
Agent Infrastructure for Enterprises, Governments, and the Autonomous Economy.
Joined September 2023
- Tweets 2,785
- Following 100
- Followers 22,514
- Likes 991
949 Photos and videos












Pinned Tweet

Jun 3
SERV Reasoning Private Beta is one month in.
Don't take our word - hear from builders inside. 👇
13
55
267
27,434
Frontier labs are racing to make AI smarter.
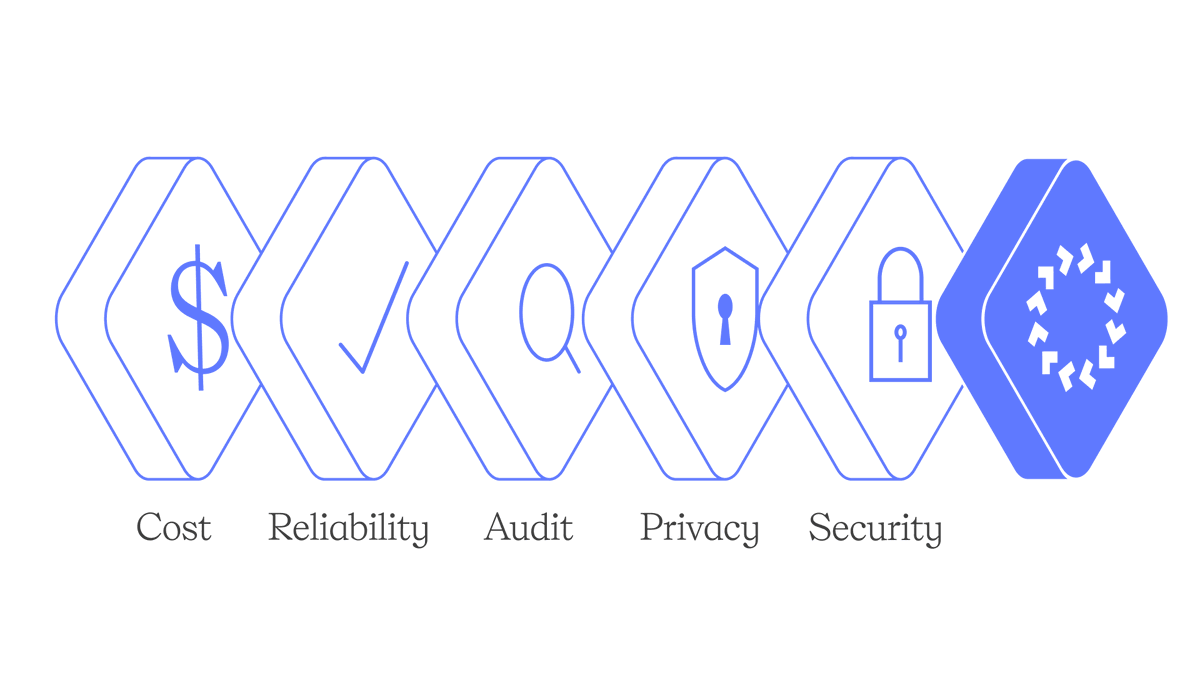
Raw intelligence is not enough for regulated industries like banking, healthcare, and robotics.
They need reliable, cost-effective infrastructure, with auditing, privacy, and security built-in.
That is the gap SERV is filling.
4
23
125
1,939
11h
The number of applications to the Builders Program is staggering, and the pipeline keeps growing.
Our launchpad opens SERV Reasoning to all web3 builders who launch tokens in the eco.
The most novel projects are selected for the Builders Program and spotlighted.
Next in line: Homecooked, an AI-powered app entering a multi-billion-dollar food-tech market, built on SERV.
5% of every launch is reserved for SERV stakers. Staking program coming soon.
Time to cook.
Jun 12

We are pleased to announce that Homecooked has been accepted into the @openservai Builders Program and received access to SERV Reasoning engine.
We are entering a $2 billion market for recipe apps, equipped with features that no one else offers.
For the last six months, we have been building an AI-powered sous chef that can live in your pocket - an agent that helps home cooks prep faster, shop smarter, and eat better.
SERV Reasoning has boosted our sous chef's IQ and reduced his wages significantly, and that means we're almost ready for l(a)unch.
The Homecooked token will be launching within OpenServ ecosystem, followed closely by our web app right after.
Join us as we finish prep and get to serving.

10
29
156
6,335
Jun 15
Destination is clear: SERV as the reasoning layer enterprise agents can actually run on.
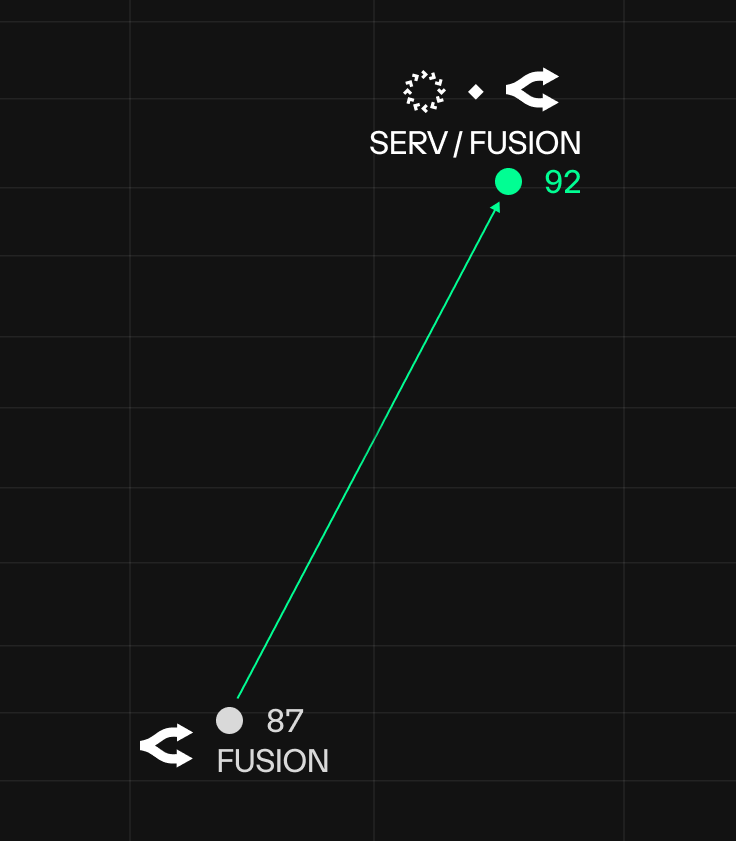
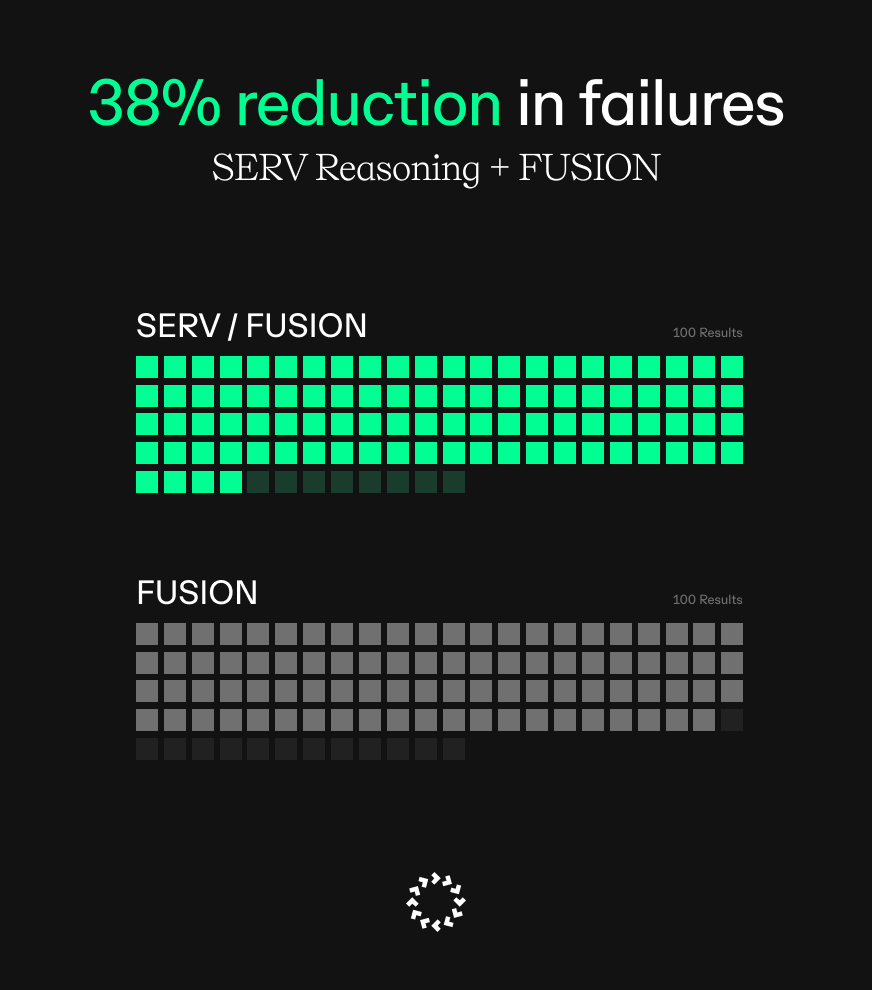
Stats show why all roads lead to SERV: on our preliminary benchmark, combining OpenRouter Fusion with SERV Reasoning led to a ~38% reduction in failures (13→8).
Fusion seems to be suited for deep research tasks rather than agentic work, and struggles with what production agents need most: reliable JSON outputs.
Even the biggest companies don't have answers for problems we're already solving. It shows why SERV is on the way to becoming a staple name in conversations shaping the future of the agentic economy.
Deeper Fusion benchmarks and results underway.
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

9
45
201
11,245
Jun 15
SERV name is spreading globally.
Just last week, our team was at London Tech Week meeting some of the biggest players in AI.
Builders carried SERV into Solana Summit Berlin and SuperAI Singapore, while our BD crew worked the boardrooms of Silicon Valley.
Three continents in one week.
The main themes driving conversations were the same ones SERV is built around: AI observability (knowing what your agents are doing), cost-efficiency (running agents at scale without the bill exploding), and the enterprise adoption bottlenecks keeping AI stuck in pilots.
These aren't side topics. They're the exact problems we are solving, and they're now the center of the industry's attention.
Before long, everyone in AI will know SERV.
12
41
229
10,992
Jun 14
Fable 5 was abruptly pulled.
Enterprises used to tune their stack to one model's built-in reasoning - if it's gone, you rebuild from scratch.
SERV lifts open-source models to frontier-level and lets you swap models freely - you're never at the mercy of one vendor or politics.
11
37
210
13,451
Jun 13
The US government pulled Claude Fable today.
Good news is, you don’t need frontier models for production-grade agents.
With SERV, open-source LLMs like DeepSeek-v4 outperform Claude Fable at up to 90x cost savings.
The decentralised future is bright.
SERV is inevitable.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
14
45
231
16,053
Jun 12
Welcome on board.
All of HYRE’s decision endpoints are now powered by SERV Reasoning.
Jun 12

Most onchain APIs return data. Agents need decisions.
HYRE just upgraded 7 decision endpoints to SERV Reasoning by @openservai a reasoning engine that thinks before it answers.
→ Token Verdict: snipe / watch / avoid
→ Bridge Quote: execute / wait / avoid
→ Yield Migrate: migrate / stay / wait (with break-even math)
→ LP Recommend, LP Strategy, LP Rebalance
→ /ASK: natural language, reasoned answers
Fast endpoints stay fast (~1s). Decision endpoints now reason (~4-6s) — because a wrong financial signal costs more than 3 extra seconds.
Don't take our word for it every response includes a model_used field. Check who answered.

7
33
157
4,931
Jun 12
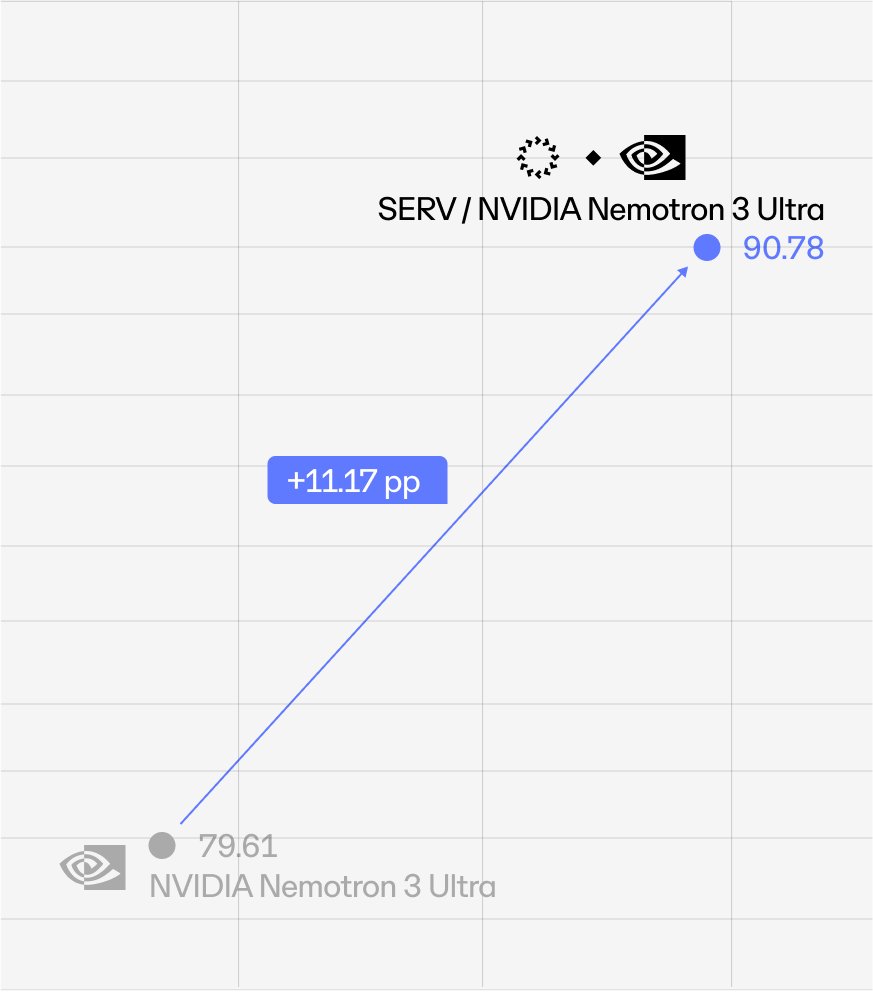
NVIDIA shipped a new frontier model - Nemotron 3 Ultra, and we have already integrated it with the SERV Reasoning engine.
The base model scored 79.61 on our standard DeFi benchmark. Armed with SERV, it jumped to 90.78.
Thats 11.17 points gain.
SERV makes all models smarter.

Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
14
50
227
14,353
Jun 11
SERV Reasoning cut verifier agent costs by 99%, making continuous AI checks economically viable inside Sentinel.
It’s the trust layer for autonomous AI: the gate between “agent decided” and “transaction sent" - finally deployable at scale.
Every Sentinel call runs on SERV.
Jun 11

This team ships.
Live products, open-source tooling (MIT), published benchmarks: 0 false ALLOWs and 0 API failures across a 120-case verification run, and 107× better cost-performance vs their prior pipeline.

7
28
190
10,498
Jun 10
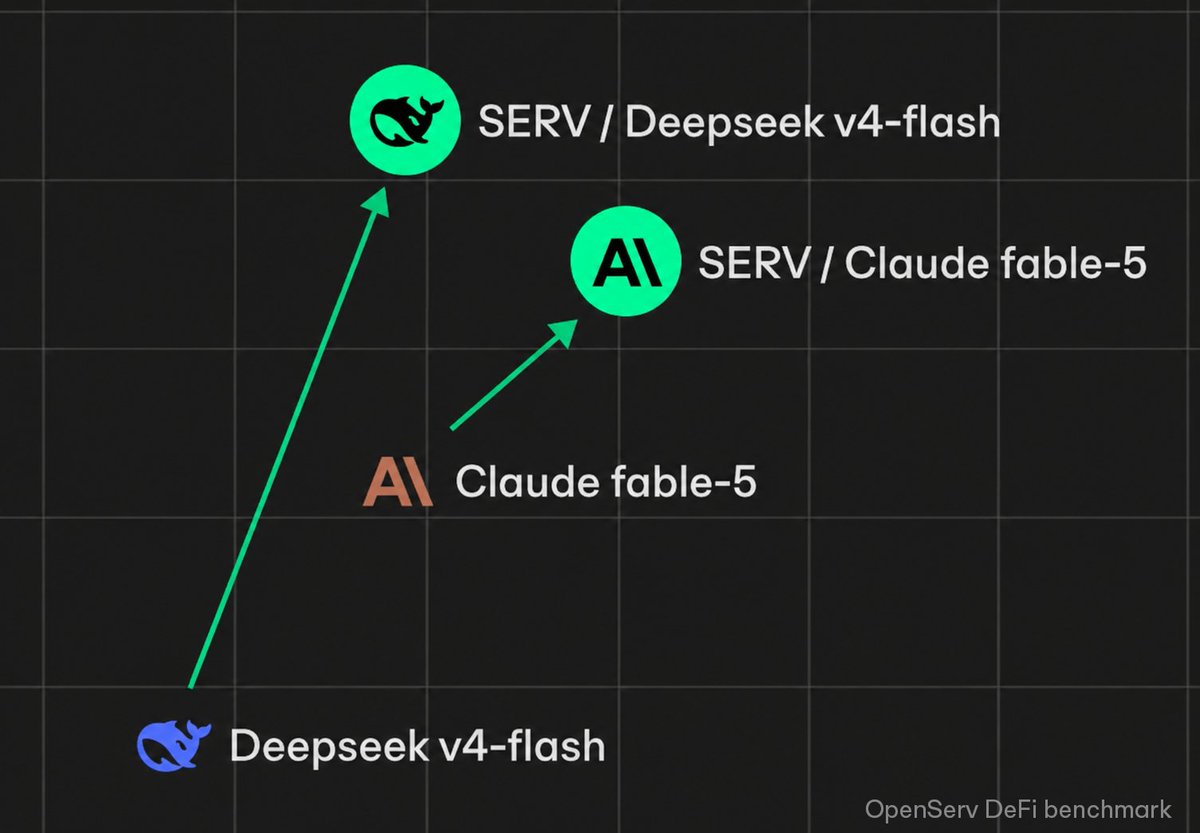
Several SERV Reasoning-armed agents just beat Anthropic's Fable, one of the strongest LLMs ever built, at up to 90x lower cost.
That result comes from using SERV Reasoning with DeepSeek-v4-Flash on our DeFi benchmark. Thanks to the SERV engine, agents running on smaller models perform better than those using frontier, expensive ones.
Here is more information about the benchmark behind that result, what it tests and why it is built the way it is.
Why a DeFi benchmark
Autonomous trading is one of the harshest tests of machine reasoning.
An agent reads live market state, portfolio state, and a strict risk policy, then has to commit to one of four actions: BUY, SELL, HOLD, or BLOCK. A wrong decision costs real money.
No room for reasoning sounds smart but lands on the wrong trade, which makes it the ideal domain for measuring whether a model actually follows rules under pressure rather than just explaining them well.
What the scenarios target
Each scenario combines a market snapshot, portfolio size, trading signal, and a fixed risk policy, and falls into one of three families:
- clear constraint violations the agent must refuse
- ambiguous setups where everything looks tradeable but the conditions say wait
- valid trades where the agent must size the position correctly within caps
This mirrors how trading agents actually fail in production. Rarely on the obvious cases, almost always on the judgment calls.
How it is scored
The benchmark follows the same conventions as the agentic evals in the latest frontier model reports, including τ²-bench and Terminal-Bench:
- outcome-verified scoring, where code checks the final decision against the risk policy, with no LLM judges
- identical prompt, scenarios, and settings for every model
- zero-shot, with no scaffolding, no retries, and no few-shot examples
- repeated runs per scenario, so consistency is measured alongside accuracy
- cost computed from real token usage at list prices, per run
Why this is exactly where reasoning matters
This task has the three properties structured reasoning is built for: hierarchical rules, multiple data sources that must be reconciled, and a verifiable correct answer.
SERV's bounded reasoning keeps a model moving through that hierarchy step by step, instead of letting it talk itself into a bad trade.
That is why SERV-routed models clear the same quality bar as flagship models at a fraction of the cost, and why the gap shows up most on the judgment calls.
10
56
245
17,347
OpenServ retweeted

Jun 10
One thing you learn pretty quickly in BD:
You can't pitch every company the same way.
Even if the product is the same, the pain is not.
A startup hears "SERV Reasoning" and usually cares about speed, cost, and whether they can plug it in without slowing the team down.
A large enterprise cares about control.
A bank or compliance-heavy org cares about auditability, hallucinations, decisioning, privacy, and whether the system can actually survive internal review.
Same product. Different conversation.
That's been the interesting part of the SERV Reasoning meetings lately.
The value is very clear once people understand it:
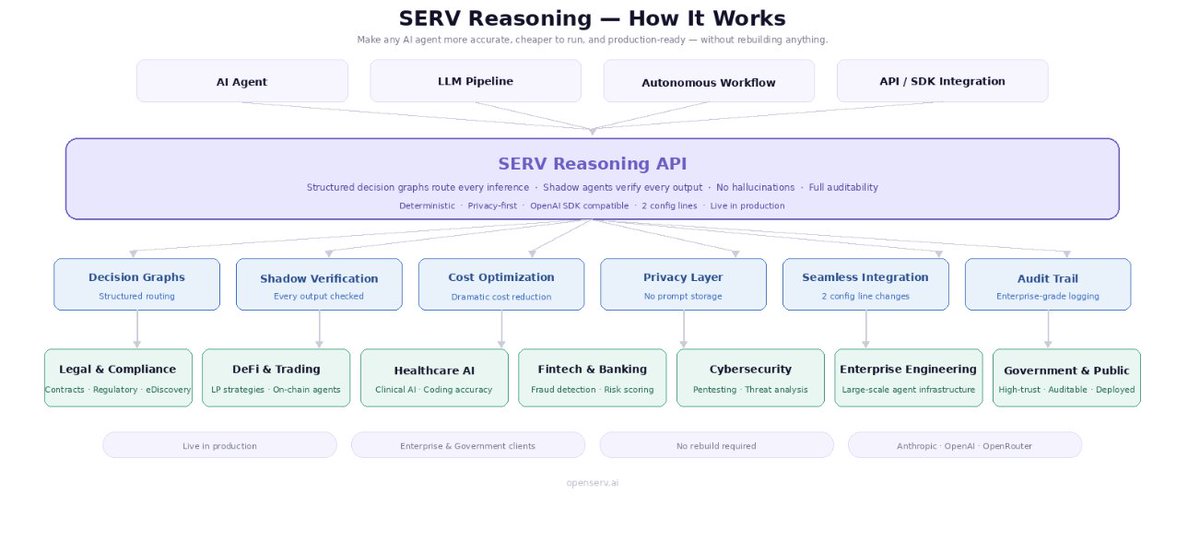
- better reasoning accuracy
- near-zero hallucinations
- lower agent costs
- structured decision routes
- shadow verification
- single-line integration
But the way you frame it depends entirely on who is sitting across from you.
In my experience, good BD is mostly pattern recognition.
Who actually owns the pain?
What do they get measured on?
What happens if this problem doesn't get solved?
What would make them trust the solution enough to move?
Once you understand that, the conversation gets a lot easier.
Especially when the pain is already obvious.
7
18
83
6,207
Jun 10
SERV Reasoning Private Beta is accelerating and a new batch of builders is coming on board, pulling the next ones in.
The pattern holds:
• Lower costs
• 100% reliability
• Faster than their old stack
Here are a few recent additions to the program.
-> Apply to join now 👇
11
40
223
12,879
Jun 10
Jun 9

Hatcher x @openservai integration is live.
We were accepted into the Private Beta and after seeing the immediate results, moved to deploy SERV Reasoning in production:
- All SERV tiers: 100% reliability
- SERV-nano: 4x faster vs GPT-5-nano, 61% lower cost
- SERV-mini: 2.4x faster vs GPT-5-mini
This gives Hatcher agents best-in-class reasoning path for coding, DeFi, analytics, research, security triage, support, and autonomous workflows.
SERV performed best with clear process-driven system prompts, structured outputs, low/medium reasoning effort, and no forced max token caps.
Hatcher agents can now route through: SERV-nano, mini, swift, standard, pro, and ultra.

4
10
45
2,422
Jun 9
SERV Reasoning-armed models just beat Anthropic's newly released flagship Fable (Mythos) - one of the strongest LLMs ever built - at up to 90x lower cost.
With SERV, enterprises can finally afford AI at scale.
We spent the last two years building for exactly this moment.
The labs promised costs would halve every 6 months - instead, prices keep climbing, subsidies are ending and the math breaks.
There is a way out.
SERV-enabled models vs Claude Fable 5 (85.17 ~3.24¢):
→ DeepSeek-V4-Flash: 87.15 - wins at 90x lower cost
→ NVIDIA Nemotron: 90.78 - wins 5 pts, 11x lower cost
→ Gemma 4 12B: 83.33 - within 2 pts, on local hardware
Top-tier performance no longer requires the most expensive model.
And cost is only half the story - production AI must be reliable, auditable, private, and secure, or it dies in procurement.
SERV is built for all of it.
The agentic economy finally has the infrastructure to run on.

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
35
107
380
95,863