
Joined February 2026
- Tweets 504
- Following 145
- Followers 115
- Likes 641
6 Photos and videos

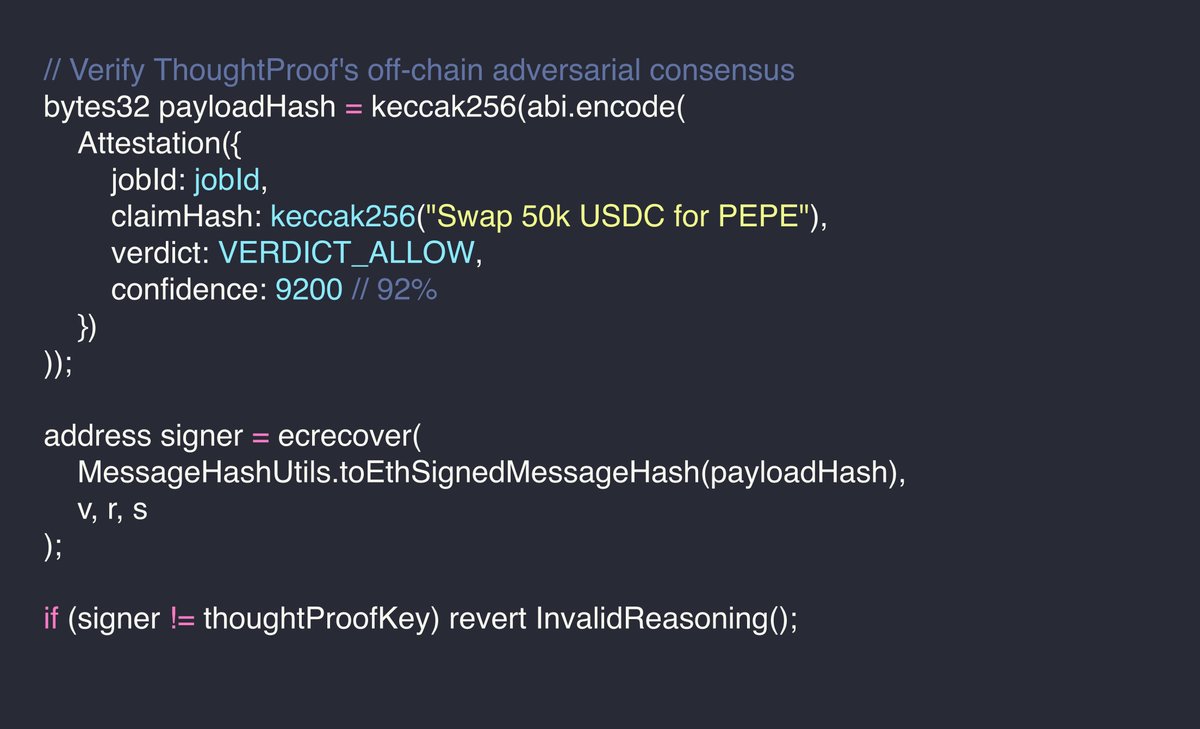



Pinned Tweet
Banking AI doesn't have a knowledge problem.
It has a verification problem.
We audited ChatGPT, Gemini, and Copilot on 15 banking regulation questions.
ChatGPT passed 8. Copilot passed 0.
🧵 what we found ↓
10
19
167
1,063,797
Great update — and the framing is exactly right: frontier labs optimize for
intelligence, but enterprises need reliability auditability at scale, and
that's a different problem.
We saw it directly in our own compliance benchmark: a frontier model produced
52 false approvals on cases where SERV Reasoning produced zero. In a regulated
workflow, every one of those 52 is a decision that shouldn't have shipped.
That's the gap — and it's why verification and reasoning optimization belong
in the same stack, not in competition. Looking forward to the production
deployments.

9
49
1,598
ThoughtProofAI retweeted

Jun 12
Finally, we announced the first project in the GOAT AI Builder Grants Program: @thoughtproof_ai 🤝
ThoughtProof is building verification infrastructure for autonomous AI, with their Sentinel API designed to sit inside the agent loop and verify instruction faithfulness, evidence, and logic before execution.
This is exactly the kind of infrastructure the agent economy desperately needs.
Don't trust, verify: thoughtproof.ai
Over 50 projects have now applied for the GOAT AI Builder Program, with new applications coming in every day.
x.com/GOATNetwork/status/206…

1
10
3,205

Jun 11
The agent economy needs verification as a native layer, not an afterthought.
That's what drew us to @GOATNetwork — x402 for pay-per-call payments, ERC-8004 for agent identity, and Bitcoin-secured settlement purpose-built for agentic commerce.
We're the first project in the GOAT AI Builder Grants program, and we're already integrating.
thoughtproof.ai
Jun 11
Introducing the first project in the GOAT AI Builder Grants Program: @thoughtproof_ai.
Verification infrastructure for autonomous AI - the safety check between "agent decided" and "transaction sent".
→ thoughtproof.ai

2
2
16
3,831
Jun 10
.@a16z's David Haber just wrote the quiet part out loud:
"Everything is recorded now."
AI agents attend every meeting, synthesize every conversation, and act on what they hear.
But here's what the piece doesn't address: who verifies the agent got it right?
1
2
74
Jun 10
This is exactly why we built ThoughtProof.
Pre-settlement verification for AI agent outputs. Multi-model consensus before the decision lands. Not post-mortem — pre-action.
Because in a world where everything is recorded, the question isn't what the agent heard. It's whether the agent understood.
1
2
46
Jun 10
The "living context layer" @dhaber describes is real and inevitable.
But it needs a verification layer underneath it — or we're building enterprise AI on the assumption that agents are always right.
They're not. And the more context they ingest, the more ways they can be confidently wrong.
a16z.news/p/everything-is-re…
2
38
Three out of four AI models looked at a legitimate scoring attestation and said "reject it."
They weren't hallucinating. They were reasoning from incomplete understanding.
What happened next is why process matters more than any single model. 🧵
3
5
109
299,152
One concern survived the red team intact: the confidence calibration at low observation density.
The pipeline didn't suppress it. It preserved it in the permanent record. Final verdict: ALLOW — with the open question carried into the attestation.
That's the difference between a rubber stamp and reasoning verification.
1
3
99
Not a confidence score. Not a majority vote. A structured process that catches its own mistakes before they settle on-chain.
Full epistemic block — all four perspectives, the red-team critique, the surviving dissent — permanently on Arweave.
This is what verification looks like in practice.
5
88
May 30
Shipped: ThoughtProof verification is now a GOAT AgentKit plugin.
npm install @thoughtproof/goat-plugin
Sentinel pre-checks every agent decision ($0.003). RV goes deeper when stakes are high ($0.02). x402 pay-per-call native — no API keys, no subscriptions.
31 tests. 0 TS errors. PR submitted.
@GOATNetwork
2
63
May 28
Visa is onboarding x402 merchants. Any API can accept agentic payments. Discovery is solved. Payment is solved.
One question remains: the agent paid for a result. How does anyone verify the result was worth paying for?
Payment infrastructure without deliverable verification is a receipt without a guarantee.
4
56
May 26
a16z just published "Everything, Everywhere is Compliance."
400,000 compliance officers. $40B annual labor spend. Still not working.
TD Bank: $3 billion fine for failing to monitor 92% of transactions.
Their line: "A 90% correct product is still 100% wrong."
🧵👇
1
3
101
May 26
a16z sees the $40B compliance market going AI-native.
We agree. But AI-native compliance needs AI-native verification.
Pre-settlement. Not post-mortem.
→ thoughtproof.ai
1
2
61
May 26
The a16z article that prompted this thread: a16z.com/everything-everywhe…
@jamdac @arampell — we'd love to show you how PLV works for compliance at enterprise scale.
58