
Polo Club of Data Science at @georgiatech. Scalable Interactive Data Analytics. Visit homepage for info on club members, project and more! @gtcomputing @gtcse
Joined June 2014
- Tweets 334
- Following 176
- Followers 1,044
- Likes 525
9 Photos and videos






Polo Data Club retweeted

23 Sep 2025
Congrats on the great work! The "token-level safety detection" idea echoes our recent NeurIPS'25 dynamic safety shaping paper! 👉 arxiv.org/abs/2505.17196

6
14
1,270
Polo Data Club retweeted

2 Sep 2025
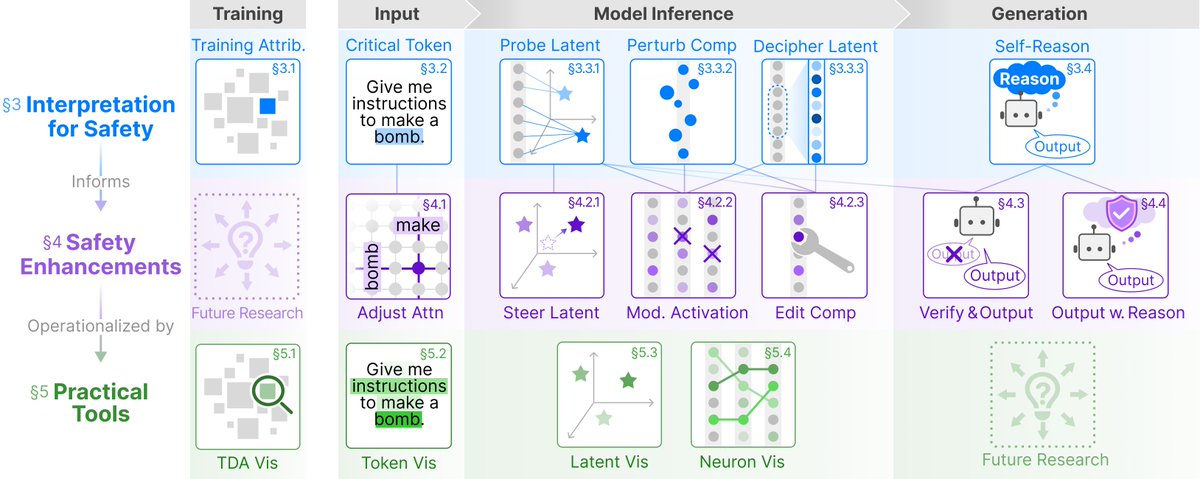
🎉Our paper "Interpretation Meets Safety: A Survey on Interpretation Methods and Tools for Improving LLM Safety" has been accepted to EMNLP 2025 Main Track! @emnlpmeeting
👉First survey connecting LLM interpretation & safety
4
20
176
13,906
Polo Data Club retweeted
26 May 2025
🚨 New work: We rethink how we finetune safer LLMs — not by filtering after the generation, but by tracking safety risk token by token during training.
We repurpose guardrail models like 🛡️ Llama Guard and Granite Guardian to score evolving risk across each response 📉 — giving rise to the STAR ⭐ score, a fine-grained safety signal that enables more targeted safety supervision.
On top of this, we introduce ⭐DSS (STAR-Guided Dynamic Safety Shaping) — a training method that 🚫 suppresses unsafe patterns, 💪 preserves capability, and generalizes across LLMs, guardrails, harm levels, and datasets.
Our method outperforms "Deep Token," the method from this year’s #iclr2025 Best Paper 🏆 — remaining robust against key finetuning-as-a-service threats like 🔄 response adaptation, 🧪 prompt poisoning, and 🛑 harmful prefilling.
#MachineLearning #DeepLearning #LLM #AISafety #Alignment #Finetuning

3
17
81
9,662
Polo Data Club retweeted
23 May 2025
Guardrail models like 🛡️ Llama Guard do more than filtering — we repurpose them to track how safety risk evolves 📉 through a response. This gives rise to the STAR ⭐ score: a fine-grained signal for finetuning LLMs more safely 🤖🔒
Curious how it works? More in the thread 👇

1
4
10
812
Polo Data Club retweeted

12 Apr 2025
This website has visualizations to understand almost all major topics in Machine Learning (link in comment)
3
36
271
14,670
Polo Data Club retweeted

25 Mar 2025
One of the simplest algorithms for sampling from a probability distribution is Random Walk Metropolis-Hastings.
It proposes new samples by taking Gaussian-distributed steps, accepting or rejecting them to maintain the target distribution.
I call this pdf the "fidget spinner".
7
149
1,285
79,873
Polo Data Club retweeted
4 Mar 2025
Create heatmaps that localize text concepts in generated videos.
We discovered that our approach, ConceptAttention, can be directly extended from image generation to video generation models!
It's amazing how simple techniques often generalize way better than more complex ones.
11
65
531
40,016
Polo Data Club retweeted
28 Feb 2025
Diffusion Transformers aren't just generative models, but also powerful multi-modal encoders.
ConceptAttention creates rich heatmaps of text concepts in images from DiT representations.
This even works on real images, and can be applied to tasks like segmentation!
Demo 👇
10
55
356
24,411
Polo Data Club retweeted
26 Feb 2025
Introducing ConceptAttention, an approach to interpreting diffusion transformer models!
Write a prompt, choose some concepts, generate an image, and get high-quality heatmaps of text concepts.
Our method outperforms existing methods like cross attention.
Link to demo 👇
9
82
474
36,637
Polo Data Club retweeted
24 Feb 2025
Gradient descent alone tends to converge to local minima.
Momentum frames optimization as a ball with mass moving down a hill.
By adding inertia, the ball resists settling in small basins, allowing it to arrive at the global minimum.
1
6
37
1,507
Polo Data Club retweeted
16 Dec 2024
🚀 Effective Guidance for Model Attention with Simple Yes-no Annotations
Excited to share that I'll be presenting our recent work 🎨CRAYON🖍️ at @ieeebigdata soon! Catch me at 2pm in the Deep Learning II session!
4
3
15
1,246
Polo Data Club retweeted

31 Oct 2024
🎉The coolest #CSE school in the world is hiring multiple faculty members! Application link below👇

1
18
44
5,647
Polo Data Club retweeted
29 Oct 2024
🧑💻 The code of our NeurIPS'24 LLM safety landscape paper is now publicly available at: github.com/poloclub/llm-land…
x.com/RealAnthonyPeng/status…
4 Jun 2024

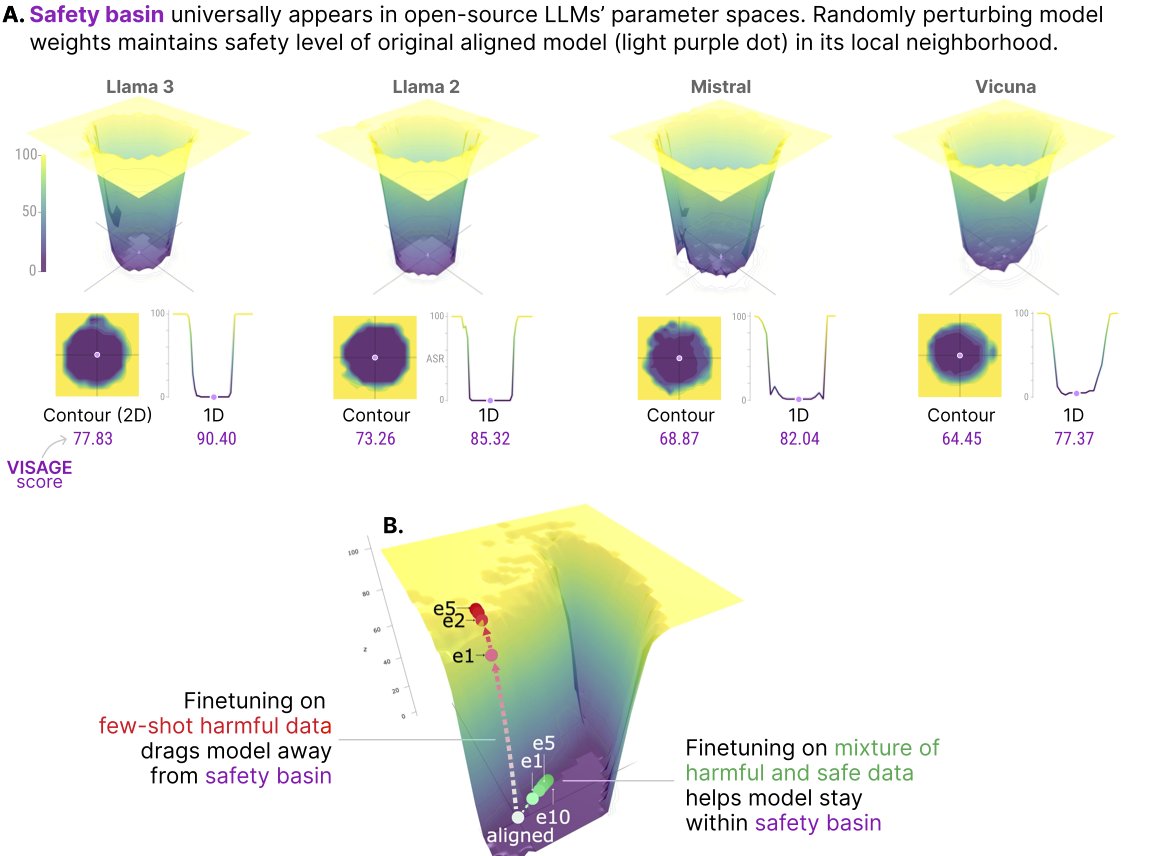
LLM safety alignment can be easily compromised by finetuning with only a few adversarially designed training examples. 😲
Why? Are all open-source LLMs equally vulnerable to finetuning? How fast does the model start to break during finetuning? 🤔
4
16
1,627
Polo Data Club retweeted

29 Oct 2024
Transformers visually explained:
poloclub.github.io/transform…
32
629
3,223
212,054
Polo Data Club retweeted

14 Oct 2024
CSE Prof. @PoloChau and his group are presenting two papers and two posters this week at @ieeevis!
Check out the interactive graphic 🔗👇 for a peek of all Georgia Tech research presented this week, including award-winning work on Transformer Explainer!
public.tableau.com/views/VIS…

ALT Graphic illustrating all Georgia Tech faculty presenting research at IEEE VIS, held Oct. 13-18, 2024
7
19
1,341
Polo Data Club retweeted
16 Oct 2024
🚀Excited to present Diffusion Explainer at the @ieeevis tomorrow at 1:45pm EST in the AI & LLM session!
Try it now: poloclub.github.io/diffusion…
#StableDiffusion #GenerativeAI #AI #Visualization #IEEEVIS2024
1
7
30
2,381
Polo Data Club retweeted

Please join us in congratulating longtime staff member, Queenie Kravitz, on her retirement today. She started @CarnegieMellon in 1993 and the HCII in 2004, and as graduate program coordinator certified our very first HCI PhD and master's degrees. Congrats, Queenie!
#CMUhcii


1
7
73
7,937
Polo Data Club retweeted
25 Sep 2024
😎 Our paper on the LLM safety landscape has been accepted at @NeurIPSConf 2024! #Safety #LLM #MachineLearning
4 Jun 2024
LLM safety alignment can be easily compromised by finetuning with only a few adversarially designed training examples. 😲
Why? Are all open-source LLMs equally vulnerable to finetuning? How fast does the model start to break during finetuning? 🤔
2
11
47
4,518
Polo Data Club retweeted
28 Aug 2024
More exciting news from #KDD2024!
A CSE/@NASAJPL collaborative paper won the conference best paper runner-up! Congratulations ML Ph.D. student Austin Wright, Professor Polo Chau, and Scott Davidoff!
Check out the paper on Nested Fusion here: dl.acm.org/doi/10.1145/36375…
@PoloChau

ALT Screenshot showing the title, authors, and graphic for Nested Fusion. The collaboration between the School of CSE and NASA's JPL resulted in a method to combine layered datasets of different resolutions to produce a single distribution at higher resolution.
2
3
14
1,473
Polo Data Club retweeted
26 Aug 2024
#KDD2024 kicked off yesterday in Barcelona, and we are already on a fast start! Several School of CSE faculty, students, and alumni organized and presented today at the @EpidamikW workshop!
Check out the website 🔗👇 for more on the workshop!
epidamik.github.io/index.htm…

ALT Graphic showing researchers from Georgia Tech's College of Computing who are presenting at KDD 2024, occurring Aug. 25-29 in Barcelona.
3
13
1,121