. Projections show potential inference costs dropping to $0.0001–$0.0005 per million tokens (or even lower with Verano).
H2 2026–2027: Venice-powered Agentic AI Racks and initial Helios deployments (already secured with major hyperscalers) relieve CPU constraints and lower underlying infrastructure costs, supporting token price relief. Pretty much CPUs are sold out for the next 3-5 years.
Conclusion:
While much of the industry chased raw training FLOPs and GPU scarcity narratives, Dr. Lisa Su positioned AMD early and decisively around inference nearly 4 years ago, the real long-term driver of token economics. She recognized that agentic AI would fundamentally invert workloads, making efficient, abundant CPUs the key to sustainable scaling rather than GPU-only supremacy.
By doubling down on high-core-density EPYC platforms, rack-scale systems like Helios and dedicated Agentic AI racks, and securing leading TSMC 2nm allocation, AMD is not merely reacting to the tokenomic crisis, it is actively solving it. This strategic clarity enables hyperscalers and enterprises to deploy balanced, power-efficient infrastructure that drives down real $/token costs, improves utilization, and restores economic viability to large-scale agentic deployments.
As Dr. Su anticipated the problem years in advance, AMD’s execution is now delivering the antidote. The result will be lower token prices, broader AI adoption, and a more balanced ecosystem where CPUs reclaim their central role AKA the brain. In the agentic era, the companies that solve the orchestration and efficiency bottlenecks, not just the matrix multiplications will define the winners. AMD, under Dr. Su’s leadership, is well-placed to be biggest TSMC customer in term of wafer as early as 2028.
Not Financial Advice! DYOR!
4
34
13,922
Jun 13

Wow, this is genuinely awful. AI accelerator development takes two years until launch, and yet they evaluate the performance of the people working on it every six months? This is exactly why MTIA is shit.

2
3
24
3,775