
Husband. Father. Programmer. Belieber.
Joined January 2013
- Tweets 1,377
- Following 712
- Followers 45
- Likes 1,927
72 Photos and videos











HXX retweeted

May 15
Source-inline display of auto watch expressions, computed by determining which addresses are read from / written to by a particular range of instructions, and mapping that back to variables via location info within debug into.
12
18
448
44,377
HXX retweeted

May 14
Something we've been working on...
277
732
10,023
1,264,428

HXX retweeted
May 5
Human oversight is fundamentally necessary for producing anything consumed by humans. In fact, anything consumed by an entity with a value system must inherently be produced by an entity *with a similar value system* (this is why trade can extend across some national/cultural boundaries but not all). Obviously some value structures are more relevant in some domains than others—trading bare necessities (energy, food, shelter) is easier than complex value-related products.
“Intelligence” sufficient to replace human work makes this doubly true, because specific value structures (e.g. creating goods that are not to the detriment of their consumer) are not intrinsic to intelligence nor can they be explicitly programmed.
Furthermore, given that software is (for all intents and purposes) an ~infinite space, human demand can expand into that space arbitrarily, requiring more and more software work. Every serious programmer knows the feeling that there is effectively an unbounded amount of work to do, and projects to investigate, almost certainly until they get bored or die. Thus, even with improved efficiency and fewer humans needed to do oversight on any one project, you’d still expect a larger number of human overseers in the end.
In practice, given that the so-called “intelligence” is extremely limited, it’s capable of producing a small fraction of that total space. Thus, you’d expect supply for that fraction to rapidly increase, despite a fixed limit on demand for it—demand will be magnified in areas with much less supply, which require greater human oversight and authorship.
8
17
283
12,463
Subtle things to make your shaders better:
1) Anti-aliasing - Real life is not limited to pixels so unless you're specifically going for a pixelated style, you should be anti-aliasing everything!
mini.gmshaders.com/p/antiali…

27
232
2,627
221,933




HXX retweeted

Apr 13
Dijkstra on why he believed programmers should stop using the term "bug"
95
278
1,860
373,677
HXX retweeted
Mar 8
For any given desired computational outcome, there is some sequence of bits which encodes that. These bits of signal (of the desired outcome) can be intermixed with bits of noise.
The reason why these LLM-generated codebases by default have so many obviously useless lines of code is that, for any given generative step, the LLM’s job is to package up the few signal bits (from the prompt) into a plausible presentation of other bits, which may or may not be noise.
If they are extra signal (because they can be statistically inferred from the other signal bits), then that’s a win, but there’s a much higher probability that they’re actually just noise. This is why every AI generated tweet, article, or indeed code snippet contains drastically more fluff (noise) than what a focused person with reasonably good instincts for compression would produce.
So, in order to actually accomplish anything (without extreme vetting, compression, and modification of generated code), the “programmer” (prompter) needs to continuously generate more code to obtain the next signal bit they wanted, at the expense of many, many more bits of noise.
The result is often ~100x if not ~1000x more code than was needed, which is impossible to hand-edit, comprehensively understand, or compress. Layers upon layers of statically average nonsense, wrapping the few bits of utility you actually wanted.
Mar 8

i read this and was like huh thats a lot of code but surely hes built some huge super complex app
it’s a blog
he’s built a blog
300,000 lines of code for a blog
the blog posts are all ai slop
there’s like 10 lines of code per line of blog
24
32
514
40,872
HXX retweeted

We’re releasing our analysis of ring-1.io, a major game cheat targeted by multiple studios in recent legal actions. We partially deobfuscated several Themida-protected components and document how it hijacks Hyper-V to inject and manipulate game code.
back.engineering/blog/04/02/…
github.com/backengineering/r…
15
97
462
115,223

HXX retweeted

1 Sep 2025
Take a look at our latest video on how EUV Photolithography Works!! youtu.be/B2482h_TNwg
1
5
18
4,518
HXX retweeted

14 Oct 2025
Microsoft OneDrive is rolling out AI face recognition for your photos.
But you can turn it off, right? Well, you CAN, but only “three times a year,” and Microsoft hasn’t clarified what that actually means.
To disable (for now), go to Privacy & Permissions → People section.

268
1,718
7,066
1,516,005
HXX retweeted

22 Aug 2025
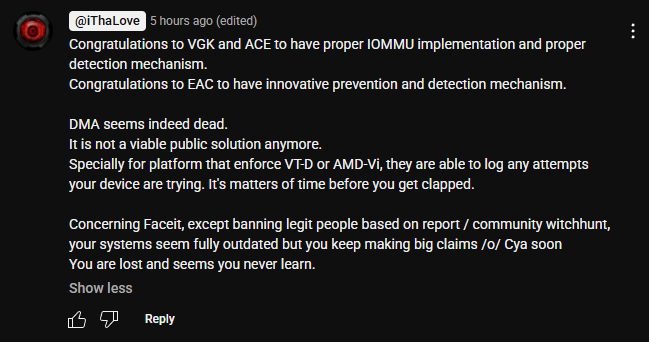
Two weeks ago, one of our chad engineers cooked so we released our IOMMU Restriction Enforcement, which marked the end of 2PC DMA attacks using IOMMU. This is where the device itself is contained in its own memory region and cannot read outside of it. No matter what you do, tampering with that would defeat the purpose of the 2PC "security" benefit.
The biggest P2C devs, including devices like HPTT that cost $4500, have all either given up or are coping on theories of how they can get around it or try to resort to finding niche stupid things that gets them detected/banned lmao.
It is a relatively simple area to cover, not a particularly problematic surface area.
I have collected their tears for your enjoyment imgur.com/a/iommu-judgement-…
and here is a video a 2PC DMA cheat dev has posted youtube.com/watch?v=IprU_G8M…
This marks the end of 2PC DMA ATTACKS 2016-2025

109
68
1,180
180,845
"LAUNCH"
for(float i,z,d,f;i <1e2;o =vec4(3,1,d,z/f)/z){vec3 v=vec3(0,-2,7),p=z*normalize(FC.rgb*2.-r.xyx) v,a=p;a.y*=.3;for(d=1.;d <9.;)a-=.1*sin((a.zxy t*v d)*d)*p.y/d;z =d=min(max(-p.y,length(a)-2.),f=.2 abs(length(a.xz-cos(a.zx*6.)) max(p.y/.1,-.6)))/8.;}o=tanh(o*o.a/1e3);
27
80
923
47,897
HXX retweeted

4 Jul 2025
The funny thing about this initiative is on paper. It sounds good. Any game you buy will be permanently yours And nobody will be able to take it from you. That is like the only positive. The negatives are: increased costs for publishers and studios (which means more expensive games), game design shifts (devs will be forced to prioritize long-term accessibility from the start which will discourage innovation in online titles as risky game design won't be as profitable long-term), smaller studios are going to seriously struggle to keep up with the legal requirements and this will create an uneven playing field where much less indie games are produced and bigger studios and publishers will maintain a monopoly over the space, because of different laws around the world if this only passes in the EU and nowhere else it will 100% screw over EU citizens with EU only versions of games that are 100% going to be worse than everywhere else due to the restrictions. And those are only a few I could keep going. From a consumer's perspective. Yes, I understand you want to be able to keep the things you buy. But that isn't the age we live in anymore. It is the digital age. Physical media is not coming back. And you can't treat digital media like it's the same.
166
25
472
113,477
HXX retweeted

3 Jul 2025
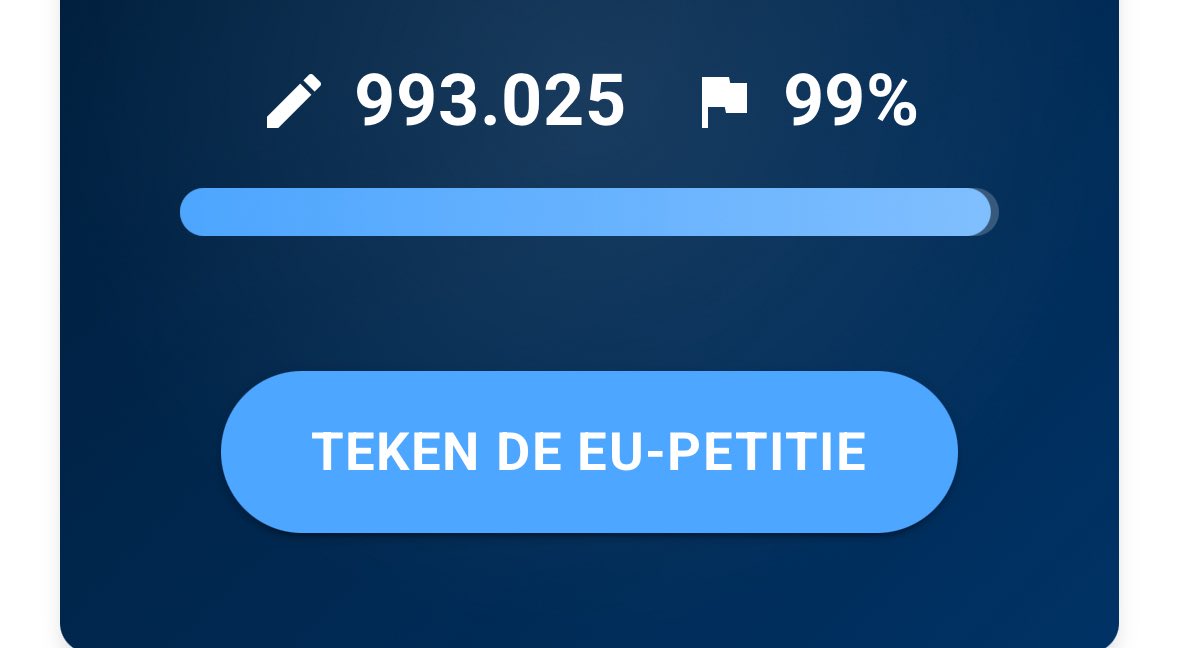
As an open source MMORG developer, the success of the #stopkilinggames petition is extremely disappointing for devs. This is a feel good movement that will thoughtlessly kill more games than it saves. Why develop a risky new online title? Just pump out more of the same…
3 Jul 2025

Imagine fading when you know all of ct will be talking about it when this bar is filled…
$SKG
Not for the weakminded
70
8
228
86,870
HXX retweeted
30 Mar 2025
I’m gifting three File Pilot licenses to students or younger programmers (one Pro, two Essential). @vkrajacic was extremely generous and gifted me one for free, so I’d like to return the favor and help others out.
If you’re a student or a younger programmer, reply with a screenshot, video, or demo of something cool you work on. I’ll pick three people from the replies.
You can try File Pilot for free, so do that (if you haven’t) to see if you’re interested in a license for the future updates.
filepilot.tech
18
19
221
38,390
HXX retweeted
4 Mar 2025
SpacetimeDB 1.0 is finally here. It's been years in the making. Indie MMOs here we come!
Check out the keynote! Couldn't be more proud of the team!
24
35
195
37,906
HXX retweeted

18 Feb 2025
File Pilot, a modern and fast file explorer, is officially out in public beta!
filepilot.tech/
After 3 years of development and hard work, it's finally in your hands!
A huge thank you to everyone who helped in any way throughout this journey!
223
280
1,859
336,510