
DNA insights with privacy, autonomy, and boundless curiosity.
Joined December 2024
- Tweets 265
- Following 79
- Followers 890
- Likes 636
22 Photos and videos












Monadic DNA retweeted

Apr 27
this is why we need @Amino_Chain @MonadicDNA
i like to call it "DeSci" or Decentralized Science
2
1
5
278
Monadic DNA retweeted

Standard short read genome sequencing is pretty much a commodity now. The value is actually in the interpretation/reports.
Apr 22

We just launched full genome sequencing for $599.
Not a panel.
Not a fraction.
All 3 billion base pairs.
30× coverage.
This changes what “DNA testing” actually means. 🧵
2
6
50
7,642
Monadic DNA retweeted

Apr 22
We are building self-sovereign personal genomics!
1
3
139
Monadic DNA retweeted
Apr 22
First talk I'll ever give about Dark Bio... no pressure... none whatsoever... 🙈

25
21
298
22,265
Apr 21
And so many regular people are now entering their confidential medical information, including DNA and lab reports, into public AI tools and irrevocably hurting their future employability and insurability.
Use Monadic DNA Explorer instead.
We use Nillion's confidential LLMs and storage so nobody snoops on your data!

57% of enterprise employees admit to entering confidential company data into public AI tools.
That includes internal documents and business information.
AI is already being used in sensitive environments.
1
1
6
387
Monadic DNA retweeted

Apr 21
Following on from Kitchen table genomes/liquid biopsy. There are two forces at work, a centralization one and a decentralization one. Large companies are trying to trap everything in central data centers with proprietary data streams, giving them a moat and control, others are pushing to run AI and other things locally empowering individual users. Same is happening to bio/medical data including sequencing.
Apr 20

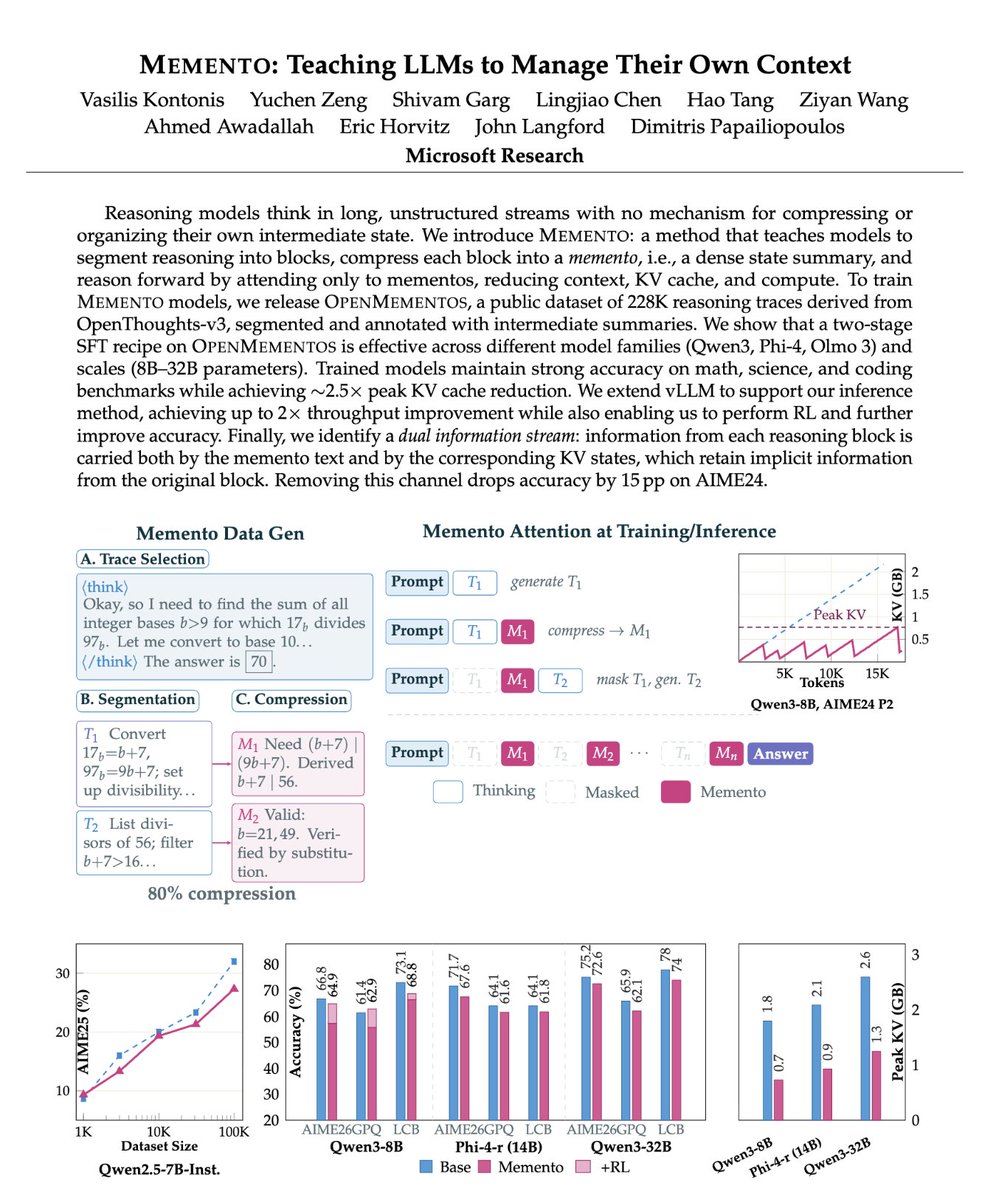
Microsoft just solved the context window problem.
Right now, every AI suffers from a fatal flaw: the "context window problem."
When an AI reasons through a complex problem, it generates a massive chain-of-thought. But there is a catch. It has to keep every single token of that thought in its active memory.
The technical term is the "KV Cache."
The longer the AI thinks, the heavier it gets. It slows down. It gets expensive. Eventually, it runs out of space.
We thought the only fix was renting bigger, more expensive cloud GPUs to hold all that context.
Microsoft just proved us wrong. They published a paper called "MEMENTO."
Instead of giving the AI a bigger memory, they taught it how to forget.
Here is how it works:
Instead of generating one endless stream of consciousness, a Memento-trained model breaks its reasoning into small blocks.
After it finishes a block, it writes a dense, highly compressed summary of its own logic—a "memento."
Then, it does something unprecedented.
It physically deletes the entire previous reasoning block from its memory cache.
It only carries the memento forward. The model reasons, extracts the core logic, and instantly drops the dead weight.
The results rewrite the economics of running AI.
• Context length compressed by 6x.
• Active memory usage (KV cache) reduced by 2.5x.
• Zero loss in math, science, or coding accuracy.
And here is the real implication.
Big tech has been charging you by the token for massive context windows you don't actually need.
With this architecture, small businesses and solo operators can run complex, multi-step autonomous agents entirely locally.
You don't need an enterprise cloud setup. A standard machine running an open-source model can now reason indefinitely without overflowing its memory. No API fees. Complete privacy.
We spent the last two years trying to give AI an infinite memory.
It turns out, the secret to smarter AI isn't remembering everything.
It's knowing exactly what to forget.
1
5
15
2,186
Apr 20
At-home sequencing is the future!
However, until it becomes cheap, easy and reliable, people will still turn to services which compromise their anonymity and privacy.
Our upcoming Batcher app provides an anonymous mixing service using reliable lab partners for your DNA exploration needs!
Apr 19

Human genome sequencing:
2003:
$3,000,000,000
global effort
years of research
2026:
your kitchen table
a few hundred $
Hard not to be excited for the future.
iwantosequencemygenomeathome…
iwantosequencemygenomeathome…
2
7
610
Apr 20
Any data our apps absolutely need to store get put on nilDB.
The Vercel breach put the problem in plain sight.
Too many systems still keep sensitive logic and data stored in one place.
nilDB exists to break that pattern.
- Sensitive data is split before it is stored
- It is distributed across multiple nilDB nodes
- No single node holds the complete secret
- No single breach reveals the whole dataset
That’s why Nillion matters: it gives builders a privacy layer for sensitive data.

2
155

The Vercel breach put the problem in plain sight.
Too many systems still keep sensitive logic and data stored in one place.
nilDB exists to break that pattern.
- Sensitive data is split before it is stored
- It is distributed across multiple nilDB nodes
- No single node holds the complete secret
- No single breach reveals the whole dataset
That’s why Nillion matters: it gives builders a privacy layer for sensitive data.
23
34
142
6,956
Monadic DNA retweeted

one of the reasons i became a medical geneticist: the genome is the only medical test where we measure once, but our interpretation evolves indefinitely.
as our models and variant knowledge mature, the same data yields new truths, and eventually, actionabilities.
the genome (and its derivative products) are the ultimate substrates for AI in medicine.
Apr 17

I'm lucky enough to have a great doctor and access to excellent Bay Area medical care. I've taken lots of standard screening tests over the years and have tried lots of "health tech" devices and tools.
With all this said, by far the most useful preventative medical advice that I've ever received has come from unleashing coding agents on my genome, having them investigate my specific mutations, and having them recommend specific follow-on tests and treatments.
Population averages are population averages, but we ourselves are not averages. For example, it turns out that I probably have a 30x(!) higher-than-average predisposition to melanoma. Fortunately, there are both specific supplements that help counteract the particular mutations I have, and of course I can significantly dial up my screening frequency. So, this is very useful to know.
I don't know exactly how much the analysis cost, but probably less than $100. Sequencing my genome cost a few hundred dollars.
(One often sees papers and articles claiming that models aren't very good at medical reasoning. These analyses are usually based on employing several-year-old models, which is a kind of ludicrous malpractice. It is true that you still have to carefully monitor the agents' reasoning, and they do on occasion jump to conclusions or skip steps, requiring some nudging and re-steering. But, overall, they are almost literally infinitely better for this kind of work than what one can otherwise obtain today.)
There are still lots of questions about how this will diffuse and get adopted, but it seems very clear that medical practice is about to improve enormously. Exciting times!
9
8
103
17,403
Apr 15
Genome editing is getting safer, but there’s an obvious question almost no one is asking: what happens to your DNA data once it’s sequenced?
The new FDA guidance focuses on catching unintended edits, but it mostly skips over how this data is stored or who can access it, even though your genome is permanent and uniquely identifying.
We think your genetic data should stay encrypted the whole time, and that analysis should happen without exposing the raw data using cryptographic techniques like FHE, MPC, TEEs, and zero-knowledge proofs.
People should have clear control over what gets shared and when.
Better editing is real progress, but without strong data protection, it creates new dangers.

🚨NEW FDA Draft Guidance Safety Assessment of Genome Editing in Human Gene Therapy Products Using Next-Generation Sequencing #FDA #Regulatory #geneediting #genetherapy
Top 5 Takeaways -
1) NGS becomes the regulatory backbone for genome editing safety
2) FDA expects a layered, redundant approach to off-target assessment
3) Low-frequency events matter and must be detectable
4) Patient genetics is now explicitly part of risk assessment
5) Genome integrity (translocations) is no longer optional for DSB-based gene editing systems
fda.gov/regulatory-informati…
1
173
Apr 14
Motion sickness is written into the body more than most people realize.
In a genome-wide study of 80,494 individuals, researchers identified 35 SNPs significantly associated with susceptibility. Individuals in the top 5% of genetic risk had over 6× higher odds of frequent motion sickness compared to the bottom 5%.
Some of the strongest signals:
• rs66800491 near PVRL3 (eye development)
• rs10514168 near TSHZ1 (inner ear development)
• rs2153535 near MUTED (balance)
• rs2551802 between HOXD3/HOXD4
• rs9906289 in HOXB3
These variants cluster around systems that maintain equilibrium. Inner ear structure, neural signaling, even glucose regulation all appear to shape how the brain processes motion.
The biology extends further. The same genetic architecture overlaps with migraines, vertigo, morning sickness, and postoperative nausea. Several variants show effects up to 3× stronger in women.
Motion sickness is not just situational. It reflects how sensory conflict is processed at a systems level, influenced by development, metabolism, and neural wiring.
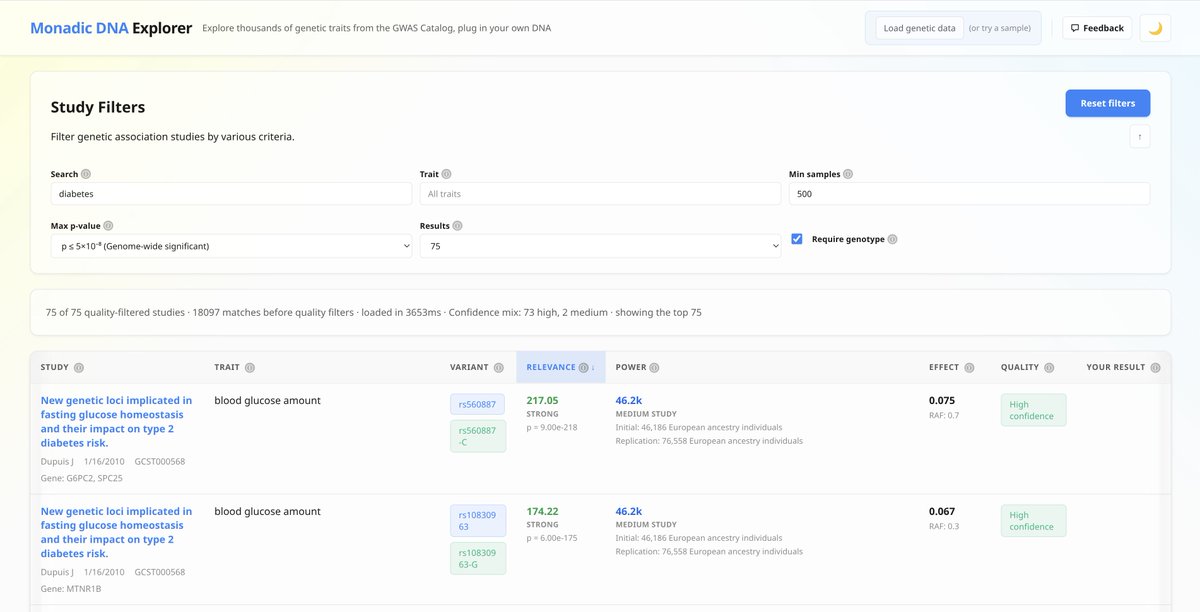
If you have your genetic data, you can look up your own propensity in Explorer.
explorer.monadicdna.com/
Study: Genetic variants associated with motion sickness point to roles for inner ear development, neurological processes and glucose homeostasis
Authors: Hromatka, Tung , et al
ALT Motion sick person in the back of a car Photo by Elvis Bekmanis on Unsplash
4
136
Monadic DNA retweeted
Just because an AI agent did something, doesn't mean it did it properly.
It's great that we have these powerful tools but there are so many ways for bioinformatics to go wrong. You shouldn't trust a pipeline that hasn't been carefully validated.
Apr 8

i got my whole genome sequenced two years ago and forgot about it.
last week i told my ai agent (@laukiantonson) to dig up my DNA files
• it dug up a two-year-old email
• found the download link
• pulled down 67 gigabytes of raw DNA.
• rented a 32-core, 64GB machine for a few hours — total cost: $5
• aligned 21 million long reads to the human reference genome — 99.83% mapped
• called 5.8 million genetic variants using a two-pass neural network
• phased every variant — separated maternal vs paternal inheritance
• annotated all 5.8M variants against ClinVar, PharmGKB, and gnomAD
• corrected for population-specific bias in the medical literature
• health risk map across 39 conditions flagged in every body system
• drug compatibility guide for 141 medications color-coded by genome response
• nutrient metabolism - 71 variants affecting absorption of vitamins, minerals, iron
• traits, ancestry going back 40,000 years, neanderthal DNA breakdown
$5 in compute. 8 hours. no bioinformatician. no doctor. just one instruction.
we've genuinely reached a point where an ai agent can take your raw genome and hand you back a full personal health profile in a single shot. i had no idea this was even possible.

2
2
45
3,284
Apr 9
We never upload your sensitive genetic data to AI companies.
By default, your DNA is analyzed using an open-source LLM inside a Trusted Execution Environment from @Nillion.
Nobody..not us, not them..can intercept, read, or retain it.
- Got a GPU? Run everything locally with @Ollama.
- Want the latest frontier model? Bring your own @HuggingFace API key.
Your genome stays under your control with zero compromises.
explorer.monadicdna.com/
1
108
Apr 8
How we keep your DNA analysis 100% private, all on your device:
- We download the full public @GWASCatalog
(millions of trait associations) straight into your browser's IndexedDB
- Your (~100k) raw results are queried instantly with in-memory SQLite via SQL.js
- All trait matching & computations run locally in Web Workers (no data ever leaves your machine)
- We let those with a local GPU use @ollama for AI queries
We literally cannot access your DNA data, even if we wanted to.
explorer.monadicdna.com/
1
208
Apr 7
Your DNA is the most sensitive data you have.
Why upload it to a company?
Monadic DNA Explorer analyzes your genome locally in your browser.
• 1M genetic traits
• AI-powered insights
• Your DNA never leaves your device
1
2
110
Apr 6
Don't plug your DNA into ChatGPT!
AI assistants do badly with large datasets, make results up and retain copies of your data.
Monadic DNA Explorer lets you explore your data securely on your computer with access to secure, private LLMs!
1
4
103
Monadic DNA retweeted

Apr 2
@nillion is building what they call a blind computer.
plain english: your data never leaves your device unencrypted. When it gets processed by AI the computation happens on the encrypted version. The nodes running the computation cannot see what they are working with.
Not "we promise not to look." structurally impossible to look. the mathematics prevent it.
They launched nilGPT, an AI chatbot where your conversation history is stored encrypted across decentralised nodes. The operator cannot read your chats. By the end of Q2 2025 it had processed 1.3 million inference calls.
x.com/nillionnetwork/status/…
@MonadicDNA is doing the same for genetic data. sequencing and analysing dna under full encryption. no one in the network sees your genetic information, including the people running the service.
nilGPT is now live for everyone.
While other chatbots ask for your trust, we built one that doesn’t need it.
Watch this 👇
1
1
3
109