
mts @thinkymachines | ex-phd student @mit | systems for ml
Joined January 2011
- Tweets 142
- Following 518
- Followers 1,536
- Likes 25,578
40 Photos and videos





Pinned Tweet

2 Dec 2025
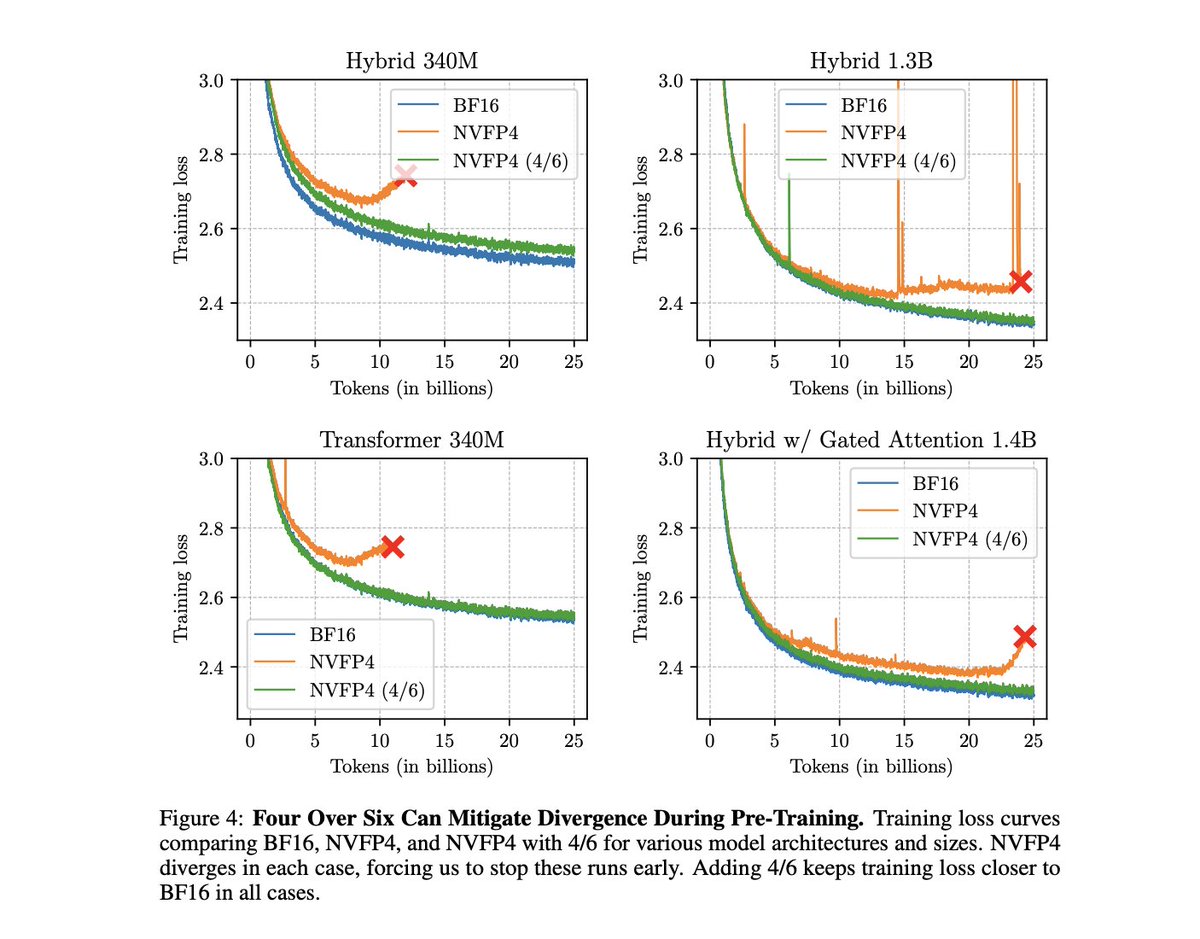
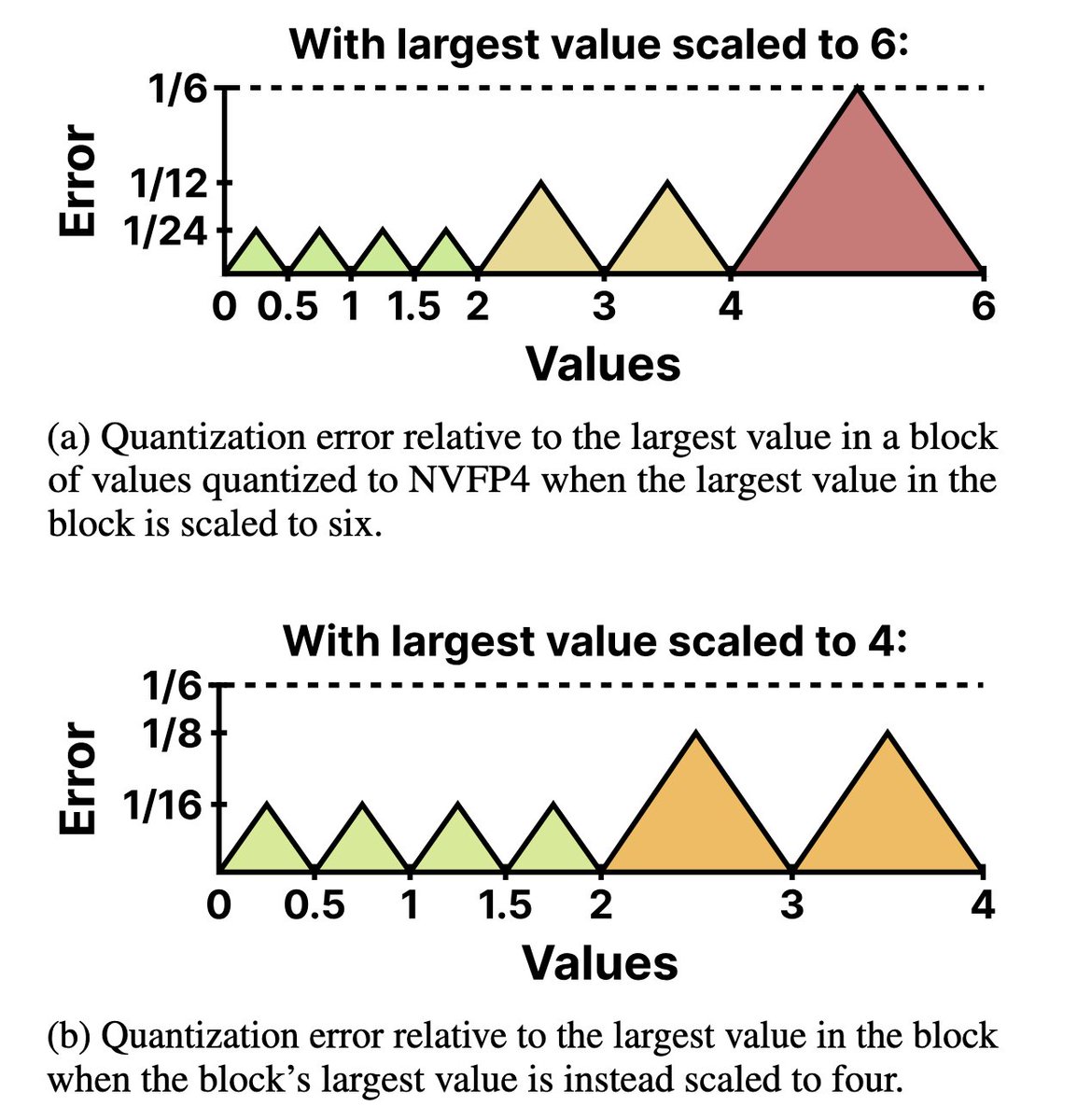
Training LLMs with NVFP4 is hard because FP4 has so few values that I can fit them all in this post: ±{0, 0.5, 1, 1.5, 2, 3, 4, 6}. But what if I told you that reducing this range even further could actually unlock better training quantization performance?
Introducing Four Over Six, a new method for improving the accuracy of NVFP4 quantization with Adaptive Block Scaling. 🧵
6
40
253
70,546
May 11
Now seems like a good time to share that I’ve recently joined @thinkymachines to work on pretraining! Very excited to work on the future of human-AI collaboration with this amazing team.
May 11

People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
12
6
136
11,117
Jack Cook retweeted

Apr 1
4/6 --> 6/7...
jokes aside jack put this out crazy fast, and it's a very clever idea that I hope it gets standardized in new hardware :)
Mar 31

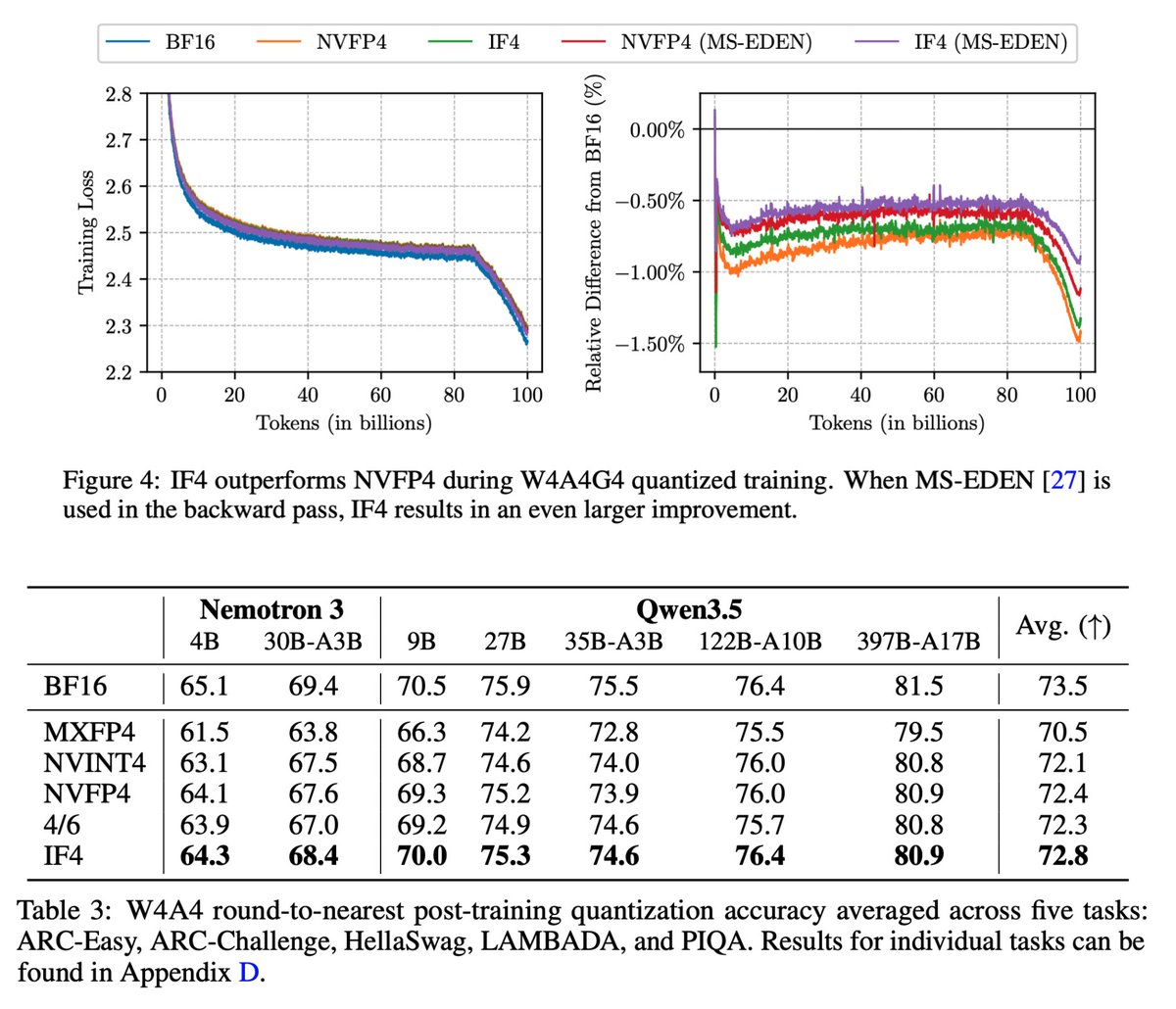
NVFP4 allows models to be quantized to 4 bits without too much performance degradation, but can we push 4-bit performance even further?
Today, we're releasing a new class of low-precision block-scaled data types that natively adapt to your input data: for 4-bit quantization, IF4 (Int/Float 4) allows each scaled group of 16 values to be saved as FP4 or INT4 depending on which option offers less error. Selections are recorded using the scale factor’s sign bit, which is unused in NVFP4, allowing IF4 to offer better performance with no memory overhead!
Our data types provide better downstream accuracy in LLMs, they can be implemented efficiently in next-generation hardware accelerators, and they reveal some interesting insights about low-bit quantization! 🧵
1
7
77
11,452
Jack Cook retweeted

Very cool paper! Glad to see our rotation-based unbiased gradient estimation scheme from Quartet II improve quality as well.
Mar 31
With these two features in place, we find that IF data types (IF3, IF4, and IF6) offer better performance over existing block-scaled data types during quantized training and inference.
During training, we show that this can be partly explained by an increased preference for integer quantization after inputs undergo a Hadamard transformation, an important component of backward passes in recently-published 4-bit training recipes. During inference, performance improvements can be primarily explained by the reduced quantization error.
1
4
975
Jack Cook retweeted

Apr 1
doot doot

Mar 31
NVFP4 allows models to be quantized to 4 bits without too much performance degradation, but can we push 4-bit performance even further?
Today, we're releasing a new class of low-precision block-scaled data types that natively adapt to your input data: for 4-bit quantization, IF4 (Int/Float 4) allows each scaled group of 16 values to be saved as FP4 or INT4 depending on which option offers less error. Selections are recorded using the scale factor’s sign bit, which is unused in NVFP4, allowing IF4 to offer better performance with no memory overhead!
Our data types provide better downstream accuracy in LLMs, they can be implemented efficiently in next-generation hardware accelerators, and they reveal some interesting insights about low-bit quantization! 🧵
3
38
4,430
Jack Cook retweeted

Mar 31
floats aren't cool. you know what's cool? integers.
Mar 31
NVFP4 allows models to be quantized to 4 bits without too much performance degradation, but can we push 4-bit performance even further?
Today, we're releasing a new class of low-precision block-scaled data types that natively adapt to your input data: for 4-bit quantization, IF4 (Int/Float 4) allows each scaled group of 16 values to be saved as FP4 or INT4 depending on which option offers less error. Selections are recorded using the scale factor’s sign bit, which is unused in NVFP4, allowing IF4 to offer better performance with no memory overhead!
Our data types provide better downstream accuracy in LLMs, they can be implemented efficiently in next-generation hardware accelerators, and they reveal some interesting insights about low-bit quantization! 🧵
1
11
1,029
Mar 31
NVFP4 allows models to be quantized to 4 bits without too much performance degradation, but can we push 4-bit performance even further?
Today, we're releasing a new class of low-precision block-scaled data types that natively adapt to your input data: for 4-bit quantization, IF4 (Int/Float 4) allows each scaled group of 16 values to be saved as FP4 or INT4 depending on which option offers less error. Selections are recorded using the scale factor’s sign bit, which is unused in NVFP4, allowing IF4 to offer better performance with no memory overhead!
Our data types provide better downstream accuracy in LLMs, they can be implemented efficiently in next-generation hardware accelerators, and they reveal some interesting insights about low-bit quantization! 🧵
14
82
438
52,292
Mar 31
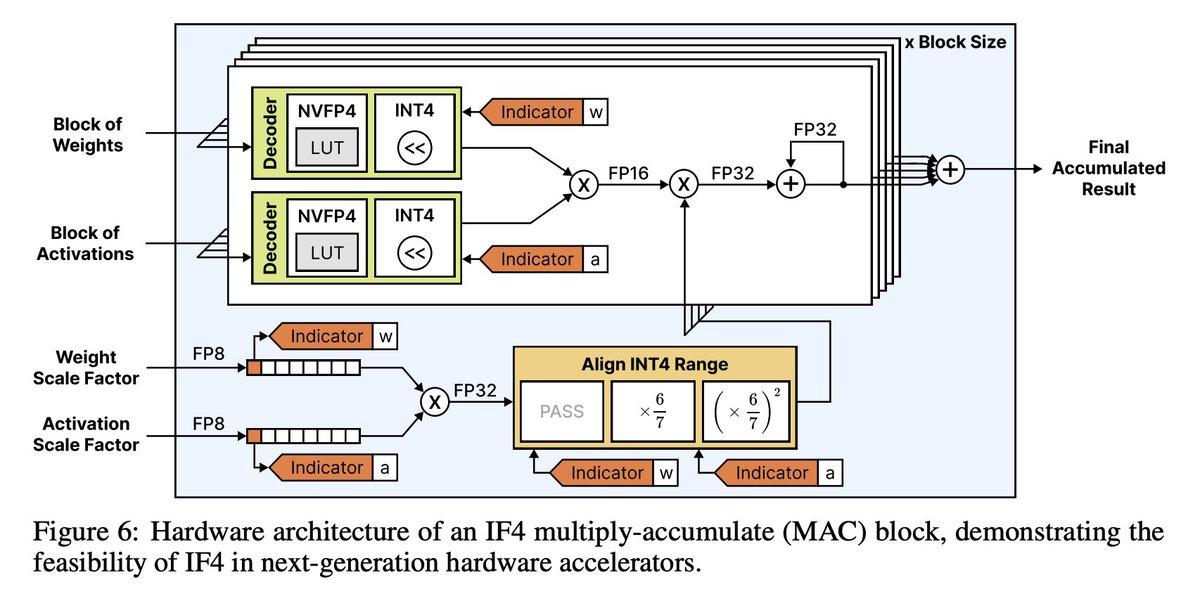
You can simulate IF data types today using higher precision formats, but we also show that IF4 can also be implemented efficiently in next-generation hardware accelerators! We design and evaluate an IF4 multiply-accumulate unit (MAC) and find that latency increases by just 4.7% compared to a baseline NVFP4 MAC unit.
1
1
17
1,574
Mar 31
Check out our paper for more analysis, and our GitHub repo if you want to experiment with low-precision block-scaled quantization schemes yourself! We also have more stuff coming out soon, especially related to 4/6, so stay tuned!
Code: github.com/mit-han-lab/fouro…
Paper: arxiv.org/abs/2603.28765
4
23
1,298
Jack Cook retweeted

Feb 2
Happy to release Quartet II, a new method that pushes the frontier of 4-bit LLM training in NVFP4.
Fully-quantized pre-training in NVFP4 can now match FP8/FP16 quality much more closely, while maintaining full hardware acceleration!
[1/4]
5
25
170
19,757
Jan 20
oh, you want a kernel that'll be right about 93% of the time and have tons of really weird and unpredictable edge cases? yeah I'd recommend Triton
8
402
Jack Cook retweeted
Jan 14
There was a flippening in the last few months: you can run your own LLM inference with rates and performance that match or beat LLM inference APIs.
We wrote up the techniques to do so in a new guide, along with code samples.
modal.com/docs/guide/high-pe…
21
98
889
93,887
Jan 13
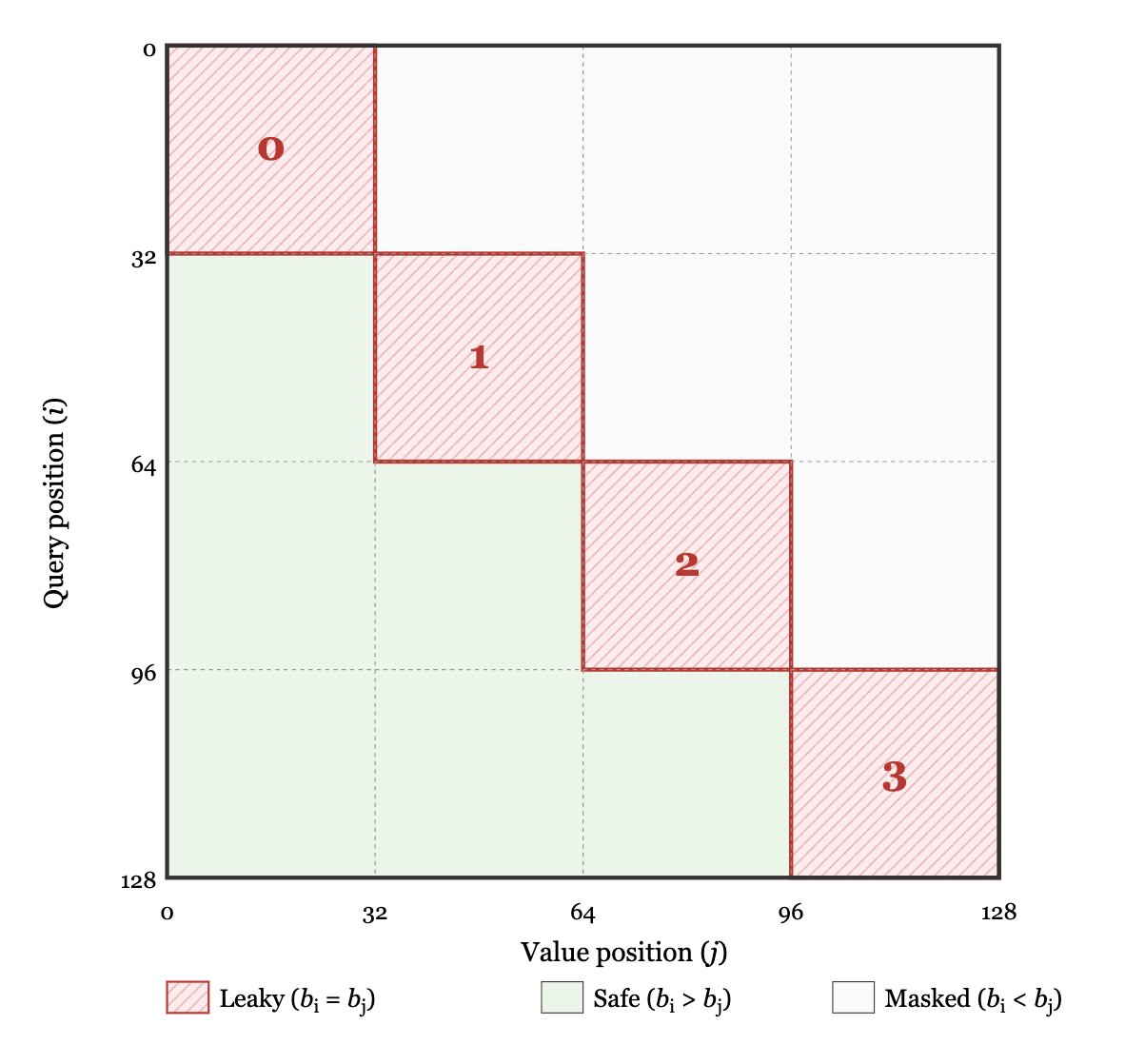
Here's a non-obvious problem with block-scaled quantized Attention: at the edge of your causal mask, later tokens can leak information to earlier ones through the scale factor computation.
I wouldn't expect this leakage to matter very much since it affects scales, not values, but it turns out it does actually cause the loss to decrease a little too quickly! Very cool post by @tensorpro and team.

Jan 13

We trained models with MXFP4-quantized attention, but it turns out this can break causal modeling. Our latest post explains why this happens and how to fix it.
matx.com/research/leaky_quan…
3
18
2,580
Jack Cook retweeted

Life update: Wrapped up my PhD at @MITEECS 🎓
Super excited to start working on pre-training at @thinkymachines.

52
70
1,923
73,783
Jack Cook retweeted
Jan 2
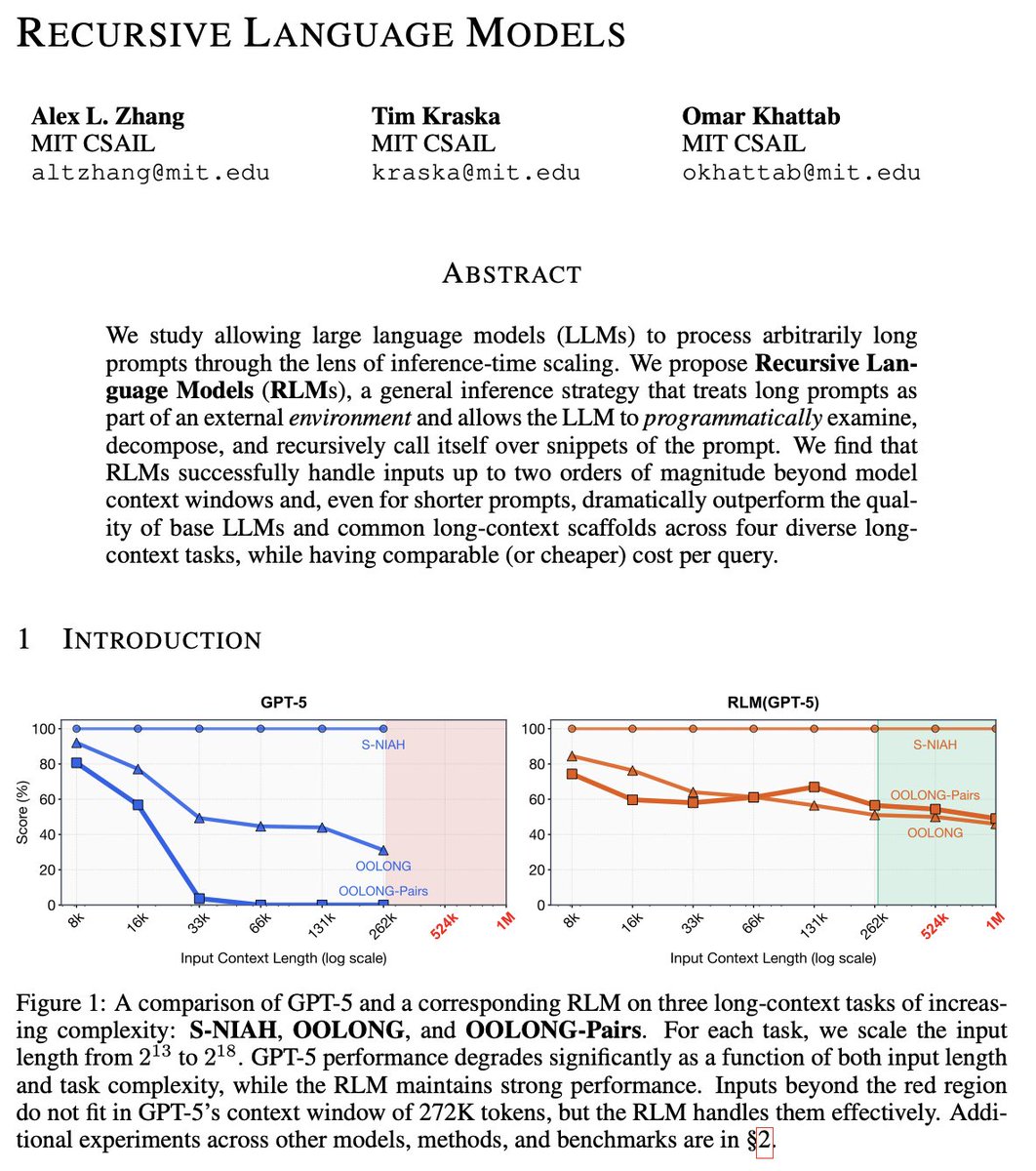
Much like the switch in 2025 from language models to reasoning models, we think 2026 will be all about the switch to Recursive Language Models (RLMs).
It turns out that models can be far more powerful if you allow them to treat *their own prompts* as an object in an external environment, which they understand and manipulate by writing code that invokes LLMs!
Our full paper on RLMs is now available—with much more expansive experiments compared to our initial blogpost from October 2025!
arxiv.org/pdf/2512.24601
251
1,095
7,364
2,030,663
Jack Cook retweeted
18 Dec 2025
use quant.exposed and maybe you too will write a groundbreaking research paper on low-precision training

2
1
152
21,316