
PhD Student at @MIT_CSAIL working on data-centric AI
Joined September 2020
- Tweets 42
- Following 515
- Followers 350
- Likes 899
1 Photos and videos

Pinned Tweet

3 Jun 2023
Excited to announce that I will be starting a CS PhD at @MIT_CSAIL in the fall w/ NSF GRFP funding, advised by @sarameghanbeery! After graduating this week with my BS MEng from MIT, I'm going to be at @ETH_en this summer, please let me know any recommendations in the area!
9
6
159
19,605
Neha Hulkund retweeted
I’ll be attending #CVPR2026 this week, June 2–7, and presenting:
Vibe Spaces for Creatively Connecting and Expressing Visual Concepts
🗓️ Saturday June 6 at 4:45 pm
📍 Poster 44 in Exhibit Hall A
Happy to chat at @CVPR – come to our poster or DM if you’re interested!

1
4
47
2,564
Neha Hulkund retweeted

Jun 2
Excited to share ID-Sim, our identity-focused similarity metric, presenting at #CVPR2026 this week in Denver! 🎉
Humans are remarkably good at distinguishing highly similar objects across different contexts.
We asked: can we train a metric that does the same?
2
12
46
6,948
Neha Hulkund retweeted

As a geometric ML researcher, I noticed pseudoscalars don’t get enough attention! Read on to see what pseudoscalars can do for you.
1
2
3
410
Neha Hulkund retweeted

Apr 26
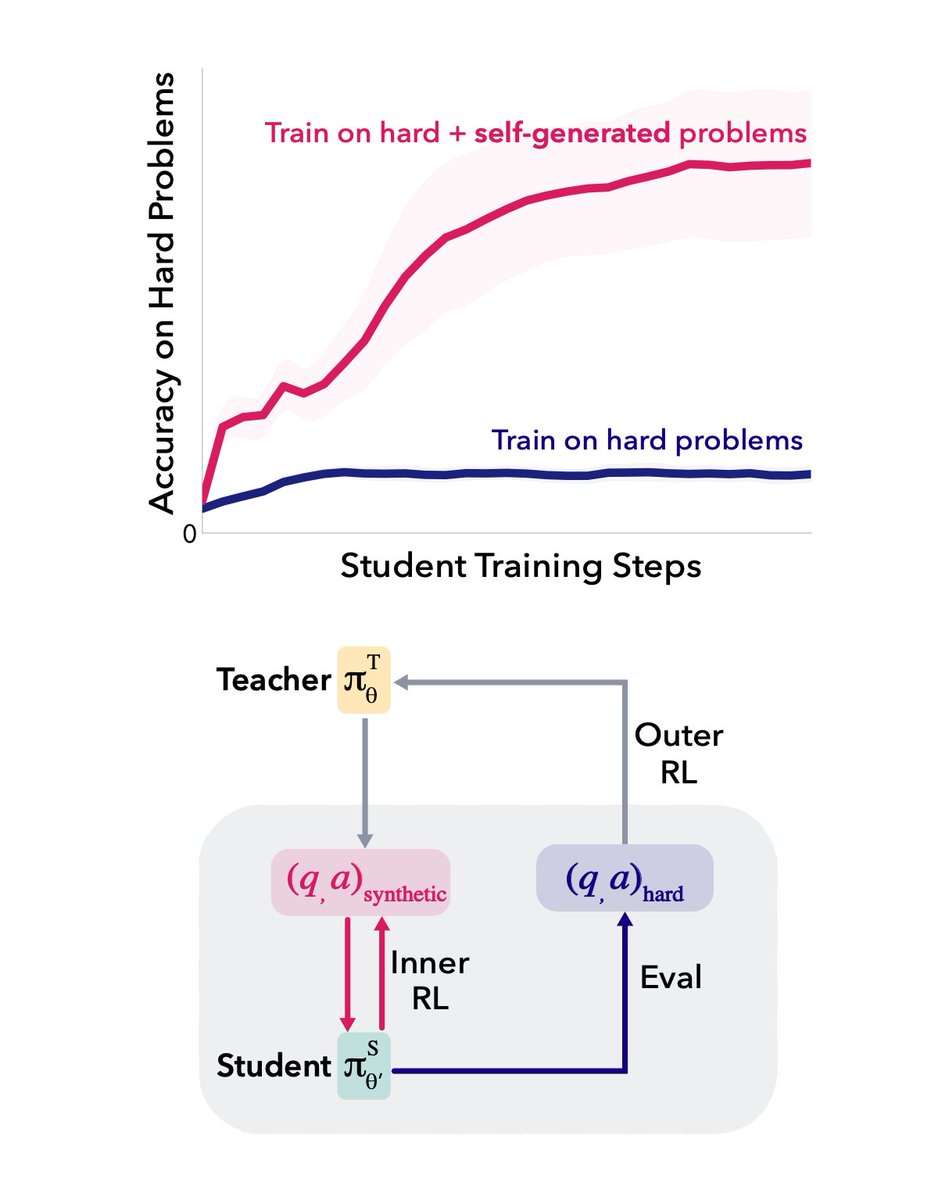
LLMs can learn to self-generate curricula for hard problems that they can't yet solve! Using meta-RL, with rewards grounded in learning progress, models produce their own stepping stones that kickstart learning on hard problems where direct RL plateaus.
Poster at the ICLR RSI workshop today!
Jan 27

Can a model learn to break its own reasoning plateau?
In our new paper, we show that LLMs can be taught with meta-RL to generate their own "stepping stones" that kickstart learning on hard math problems (0/128 success rate) where direct RL fails.
Paper 📝: arxiv.org/abs/2601.18778
Blog post 🌐: ssundaram21.github.io/soar/
(1/n)

1
24
171
16,762
Neha Hulkund retweeted

Mar 31
NVFP4 allows models to be quantized to 4 bits without too much performance degradation, but can we push 4-bit performance even further?
Today, we're releasing a new class of low-precision block-scaled data types that natively adapt to your input data: for 4-bit quantization, IF4 (Int/Float 4) allows each scaled group of 16 values to be saved as FP4 or INT4 depending on which option offers less error. Selections are recorded using the scale factor’s sign bit, which is unused in NVFP4, allowing IF4 to offer better performance with no memory overhead!
Our data types provide better downstream accuracy in LLMs, they can be implemented efficiently in next-generation hardware accelerators, and they reveal some interesting insights about low-bit quantization! 🧵

14
83
438
52,304
Neha Hulkund retweeted

Feb 24
Targeted instruction tuning for LLMs involves selecting a subset of instructions from a candidate pool using a small query set from target tasks. Despite growing interest, we still lack guidance on what to select. Our new preprint brings clarity to this space (thread 👇).
2
8
22
3,490
2 Dec 2025
I'll be at NeurIPS on workshop days, helping organize DCVLR (dcvlr-neurips.github.io) on Dec 6 from 11:30 am - 2:30 pm!
Please reach out to chat about data curation across modalities (especially scientific data), data-efficient learning, and DCVLR!
2
152
Neha Hulkund retweeted

14 Oct 2025
I am on the job market this year! My research advances methods for reliable machine learning from real-world data, with a focus on healthcare. Happy to chat if this is of interest to you or your department/team.
4
49
250
54,191
Neha Hulkund retweeted

18 Jun 2025
So excited to announce the DCVLR (Data Curation for Vision-Language Reasoning) competition at NeurIPS 2025, led by @Oumi_PBC and sponsored by @LambdaAPI!
🌟open-data 🌟
🤖 open-models 🤖
💻 open-source 💻
💪anyone can compete for free 💪
dcvlr-neurips.github.io/
🧵 1 / n
1
13
43
10,830
Neha Hulkund retweeted

7 Aug 2025
The submission portal is now OPEN to take part in this interesting @NeurIPSConf 2025 data curation competition!! This is the first open-data, open-models, open-source competition for data curation in vision-language reasoning -- learn more 👇
dcvlr-neurips.github.io/
18 Jun 2025

So excited to announce the DCVLR (Data Curation for Vision-Language Reasoning) competition at NeurIPS 2025, led by @Oumi_PBC and sponsored by @LambdaAPI!
🌟open-data 🌟
🤖 open-models 🤖
💻 open-source 💻
💪anyone can compete for free 💪
dcvlr-neurips.github.io/
🧵 1 / n
3
9
2,311
Neha Hulkund retweeted

17 Jul 2025
If you are attending #ICML2025, check out our DataWorld workshop on Sat July 19. We have updated the website with more info on speakers & accepted papers! dataworldicml2025.github.io/
Also happy to chat offline about all things ✨ data ✨

24
81
10,960
18 Jun 2025
Really excited for more data-centric work -- this time at NeurIPS 2025!
18 Jun 2025
So excited to announce the DCVLR (Data Curation for Vision-Language Reasoning) competition at NeurIPS 2025, led by @Oumi_PBC and sponsored by @LambdaAPI!
🌟open-data 🌟
🤖 open-models 🤖
💻 open-source 💻
💪anyone can compete for free 💪
dcvlr-neurips.github.io/
🧵 1 / n
1
4
425
21 May 2025
📣We are extending our deadline to May 31st!📣
Looking forward to seeing everyone's submissions :)
1 May 2025

📢 Announcing our data-centric workshop at ICML 2025 on unifying data curation frameworks across domains!
📅 Deadline: May 24, AoE
🔗 Website: dataworldicml2025.github.io/
We have an amazing lineup of speakers panelists from various institutions and application areas.

4
7
828
Neha Hulkund retweeted
1 May 2025
📢 Announcing our data-centric workshop at ICML 2025 on unifying data curation frameworks across domains!
📅 Deadline: May 24, AoE
🔗 Website: dataworldicml2025.github.io/
We have an amazing lineup of speakers panelists from various institutions and application areas.
2
21
133
25,907
Neha Hulkund retweeted
15 Oct 2024
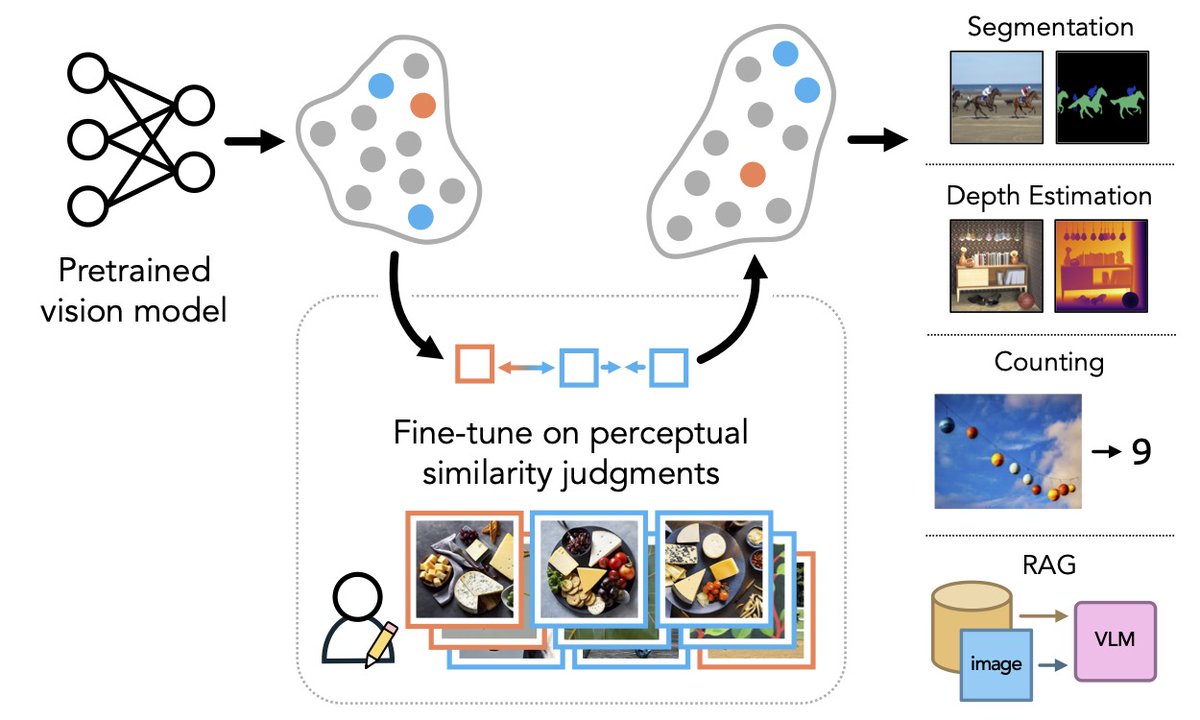
What happens when models see the world as humans do?
In our #NeurIPS2024 paper we show that aligning to human perceptual preferences can *improve* general-purpose representations!
📝: arxiv.org/abs/2410.10817
🌐: percep-align.github.io
💻: github.com/ssundaram21/dream…
(1/n)
8
82
449
52,628
Neha Hulkund retweeted
30 Sep 2024
The BeeryLab is busy at @eccvconf today!
@juliachae_ and @EdwardVendrow co-organized @CV4E_ECCV workshop, happening 8:30-1, where I'll moderate the panel and
Kai van Brunt and @__justinkay will present fish counting in sonar and Jae Joong Lee will present 3D trees
...
1
2
28
2,243
Neha Hulkund retweeted
17 Jun 2024
Synthetic data has huge potential to drive new improvements in training and evaluation for computer vision. Interested in learning more about advancements and challenges? Join us at the SynData4CV Workshop at #CVPR2024 tomorrow (June 18)!
syndata4cv.github.io
14 Jun 2024

Calling all #CVPR2024 attendees!
Join us at the SynData4CV Workshop at @CVPR (Jun 18 full day at Summit 423-425) to learn more about recent advancements in synthetic data!
Explore more: syndata4cv.github.io/
6
32
4,969
Neha Hulkund retweeted

14 Jun 2024
@CVPR AI for Conservation happy hour on Monday! Open to anyone working on or interested in the intersection of CV/ML and ecology, conservation, sustainability, climate, etc
Hosted w/ @sarameghanbeery @timmhaucke

10
23
5,589
Neha Hulkund retweeted
27 May 2024
Delighted to share one of my favorite pieces of work, now published: PURPLE, a method to estimate disparities in the prevalence of underreported outcomes, in women’s health and healthcare more broadly.
nature.com/articles/s44294-0…
5
15
80
11,554
Neha Hulkund retweeted

3 Apr 2024
Had a fun time attending NYC Computer Vision Day sharing my work on Amodal Completion via Progressive Mixed Context Diffusion #CVPR2024
Project page: k8xu.github.io/amodal/
Event: cs.nyu.edu/~fouhey/NYCVision…
Thank you to the organizers and sponsors! 🗽

3
7
35
5,109