
Joined January 2026
- Tweets 1,901
- Following 165
- Followers 381
- Likes 4,773
253 Photos and videos
















Pinned Tweet

Mar 14
Python slicing Explained ❤️🔥
SYNTAX - s[start:stop:step]
✅ s[1:4] → chars at index 1,2,3 not 4
✅ s[:3] → first 3
✅ s[-1] → last item
✅ s[::-1] → reversed 🔄
✅ s[:] → copy
🔶stop is exclusive.
🔶step -1 reverses.
🔶omit any part = use default.
Works on strings, lists & tuples.
#Python #CodingTips #LearnToCode


2
7
66
15,020
PyBerry Tech 🐍🍓 retweeted
Feb 26
Python Inheritance explained in one diagram 🧬
🔶Single 🚥 One parent, one child
🔶Multiple 🚥 Many parents, one child
🔶Multilevel 🚥 Chain inheritance
🔶Hierarchical 🚥 One parent, many children
🔶Hybrid 🚥 Mix of all types
Inheritance = Cleaner code Reusability
#Python #LearnToCode #100DaysOfCode

1
2
7
516
PyBerry Tech 🐍🍓 retweeted
Feb 27
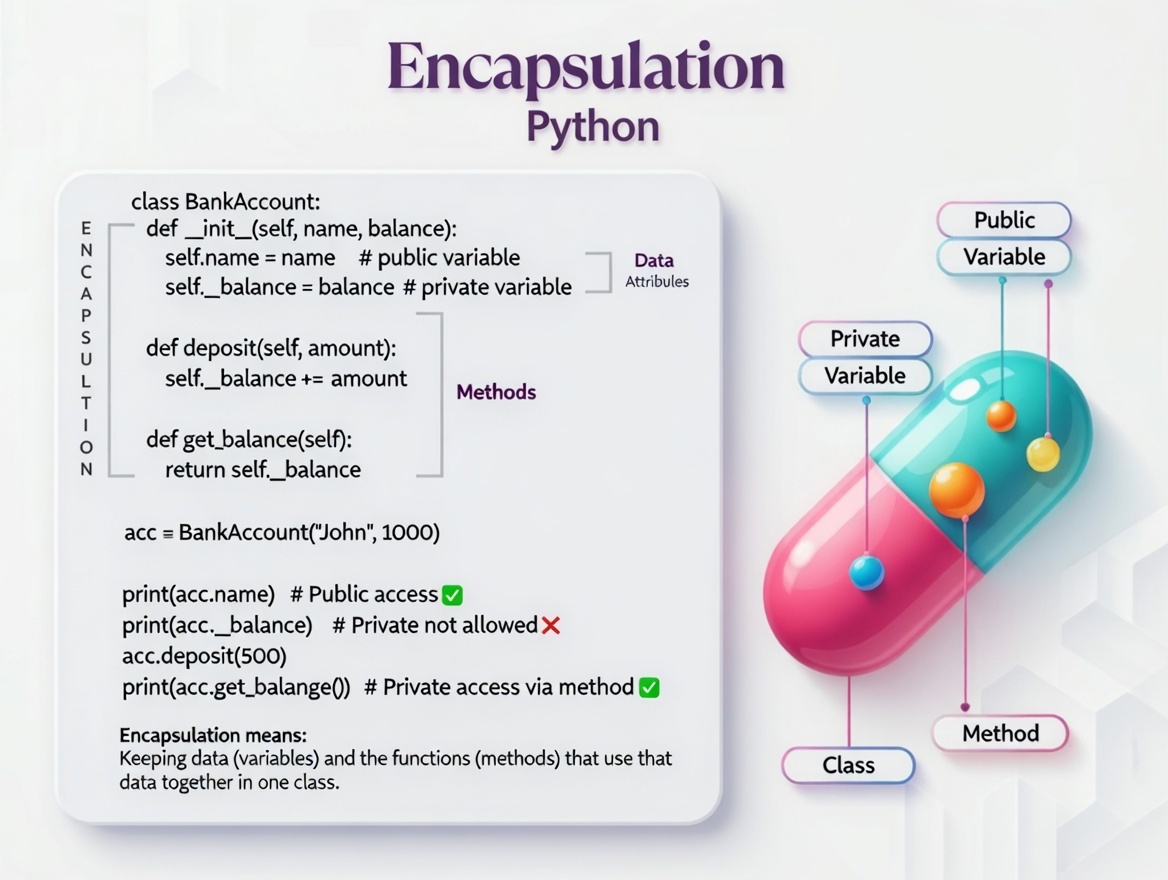
Python Encapsulation Made Simple ⭐
Encapsulation bundles data and methods into a single class. It acts like a protective shield, hiding internal details and allowing access only through specific paths. This keeps your code secure, organized, and easy to maintain. 🛡️💻
#Python #CodingTips #OOP #Programming
1
1
8
357
PyBerry Tech 🐍🍓 retweeted
Feb 28
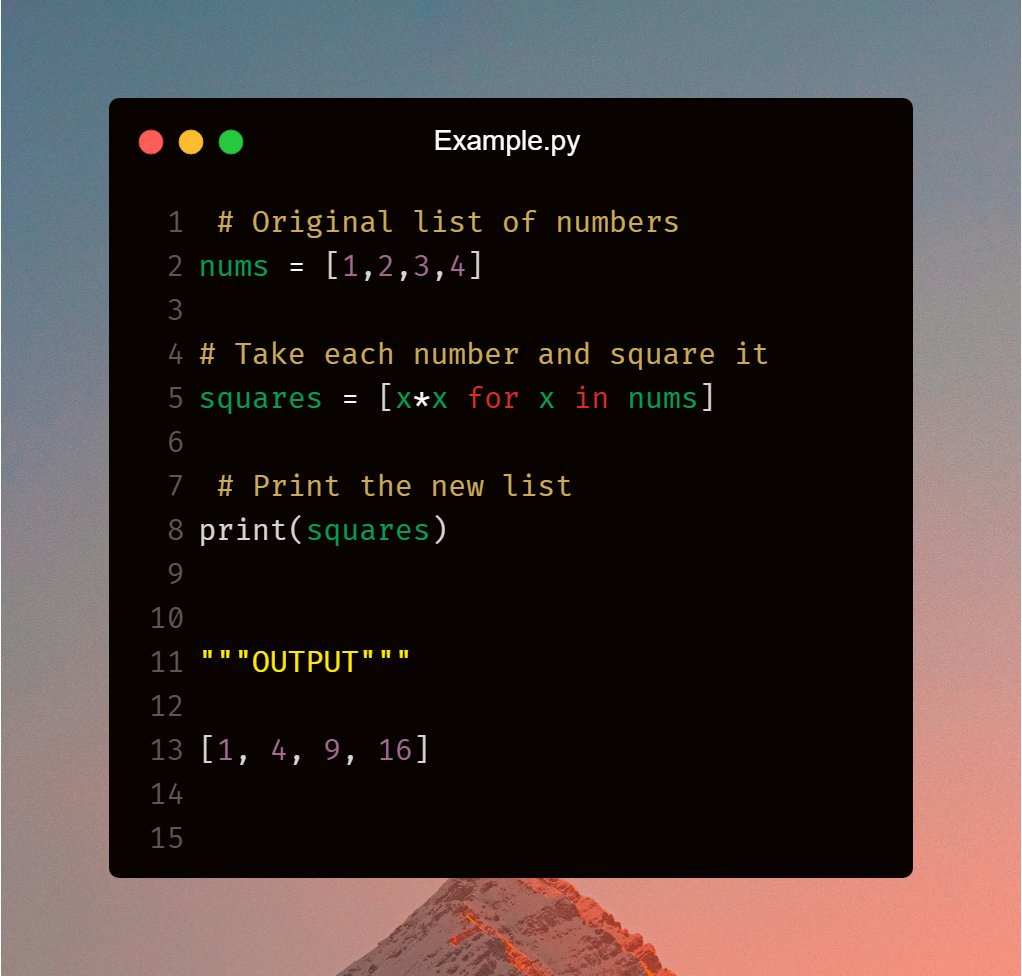
#Python Comprehension Explained 🐍
Comprehension is a short way to create lists, sets, or dictionaries in one line.
List Comprehension Example 👇
🔶Simple Idea 🔑
❌ Instead of:
result = []
for x in nums:
result.append(x*x)
✅ We write:
result = [x*x for x in nums]
#LearnPython #pythonprogramming #coding
1
8
397
Apr 10
Virtualization vs Containerization Explained 👇
Apr 10

Virtualization vs Containerization
𝗩𝗶𝗿𝘁𝘂𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 (VMs) gives each workload its own full machine with its own guest OS and kernel. Great for isolation and OS flexibility, but you’re paying the cost of booting and managing entire operating systems for every workload.
𝗖𝗼𝗻𝘁𝗮𝗶𝗻𝗲𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 runs workloads as isolated processes on a shared OS. It’s fast and efficient; but with weaker isolation and more constraints around security and OS compatibility.
VMs give you strong boundaries and full environments. Containers give you speed and efficient delivery.
If you’ve used VMs, you know the pain isn’t the VM; it’s everything around it: provisioning, networking, exposure, and persistence.
That’s where exe[.]dev comes in.
It gives you instant VMs over SSH, with:
• Built-in HTTPS exposure
• Persistent environments
• Zero cloud config overhead
• Safe sandbox execution layer for agents (with secure credential injection via Integrations)
When infra is this fast to spin up, you stop hesitating and start testing.
Check it out → lucode.co/exe-dot-dev-z7xd
What else would you add?
——
♻️ Repost to help others learn and grow.
🙏 Thanks to @ssh_exe_dev for sponsoring this post.
➕ Follow me ( Nikki Siapno ) to become good at system design.

1
186
Apr 6
SQL Joins 👇


1
1
5
245
Apr 5
32 Claude shortcut hacks 👇
Apr 5

32 Claude shortcut hacks for faster prompts:
(worth saving for later)
Add one of these at the very start of your prompt.
Example: ELI5: [your topic] → get a simple, kid-friendly explanation.
——
/ELI5 is used to explain as if to a 5-year-old.
/TLDL summarizes a very long text in a few lines.
/STEP-BY-STEP lays out reasoning step by step.
/CHECKLIST turns a response into a checklist.
/EXEC SUMMARY gives a quick executive-style summary.
/ACT AS makes ChatGPT speak in a specific role.
/BRIEFLY forces a very short answer.
/JARGON asks to use technical vocabulary.
/AUDIENCE adapts the response to a chosen audience.
/TONE changes the tone (formal, funny, dramatic, etc.).
/DEV MODE simulates a raw, technical developer style.
/PM MODE gives a project-management perspective.
/SWOT produces a strengths/weaknesses/opportunities/threats analysis.
/FORMAT AS enforces a specific format (table, JSON, etc.).
/COMPARE puts two or more things side by side.
/MULTI-PERSPECTIVE shows several points of view.
/CONTEXT STACK keeps multiple layers of context in memory.
/BEGIN WITH / END WITH forces starting or ending with something.
/ROLE: TASK: FORMAT: explicitly defines the role, the task, and the expected format.
/SCHEMA generates a structured outline or a data model.
/REWRITE AS: rephrases in a requested style.
/REFLECTIVE MODE prompts the AI to reflect on its own answer.
/SYSTEMATIC BIAS CHECK asks to identify biases.
/DELIBERATE THINKING forces slower, more thoughtful reasoning.
/NO AUTOPILOT forbids superficial, autopilot responses.
/EVAL-SELF asks for a critical self-evaluation of the response.
/PARALLEL LENSES examines from several angles in parallel.
/FIRST PRINCIPLES rebuilds from fundamental basics.
/CHAIN OF THOUGHT shows intermediate reasoning.
/PITFALLS identifies possible traps and errors.
/METRICS MODE expresses answers with measures and indicators.
/GUARDRAIL sets strict boundaries not to cross.
——
After months of testing Claude, I built a single prompt library with every prompt I personally use.
To access it, complete these 4 steps:
1. Subscribe (for free) → how-to-ai.guide.
2. Open my welcome email.
3. Hit the automatic reply button inside.
4. Receive your prompt library bonus video.

1
4
237
PyBerry Tech 🐍🍓 retweeted
Feb 25
Tuple is immutable… but not everything inside it 👀
Tuple can't change ❌
List inside tuple can change ✅
Immutability stops at the container. 🧠🐍
#Python #Coding #LearnPython #Programming #PythonTips #DevCommunity #100DaysOfCode

1
1
10
310
PyBerry Tech 🐍🍓 retweeted
Mar 17
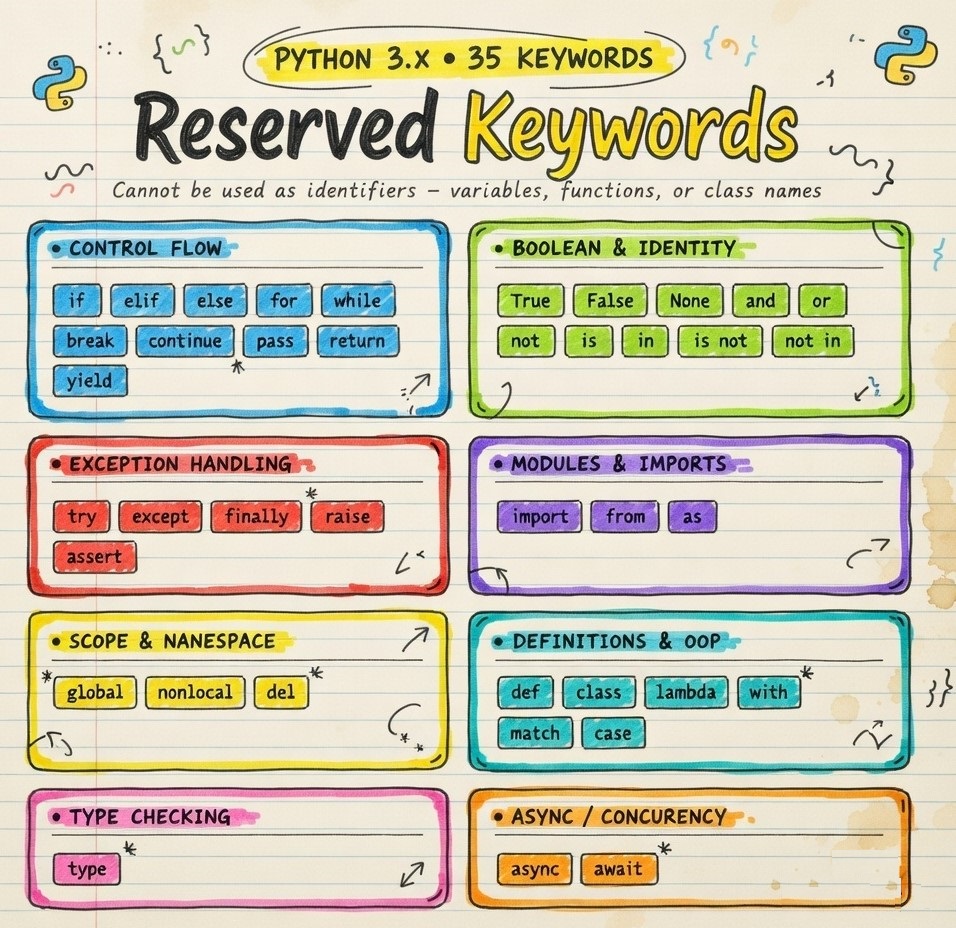
🐍 Python has 35 reserved keywords
You CANNOT use them as variable names, function names, or class names. Ever.
Here's every keyword, color-coded by category 👇
Save this. Share it. Come back to it. 🔖
#Python #Programming #LearnPython #CodeNewbie #100DaysOfCode #SoftwareEngineering
1
11
512
PyBerry Tech 🐍🍓 retweeted
Mar 27
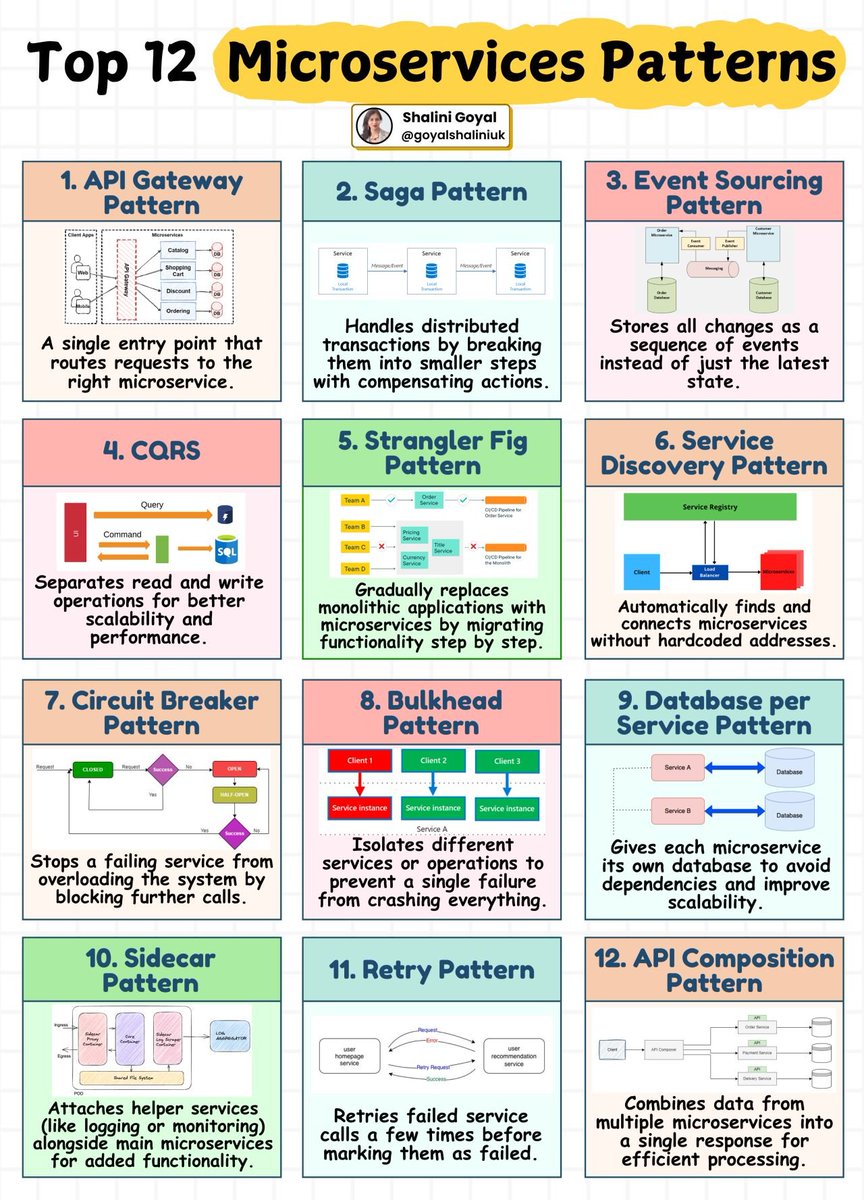
Top 12 Microservices Patterns👇
Mar 27

Master These 12 Microservices Patterns to Build Scalable Systems!
Microservices architecture is all about scalability, resilience, and efficiency—but without the right design patterns, things can get messy fast!
Here are 12 essential microservices patterns every developer should know:
1. API Gateway Pattern – A single entry point that routes requests to the right microservice.
2. Saga Pattern – Breaks distributed transactions into smaller steps with compensating actions.
3. Event Sourcing Pattern – Stores all changes as a sequence of events instead of just the latest state.
4. CQRS – Separates read and write operations for better scalability and performance.
5. Strangler Fig Pattern – Gradually replaces monolithic applications with microservices.
6. Service Discovery Pattern – Automatically finds and connects microservices without hardcoded addresses.
7. Circuit Breaker Pattern – Stops a failing service from overloading the system by blocking further calls.
More in graphics below.
Consider reposting if you found this helpful!
1
5
532
PyBerry Tech 🐍🍓 retweeted
Mar 22
🔶Most Python devs don't know about __slots__ :- it can cut memory usage by ~40% when you have millions of objects.
🔶By default, every Python object stores attributes in a __dict__ (a hashmap).
🔶__slots__ replaces it with a fixed array. The difference is wild:
👀Worth it when you're creating millions of objects (data pipelines, game entities, parsers).
#Python #Programming #SoftwareEngineering

1
2
9
423
Apr 2
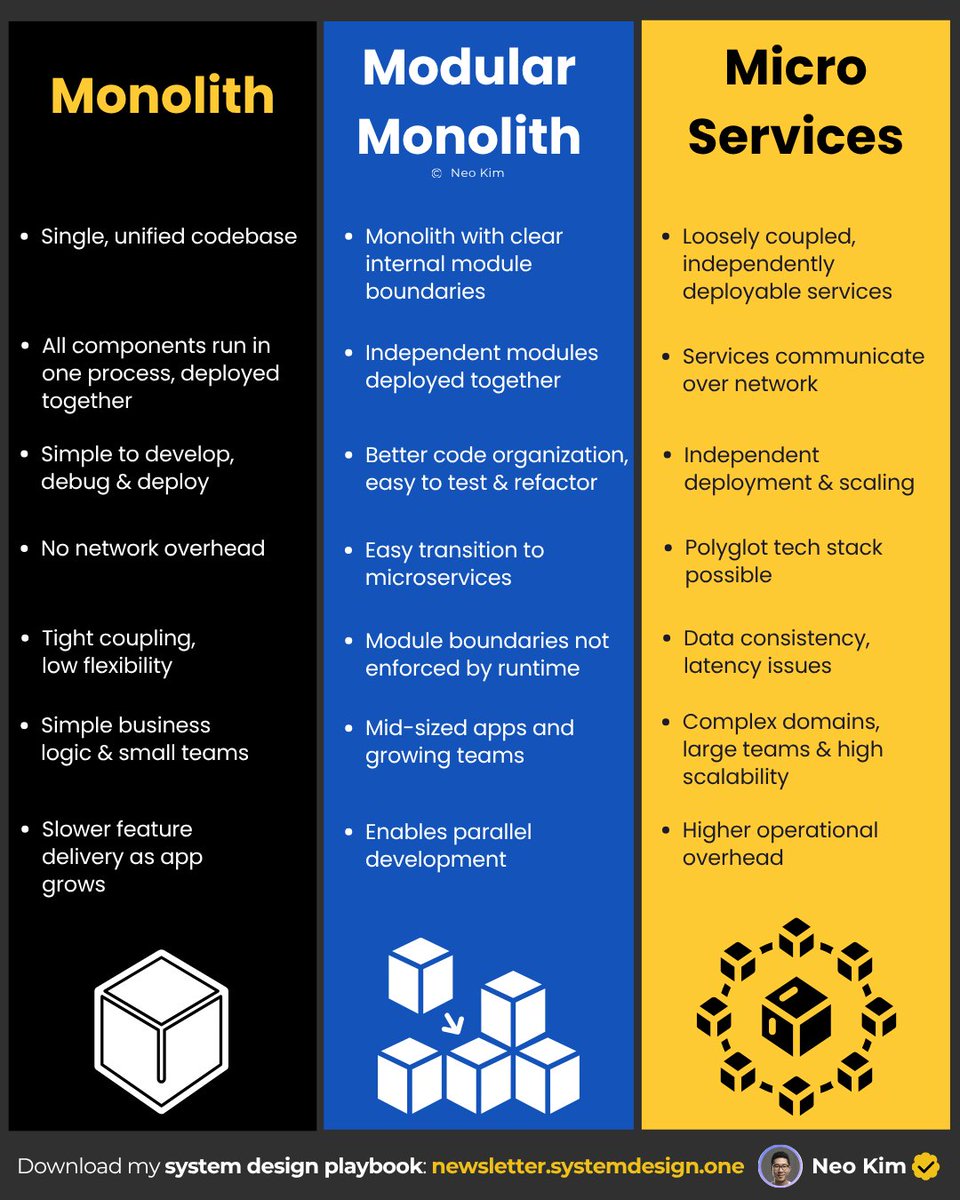
Monolith vs Modular Monolith vs Microservices 👇
Apr 1

If I had to build an app, here are 3 architectures I'd consider:
1 Monolith
↳ An all-in-one application structure that is run as a single service.
2 Modular Monolith
↳ An app structured as independent, loosely coupled modules that can be deployed together.
3 Microservices
↳ Loosely coupled, independently deployable services.
Don't forget, each architecture has tradeoffs.
What else would you add to this list?
3
134
Apr 1
LLM Fine tuning technique explained 👇
Apr 1

I have been fine-tuning LLMs for over 2 years now!
Here are the top 5 LLM fine-tuning techniques, explained with visuals:
First of all, what's so different about LLM finetuning?
Traditional fine‑tuning is impractical for LLMs (billions of params; 100s GB).
Since this kind of compute isn't accessible to everyone, parameter-efficient finetuning (PEFT) came into existence.
Before we go into details of each technique, here's some background that will help you better understand these techniques:
LLM weights are matrices of numbers adjusted during finetuning.
Most PEFT techniques involve finding a lower-rank adaptation of these matrices, a smaller-dimensional matrix that can still represent the information stored in the original.
Now with a basic understanding of the rank of a matrix, we're in a good position to understand the different finetuning techniques.
(refer to the image below for a visual explanation of each technique)
1) LoRA
- Add two low-rank trainable matrices, A and B, alongside weight matrices.
- Instead of fine-tuning W, adjust the updates in these low-rank matrices.
Even for the largest of LLMs, LoRA matrices take up a few MBs of memory.
2) LoRA-FA
While LoRA significantly decreases the total trainable parameters, it requires substantial activation memory to update the low-rank weights.
LoRA-FA (FA stands for Frozen-A) freezes matrix A and only updates matrix B.
3) VeRA
- In LoRA, low-rank matrices A and B are unique for each layer.
- In VeRA, A and B are frozen, random, and shared across all layers.
- Instead, it learns layer-specific scaling VECTORS (b and d) instead.
4) Delta-LoRA
- It tunes the matrix W as well, but not in the traditional way.
- Here, the difference (or delta) between the product of matrices A and B in two consecutive training steps is added to W.
5) LoRA
- In LoRA, both matrices A and B are updated with the same learning rate.
- Authors of LoRA found that setting a higher learning rate for matrix B results in better convergence.
____
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.

4
162
Apr 1
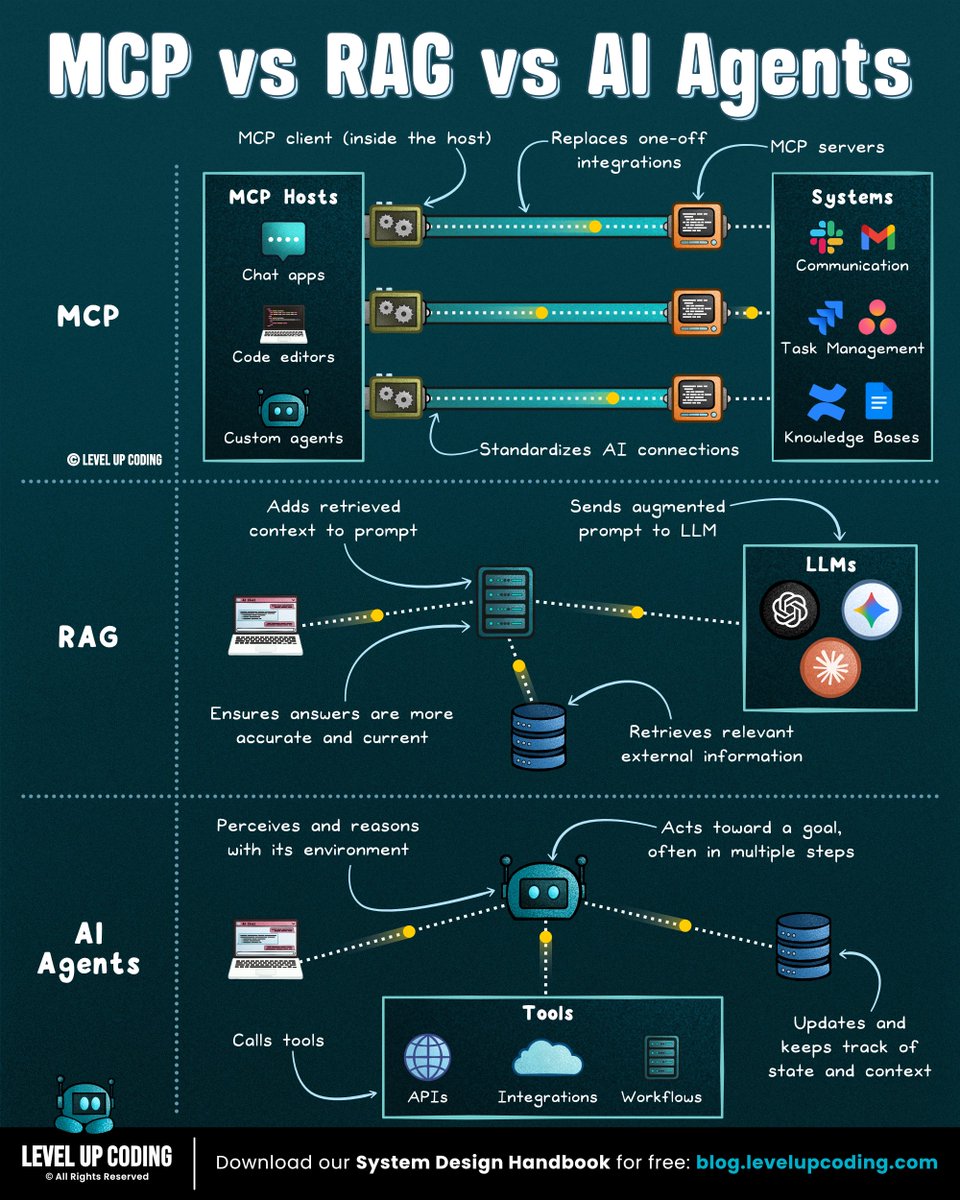
MCP vs RAG vs AI Agents Explained 👇
Apr 1
MCP vs RAG vs AI Agents
To understand modern AI systems, you need to understand how these three pieces fit together.
𝗥𝗔𝗚 = “𝗚𝗶𝘃𝗲 𝘁𝗵𝗲 𝗺𝗼𝗱𝗲𝗹 𝗯𝗲𝘁𝘁𝗲𝗿 𝗮𝗻𝘀𝘄𝗲𝗿𝘀”
RAG retrieves relevant data, injects it into the prompt, and generates a grounded response. It’s best when your problem is answering questions using your docs, reducing hallucinations, or showing sources and citations. RAG improves what the model knows, not what it can do.
If you’re building with these patterns, here's a great guide on scaling multi-agent RAG systems: lucode.co/multi-agent-rag-ar…
𝗠𝗖𝗣 = “𝗦𝘁𝗮𝗻𝗱𝗮𝗿𝗱𝗶𝘇𝗲𝗱 𝘁𝗼𝗼𝗹 𝗮𝗻𝗱 𝗱𝗮𝘁𝗮 𝗮𝗰𝗰𝗲𝘀𝘀”
MCP is a standardized interface between LLMs and external systems like APIs, databases, and apps. Use it when your model needs to query data, call services, or interact with real systems (Slack, GitHub, etc). MCP doesn’t decide actions, it defines how tools are exposed.
𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀 = “𝗠𝗮𝗸𝗲 𝘁𝗵𝗲 𝗺𝗼𝗱𝗲𝗹 𝘁𝗮𝗸𝗲 𝗮𝗰𝘁𝗶𝗼𝗻”
Agents operate in a loop: observe → plan → act → repeat, often using tools and memory. Use them when your problem requires multi-step reasoning, tool usage with verification, or full task execution. Agents start where RAG stops, turning decisions into actions and outcomes.
The simple mental model:
RAG → knowledge layer
MCP → tool layer
Agents → execution layer
Not every system needs all three explicitly, but complex ones often combine them.
If you want to see what this looks like in practice, this guide walks you through building a scalable multi-agent RAG system.
Check it out: lucode.co/multi-agent-rag-gu…
What else would you add?
♻️ Repost to help others learn AI.
🙏 Thanks to @Oracle for sponsoring this post.
2
116
PyBerry Tech 🐍🍓 retweeted
Mar 1
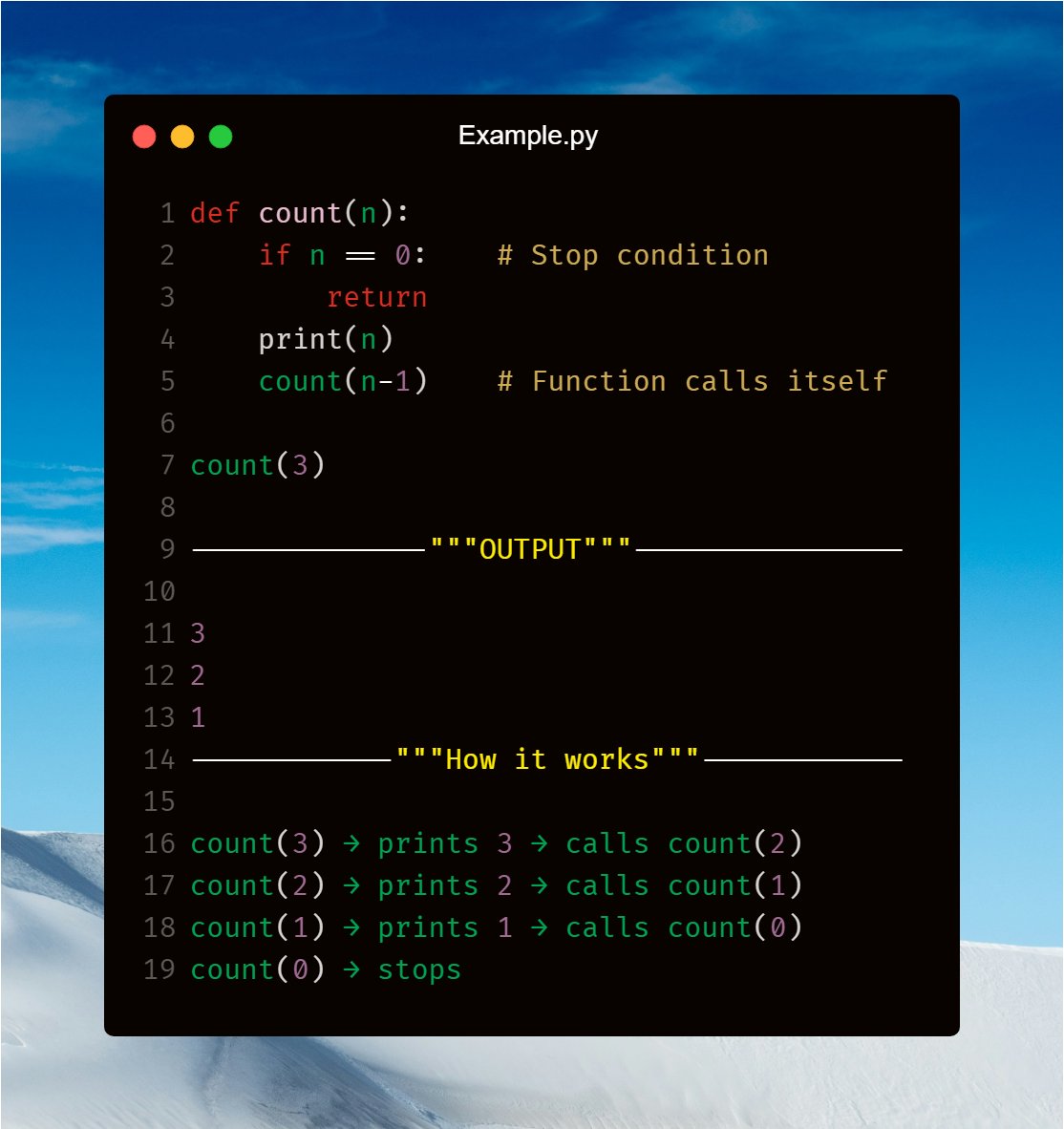
🔶 Recursion in Python Explained 🐍
Recursion is when a function calls itself to solve a problem.
⭐ Important Rule ⭐
Every recursive function needs a stop condition.
#Python #Recursion #LearnPython #CodingConcepts #Programming

2
4
355
PyBerry Tech 🐍🍓 retweeted
Mar 15

1
2
9
453
Mar 30
🚨Software Engineering is Rapidly changing 🚨
In one prompt Claude can write the code run it open the app test it find the bug fix it and check that it works👇

Computer use is now in Claude Code.
Claude can open your apps, click through your UI, and test what it built, right from the CLI.
Now in research preview on Pro and Max plans.
2
123
Mar 30
Vector Database Fundamentals 👇
Mar 30

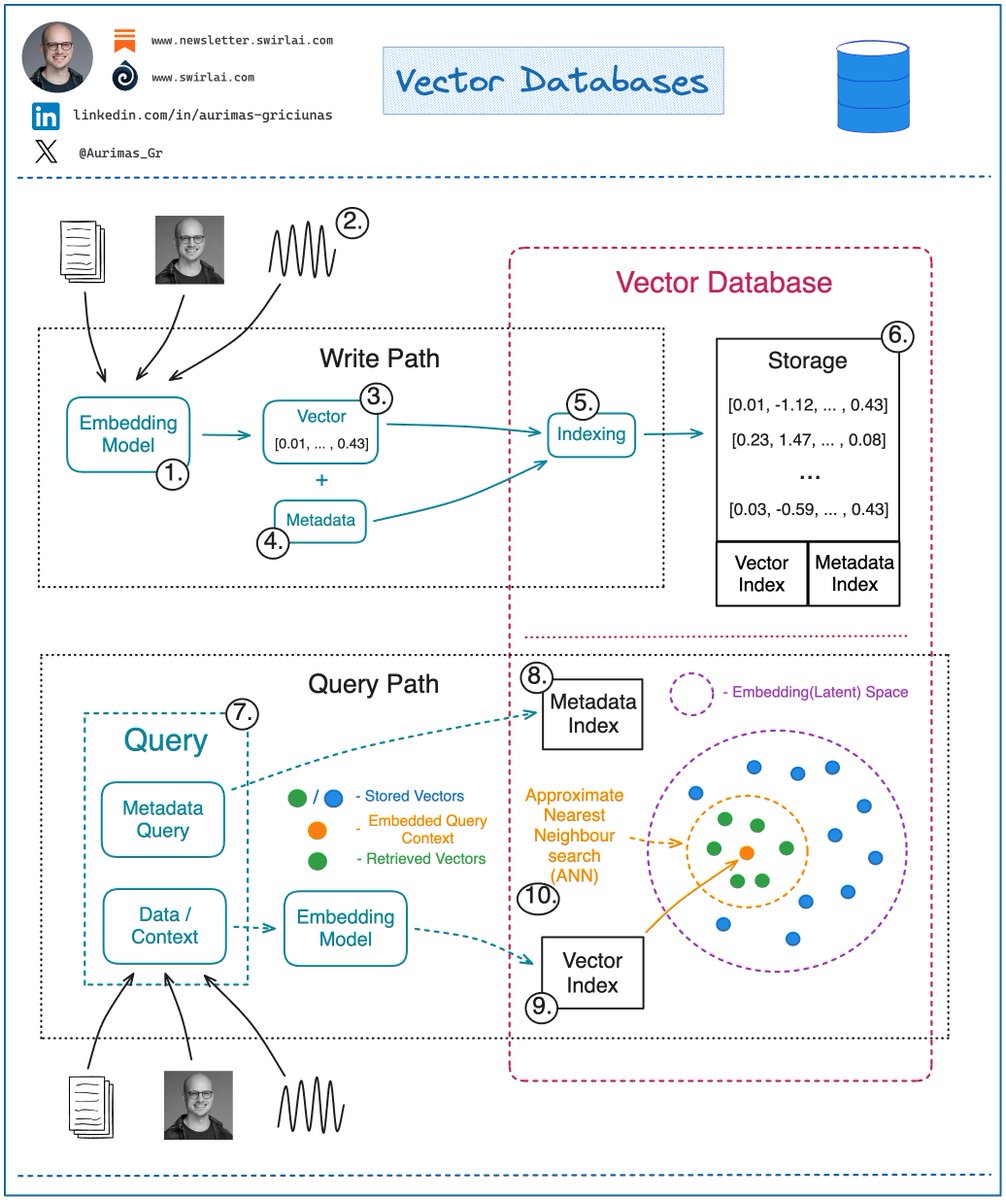
Fundamentals of a 𝗩𝗲𝗰𝘁𝗼𝗿 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲.
With the rise of GenAI, Vector Databases skyrocketed in popularity. The truth - Vector Databases are also useful outside of a Large Language Model context.
When it comes to Machine Learning, we often deal with Vector Embeddings. Vector Databases were created to perform specifically well when working with them:
➡️ Storing.
➡️ Updating.
➡️ Retrieving.
When we talk about retrieval, we refer to retrieving set of vectors that are most similar to a query in a form of a vector that is embedded in the same Latent space. This retrieval procedure is called Approximate Nearest Neighbour (ANN) search.
A query here could be in a form of an object like an image for which we would like to find similar images. Or it could be a question for which we want to retrieve relevant context that could later be transformed into an answer via a LLM.
Let’s look into how one would interact with a Vector Database:
𝗪𝗿𝗶𝘁𝗶𝗻𝗴/𝗨𝗽𝗱𝗮𝘁𝗶𝗻𝗴 𝗗𝗮𝘁𝗮.
1. Choose a ML model to be used to generate Vector Embeddings.
2. Embed any type of information: text, images, audio, tabular. Choice of ML model used for embedding will depend on the type of data.
3. Get a Vector representation of your data by running it through the Embedding Model.
4. Store additional metadata together with the Vector Embedding. This data would later be used to pre-filter or post-filter ANN search results.
5. Vector DB indexes Vector Embedding and metadata separately. There are multiple methods that can be used for creating vector indexes, some of them: Random Projection, Product Quantization, Locality-sensitive Hashing.
6. Vector data is stored together with indexes for Vector Embeddings and metadata connected to the Embedded objects.
𝗥𝗲𝗮𝗱𝗶𝗻𝗴 𝗗𝗮𝘁𝗮.
7. A query to be executed against a Vector Database will usually consist of two parts:
➡️ Data that will be used for ANN search. e.g. an image for which you want to find similar ones.
➡️ Metadata query to exclude Vectors that hold specific qualities known beforehand. E.g. given that you are looking for similar images of apartments - exclude apartments in a specific location.
8. You execute Metadata Query against the metadata index. It could be done before or after the ANN search procedure.
9. You embed the data into the Latent space with the same model that was used for writing the data to the Vector DB.
10. ANN search procedure is applied and a set of Vector embeddings are retrieved. Popular similarity measures for ANN search include: Cosine Similarity, Euclidean Distance, Dot Product.
How are you using Vector DBs? Let me know in the comment section!
1
90
Mar 30
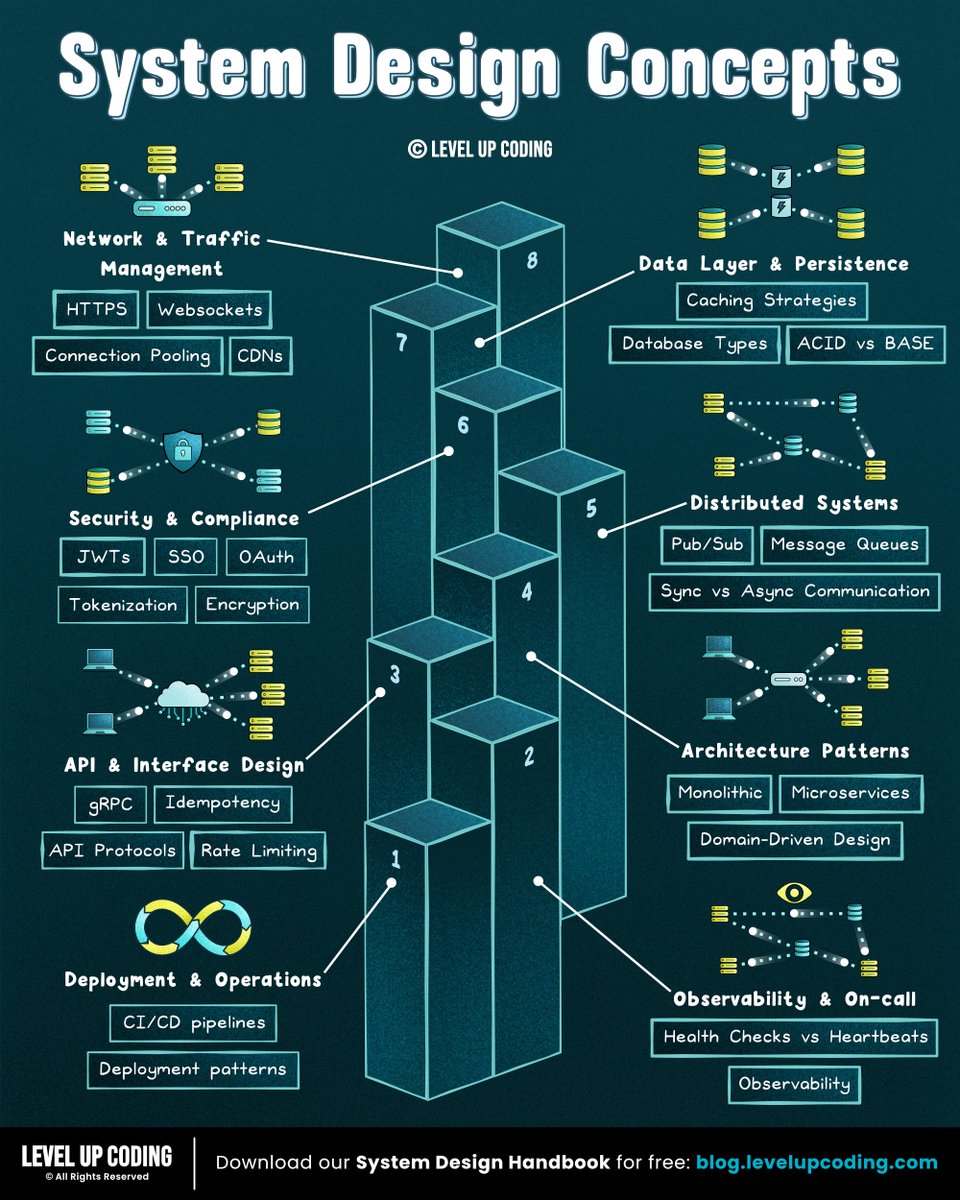
System Design Concept 👇
Mar 30
If I had to learn system design from scratch,
here’s what I’d do.
Most people learn system design like this:
→ Random topics
→ Disconnected concepts
→ Memorizing patterns
Instead, think in layers.
Full pathway here: lucode.co/system-design-hand…
Start with fundamentals → then scaling patterns → then distributed systems → then trade-offs.
I turned that into a 142-page handbook to make system design actually click.
Inside you'll find breakdowns of concepts like:
↳ gRPC
↳ JWT
↳ Load balancing
↳ ACID vs BASE
↳ Microservices
…and dozens more.
Get it here (for free): lucode.co/system-design-hand…
♻️ Repost to help others learn system design.
➕ Follow me ( Nikki Siapno ) to improve at system design.
1
79
Mar 29
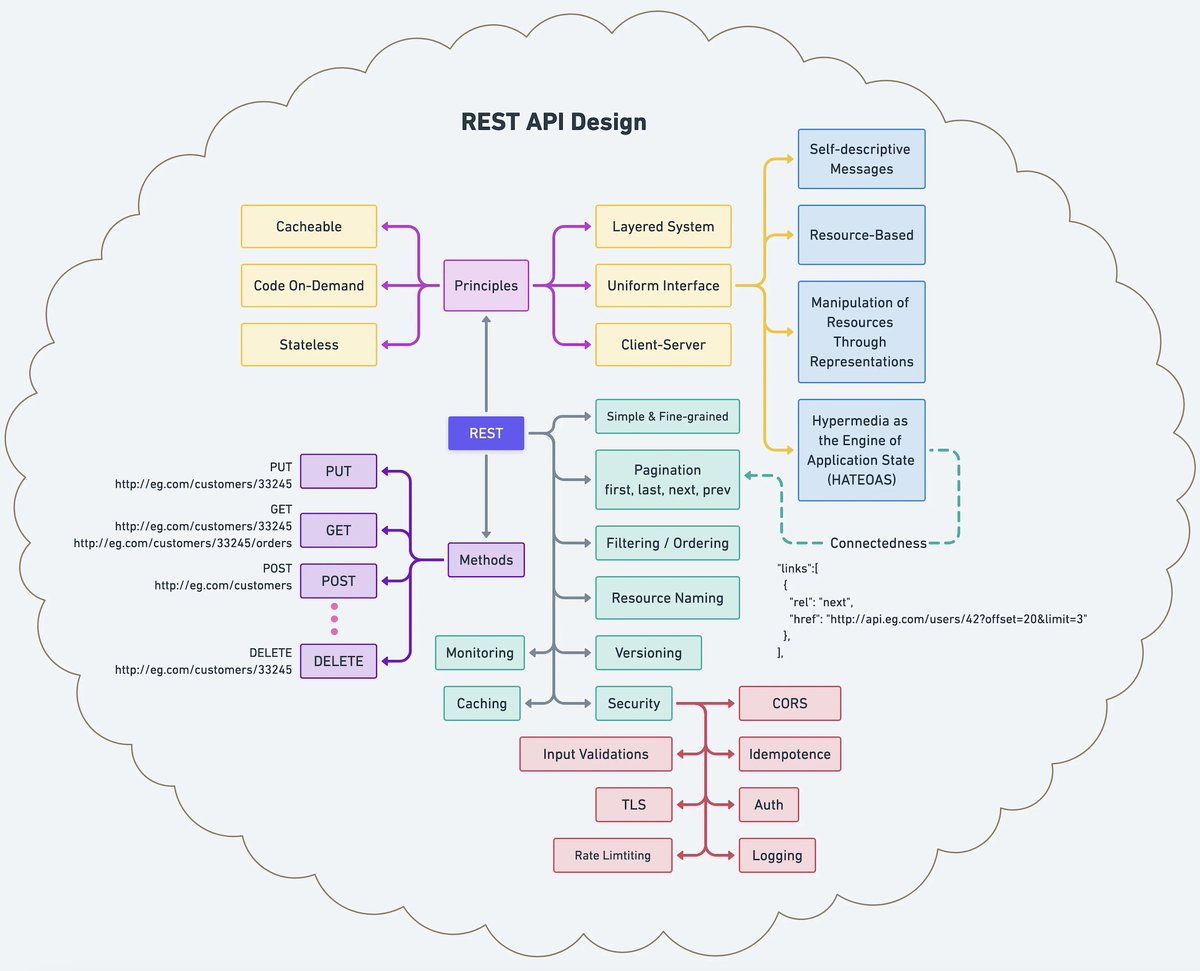
REST API Working Explained 👇

1
98
PyBerry Tech 🐍🍓 retweeted

Mar 29
Microsoft did it again!
Building with AI agents almost never works on the first try.
A dev has to spend days tweaking prompts, adding examples, hoping it gets better.
This is exactly what Microsoft's Agent Lightning solves.
It's an open-source framework that trains ANY AI agent with reinforcement learning. Works with LangChain, AutoGen, CrewAI, OpenAI SDK, or plain Python.
Here's how it works:
> Your agent runs normally with whatever framework you're using. Just add a lightweight agl.emit() helper or let the tracer auto-collect everything.
> Agent Lightning captures every prompt, tool call, and reward. Stores them as structured events.
> You pick an algorithm (RL, prompt optimization, fine-tuning). It reads the events, learns patterns, and generates improved prompts or policy weights.
> The Trainer pushes updates back to your agent. Your agent gets better without you rewriting anything.
In fact, you can also optimize individual agents in a multi-agent system.
I have shared the link to the GitHub repo in the replies!

86
203
1,332
111,680