
Joined January 2024
- Tweets 17,296
- Following 832
- Followers 471
- Likes 41,657
1,557 Photos and videos









Pinned Tweet

Jun 12
GPT-5.5 Pro is going to be included in the Pro plan in Codex

23
26
802
192,521
23h
Kimi Code is as good in FrontierMath Tier 4 as GPT-5 mini and GPT-5.4 nano 🙈
10
3
89
11,676
Raphi-2Code retweeted

Jun 13
It’s easier than ever to use ChatGPT - and in the future other third-party AI models installed via the App Store - inside of Siri and the Siri app. All the prep work is in there for Siri to be a platform for both Apple’s own AI and rival options.

57
81
2,171
196,058
Jun 13
🥀

Claude Fable 5 result for FrontierMath T4 has just come in and it is vastly SoTA.
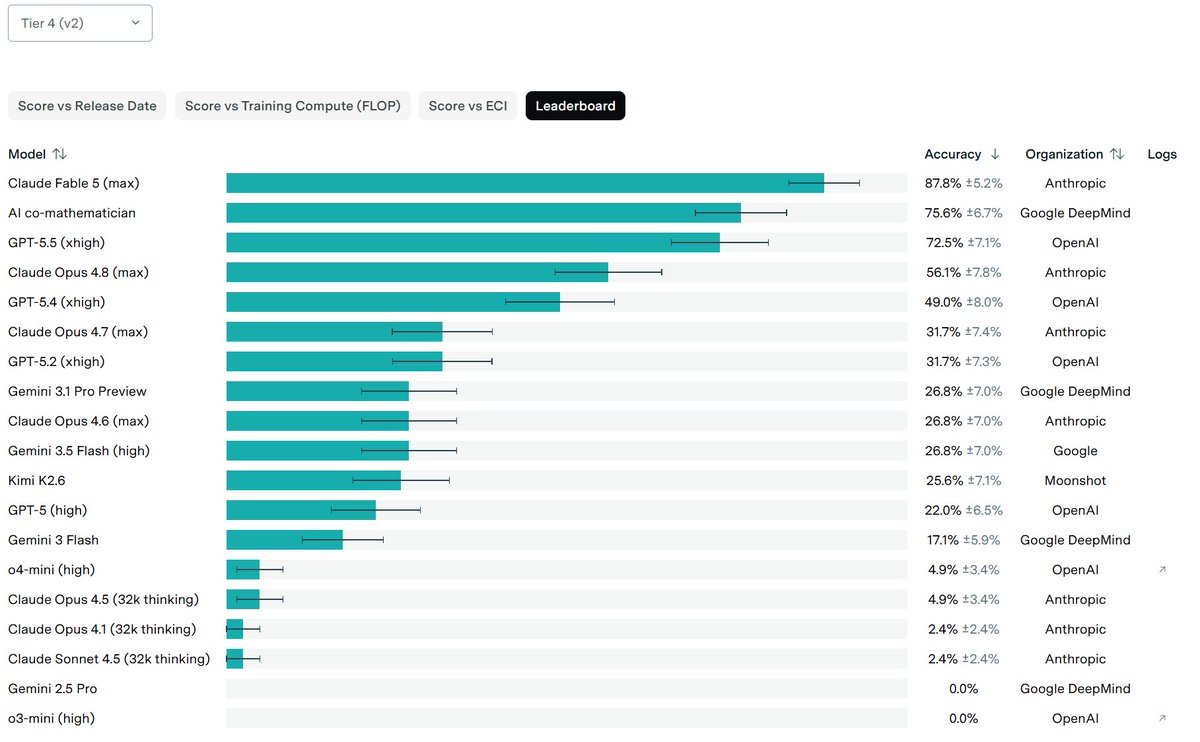
1
147
Jun 13
what?
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
2
1
8
303


Jun 12
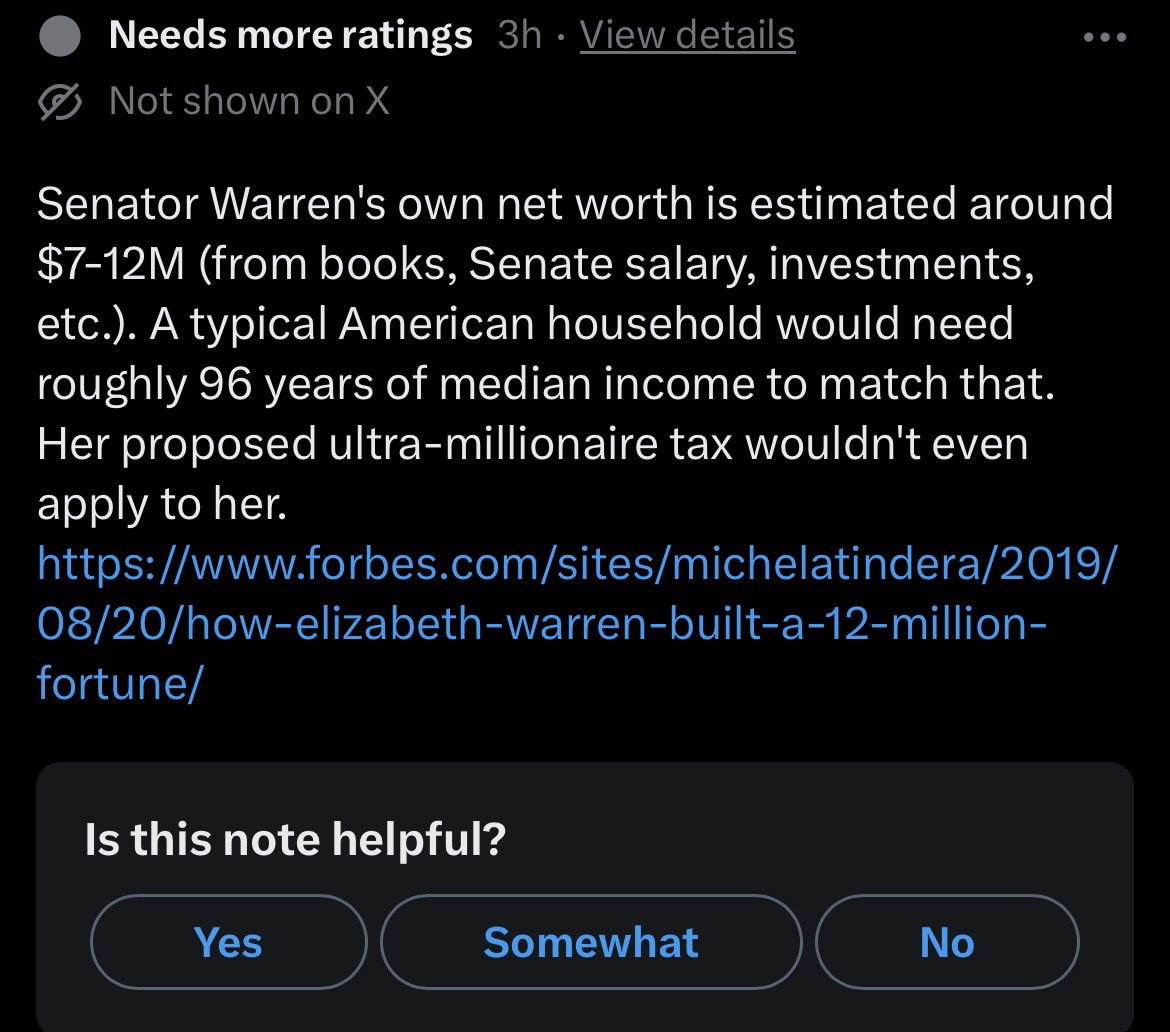
“Effective Altruism”

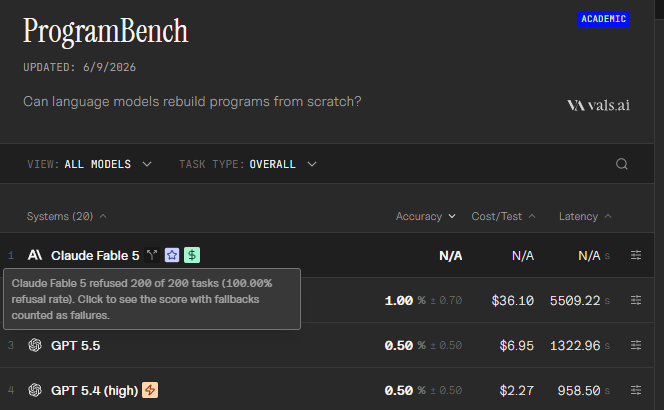
10
1,489
Jun 12
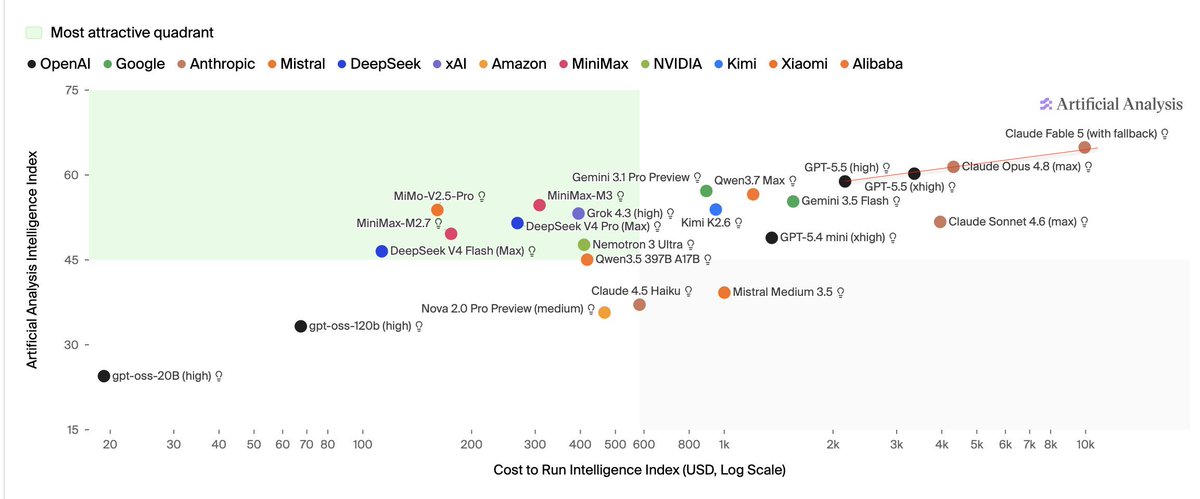
Wow! This is even cheaper as the trend!
Jun 11

Cost token data from @ArtificialAnlys is finally out (this level of detail is what makes them such a useful benchmark🙂). More or less as guessed: incremental boost on benches vs opus 4.8, but more than 2x the cost ( 130%). 4.5x the cost of gpt 5.5 high for ~10% better perf.




2
1
23
2,105
Jun 12
what????

11
2,555
Jun 12
WHAT? WOW???

We heard you wanted to use Codex rate limit resets on your own time.
Starting today, we’re rolling out the ability to save rate limit resets to use later.
We’re starting Go, Plus, Pro, and Business users with one free reset:
6
984
Jun 12
WhHAT???
1
2
34
7,214

GPT-5.5 (xHigh) ranks #2 on Agent Arena ( 10.6% net improvement), making it the highest-ranked OpenAI model closely behind Claude Fable 5 (High).
Per signal breakdown, GPT-5.5 (xHigh) ranks #1 in Praise vs. Complaint ( 29.4%) and Bash Recovery ( 14.1%), scoring higher than Claude Fable 5 (High) on both signals. It trails Claude Fable 5 (High) on Confirmed Success ( 5.4% vs. 17.6%) and Steerability ( 1.9% vs. 5.4%).
Agent Arena evaluates models on millions of real-world, long-horizon agentic tasks. Models use tools like web search, filesystem, and terminal to complete complex workflows: writing code, creating slide decks, researching the web, building apps, and analyzing documents.
We use causal tracing to measure model performance across real-world agentic tasks. More breakdown of GPT-5.5 (xHigh) across five signals in the thread.


Introducing Agent Mode: Agentic AI is now measured in the Arena.
Agent Mode can do deep research, create reports, generate images, build websites, debug code, and more.
It completes more complex tasks by using tools like web search, bash in a sandbox environment, image generation, file writing, and asking follow-up questions.
Frontier models are waiting for you in Agent Mode to take on real-world tasks. GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and top open models. Test them yourself.
20
39
472
45,672
Jun 11
WHEN GERMANY???????????????????????????????

FSD Supervised now approved in Belgium 🇧🇪
Rollout will begin soon
2
665
Jun 8
GPT-5.6 release checkpoint "kindle" Peacock SVG animation

11
6
265
34,441

Jun 11
Wow! Recraft Vector and Arrow-1.0 are a lot better in real world usage, but this result seems to be great!

2
4
724
