@AnthropicAI | prev @uwcse
- Tweets 422
- Following 1,054
- Followers 1,900
- Likes 1,366









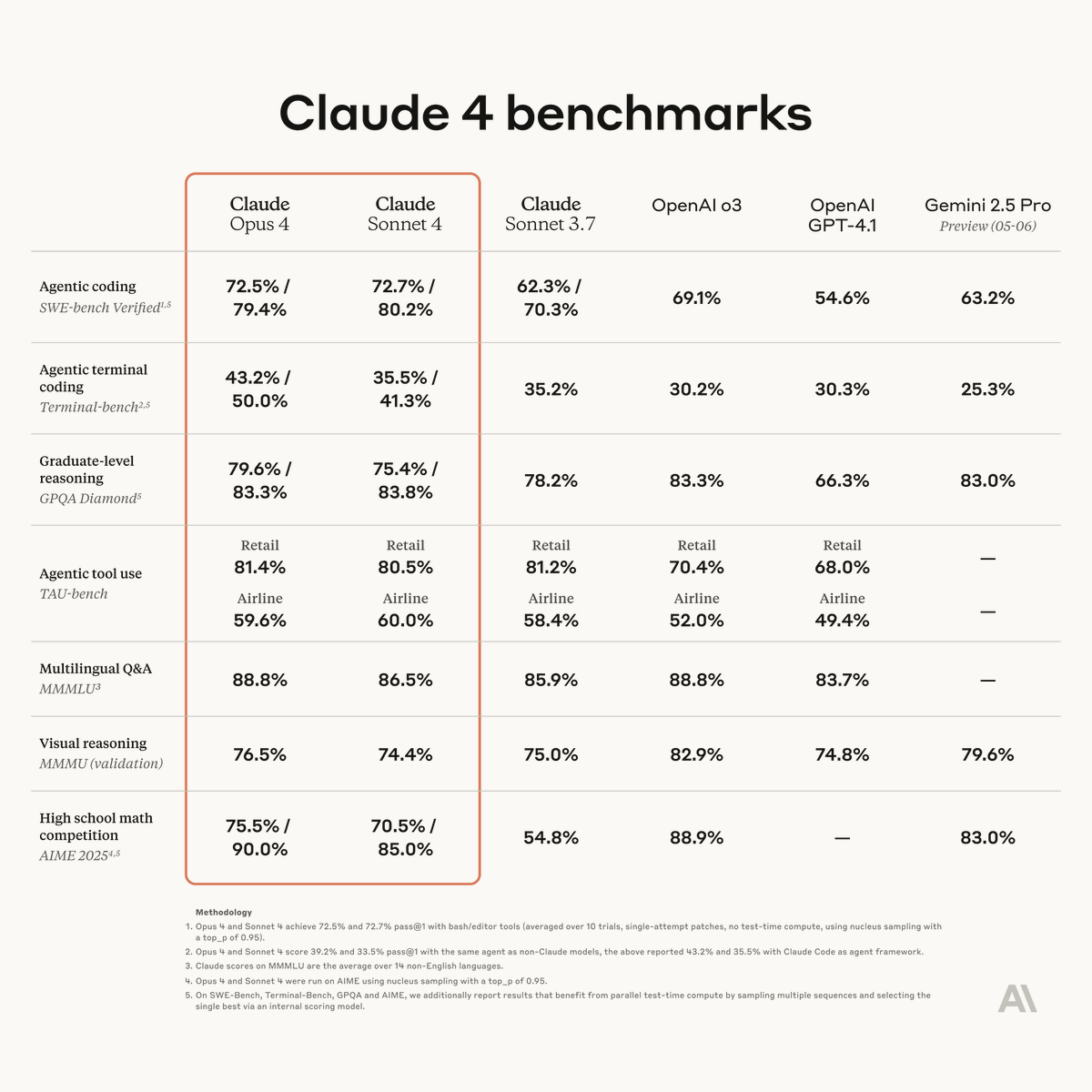
ALT A benchmarking table titled Claude 4 benchmarks comparing performance metrics across various capabilities including coding, reasoning, tool use, multilingual Q&A, visual reasoning, and mathematics.




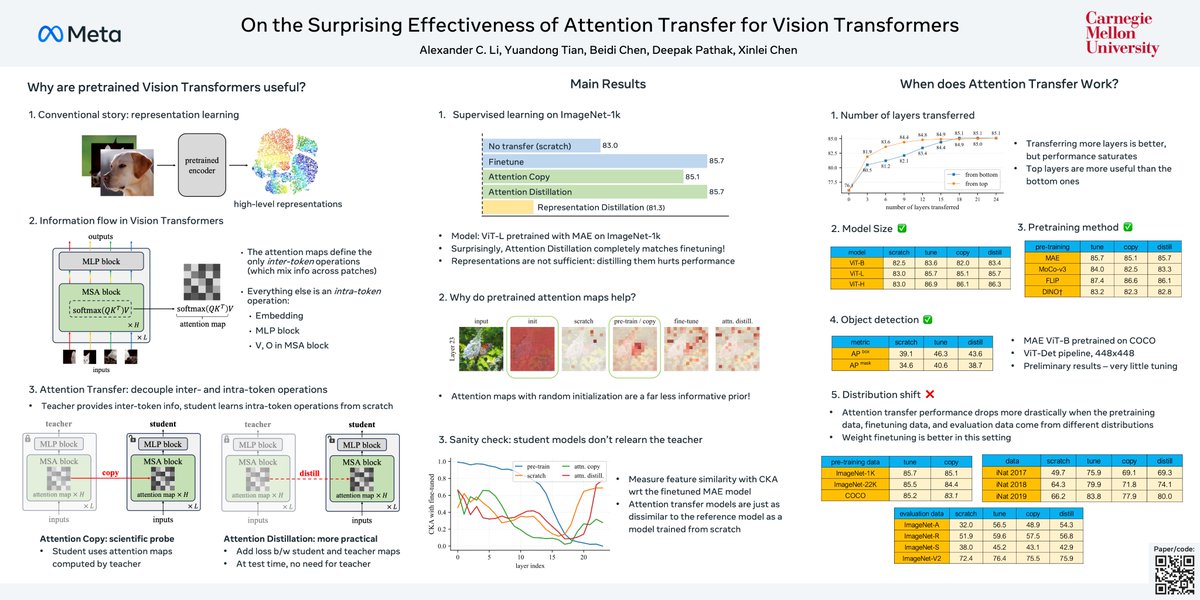


ALT Overview of Akari's research. More information is at https://akariasai.github.io/


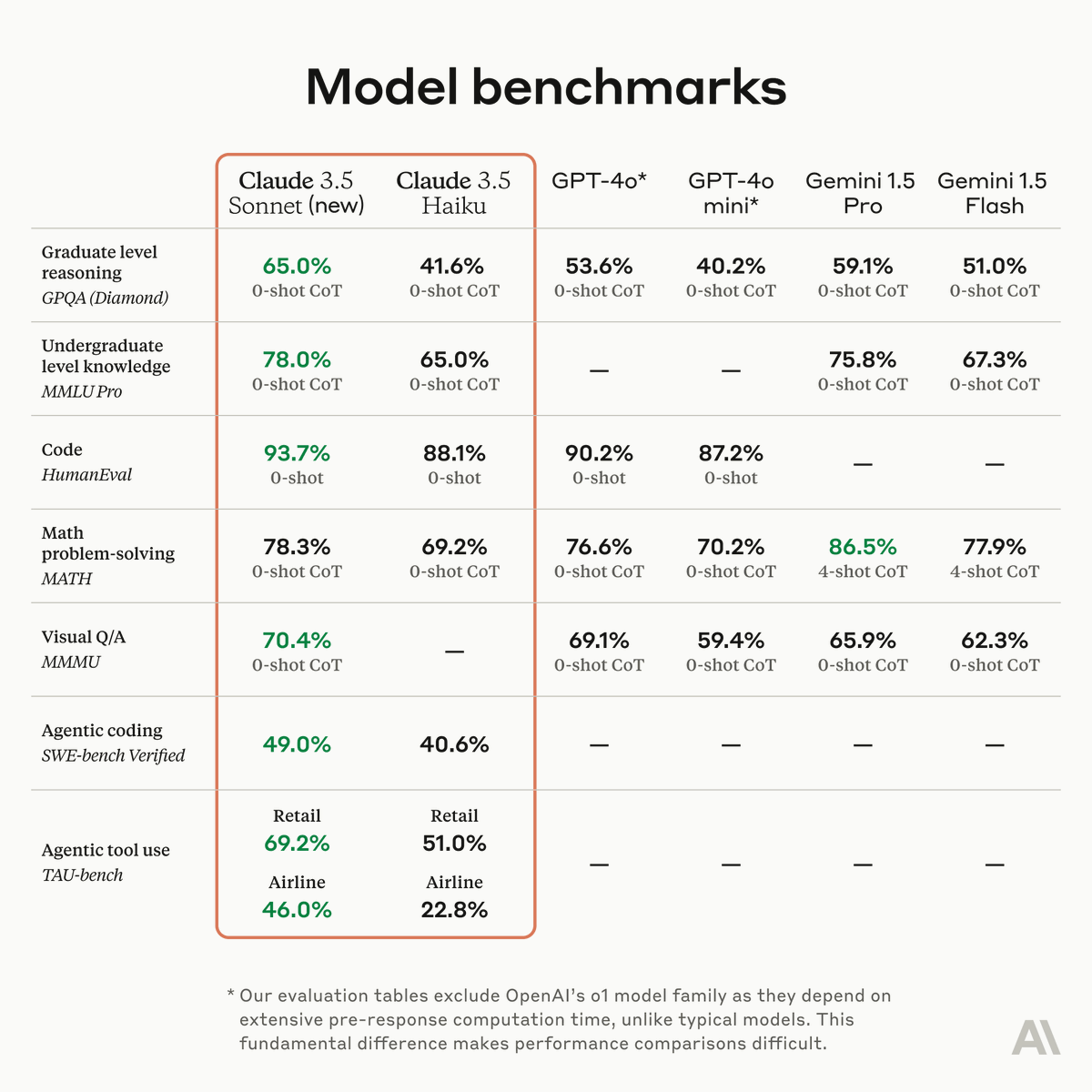
ALT A benchmark comparison table showing performance metrics for multiple AI models including Claude 3.5 Sonnet (new), Claude 3.5 Haiku, GPT-4o, and Gemini models across different tasks.






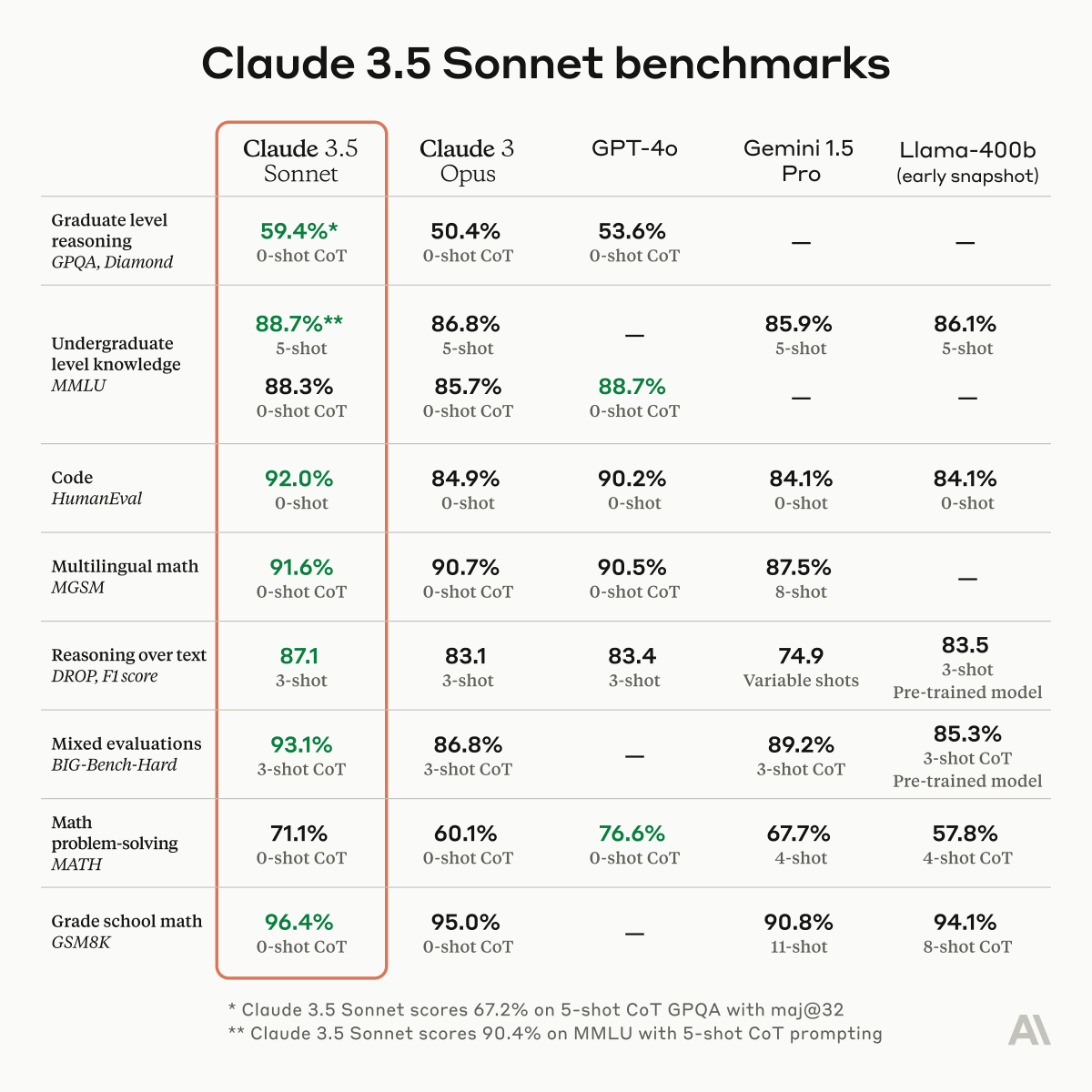
ALT Benchmark table showing Claude 3.5 Sonnet outperforming (as indicated by green highlights) other AI models on graduate level reasoning, code, multilingual math, reasoning over text, and more evaluations. Models compared include Claude 3 Opus, GPT-4o, Gemini 1.5 Pro, and Llama-400b.